Spark--Spark SQL
Spark-Sql介绍及使用
- Spark Sql 概述
- Spark sql 的前世今生
- 什么是 Spark Sql
- 为什么要学习 Spark SQL
- DataFrame
- 什么是 DataFrame
- DataFrame与RDD的区别
- DataFrame与RDD的优缺点
- 读取数据源创建 DataFrame
- 读取文本文件创建 DataFrame
- 读取 json 文件创建 DataFrame
- 读取 parquet 列式存储格式文件创建 DataFrame
- DataFrame 常用操作
- DSL 风格语法
- SQL 风格语法
- DataSet
- 什么是DataSet
- DataFrame、DataSet、RDD 的区别
- DataFrame 与 DataSet 的互转
- 创建DataSet
- Spark SQL 代码实现
- 编写 Spark SQL 程序实现 RDD 转换 DataFrame
- 通过反射获取 Schema
- 通过 StructType 直接指定 schema
- 编写 Spark SQL 程序操作 HiveContext
- 添加 pom 依赖
- 代码实现
- 通过 sz 将linux中的 hive-site.xml 配置文件导入到项目中
- 数据源
- JDBC
- SparkSql 从 Mysql 中加载数据
- 通过 IDEA 编写 SparkSql 代码
- 通过 spark-shell 运行
- SparkSql 将数据写入到 Mysql 中
- 通过 IDEA 编写 SparkSql 代码
- Spark SQL 自定义函数
- 常规的 SQL
- UDF 函数
- UDAF 函数
- UDTF
Spark Sql 概述
Spark sql 的前世今生
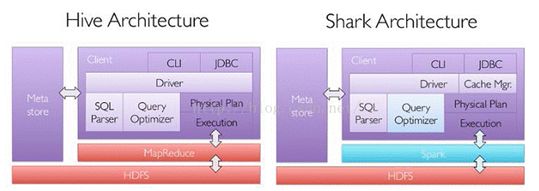
Shark 是一个为 Spark 设计的大规模数据仓库系统,它与 Hive 兼容。Shark 建立在 Hive 的代码基础上,并通过将 Hive 的部分物理执行计划交换出来。这个方法使得 Shark 的用户可以加速 Hive 的查询,但是 Shar k继承了 Hive 的大且复杂的代码使得 Shark 很难优化和维护,同时 Shark 依赖于 Spark 的版本。随着我们遇到了性能优化的上限,以及集成 SQL 的一些复杂的分析功能,我们发现 Hive 的 MapReduce 设计的框架限制了 Shark 的发展。在 2014 年 7 月 1 日 的 Spark Summit 上,Databricks 宣布终止对 Shark 的开发,将重点放到 Spark SQL 上 。
Hive和shark的架构图
什么是 Spark Sql

Spark Sql 是 Spark 用来处理结构化数据的一个模块,它提供了一个编程抽象叫做 DataFrame 并且作为分布式 Sql 查询引擎的作用。
相比于 Spark RDD API 包含了对结构化数据和在其上运算的更多信息,Spark Sql 使用这些信息进行了额外的优化,使对结构化数据的操作更加高效和方便。
有多种方式去使用 Spark Sql ,包括 SQL、DataFrames API 和 Datasets API。但是无论是那种 API 或者是编程语言,他们都是基于同样的执行引擎,因此你可以在不同的 API 之间随意转换,它们各有各的特点
为什么要学习 Spark SQL
我们知道 Hive,它是将 Hive SQL 转换成 MapReduce 然后提交到集群中去执行,大大简化了编写 MapReduce 程序的复杂性,由于 MapReduce 这种计算模型执行效率比较慢,所以 Spark SQL 应运而生,它是将 Spark SQL 转换成 RDD ,然后提交到集群中运行,执行效率非常快!
-
易整合

将 sql 查询与 spark 程序无缝混合、可以使用 java、scala、python、R 等语言的 API 操作。 -
统一的数据访问:

以相同的方式连接到任何数据源。 -
兼容 Hive

支持 hiveSQL 的语法 -
标准的数据连接

可以使用行业标准的 JDBC 或者 ODBC 连接。
DataFrame
什么是 DataFrame
DataFrame 的前身是 SchemaRDD ,从 Spark 1.3.0 开始 SchemaRDD 更名为 DataFrame 。与 SchemaRDD 的主要区别是: DataFrame 不在继承自 RDD ,而是自己实现了 RDD 的绝大多数功能。你仍旧可以在 DataFrame 上调用 rdd 方法将其转换一个 RDD。
在 Spark 中,DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库的二维表格,DataFrame 带有 Schema 元信息,即 DataFrame 所表示的二维表数据集的每一列都带有名称和类型,但底层做了更多的优化。DataFrame 可以从很多数据源构建,比如:已经存在的 RDD、结构化文件、外部数据库、Hive表。
DataFrame与RDD的区别
RDD 可看做是分布式对象的集合,Spark 并不知道对象的详细模式信息, DataFrame 可看做是分布式的 Row 对象的集合,其提供了由列组成的详细模式信息,使得 Spark SQL 可以进行某些形式执行优化。 DataFrame 和普通的 RDD 的逻辑框架区别如下所示:
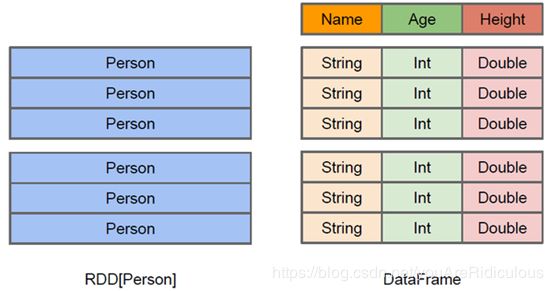
上图中为 DataFrame 和 RDD 的区别
左侧的 RDD[Person] 虽然以Person 为类型参数,但 Spark 框架本省不了解 Person 类的内部结构。
而右侧的 DataFrame 却提供了详细的结构信息,使得 Spark SQL 可以清楚地知道该数据集中包含那些列,每列的名称和类型各是什么。DataFrame 多了数据的结构信息,即 Schema。这样看起来就像一张表了,Dataframe 还配套了新的操作数据的方法,DataFrame API (如 df.select())和 SQL(select id, name from xx_table where ... )。
此外 DataFrame 还引入了 off-heap,意味着 JVM 堆以外的内存,这些内存值接受操作系统管理(而不是 JVM)。Spark 能够以二进制的形式序列化数据(不包括结构)到off-heap 中,当要操作数据时,就直接操作 off-heap 内存,由于 Spark 理解 schema,所以知道该怎么操作。
RDD 是分布式的 Java 对象的集合。DataFrame 是分布式的 Row 对象的集合。DataFrame 除了提供了比 RDD 更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化。
有了DataFrame 这个高一层的抽象后,我们处理数据就更加简单了,甚至可以用 SQL 来处理数据了,对于开发者来说,易用性有了很大的提升。
不仅如此,DataFrame API 或 SQL 处理数据,会自动经过 Spark 优化器(Catalyst)的优化,即使你写的程序 SQL 不高效,也可以运行的很快
DataFrame与RDD的优缺点
RDD 的优缺点:
优点
- 编译时类型安全,编译时就能检查出类型错误。
- 面向对象的编程风格,直接通过对象调用方法的形式来操作数据。
缺点:
-
序列化和反序列化的性能开销,无论是集群间的通信,还是 IO 操作都需要对对象的结构和数据进行序列化和反序列化。
-
== GC的性能开销==,频繁的创建和销毁对象,势必会增加 GC
DataFrame 通过引入 schema 和 off-heap(不在堆里面的内存,指的是除了不在堆的内存,使用操作系统上的内存),解决了 RDD 的缺点, Spark 通过 schame 就能够读懂数据, 因此在通信和 IO 时就只需要序列化和反序列化数据, 而结构的部分就可以省略了;通过 off-heap 引入,可以快速的操作数据,避免大量的 GC 。但是却丢了 RDD 的优点, DataFrame 不是类型安全的, API 也不是面向对象风格的。
读取数据源创建 DataFrame
读取文本文件创建 DataFrame
在 spark2.0 版本之前,Spark SQL 中 SQLContext 是创建 DataFrame 和执行 SQL 的入口,利用 hiveContext 通过 hive sql 语句操作 hive 表数据,兼容 hive 操作,并且 hiveContext 继承自 SQLContext 。在 spark2.0 之后,这些都统一于 SparkSession ,SparkSession 封装了 SparkContext,SqlContext,通过 SparkSession 可以获取到SparkConetxt,SqlContext对象。
实现:
-
在本地创建一个文件,有三列,分别是id、name、age,用空格分隔,然后上传到hdfs上。person.txt内容为
1 zhangsan 20
2 lisi 29
3 wangwu 25
4 zhaoliu 30
5 tianqi 35
6 kobe 40
上传数据文件到HDFS上:hdfs dfs -put person.txt / -
在 Spark shell 执行下面命令,读取数据,将每一行的数据使用列分隔符分割。
先执行 spark-shell --master local[2]
val lineRDD= sc.textFile("/person.txt").map(_.split(" "))

-
定义 case class(相当于表的 schema)
case class Person(id:Int,name:String,age:Int)

-
将 RDD 和 case class 关联
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))

