以太坊 Trie树
Trie树
Trie树,又称字典树,是一种用于快速检索的多叉树结构。
Trie树可以利用字符串的公共前缀来节约存储空间,如果系统中存在大量字符串且这些字符串基本没有公共前缀,则相应的trie树将非常消耗内存,这也是trie树的一个缺点。
Trie树的基本性质可以归纳为:
根节点不包含字符,除根节点以外每个节点只包含一个字符。
从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。
每个节点的所有子节点包含的字符串不相同。
如英文字母的字典树是一个26叉树,数字的字典树是一个10叉树。
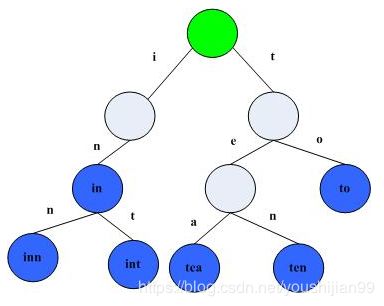
如下图所示,该trie树用10个节点保存了6个字符串:tea,ten,to,in,inn,int:
Patricia Tries 前缀树
前缀树跟Trie树的不同之处在于Trie树是为每一个字符串分配一个节点,
而前缀树是将那些很长但又没有公共节点的字符串的Trie树退化成数组。
在以太坊里面会由黑客构造很多这种节点造成拒绝服务攻击。
前缀树的不同之处在于如果节点有公共前缀,那么就使用公共前缀,否则就把剩下的所有节点插入同一个节点。
如: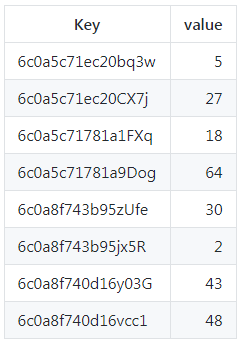
Merkle树
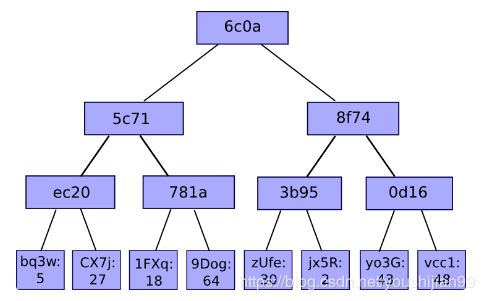
Merkle Tree,通常也被称作Hash Tree,顾名思义,就是存储hash值的一棵树。
Merkle树的叶子是数据块(例如,文件或者文件的集合)的hash值。
非叶节点是其对应子节点串联字符串的hash。
Merkle Tree的主要作用是当我拿到Top Hash的时候,这个hash值代表了整颗树的信息摘要,当树里面任何一个数据发生了变动,都会导致Top Hash的值发生变化。
而Top Hash的值是会存储到区块链的区块头里面去的, 区块头是必须经过工作量证明。
这也就是说我只要拿到一个区块头,就可以对区块信息进行验证。
MPT 以太坊Tries树
Merkle Patricia Trie(MPT) 是 EThereum 中一种非常重要的数据结构,用来存储用户账户的状态及其变更、交易信息、交易的收据信息。
每一个以太坊的区块头包含三颗MPT树,分别是:
1、交易树
2、收据树(交易执行过程中的一些数据)
3、状态树(账号信息,合约账户和用户账户)
MPT树有以下几个作用:
存储任意长度的key-value键值对数据;
提供了一种快速计算所维护数据集哈希标识的机制;
提供了快速状态回滚的机制;
提供了一种称为默克尔证明的证明方法,进行轻节点的扩展,实现简单支付验证;
下图中是两个区块头,
其中state root,tx root,receipt root分别存储了这三棵树的树根,
第二个区块显示了当账号 175的数据变更(27 -> 45)的时候,只需要存储跟这个账号相关的部分数据,而且老的区块中的数据还是可以正常访问。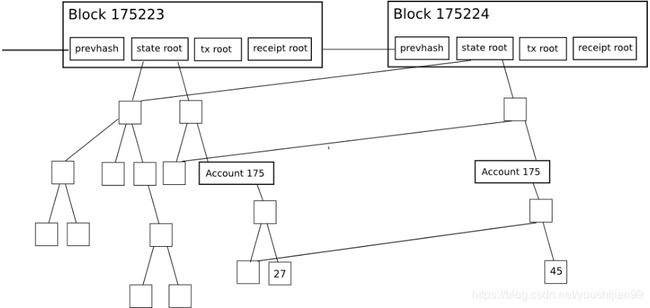
key value
a711355 45.0 ETH
a77d337 1.00 WEI|
a7f9365 1.1 ETH
a77d397 0.12 ETH
prefix 前缀:
0 - 扩展节点,偶数个半字节
1 - 扩展节点,奇数个半字节
2 - 叶子节点,偶数个半字节
3 - 叶子节点,奇数个半字节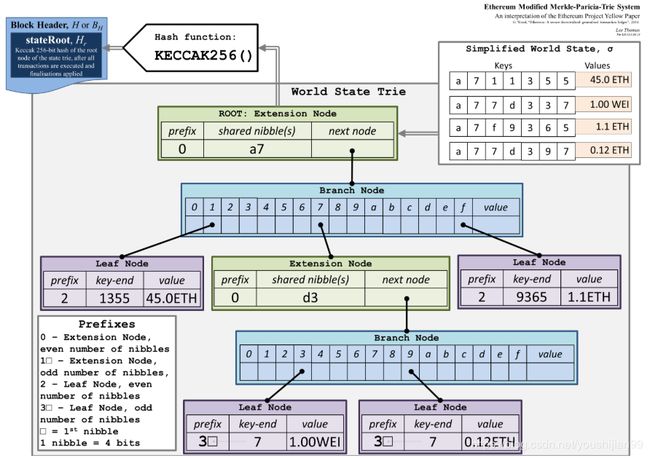
MPT 中对 key 的编码
trie/encoding.go 主要处理trie树中的三种编码格式的相互转换的工作。
三种编码格式分别为:
KEYBYTES 编码: 这种编码格式是原生的key字节数组
HEX 编码: 这种编码格式是把一字节拆分成两字节,尾部加一字节编码标记(0x10),
COMPACT 编码: 这种编码格式是把Hex的两字节合并为一字节,在头部加一字节奇偶数据位(0x20或0x30)
将 keybytes 编码为 Hex:
编码前: 0x12 0x34 0x56
编码后: 0x01 0x02 0x03 0x04 0x03 0x04 0x05 0x06 0x10
0x10 为标记为 表示是Hex编码
package main
import (
"fmt"
)
// 将 keybytes 转化成 Hex
// 1. 将 keybytes 中的1byte信息,高4bit和低4bit分别放在2个byte里。
// 2. 最后在尾部加1字节标记当前属于Hex格式。
func keybytesToHex(str []byte) []byte {
l := len(str)*2 + 1
var nibbles = make([]byte, l)
for i, b := range str {
nibbles[i*2] = b / 16 // 取 keybytes 高 4bit
nibbles[i*2+1] = b % 16 // 取 keybytes 低 4bit
}
