论文解读:Towards Instance-level Image-to-Image Translation
论文题目:Towards Instance-level Image-to-Image Translation(CVPR2019)
项目地址:http://zhiqiangshen.com/projects/INIT/index.html
论文背景:

通过t-sne可视化,同一种颜色表示同一个域的全局style和实例style,可以看到即使是同一个域的图片,全局的style和实例的style仍具有差异,因此像MUNIT等直接用全局的style对图像迁移存在一定的问题;
论文主要贡献:该篇论文主要基于MUNIT主题结构,解决了实例级别的图像翻译问题,原始的MUNIT是全局翻译,对一幅图像迁移时只用到了一个style-code,在有些场景下对具体的物体效果不好;
例如:

其中第1、2、6列论文方法比MUNIT产生的输出更加多样化;其中第2列MUNIT用全局的style生成的不好,而该论文基于实例的风格迁移出很好的效果;第5、6、7列论文比MUNIT生成的细节更多,而第7列甚至有很逼真的反光;
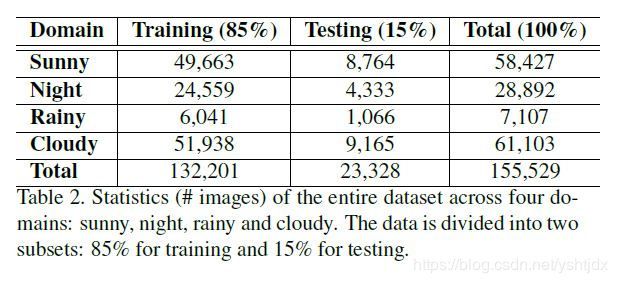
2、该论文开源了大规模的数据集,包含sunny, night, cloudy, rainy四种场景下的街景图片,共15万+的数据,有bbox级别的标注(car、person、traffic sign三种类别的标注),同时该数据集的数据都是unpaired;因此该数据集可以用来研究无监督的图像级别的图像翻译、无监督的实例级别的图像翻译、还可以用于研究多域的无监督图像翻译(例如stargan);
网络结构图:

论文主要在MUNIT结构上加入实例object分支,提取出三种类别的style,包括背景style、全局的style和实例object的style;在源域和目标域的style-content合成用的还是MUNIT的AdaIN结构;
同时在style和content合成是有一个corse-to-fine的过程:

即全局的style能过影响object的content和style的合成,但是反过来不行;也很容易理解,例如夜晚场景下,全局的style是黑色的夜晚场景影响car的style,但是具体的黄色的car对全局的style影响较小;
其余的跟MUNIT结构一样,cycle-consistency 的过程,也是分离content和style,然后交叉重建,自重建;注意自重建可能有两种,一种是输入一张图片,解耦图片的content和style,然后将content和style合成解码出原图;另一种是输入一张图片,解码成content和style,然后和目标域的content和style交叉重建(图像翻译),然后对翻译后的图像再次分离成content和style,再次交叉重建成原图,这个过程比第一种自重建多了一个过程;

实验结果:

评价指标:LPIPS、IS、CIS;LPIPS、IS衡量生成图片的多样性;CIS是MUNIT种提到的,衡量针对一张目标图片,生成的图片多样性,用于multimodel生成的多样性衡量;

通过对COCO2017训练测试检测和分割结果,证明合成图像有利于提高模型的鲁棒性;真实图片训练,测试种加入合成图片能提高性能,合成图片训练、测试种加入真实图片也能够提高性能;因为coco和该论文采集的数据很像,合成数据相当于对数据增强的数据,因此能提高性能;
this indicates that the distribution differences between original COCO and our synthetic images are not very huge.
It seems that our generation process is more likely to do photo-metric distortions or brightness adjustment of images, which can be regarded as a data augmentation technique and has been verified the effectiveness for object detection in [24].
但是有些情况下也会下降:
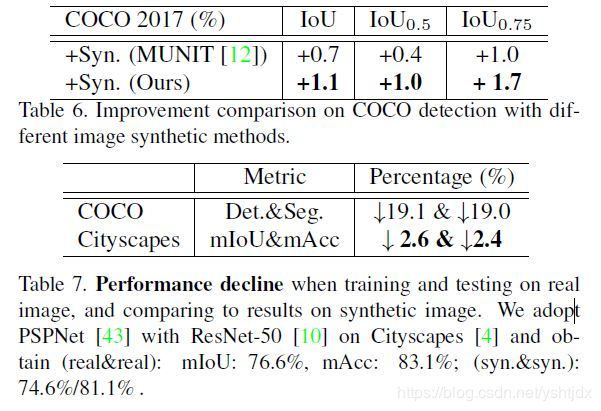
论文分析的原因:We further conduct scene parsing on Cityscapes [4].However, we didn’t see obvious improvement in this experiment.Using PSPNet [43] with ResNet-50 [10], we obtain mIoU: 76.6%, mAcc: 83.1% when training and testing on real images and 74.6%/81.1% on both synthetic images.We can see that the gaps between real and synthetic image are really small. We conjecture this case (no gain) is because the synthetic Cityscapes is too close to the original one. We compare the performance decline in Tab. 7. Since the metrics are different in COCO and Cityscapes, we use the relative percentage for comparison. The results indicate that the synthetic images may be more diverse for COCO since the decline is much smaller on Cityscapes.
其中论文Conditional Generative Adversarial Network for Structured Domain Adaptation种也提到生成多样性的数据比单一的数据增强效果要好;Beyond a substantial amount of synthetic data, the diversity of the scenes in the training images may mat-ter more than the number of the training samples.
效果图:
1、multimodel 输出:

2、与MUNIT的对比效果图:

Addition:
常用的图像翻译数据集比较:

本文开源的数据集详细情况: