了解open-falcon及组件
OpenFalcon是一款企业级、高可用、可扩展的开源监控解决方案。
Open-Falcon是一个比较大的分布式系统,有十几个组件。按照功能,这十几个组件可以划分为 基础组件、作图链路组件和报警链路组件。
特点
- 强大灵活的数据采集:自动发现,支持falcon-agent、snmp、支持用户主动push、用户自定义插件支持、opentsdb data model like(timestamp、endpoint、metric、key-value tags)
- 水平扩展能力:支持每个周期上亿次的数据采集、告警判定、历史数据存储和查询
- 高效率的告警策略管理:高效的portal、支持策略模板、模板继承和覆盖、多种告警方式、支持callback调用
- 人性化的告警设置:最大告警次数、告警级别、告警恢复通知、告警暂停、不同时段不同阈值、支持维护周期
- 高效率的graph组件:单机支撑200万metric的上报、归档、存储(周期为1分钟)
- 高效的历史数据query组件:采用rrdtool的数据归档策略,秒级返回上百个metric一年的历史数据
- dashboard:多维度的数据展示,用户自定义Screen
- 高可用:整个系统无核心单点,易运维,易部署,可水平扩展
- 开发语言: 整个系统的后端,全部golang编写,portal和dashboard使用python编写。
架构
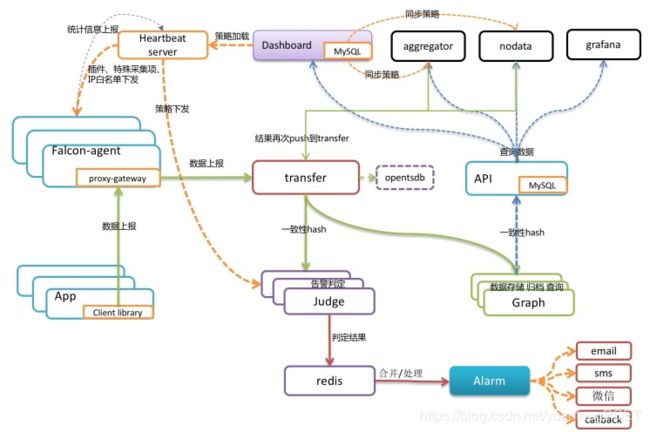
运作流程:
1、目标服务器运行agent
2、agent采集各类监控项数值,传给transfer
3、transfer校验和整理监控项数值,做一致性hash分片,传给对应的judge模块以验证是否触发告警
4、transfer整理监控项数值,做一致性hash分片,传输给graph以进行数据的存储
5、judge根据具体报警策略或阈值进行告警判断,如触发告警则组装告警event事件,写入缓存队列。
6、alarm和sender根据event事件中的判定结果,执行event,像用户组发送短信或邮件。
7、graph收到监控项数据后,将数据存储成RRD文件格式,进行归档,并提供查询接口。
8、query将调用graph的查询接口,将监控数据传送到dashboard以进行页面展示。
9、dashboard则渲染页面,展示曲线报表图等。
10、portal提供页面供用户配置机器分组、报警策略、表达式、nodata等配置。
组件
falcon-agent
agent用于采集机器负载监控指标,比如cpu.idle、load.1min、disk.io.util等等,每隔60秒push给Transfer。agent与Transfer建立了长连接,数据发送速度比较快,agent提供了一个http接口/v1/push用于接收用户手工push的一些数据,然后通过长连接迅速转发给Transfer。
transfer
transfer是数据转发服务。它接收agent上报的数据,然后按照哈希规则进行数据分片、并将分片后的数据分别push给graph&judge等组件。
Graph
graph是存储绘图数据的组件。graph组件 接收transfer组件推送上来的监控数据,同时处理api组件的查询请求、返回绘图数据。
API
api组件,提供统一的restAPI操作接口。比如:api组件接收查询请求,根据一致性哈希算法去相应的graph实例查询不同metric的数据,然后汇总拿到的数据,最后统一返回给用户。
dashboard
dashboard首页,用户可以以多个维度来搜索endpoint列表,即可以根据上报的tags来搜索关联的endpoint。
HBS(Heartbeat)
心跳服务器,公司所有agent都会连到HBS,每分钟发一次心跳请求。
HBS功能:
1、agent发送心跳信息给HBS的时候,会把hostname,ip,agent version,plugin version等信息告诉HBS,HBS负责更新host表。
2、从mysql中读取所有主机/分组/模板/告警/策略等信息,一次性加载到内存
Judge需要获取所有的报警策略,让Judge去读取Portal的DB么?不太好。因为Judge的实例数目比较多,如果公司有几十万机器,Judge实例数目可能会是几百个,几百个Judge实例去访问Portal数据库,也是一个比较大的压力。既然HBS无论如何都要访问Portal的数据库了,那就让HBS去获取所有的报警策略缓存在内存里,然后Judge去向HBS请求。这样一来,对Portal DB的压力就会大大减小。
judge
Judge用于告警判断,agent将数据push给Transfer,Transfer不但会转发给Graph组件来绘图,还会转发给Judge用于判断是否触发告警。
设计初衷:
因为监控系统数据量比较大,一台机器显然是搞不定的,所以必须要有个数据分片方案。Transfer通过一致性哈希来分片,每个Judge就只需要处理一小部分数据就可以了。所以判断告警的功能不能放在直接的数据接收端:Transfer,而应该放到Transfer后面的组件里。
Alarm
alarm模块是处理报警event的,judge产生的报警event写入redis,alarm从redis读取处理,并进行不同渠道的发送。
设计初衷:
在配置报警策略的时候配置了报警级别,比如P0/P1/P2等等,每个及别的报警都会对应不同的redis队列 alarm去读取这个数据的时候我们希望先读取P0的数据,再读取P1的数据,最后读取P5的数据,因为我们希望先处理优先级高的。于是:用了redis的brpop指令。
已经发送的告警信息,alarm会写入MySQL中保存,这样用户就可以在dashboard中查阅历史报警,同时针对同一个策略发出的多条报警,在MySQL存储的时候,会聚类;历史报警保存的周期,是可配置的,默认为7天。
Task
task是监控系统一个必要的辅助模块。定时任务,实现了如下几个功能:
- index更新。包括图表索引的全量更新 和 垃圾索引清理。
- falcon服务组件的自身状态数据采集。定时任务了采集了transfer、graph、task这三个服务的内部状态数据。
- falcon自检控任务。
Gateway
Nodata
nodata用于检测监控数据的上报异常。nodata和实时报警judge模块协同工作,过程为: 配置了nodata的采集项超时未上报数据,nodata生成一条默认的模拟数据;用户配置相应的报警策略,收到mock数据就产生报警。采集项上报异常检测,作为judge模块的一个必要补充,能够使judge的实时报警功能更加可靠、完善。
Aggregator
集群聚合模块。聚合某集群下的所有机器的某个指标的值,提供一种集群视角的监控体验。