-
将RDD转换成DataFrame

-
对 DataFrame 进行处理
personDF.show

personDF.printSchema

-
通过 SparkSession 构建 DataFrame
使用 spark-shell 中已经初始化好的 SparkSession 对象 spark 生成 Dataframe。
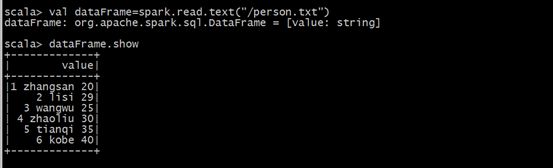
val dataFrame=spark.read.text("/person.txt")
读取 json 文件创建 DataFrame
- 数据文件
使用spark安装包下的
/opt/bigdata/spark/examples/src/main/resources/people.json文件 - 在 spark shell 执行下面命令,读取数据
val jsonDF = spark.read.json(“file:///opt/bigdata/spark/examples/src/main/resources/people.json”)

- 接下来就可以使用 DataFrame 的函数操作


读取 parquet 列式存储格式文件创建 DataFrame
- 数据文件
使用spark安装包下的
/opt/bigdata/spark/examples/src/main/resources/users.parquet文件 - 在 spark shell 执行下面命令,读取数据
val parquetDF = spark.read.parquet(“file:///opt/bigdata/spark/examples/src/main/resources/users.parquet”)

- 接下来就可以使用 DataFrame 的函数操作


DataFrame 常用操作
DSL 风格语法
DataFrame 提供了一个领域特定语言(DSL)以方便操作结构化数据。下面是一些使用示例
- 查看DataFrame中的内容,通过调用show方法
personDF.show

- 查看DataFrame部分列中的内容
- 查看name字段的数据
personDF.select(personDF.col(“name”)).show - 查看name字段的数据的另一种写法
personDF.select(“name”).show

- 查看 name 和age字段数据
personDF.select(col(“name”), col(“age”)).show

- 查看name字段的数据
- 打印DataFrame的Schema信息
personDF.printSchema

- 查询所有的name和age,并将age+1
personDF.select(col(“id”), col(“name”), col(“age”) + 1).show

也可以:
personDF.select(personDF(“id”), personDF(“name”), personDF(“age”) + 1).show

- 过滤age大于等于25的,使用filter方法过滤
personDF.filter(col(“age”) >= 25).show

- 统计年龄大于30的人数
personDF.filter(col(“age”)>30).count()

- 按年龄进行分组并统计相同年龄的人数
personDF.groupBy(“age”).count().show

SQL 风格语法
DataFrame 的一个强大之处就是我们可以将它看做一个关系型数据表,然和可以通过在程序中使用 spark.sql() 来执行 SQL 查询,结果将作为一个 DataFrame 返回。
如果想使用 SQL 风格的语法,需要将 DataFrame 注册成表,采用如下的方式:personDF.registerTempTable("t_person")
- 查询年龄最大的前两名
spark.sql(“select * from t_person order by age desc limit 2”).show

- 显示表的Schema信息
spark.sql(“desc t_person”).show

- 查询年龄大于30的人的信息
spark.sql("select * from t_person where age > 30 ").show

DataSet
什么是DataSet
DataSet是分布式的数据集合。DataSet 是在 spark 1.6 添加的新的接口。它集中了 RDD 的优点(强类型和可以用强大 lambda 函数)以及 Spark SQL 优化的执行引擎。DataSet 可以通过 JVM 对象进行构建,可以用函数式的转换(map/flatmap/filter)进行更多操作。
DataFrame、DataSet、RDD 的区别
假设 RDD 中的两行数据长这样

那么 DataFrame 中的数据长这样
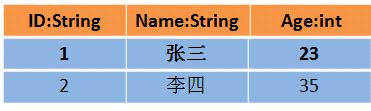
那么 DataSet 中的数据长这样
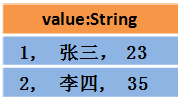
或者这样