nibbles[l-1] = 16 // 标记是Hex格式
return nibbles
}
func main() {
key := []byte{0x12,0x34,0x56}
h := keybytesToHex(key)
fmt.Printf("keybytesToHex(%x) -> %x\n", key, h, )
}运行结果:
keybytesToHex(123456) -> 01020304050610
将 Hex 编码为 keybytes :
将0x01 0x02 0x03 0x04 0x10 合并 1234
注:0x10 为标记符,表示Hex编码
package main
import (
"fmt"
)
// hex 参数必须是偶数长度(不包括终结符16)
func hexToKeybytes(hex []byte) []byte {
if hasTerm(hex) {
hex = hex[:len(hex)-1] // 去除终结符 16
}
if len(hex)&1 != 0 { // 判断 hex长度是否为偶数(hex不包含终结符16)
panic("can't convert hex key of odd length")
}
key := make([]byte, len(hex)/2)
decodeNibbles(hex, key)
return key
}
// 将 nibbles 的每2个字节的低4位合并为一个字节
func decodeNibbles(nibbles []byte, bytes []byte) {
for bi, ni := 0, 0; ni < len(nibbles); bi, ni = bi+1, ni+2 {
bytes[bi] = nibbles[ni]<<4 | nibbles[ni+1] // 将2个字节的 各自低4位合并为1个字节
}
}
// 判断是否有终结符 16, 有终结符16 表明是Hex编码
func hasTerm(s []byte) bool {
return len(s) > 0 && s[len(s)-1] == 16
}
func main() {
hex := []byte{0x01,0x02,0x03,0x04,0x10}
h := hexToKeybytes(hex)
fmt.Printf("keybytesToHex(%x) -> %x\n", hex, h, )
}运行结果:
hexToKeybytes(0102030410) -> 1234
将 Hex 压缩 Compact:
0x01 0x02 0x03 0x04 0x10 压缩后 201234
其中 20 为奇偶标记位
package main
import (
"fmt"
)
// 将 Hex 压缩
func hexToCompact(hex []byte) []byte {
terminator := byte(0) // 设置终结符为 0 (1字节)
if hasTerm(hex) {
terminator = 1 // 如果为 Hex 编码, 设置终结符为1
hex = hex[:len(hex)-1] // 去除编码标记位
}
buf := make([]byte, len(hex)/2+1) // buf 长度为 hex去除编码标记位后除2,加上1字节的终结符标记
buf[0] = terminator << 5 // 偶数设置终结符标记位为 0x20
if len(hex)&1 == 1 { // 判断长度为奇数还是偶数,如果是奇数做如下处理
buf[0] |= 1 << 4 // 奇数设置终结符标记位为 0x30
buf[0] |= hex[0] // 将 hex[0] 的低四位包含到 buf[0] 的低四位,因为高四位是奇数/偶数位
hex = hex[1:] // 截取掉hex的第1字节
}
decodeNibbles(hex, buf[1:])
return buf
}
// 将 nibbles 的每2个字节的低4位合并为一个字节
func decodeNibbles(nibbles []byte, bytes []byte) {
for bi, ni := 0, 0; ni < len(nibbles); bi, ni = bi+1, ni+2 {
bytes[bi] = nibbles[ni]<<4 | nibbles[ni+1] // 将2个字节的 各自低4位合并为1个字节
}
}
// 判断是否有终结符 16, 有终结符16 表明是Hex编码
func hasTerm(s []byte) bool {
return len(s) > 0 && s[len(s)-1] == 16
}
func main() {
hex := []byte{0x01,0x02,0x03,0x04,0x10}
h := hexToCompact(hex)
fmt.Printf("hexToCompact(%x) -> %x\n", hex, h, )
}运行结果:
hexToCompact(0102030410) -> 201234
