在Docker Container中运行Hadoop程序
Hadoop 自从2.7.1 之后开始支持 Docker Container Executor, 这就为我们运行mapreduce 任何提供了一个新的可能,也就是说我们可以把mapreduce 任务的JVM 运行在docker里。利用docker提供的资源隔离技术可以减少并行运行task之间的的干扰。本文主要介绍了把任务运行在docker内,其他相关文章也有讨论把docker配资成单一的节点,该情况不在本文讨论的范围之内。
一. Docker Container vs. YARN Container
首先,docker是一个开源的应用容器引擎,它主要利用namespace实现作用域的隔离,利用cgroup实现资源的 隔离。利用docker可以实现应用的开发,测试以及部署完全没有依赖。当然这些概念化的语句读者可以再wiki或者百度百科上找到,这里就不多说了。其实YARN也就是我们说的hadoop v2.0 也有自已的一套容器机制。有别于hadoop v 1.0 仅仅用slot来区分map 的资源和reduce 资源。 YARN引入了容器的概念,就我自己的感觉来说,起码有以下几个好处:
1. 资源复用,提高集群的利用率(map释放的资源可以被reduce利用)
2. 对资源有了更高纬度的抽象,目前为止支持cpu和memory的抽象,可以想象,随着机器学习应用的流行,将来还可能支持io,gpu,network等
3. YARN能更好的支持除了mapreduce以外的其他应用,例如spark, mpi等
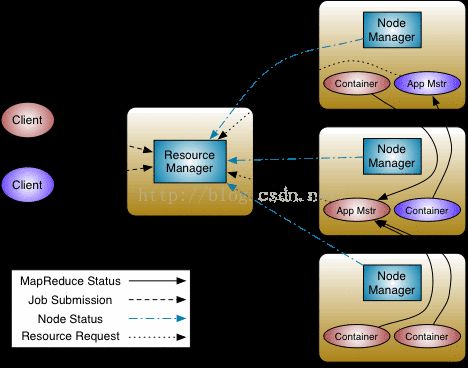
如图所示,在一个Application Maser(AppMaster)为它的task请求到资源以后,YARN会以container的形式把封装好的资源发送给这个task。通俗来说,一个container也就是若干cpu和若干memory的抽象集合。之后Node Manager 再在相应的节点上把这个container运行起来,这个过程很复杂,主要包括从HDFS得到运行程序的jar包、配置文件,从Distributed cache里得到相应的文件,以及本地的配置文件等。但是,问题在于,YARN的container仅仅是一个概念上的container,在YARN的container总并没有实现任何资源隔离,所以我们经常看到的情况是,明明配置了2GB 1core的一个container, top 一下发现这个container上运行的JVM内存消耗超过4GB,CPU利用率超过300%。当然其实YARN的开发组并没有忽视这个问题,他们一直在下一盘很大的棋。于是在hadoop-2.7.1发布之后,DockerContainerExecutor横空出世。
关于Docker的安装,本文不展开细讲,网上能找到大量的资料,ubuntu 上步骤如下:
$ apt-get update
$ apt-get install apt-transport-https ca-certificates编辑/etc/apt/sources.list.d/docker.list,如果没有的话就创建一个。添加以下条目:
On Ubuntu Precise 12.04 (LTS)
deb https://apt.dockerproject.org/repo ubuntu-precise mainOn Ubuntu Trusty 14.04 (LTS)
deb https://apt.dockerproject.org/repo ubuntu-trusty mainUbuntu Wily 15.10
deb https://apt.dockerproject.org/repo ubuntu-wily main$ apt-get update
$ apt-get purge lxc-docker
$ apt-cache policy docker-engine$ docker images ## list docker images on your host $ docker ps ## list all running containers on your host如果命令执行成功,说明docker安装成功。docker image 可以理解成一个 文件系统,该镜像提供的一些必要的可执行文件(例如 ls,cd)以及镜像制作者在 Dockerfile里面
定义的需要预先安装的程序,配置文件,依赖的各种包等。设想一下,如果我们提前制作好镜像,这个镜像可以无缝的切换到各个机器上面而不需要我们做额外的peizhi配置,这是多么逆天的功能。
二. YARN 配置
1. pull images
sudo docker pull sequenceiq/hadoop-docker:2.4.1sequenceiq 已经为我们打包好了hadoop 任务运行所依赖的所有包,环境变量(PATH ,JAVA_HOME,HADOOP_HOME)以及hadoop的环境等,在image pull好之后,你也可以在你这个image里运行一个bash然后验证一下刚才所说的运行环境。
docker run -it sequenceiq/hadoop-docker:2.7.1 /etc/bootstrap.sh -bash然后到/usr/local/目录下面你能找到hadoop目录
2. 配置yarn
yarn.nodemanager.docker-container-executor.exec-name
/usr/bin/docker
Name or path to the Docker client. This is a required parameter. If this is empty,
user must pass an image name as part of the job invocation(see below).