DataSet 包含了 DataFrame 的功能,Spark2.0 中两者统一,DataFrame 表示为 DataSet[Row],即 DataSet 的子集。
- DataSet 可以在编译时检查类型。
- 并且是面向对象的编程接口。
相比 DataFrame,DataSet 提供了编译时类型检查,对于分布式程序来讲,提交一次作业太费劲了(要编译,打包,上传,运行),到提交到集群运行时才发现错误,这会浪费大量的时间,这也是引入 DataSet 的一个重要原因。
DataFrame 与 DataSet 的互转
DataFrame 和 DataSet 可以相互转换
- DataFrame 转为 DataSet
df.as[ElementType] 这样可以把 DataFrame 转化为 DataSet。 - DataSet 转为 DataFrame
ds.toDF() 这样可以把 DataSet 转化为 DataFrame。
创建DataSet
- 通过 spark.createDataSet 创建
//todo:1、创建SparkSession,指定appName和master
val spark: SparkSession = SparkSession.builder()
.appName("SparkSqlSchema")
.master("local[2]")
.getOrCreate()
//需要导入隐式装换
import spark.implicits._
//创建dataframe的方式1
val ds: Dataset[Int] = spark.createDataset(0 to 10)
ds.show()
spark.stop()
- 通过 toDS 方法生成 DataSet
//todo:1、创建SparkSession,指定appName和master
val spark: SparkSession = SparkSession.builder()
.appName("SparkSqlSchema")
.master("local[2]")
.getOrCreate()
//需要导入隐式装换
import spark.implicits._
val df = spark.createDataFrame(List(Person01("Jason", 34), Person01("Tom", 20))).toDF("name", "age")
val ds = df.as[Person01]
ds.show()
spark.stop()
- 通过 List 封装数据直接转换成 DataSet
//todo:1、创建SparkSession,指定appName和master
val spark: SparkSession = SparkSession.builder()
.appName("SparkSqlSchema")
.master("local[2]")
.getOrCreate()
import spark.implicits._
//需要导入隐式装换
val ds = List(Person("Jason", 34), Person("Tom", 20)).toDS()
ds.show();
点我查看更多DataSet操作API
Spark SQL 代码实现
编写 Spark SQL 程序实现 RDD 转换 DataFrame
在 Spark SQL 中有两种方式可以在 DataFrame 和 RDD 进行转换,第一种方式是利用反射机制,推到包含某种类型的 RDD ,通过反射将其转换为指定类型的 DataFrame,适用于提前知道 RDD 的 Schema 。
第二种方法通过编程接口与 RDD 进行交互获取 schema,并创建 DataFrame,在运行时决定列及其类型。
**首先在maven项目的pom.xml中添加Spark SQL的依赖**
org.apache.spark
spark-sql_2.11
2.0.2
通过反射获取 Schema
Scala 支持使用 case class 类型导入 RDD 转换为 DataFrame,通过case class 创建 schema ,case class 的参数名称会被反射读取并成为其表的列名。这种 RDD 可以高效的转换为 DataFrame 并注册为表。
代码如下: import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* RDD转化成DataFrame:利用反射机制
*/
//todo:定义一个样例类Person
case class Person(id:Int,name:String,age:Int) extends Serializable
object InferringSchema {
def main(args: Array[String]): Unit = {
//todo:1、构建sparkSession 指定appName和master的地址
val spark: SparkSession = SparkSession.builder()
.appName("InferringSchema")
.master("local[2]").getOrCreate()
//todo:2、从sparkSession获取sparkContext对象
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")//设置日志输出级别
//todo:3、加载数据
val dataRDD: RDD[String] = sc.textFile("D:\\person.txt")
//todo:4、切分每一行记录
val lineArrayRDD: RDD[Array[String]] = dataRDD.map(_.split(" "))
//todo:5、将RDD与Person类关联
val personRDD: RDD[Person] = lineArrayRDD.map(x=>Person(x(0).toInt,x(1),x(2).toInt))
//todo:6、创建dataFrame,需要导入隐式转换
import spark.implicits._
val personDF: DataFrame = personRDD.toDF()
//todo-------------------DSL语法操作 start--------------
//1、显示DataFrame的数据,默认显示20行
personDF.show()
//2、显示DataFrame的schema信息
personDF.printSchema()
//3、显示DataFrame记录数
println(personDF.count())
//4、显示DataFrame的所有字段
personDF.columns.foreach(println)
//5、取出DataFrame的第一行记录
println(personDF.head())
//6、显示DataFrame中name字段的所有值
personDF.select("name").show()
//7、过滤出DataFrame中年龄大于30的记录
personDF.filter($"age" > 30).show()
//8、统计DataFrame中年龄大于30的人数
println(personDF.filter($"age">30).count())
//9、统计DataFrame中按照年龄进行分组,求每个组的人数
personDF.groupBy("age").count().show()
//todo-------------------DSL语法操作 end-------------
//todo--------------------SQL操作风格 start-----------
//todo:将DataFrame注册成表
personDF.createOrReplaceTempView("t_person")
//todo:传入sql语句,进行操作
spark.sql("select * from t_person").show()
spark.sql("select * from t_person where name='zhangsan'").show()
spark.sql("select * from t_person order by age desc").show()
//todo--------------------SQL操作风格 end-------------
sc.stop()
}
}
通过 StructType 直接指定 schema
当case class 不能提前定义耗时,可以通过以下散步通过代码创建 DataFrame。
- 将 RDD 转为包含 row 对象的 RDD。
- 基于 structType 类型创建 schema ,与第一步创建的 RDD 相匹配。
- 通过 sparkSession 的 createDataFrame 方法对第一步的 RDD 应用。
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