将 compact 解压为 Hex 或 keybytes:
package main
import (
"fmt"
)
// 将Hex的压缩码 解压为Hex
func compactToHex(compact []byte) []byte {
base := keybytesToHex(compact) // 先将 compact 转换为Hex编码
// delete terminator flag
if base[0] < 2 { // 如果不为Hex 压缩编码, 去除 Hex 编码标记
base = base[:len(base)-1] // 去除 Hex 编码标记
}
// apply odd flag
chop := 2 - base[0]&1 // 0 是偶数(从索引2开始,去除头部), 1是奇数 (从索引1开始,去除头部)
return base[chop:]
}
func keybytesToHex(str []byte) []byte {
l := len(str)*2 + 1
var nibbles = make([]byte, l)
for i, b := range str {
nibbles[i*2] = b / 16
nibbles[i*2+1] = b % 16
}
nibbles[l-1] = 16
return nibbles
}
func main() {
compact := []byte{0x20,0x13,0x34}
h := compactToHex(compact)
fmt.Printf("compactToHex(%x) -> %x\n", compact, h, )
}运行结果:
compactToHex(201334) -> 0103030410
Node 节点
node接口及node接口分四种实现:
fullNode 对应于分支节点,可以有多个子节点
shortNode 对应于扩展节点,只有一个子节点
valueNode 对应于叶子节点,没有子节点
hashNode 比较特殊,是fullNode和shortNode对象的RLP哈希值。没有子节点。
type node interface {
fstring(string) string
cache() (hashNode, bool)
canUnload(cachegen, cachelimit uint16) bool
}
type (
fullNode struct {
Children [17]node // Actual trie node data to encode/decode (needs custom encoder)
flags nodeFlag
}
shortNode struct {
Key []byte
Val node
flags nodeFlag
}
hashNode []byte
valueNode []byte
)- fullNode : 有一个node数组成员Children,该数组中保存的值为16进制的 0 ~ 9 和 a ~ f。
对于每个子节点,根据key值的第一位,就可挂载到Children数组的某个位置。
每个父节点最多有16个分支。
Children的第17位,用来保存fullNode的数据部分。
fullNode本身不再需要额外key变量。 - shortNode:成员Val指向一个子节点。
成员Key是一个字节数组。
shortNode 通过合并只有一个子节点的父节点和其子节点来缩短trie的深度。 - valueNode:保存了MPT结构中真正的数据部分的节点。
valueNode值为RLP哈希值,长度32byte。 - hashNode:是fullNode或者shortNode对象的RLP哈希值。
hashNode不会单独存在,而是以nodeFlag.hsah的形式存在,被fullNode和shortNode间接持有。
一旦fullNode或shortNode的成员变量发生任何变化,nodeFlag.hsah就一定会更新。
trie.insert(...) 和 trie.delete(...) 实现中除了新创建的fullNode、shortNode
Trie
trie的结构
db是后端的KV存储,trie的结构最终都是需要通过KV的形式存储到数据库里面去,然后启动的时候是需要从数据库里面加载的。root作为整个MPT的根节点。originalRoot 在创建trie对象时承接入参hashNode,通过这个hash值可以在数据库里面恢复出整颗的trie树。
cachegen字段指示了当前Trie树的cache时代,每次调用Commit操作的时候,会增加Trie树的cache时代,即cahegen自增1。
Trie每次Commit时node会被更新,默认是node.nodeFlag.gen = cachegen,如果node的gen会小于cachegen,当前的cachegen - cachelimit 大于node的gen,说明trie commit之后,node一直没有更新,那么node会从cache里面卸载,以便节约内存。 其实这就是缓存更新的LRU算法, 如果一个缓存在多久没有被使用,那么就从缓存里面移除,以节约内存空间。