yarn.nodemanager.container-executor.class
org.apache.hadoop.yarn.server.nodemanager.DockerContainerExecutor
This is the container executor setting that ensures that all
jobs are started with the DockerContainerExecutor.
其中第一个配置选项告诉YARN你的docker可执行文件路径,第二个配置选项告诉YARN,conainer-executor 将使用DockerContainerExecutor而不是DefaultContainerExecutor。
./sbin/stop-all.sh
./sbin/start-all.sh然后提交job,命令如下:
hadoop jar $HADOOP_PREFIX/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar \
teragen \
-Dmapreduce.map.env="yarn.nodemanager.docker-container-executor.image-name=sequenceiq/hadoop-docker:2.4.1" \
-Dyarn.app.mapreduce.am.env="yarn.nodemanager.docker-container-executor.image-name=sequenceiq/hadoop-docker:2.4.1" \
1000 \
teragen_out_dir其中Dmapreduce.map.env 和 Dyarn.app.mapreduce.am.env以环境变量的方式告诉 executor影像的名称。 等job运行起来之后你登录到任意一个slave 节点上执行docker ps
三. 源码分析
public abstract class ContainerExecutor implements Configurable { /**
* Run the executor initialization steps.
* Verify that the necessary configs, permissions are in place.
* @throws IOException
*/ public abstract void init() throws IOException; /**
* Prepare the environment for containers in this application to execute.
*
* For $x in local.dirs
* create $x/$user/$appId
* Copy $nmLocal/appTokens {@literal ->} $N/$user/$appId
* For $rsrc in private resources
* Copy $rsrc {@literal ->} $N/$user/filecache/[idef]
* For $rsrc in job resources
* Copy $rsrc {@literal ->} $N/$user/$appId/filecache/idef
*
* @param user user name of application owner
* @param appId id of the application
* @param nmPrivateContainerTokens path to localized credentials, rsrc by NM
* @param nmAddr RPC address to contact NM
* @param dirsHandler NM local dirs service, for nm-local-dirs and nm-log-dirs
* @throws IOException For most application init failures
* @throws InterruptedException If application init thread is halted by NM
*/ public abstract void startLocalizer(Path nmPrivateContainerTokens,
InetSocketAddress nmAddr, String user, String appId, String locId,
LocalDirsHandlerService dirsHandler)
throws IOException, InterruptedException;
/**
* Launch the container on the node. This is a blocking call and returns only
* when the container exits.
* @param container the container to be launched
* @param nmPrivateContainerScriptPath the path for launch script
* @param nmPrivateTokensPath the path for tokens for the container
* @param user the user of the container
* @param appId the appId of the container
* @param containerWorkDir the work dir for the container
* @param localDirs nm-local-dirs to be used for this container
* @param logDirs nm-log-dirs to be used for this container
* @return the return status of the launch
* @throws IOException
*/
public abstract int launchContainer(Container container,
Path nmPrivateContainerScriptPath, Path nmPrivateTokensPath,
String user, String appId, Path containerWorkDir,
List localDirs, List logDirs) throws IOException;
}
public int launchContainer(Container container,
Path nmPrivateContainerScriptPath, Path nmPrivateTokensPath,
String userName, String appId, Path containerWorkDir,
List localDirs, List logDirs) throws IOException {
//从配置文件中读取镜像名称,也就是我们前文说的sequenceiq/hadoop-docker:2.4.0
String containerImageName = getConf().get(YarnConfiguration.NM_DOCKER_CONTAINER_EXECUTOR_IMAGE_NAME,YarnConfiguration.NM_DEFAULT_DOCKER_CONTAINER_EXECUTOR_IMAGE_NAME);
//检查镜像是否为空
Preconditions.checkArgument(!Strings.isNullOrEmpty(containerImageName), "Container image must not be null");
containerImageName = containerImageName.replaceAll("['\"]", "");
......................