/**
* RDD转换成DataFrame:通过指定schema构建DataFrame
*/
object SparkSqlSchema {
def main(args: Array[String]): Unit = {
//todo:1、创建SparkSession,指定appName和master
val spark: SparkSession = SparkSession.builder()
.appName("SparkSqlSchema")
.master("local[2]")
.getOrCreate()
//todo:2、获取sparkContext对象
val sc: SparkContext = spark.sparkContext
//todo:3、加载数据
val dataRDD: RDD[String] = sc.textFile("d:\\person.txt")
//todo:4、切分每一行
val dataArrayRDD: RDD[Array[String]] = dataRDD.map(_.split(" "))
//todo:5、加载数据到Row对象中
val personRDD: RDD[Row] = dataArrayRDD.map(x=>Row(x(0).toInt,x(1),x(2).toInt))
//todo:6、创建schema
val schema:StructType= StructType(Seq(
StructField("id", IntegerType, false),
StructField("name", StringType, false),
StructField("age", IntegerType, false)
))
//todo:7、利用personRDD与schema创建DataFrame
val personDF: DataFrame = spark.createDataFrame(personRDD,schema)
//todo:8、DSL操作显示DataFrame的数据结果
personDF.show()
//todo:9、将DataFrame注册成表
personDF.createOrReplaceTempView("t_person")
//todo:10、sql语句操作
spark.sql("select * from t_person").show()
spark.sql("select count(*) from t_person").show()
sc.stop()
}
}
编写 Spark SQL 程序操作 HiveContext
HiveContext 是对应 spark-hive 这个项目,与 hive 有部分耦合,支持hql,是 SqlContext 的子类,也就是说兼容 SqlContext。
添加 pom 依赖
org.apache.spark
spark-hive_2.11
2.0.2
代码实现
import org.apache.spark.sql.SparkSession
/**
* todo:支持hive的sql操作
*/
object HiveSupport {
def main(args: Array[String]): Unit = {
val warehouseLocation = "D:\\workSpace_IDEA_NEW\\day2017-10-12\\spark-warehouse"
//todo:1、创建sparkSession
val spark: SparkSession = SparkSession.builder()
.appName("HiveSupport")
.master("local[2]")
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport() //开启支持hive
.getOrCreate()
spark.sparkContext.setLogLevel("WARN") //设置日志输出级别
import spark.implicits._
import spark.sql
//todo:2、操作sql语句
sql("CREATE TABLE IF NOT EXISTS person (id int, name string, age int) row format delimited fields terminated by ' '")
sql("LOAD DATA LOCAL INPATH '/person.txt' INTO TABLE person")
sql("select * from person ").show()
spark.stop()
}
}
通过 sz 将linux中的 hive-site.xml 配置文件导入到项目中
注意:
使用hive需要sparksession设置支持选项,如果用户集群里,没有部署好的hive,sparksession也能够提供hive支持,在这种情况下,如果没有hive-site.xml文件,sparkcontext会自动在当前目录创建元数据db,并且会在spark.sql.warehouse.dir表示的位置创建一个目录,用户存放table数据,所以spark.sql.warehouse.dir是一个用户存放hive table文件的一个目录,因为是一个目录地址,难免会收到操作系统的影响,因为不同的文件系统的前缀是不一样了,为了适配性,spark鼓励在code中设置该选项,而不是在hive-site.xml中设置该选项。
- 如果没有部署好的hive,spark确实是会使用内置的hive,但是spark会将所有的元信息都放到spark_home/bin 目录下也就是为什么配置了spark.sql.warehouse.dir 却不起作用的原因。而且,就算部署了hive,也需要让spark识别hive,否则spark,还是会使用spark默认的hive
- 只有在部署好的hive情况下,使用spark.sql.warehouse.dir才会生效,而且spark会默认覆盖hive的配置项。
数据源
JDBC
Spark SQL 可以通过 JDBC 从关系型数据库中读取数据的方式创建 DataFrame ,通过对 DataFrame 一系列的计算后,还可以将数据在写回关系型数据库中。
SparkSql 从 Mysql 中加载数据
通过 IDEA 编写 SparkSql 代码
导入 mysq 的连接驱动包
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* todo:Sparksql从mysql中加载数据
*/
object DataFromMysql {
def main(args: Array[String]): Unit = {
//todo:1、创建sparkSession对象
val spark: SparkSession = SparkSession.builder()
.appName("DataFromMysql")
.master("local[2]")
.getOrCreate()
//todo:2、创建Properties对象,设置连接mysql的用户名和密码
val properties: Properties =new Properties()
properties.setProperty("user","root")
properties.setProperty("password","123456")
//todo:3、读取mysql中的数据
val mysqlDF: DataFrame = spark.read.jdbc("jdbc:mysql://192.168.200.150:3306/spark","iplocaltion",properties)
//todo:4、显示mysql中表的数据
mysqlDF.show()
spark.stop()
}
}
通过 spark-shell 运行
- 启动 spark-shell(必须制定 mysq 的连接驱动包)
spark-shell \
--master spark://hdp-node-01:7077 \
--executor-memory 1g \
--total-executor-cores 2 \
--jars /opt/bigdata/hive/lib/mysql-connector-java-5.1.35.jar \
--driver-class-path /opt/bigdata/hive/lib/mysql-connector-java-5.1.35.jar
- 从mysql中加载数据
val mysqlDF = spark.read.format("jdbc").options(Map("url" -> "jdbc:mysql://192.168.200.100:3306/spark", "driver" -> "com.mysql.jdbc.Driver", "dbtable" -> "iplocaltion", "user" -> "root", "password" -> "123456")).load()
- 执行查询

