JVM——8.调优工具1(jstat)
文章目录
- 1. 使用背景
- 2. jstat 的介绍及使用
-
- 2.1 jstat -gc PID 介绍
- 2.2 其他的 jstat命令
- 2.3 jstat -gc PID 使用
- 3. 关注指标及计算分析
-
- 3.1 关注指标
- 3.2 计算分析
1. 使用背景
一般来说,中大型公司都会有自己的应用监控系统,比如开源的 Zabbix、Open-Falcon、Prometheus等,也可能一些公司自己实现了监控或者告警系统;这些系统可以监控所有在线上的各种应用的运行情况,一旦发生异常(比如CPU利用率过高、FullGC频繁等)会直接通过短信、邮箱或者IM工具发送告警给管理员。
但是对于开发人员来说,并不应该依赖这些监控系统;熟练的使用各种命令行工具,在命令行中就能实现问题的发现定位及解决,是一个优秀工程师的必备技能。
所以我们需要掌握一些简单易用,且高效实用的命令行jvm监控工具,来让我们日常的开发和解决问题更加高效。
2. jstat 的介绍及使用
jstat 就是JDK中自动的一个非常有用的命令,它可以展示出当前运行系统的JVM的Eden、Survivor、老年代等的内存使用情况,还能展示出Young CG、Full GC等的执行情况及耗时。
通过这些指标,我们就可以轻松的分析出当前系统的运行情况、GC情况、内存分配是否合理等。
2.1 jstat -gc PID 介绍
在服务器上执行jps(不懂的自行百度)命令,就可以看到当前服务器中正在运行的java进程,每个进程前面会有一个进程ID,也就是这里的PID。
然后使用这个PID来执行 jstat -gc PID命令:
jstat -gc PID: 只能得到当前系统运行情况的一行指标;
jstat -gc PID 1000 10:每1000毫秒(1秒)执行一次,共执行10次;
jstat -gc PID 1000:每秒执行一次,一直不停的执行;
示例:

- S0C:From Survivor区的大小;
- S1C:To Survivor区的大小;
- S0U:From Survivor区当前使用的内存大小;
- S1U:To Survivor区当前使用的内存大小;
- EC:Eden区的大小;
- EU:Eden区当前使用的内存大小;
- OC:老年代的大小;
- OU:老年代当前使用的内存大小;
- MC:方法区(永久代、元数据区)的大小;
- MU:方法区(永久代、元数据区)的当前使用的内存大小;
- YGC:系统运行迄今为止的Young GC次数;
- YGCT:Young GC的耗时;
- FGC:系统运行迄今为止的Full GC次数;
- FGCT:Full GC的耗时;
- CGC:Concurrent GC的次数;(JDK11)
- CGCT:Concurrent GC的耗时;(JDK11)
- GCT:所有GC的总耗时;
到这里,如果JVM基础好一点的同学,你应该能够发现:根据这些指标,我们就能完成JVM的各项监控了;
这个命令也是 最完整、最常用和最实用的jstat的命令。
2.2 其他的 jstat命令
- jstat -gccapacity PID:堆内存分析;
- jstat -gcnew PID:年轻代GC分析;(TT和MTT:对象在年轻代存活的年龄和存活的最大年龄)
- jstat -gcnewcapacity PID:年轻代内存分析;
- jstat -gcold PID:老年代GC分析;
- jstat -gcoldcapacity PID:老年代内存分析;
- jstat -gcmetacapacity PID:元数据区内存分析;
这些命令一看也就知道,是分别针对单独的某个区域进行分析和统计的,可以都自己使用看看。
2.3 jstat -gc PID 使用
首先用一段代码来进行GC的模拟:
/**
* jvm options:
* -Xms20m -Xmx20m -Xmn5m -XX:SurvivorRatio=8 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC
*/
public class JstatDemo {
public static void main(String[] args) throws InterruptedException {
TimeUnit.SECONDS.sleep(15); // 便于等待执行jps, jstat命令...