// Trie is a Merkle Patricia Trie.
// The zero value is an empty trie with no database.
// Use New to create a trie that sits on top of a database.
//
// Trie is not safe for concurrent use.
type Trie struct {
db *Database
root node
// Cache generation values.
// cachegen increases by one with each commit operation.
// new nodes are tagged with the current generation and unloaded
// when their generation is older than than cachegen-cachelimit.
cachegen, cachelimit uint16
}Trie树的初始化
Trie树的初始化调用New函数,函数接受一个hash值和一个Database参数,
如果hash值不是空值的化,就说明是从数据库加载一个已经存在的Trie树, 就调用trei.resolveHash方法来加载整颗Trie树,
如果root是空,那么就新建一颗Trie树返回。
// New creates a trie with an existing root node from db.
//
// If root is the zero hash or the sha3 hash of an empty string, the
// trie is initially empty and does not require a database. Otherwise,
// New will panic if db is nil and returns a MissingNodeError if root does
// not exist in the database. Accessing the trie loads nodes from db on demand.
func New(root common.Hash, db *Database) (*Trie, error) {
if db == nil {
panic("trie.New called without a database")
}
trie := &Trie{
db: db,
}
if root != (common.Hash{}) && root != emptyRoot {
rootnode, err := trie.resolveHash(root[:], nil)
if err != nil {
return nil, err
}
trie.root = rootnode
}
return trie, nil
}Trie结构提供插入、删除、更新,所有节点改动的提交,以及返回整个MPT的哈希值。
- node 接口担当整个MPT中的各个节点。
- 任何一个k,v类型数据被插入,会以k字符串为路径沿着root向下延伸,在此次插入结束时首先会成为一个shortNode。
- k以自顶点root起到该节点此的 key路径形式存在。
MPT结构是不断变化的,原有节点可能会变化成其他node类型的节点,同时MPT中也会不断裂变或者合并出新的节点。
如:
// Update associates key with value in the trie. Subsequent calls to
// Get will return value. If value has length zero, any existing value
// is deleted from the trie and calls to Get will return nil.
//
// The value bytes must not be modified by the caller while they are
// stored in the trie.
func (t *Trie) Update(key, value []byte) {
if err := t.TryUpdate(key, value); err != nil {
log.Error(fmt.Sprintf("Unhandled trie error: %v", err))
}
}
// TryUpdate associates key with value in the trie. Subsequent calls to
// Get will return value. If value has length zero, any existing value
// is deleted from the trie and calls to Get will return nil.