SparkSql 将数据写入到 Mysql 中
通过 IDEA 编写 SparkSql 代码
- 编写代码
import java.util.Properties
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, SaveMode, SparkSession}
/**
* todo:sparksql写入数据到mysql中
*/
object SparkSqlToMysql {
def main(args: Array[String]): Unit = {
//todo:1、创建sparkSession对象
val spark: SparkSession = SparkSession.builder()
.appName("SparkSqlToMysql")
.getOrCreate()
//todo:2、读取数据
val data: RDD[String] = spark.sparkContext.textFile(args(0))
//todo:3、切分每一行,
val arrRDD: RDD[Array[String]] = data.map(_.split(" "))
//todo:4、RDD关联Student
val studentRDD: RDD[Student] = arrRDD.map(x=>Student(x(0).toInt,x(1),x(2).toInt))
//todo:导入隐式转换
import spark.implicits._
//todo:5、将RDD转换成DataFrame
val studentDF: DataFrame = studentRDD.toDF()
//todo:6、将DataFrame注册成表
studentDF.createOrReplaceTempView("student")
//todo:7、操作student表 ,按照年龄进行降序排列
val resultDF: DataFrame = spark.sql("select * from student order by age desc")
//todo:8、把结果保存在mysql表中
//todo:创建Properties对象,配置连接mysql的用户名和密码
val prop =new Properties()
prop.setProperty("user","root")
prop.setProperty("password","123456")
resultDF.write.jdbc("jdbc:mysql://192.168.200.150:3306/spark","student",prop)
//todo:写入mysql时,可以配置插入mode,overwrite覆盖,append追加,ignore忽略,error默认表存在报错
//resultDF.write.mode(SaveMode.Overwrite).jdbc("jdbc:mysql://192.168.200.150:3306/spark","student",prop)
spark.stop()
}
}
//todo:创建样例类Student
case class Student(id:Int,name:String,age:Int)
-
用 maven 将程序打包
通过 IDEA 工具打包即可 -
将 Jar 包提交到 spark 集群
spark-submit \
--class itcast.sql.SparkSqlToMysql \
--master spark://hdp-node-01:7077 \
--executor-memory 1g \
--total-executor-cores 2 \
--jars /opt/bigdata/hive/lib/mysql-connector-java-5.1.35.jar \
--driver-class-path /opt/bigdata/hive/lib/mysql-connector-java-5.1.35.jar \
/root/original-spark-2.0.2.jar /person.txt