// Create the container log-dirs on all disks
createContainerLogDirs(appIdStr, containerIdStr, logDirs, userName);
Path tmpDir = new Path(containerWorkDir,
YarnConfiguration.DEFAULT_CONTAINER_TEMP_DIR);
createDir(tmpDir, dirPerm, false, userName);
// copy launch script to work dir
Path launchDst =
new Path(containerWorkDir, ContainerLaunch.CONTAINER_SCRIPT);
lfs.util().copy(nmPrivateContainerScriptPath, launchDst);
//产生docker 的执行命令,也就是docker run XXXXXX
String memory = Integer.toString(container.getResource().getMemory());
String localDirMount = toMount(localDirs);
String logDirMount = toMount(logDirs);
String containerWorkDirMount = toMount(Collections.singletonList(containerWorkDir.toUri().getPath()));
StringBuilder commands = new StringBuilder();
String commandStr = commands.append(dockerExecutor)
.append(" ")
.append("run")
.append(" ")
.append("--rm --net=host")
.append(" ")
.append("--memory="+memory+"m")
.append(" ")
.append("--memory-swap -1")
.append(" ")
.append(" --name " + containerIdStr)
.append(localDirMount)
.append(logDirMount)
.append(containerWorkDirMount)
.append(" ")
.append(containerImageName)
.toString();
//产生docker inspect命令用于监控docker的运行情况
String dockerPidScript = "`" + dockerExecutor + " inspect --format {{.State.Pid}} " + containerIdStr + "`";
// Create new local launch wrapper script,将产生的两个命令写入脚本文件
LocalWrapperScriptBuilder sb =
new UnixLocalWrapperScriptBuilder(containerWorkDir, commandStr, dockerPidScript);
//写入pid文件
Path pidFile = getPidFilePath(containerId);
if (pidFile != null) {
sb.writeLocalWrapperScript(launchDst, pidFile);
} else {
LOG.info("Container " + containerIdStr
+ " was marked as inactive. Returning terminated error");
return ExitCode.TERMINATED.getExitCode();
}
ShellCommandExecutor shExec = null;
try {
//修改产生的脚本文件的权限
lfs.setPermission(launchDst,
ContainerExecutor.TASK_LAUNCH_SCRIPT_PERMISSION);
lfs.setPermission(sb.getWrapperScriptPath(),
ContainerExecutor.TASK_LAUNCH_SCRIPT_PERMISSION);
// Setup command to run,产生set up command
String[] command = getRunCommand(sb.getWrapperScriptPath().toString(),
containerIdStr, userName, pidFile, this.getConf());
if(command.length > 0){
for(String str : command)
{
LOG.info("dockerlaunchContainer: " + str);
}
}else{
LOG.info("dockerlaunchContainer length < 0");
}
//利用YARN自身的脚本运行的框架运行刚刚产生的一些列脚本,注意这个函数是阻塞的,所以在脚本运行返回之前,也就是container 运行返回之前是不会结束的
shExec = new ShellCommandExecutor(
command,
new File(containerWorkDir.toUri().getPath()),
container.getLaunchContext().getEnvironment()); // sanitized env
if (isContainerActive(containerId)) {
shExec.execute();
} else {
LOG.info("Container " + containerIdStr +
" was marked as inactive. Returning terminated error");
return ExitCode.TERMINATED.getExitCode();
}
} catch (IOException e) {
if (null == shExec) {
return -1;
}