//
// The value bytes must not be modified by the caller while they are
// stored in the trie.
//
// If a node was not found in the database, a MissingNodeError is returned.
func (t *Trie) TryUpdate(key, value []byte) error {
k := keybytesToHex(key)
if len(value) != 0 { // 插入节点
_, n, err := t.insert(t.root, nil, k, valueNode(value))
if err != nil {
return err
}
t.root = n
} else { // 如果 value 长度为0,删除节点
_, n, err := t.delete(t.root, nil, k)
if err != nil {
return err
}
t.root = n
}
return nil
}
例程: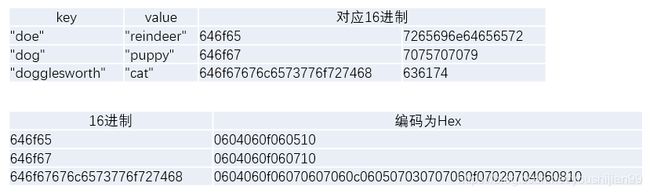
第一次insert: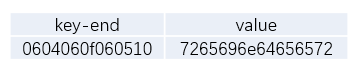
第二次insert: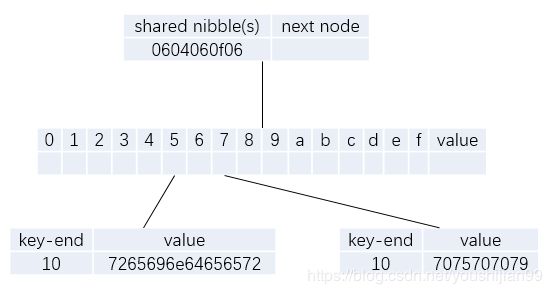
第三次insert: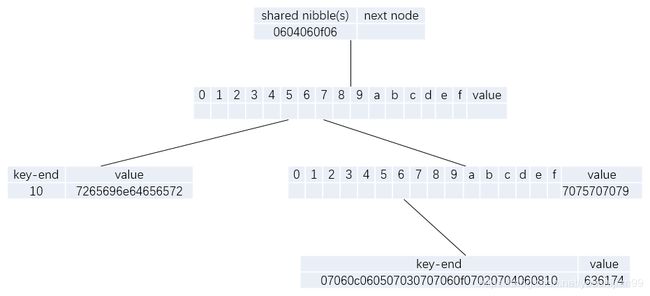
trie commit:
// Commit writes all nodes to the trie's memory database, tracking the internal
// and external (for account tries) references.
func (t *Trie) Commit(onleaf LeafCallback) (root common.Hash, err error) {
if t.db == nil {
panic("commit called on trie with nil database")
}
hash, cached, err := t.hashRoot(t.db, onleaf)
if err != nil {
return common.Hash{}, err
}
t.root = cached
t.cachegen++
return common.BytesToHash(hash.(hashNode)), nil
}func (t *Trie) hashRoot(db *Database, onleaf LeafCallback) (node, node, error) {
if t.root == nil {
return hashNode(emptyRoot.Bytes()), nil, nil
}
h := newHasher(t.cachegen, t.cachelimit, onleaf)
defer returnHasherToPool(h)
return h.hash(t.root, db, true)
}// hash collapses a node down into a hash node, also returning a copy of the
// original node initialized with the computed hash to replace the original one.
func (h *hasher) hash(n node, db *Database, force bool) (node, node, error) {
// If we're not storing the node, just hashing, use available cached data
if hash, dirty := n.cache(); hash != nil {
if db == nil {
return hash, n, nil
}
if n.canUnload(h.cachegen, h.cachelimit) {
// Unload the node from cache. All of its subnodes will have a lower or equal
// cache generation number.
cacheUnloadCounter.Inc(1)
return hash, hash, nil
}
if !dirty {
return hash, n, nil
}
}
// Trie not processed yet or needs storage, walk the children
collapsed, cached, err := h.hashChildren(n, db)
if err != nil {
return hashNode{}, n, err
}
hashed, err := h.store(collapsed, db, force)
if err != nil {
return hashNode{}, n, err
}
// Cache the hash of the node for later reuse and remove
// the dirty flag in commit mode. It's fine to assign these values directly
// without copying the node first because hashChildren copies it.
cachedHash, _ := hashed.(hashNode)
switch cn := cached.(type) {
case *shortNode:
cn.flags.hash = cachedHash
if db != nil {
cn.flags.dirty = false
}
case *fullNode:
cn.flags.hash = cachedHash
if db != nil {
cn.flags.dirty = false
}
}
return hashed, cached, nil
}// hashChildren replaces the children of a node with their hashes if the encoded
// size of the child is larger than a hash, returning the collapsed node as well
// as a replacement for the original node with the child hashes cached in.