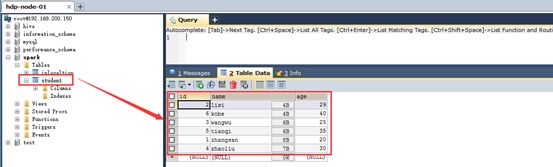
- 查看 mysql 中表的数据
Spark SQL 自定义函数
常规的 SQL
常规的SQL 语句中包含部分为 select 字段 from 表 where 条件 order by 排序条件等。要重点掌握聚合函数 max,min,sum,count,avg 等。
语法:
-
select:
select 语句同于从表中选取数据。
结果被存储在一个结果表中(成为数据集)。 -
where 子句
如需有条件地从表中选取数据,可将 where 子句添加到 select 语句中。 -
order by 语句
order by 语句用于根据指定的列对结果集进行排序
order by 语句默认按照升序对记录进行排序,如果按照降序对记录进行排序,可以使用 desc 关键字 升序为 asc(默认)。 -
聚合函数
avg 函数返回数值列的平均值。null值不包括在计算中。
sum 函数返回数值列的总数。
max 函数计算列的最大值。
min 函数计算列的最小值。
count 函数统计行的数量。常常需要添加 group by 语句
group by 语句用于结合合计函数,根据一个或者多个列对结果集进行分组。
比如:
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name
在常用的过程中,如果分析过程能用sql 或者函数能统计出来结果,尽量直接使用sql去进行分 析。但是有特殊情况,可以采用很多种灵活变通的方式。
UDF 函数
-
概念:
UDF(User-defined functions)用户自定义函数,简单说就是输入一行输出一行的自定义算子,是大多数 SQL 环境的关键特性,用于扩张系统的内置功能。 -
使用过程
spark.udf.register(“funcName”, func) 来进行注册。
select funcName(name) from people 来直接使用。 -
案例
-
需求:对给定城市的温度进行华氏温标和摄氏温标转化,其中对应的数据如下:
{“city”:“St. John’s”,“avgHigh”:8.7,“avgLow”:0.6}
{“city”:“Charlottetown”,“avgHigh”:9.7,“avgLow”:0.9}
{“city”:“Halifax”,“avgHigh”:11.0,“avgLow”:1.6}
{“city”:“Fredericton”,“avgHigh”:11.2,“avgLow”:-0.5}
{“city”:“Quebec”,“avgHigh”:9.0,“avgLow”:-1.0}
{“city”:“Montreal”,“avgHigh”:11.1,“avgLow”:1.4} -
实现
import org.apache.spark.sql.SQLContext import org.apache.spark.{SparkConf, SparkContext} object UdfDemo { def main(args: Array[String]): Unit = { //资源的调度 var conf = new SparkConf().setMaster("local").setAppName("demo") var sc = new SparkContext(conf) val sqlContext = new SQLContext(sc) val df = sqlContext.read.json("G:\\workspaceBigdata\\ScalaDemo\\src\\com\\spark\\sparksql\\user.txt") df.registerTempTable("citytemps") // Register the UDF with our SQLContext sqlContext.udf.register("CTOF", (degreesCelcius: Double) => ((degreesCelcius * 9.0 / 5.0) + 32.0)) sqlContext.sql("SELECT city, CTOF(avgLow) AS avgLowF, CTOF(avgHigh) AS avgHighF FROM citytemps").show() } } -
-
小结:
简单粗暴的理解,他就是输入一行输出一行自定义算子。
我们可以通过实名函数或者匿名的方式来实现,并使用 sparkSession.udf.register() 来注册,需要注意,戒指目前(spark2.4)最多支持22个输入参数的 UDF。
UDAF 函数
-
概念:
UDAF (User Defined Aggregate Function) 即用户定义的聚合函数,聚合函数和普通函数的区别是,普通函数是接收一行输入产生一行输出,聚合函数就是接收一组(一般是多行)然后产生一个输出,即将一组的值想办法聚合一下。
UDAF 可以跟 group by 一起使用,也可以不跟 group by 一起使用,这个比较好理解,联想到 mysql 中的 max、min 等函数,可以:
1. select max(foo) from foobar group by bar; 表示根据 bar 字段分组,然后求每个分组的最大值,这时候的分组有很多个,使用这个函数有很多个,使用这个函数对每个分组进行处理。 2. select max(foo) from foobar; 这种情况可以将整张表看做一个分组,然后在这个分组(实际上就是一整张表)中求最大值。所以聚合函数其实是对分组做处理,而不关心分组中记录的具体数量。 -
使用过程
自定义类继承UserDefinedAggregateFunction,对每个阶段方法做实现
spark.udf.register(“funcName”, new func) 来进行注册。
select funcName(name) from people 来直接使用 -
案例:
进行操作的源数据:
hello bawei
hello beijing
hello zongbu
hello world
I love bawei
I love my teacher
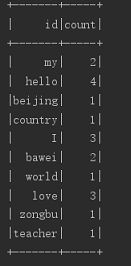
I love my countryimport org.apache.spark.rdd.RDD import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction} import org.apache.spark.sql.types._ import org.apache.spark.sql.{DataFrame, Row, SQLContext} import org.apache.spark.{SparkConf, SparkContext} object UDAFT { def main(args: Array[String]): Unit = { //todo:获得SparkConf,并设置进程名,以及索取资源的位置 val conf: SparkConf = new SparkConf().setAppName("udaf").setMaster("local") //todo:获得SparkContext 上下文对象 val sc = new SparkContext(conf) //todo:获得 SQLContext对象 val sqsc = new SQLContext(sc) //todo:通过获得SparkContext读取本地文件,返回 RDD val filerdd: RDD[String] = sc.textFile("d:\\person.txt") //todo:对RDD进行切割,并且加载数据到 Row 对象中(创建DataFrame需要对每行设置字段名) val lineRDD: RDD[Row] = filerdd.flatMap(_.split(" ")).map(Row(_)) //todo:获得Schema ,并设置字段名称 字段类型 val structType: StructType = StructType(Seq(StructField("id",StringType,false))) //todo:通过SQLContext对象,创建DataFrame ,传入参数 RDD和Schema,返回DataFrame val dataFrame: DataFrame = sqsc.createDataFrame(lineRDD,structType) //todo:通过 DataFrame 注册一个临时的表 dataFrame.registerTempTable("person") //todo:通过SQLContext 注册函数,参数函数名字和继承了UserDefinedAggregateFunction 的类 sqsc.udf.register("funcname",new UDAFT) //todo:通过SQLContext 使用sql语句调用自定义的 UDAF 函数,并打印结果 sqsc.sql("select id,funcname(id) as count from person group by id").show() //todo:关闭 SparkContext,释放资源 sc.stop() } } //todo:写一个自定义的类 继承 UserDefinedAggregateFunction,重写方法 class UDAFT extends UserDefinedAggregateFunction { //todo: 传入的参数,自定义名称和类型 override def inputSchema: StructType = StructType(List(StructField("words",StringType))) //todo:放入缓存区中操作的数据,自定义名称和类型,(缓存区中为同一组的所有数据) override def bufferSchema: StructType = StructType(List(StructField("count",IntegerType))) //todo:最终返回的类型 override def dataType: DataType = IntegerType //todo:聚合函数是否是一致的,即相同输入是否总是能得到相同输出,一般为true override def deterministic: Boolean = true //todo:放入缓存区的数据给一个初始化的数据,每组执行一次 override def initialize(buffer: MutableAggregationBuffer): Unit = buffer(0) = 0 //todo:每当有新的值进来的时候,执行的方法,执行多次,buffer为缓存区自定义数据,input为每次进来的表中分组的数据 override def update(buffer: MutableAggregationBuffer, input: Row): Unit = buffer(0) = buffer.getInt(0) + 1 //todo:合并聚合函数缓冲区 override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = buffer1(0) = buffer1.getInt(0)+buffer2.getInt(0) //todo:最终结果,可以加入算法 override def evaluate(buffer: Row): Any = buffer(0) }返回的结果:
UDTF
-
概念:
UDTF(User-Defined Table-Generating Functions),用户自定义生成函数。他就是输入一行输出多行的自定义算子,可输出多行多列,又被称为 “ 表生成函数 ” 。
-
使用过程
实现抽象类org .apache.hadoop.hive.ql.udf.generic.GenericUDTF来自定义UDTF算子。
sparkSession.sql(“CREATE TEMPORARY FUNCTION 自定义算子名称 as '算子实现类全限定名称 '”)来进行注册。
select funcName(name) from people 来直接使用。 -
案例
class UserDefinedUDTF extends GenericUDTF{ //这个方法的作用:1.输入参数校验 2. 输出列定义,可以多于1列,相当于可以生成多行多列数据 override def initialize(args:Array[ObjectInspector]): StructObjectInspector = { if (args.length != 1) { throw new UDFArgumentLengthException("UserDefinedUDTF takes only one argument") } if (args(0).getCategory() != ObjectInspector.Category.PRIMITIVE) { throw new UDFArgumentException("UserDefinedUDTF takes string as a parameter") } val fieldNames = new util.ArrayList[String] val fieldOIs = new util.ArrayList[ObjectInspector] //这里定义的是输出列默认字段名称 fieldNames.add("col1") //这里定义的是输出列字段类型 fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector) ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs) } //这是处理数据的方法,入参数组里只有1行数据,即每次调用process方法只处理一行数据 override def process(args: Array[AnyRef]): Unit = { //将字符串切分成单个字符的数组 val strLst = args(0).toString.split("") for(i <- strLst){ var tmp:Array[String] = new Array[String](1) tmp(0) = i //调用forward方法,必须传字符串数组,即使只有一个元素 forward(tmp) } } override def close(): Unit = {}} 测试代码 object UserAnalysis { def main(args:Array[String]): Unit ={ //测试数据所在的本地路径 val userDataPath = "file:///home/hadoop/data_format/zxc/small1.csv" //创建sparksession val sparkSession = SparkSession .builder .master("local") .appName("UserAnalysis") .enableHiveSupport() //启用hive .getOrCreate() //sparksession直接读取csv,可设置分隔符delimitor. var userDF = sparkSession.read .option("header","true") .csv(userDataPath) //将DataFrame注册成视图,然后即可使用hql访问 userDF.createOrReplaceTempView("userDF") //注册utdf算子,这里无法使用sparkSession.udf.register() sparkSession.sql("CREATE TEMPORARY FUNCTION UserDefinedUDTF as 'com.zxc.sparkAppTest.udtf.UserDefinedUDTF'") //使用UDTF算子处理原表userDF val UserDefinedUDTFDF = sparkSession.sql( "select " + "user_id," + "item_id," + "cat_id," + "merchant_id," + "brand_id," + "month," + "day," + "action," + "age_range," + "gender," + "UserDefinedUDTF(province) " + "from " + "userDF" ) UserDefinedUDTFDF.show }} -
小结:
它是输入一行输出多行的自定义算子,可输出多行多列,又被称为表生成函数。
通过实现抽象类org.apache.hadoop.hive.ql.udf.generic.GenericUDTF 来实现UDTF算子,但是似乎无法使用 sparkSession.udf.register() 来注册。需要通过sparkSession.sql("CREATE TEMPORARY FUNCTION 自定义算子名称 as '算子实现类全限定名称'")来注册
实现UDTF 还需要主语(基于 Spark1.5,可以已过时)
udtf,process 方法中对参数需要使用 toString 。
sparksql 子查询必须要有别名
算子内部使用竖线切分字符串,需要转义。
UDTF 调用 forward 方法,必须传入字符串数组,及时只有一个元素。