// 把所有的子节点替换成它们的hash
func (h *hasher) hashChildren(original node, db *Database) (node, node, error) {
var err error
switch n := original.(type) {
case *shortNode:
// Hash the short node's child, caching the newly hashed subtree
// cached 接管了原来的Trie树的完整结构
// collapsed 把子节点替换成子节点的hash值
collapsed, cached := n.copy(), n.copy()
// collapsed.Key 从Hex编码 替换成 Compact编码
collapsed.Key = hexToCompact(n.Key)
// cached.Key 保留 n.Key 的拷贝
cached.Key = common.CopyBytes(n.Key)
// 递归调用 hash 方法,计算子节点的hash和cache,把子节点替换成子节点的hash值
if _, ok := n.Val.(valueNode); !ok {
collapsed.Val, cached.Val, err = h.hash(n.Val, db, false)
if err != nil {
return original, original, err
}
}
return collapsed, cached, nil
case *fullNode:
// Hash the full node's children, caching the newly hashed subtrees
// cached 接管了原来的Trie树的完整结构
// collapsed 把子节点替换成子节点的hash值
collapsed, cached := n.copy(), n.copy()
// 遍历每个字节点,把子节点替换成子节点的hash值
for i := 0; i < 16; i++ {
if n.Children[i] != nil {
collapsed.Children[i], cached.Children[i], err = h.hash(n.Children[i], db, false)
if err != nil {
return original, original, err
}
}
}
cached.Children[16] = n.Children[16]
return collapsed, cached, nil
default:
// Value and hash nodes don't have children so they're left as were
return n, original, nil
}
}
trie store:
rlp.Encode(&h.tmp, n) 对节点n进行编码,编码信息保存到h.tmp中。
hash = h.makeHashNode(h.tmp) 对RPL进行hash计算。
db.insert(hash, h.tmp, n) 将节点hash值,RLP编码,节点插入数据库
// store hashes the node n and if we have a storage layer specified, it writes
// the key/value pair to it and tracks any node->child references as well as any
// node->external trie references.
func (h *hasher) store(n node, db *Database, force bool) (node, error) {
// Don't store hashes or empty nodes.
if _, isHash := n.(hashNode); n == nil || isHash {
return n, nil
}
// Generate the RLP encoding of the node
h.tmp.Reset() // tmp 赋值为空
// 对 node进行RLP编码保存到h.tmp中
if err := rlp.Encode(&h.tmp, n); err != nil {
panic("encode error: " + err.Error())
}
if len(h.tmp) < 32 && !force {
// 小于32字节的节点存储在其父节点内
return n, nil // Nodes smaller than 32 bytes are stored inside their parent
}
// Larger nodes are replaced by their hash and stored in the database.
// RLP 做 sha hash
hash, _ := n.cache()
if hash == nil {
hash = h.makeHashNode(h.tmp)
}
if db != nil {
// We are pooling the trie nodes into an intermediate memory cache
// 字节数组转换成hash
hash := common.BytesToHash(hash)
// 插入数据库, key是node的RLP之后的hash值(即hashNode)
db.lock.Lock()
db.insert(hash, h.tmp, n)
db.lock.Unlock()
// Track external references from account->storage trie
if h.onleaf != nil {
switch n := n.(type) {
case *shortNode:
if child, ok := n.Val.(valueNode); ok {
h.onleaf(child, hash)
}
case *fullNode:
for i := 0; i < 16; i++ {
if child, ok := n.Children[i].(valueNode); ok {
h.onleaf(child, hash)
}
}
}
}
}
return hash, nil
}
https://www.jianshu.com/p/1e7455d00065
https://github.com/ZtesoftCS/go-ethereum-code-analysis/blob/master/trie%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90.md