for (int i = 0; i < 10; i++) {
call();
}
}
private static void call() throws InterruptedException {
List<byte[]> list = new ArrayList<>();
for (int j = 0; j < 4; j++) {
list.add(new byte[1024 * 1024]);
TimeUnit.SECONDS.sleep(1);
}
}
}
注意代码上面的jvm参数:堆空间20m,新生代5m(按比例Eden区4m),老年代15m。
按照预想,代码的执行情况应该为:
在 call()方法的for循环中,每秒生成1m对象,由于Eden区是4m,则在生成第4m对象的时候,应该发生 Young GC;(则每第4秒发生一次YGC)
并且使用了list引用生成的对象,使得它们此时并不是垃圾对象,不会直接被GC掉;
而Survivor区只有0.5m,肯定是不够存放Young GC后存活的3M对象的,所以此时这3M对象会通过分配担保进入到老年代;
老年代的大小为15m,但是空间分配担保有特定的比较规则(不知道的可以看看前面的文章),所以不会等到老年代真正快要满的时候才发生 Full GC;有可能在使用10m左右,甚至一半的时候就发生Full GC;(发生Full GC时,list都成为了垃圾对象,可以被回收)
理想情况下,假设按照10m发生Full GC计算,,每3秒会有3M对象进入老年代,则在第四次进入老年代的时候,老年代空间不够,发生Full GC;此时应该是第15秒(从第一次进入老年代开始计算,此时新生代中已经消耗了3秒);
后面则应该每12秒,老年代发生一次Full GC;
当然这些都是很理想的情况,实际中会受机器性能,JDK版本等多种因素影响,导致执行情况跟理想情况有差别。
执行情况:
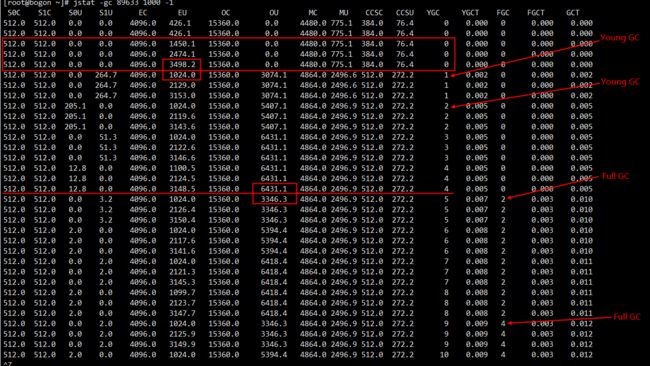
- 第3行:代码正式开始执行;
- 可以看到EU列也就是Eden区是以每秒增大1M的速率进行分配的;
- 第6行:EU列由 3498变成了1024;
- 就是上面说的Eden区大小为4m,经过3秒后使用了3m,再继续时放不下了,发生YGC;再看YGC列由0变为了1;
- 并且OU列由 0变成了3074,则是通过分配担保进入到老年代的3M对象;
- 第9行:第2个3秒,再次发生YGC,YGC列由1变成了2;
- OU列由 3074变成了5407;(这里没有按我们预想的进行晋升,预想的这里该又晋升3m,不过不影响jstat的分析)
- 第18行:第5个3秒,再次发生YGC,YGC列由4变成了5;
- OU列由6431变成了3346,也就是发生了Full GC,回收了老年代的对象;(这里也没有按我们预想的10m左右才回收,不过不影响jstat的分析)
- FGC列由0变成了2,这里也是直接就发生了2次 FGC…
- 第31行:第9个3秒,再次发生FGC,FGC列由2变成了4;
这里也看到了,真正的执行情况跟逻辑分析的情况有不小的出入。
3. 关注指标及计算分析
3.1 关注指标
一个运行在线上的应用系统,对于JVM方面我们需要关注的是它的什么呢?我觉得是以下几类指标:
- 对象的增长速率(每秒或者每分钟生成多大内存的对象);
- Young GC 的发生频率 和耗时;
- 每次 Young GC之后,有多少对象能够存活;
- 每次 Young GC之后,有多少对象进入了老年代;
- 老年代对象增长的速率;
- Full GC 的发生频率 和耗时;
3.2 计算分析
那我们如何运用 jstat这个命令来得到这些指标呢?
- 对象的增长速率:
- 解释:这个指标,也是我们平时对于jvm第一个要了解的东西,也就是随着系统运行,每秒会在新生代的Eden区分配多少对象;
- 测算:执行
jstat -gc PID 1000 10命令;- 假设第一秒统计信息里展示Eden区使用了200M,第二秒展示Eden区使用了210M,第三秒展示使用了219M…
- 以此类推,就可以大概推算出来,当前系统每秒新增 10M 左右的对象;
- 这里也可以根据自己的系统灵活调整使用,比如系统负载很低,不一定每秒都有请求,就可以把上面的1秒改成1分钟,甚至10分钟等;然后统计系统1分钟或者10分钟大概增长多少对象;
- 另外就是,系统可能存在高峰期和日常期两种状态,也得分开进行统计;
- Young GC 的发生频率 和耗时:
- 解释:其实在知道了对象的增长速率的情况下,根据你设定的Eden区内存大小,可以很容易推算出来多久发生一次Young GC;
- 比如你的Eden区大小为800M,然后每秒生成10M的对象,那么就大概在80s左右会发生一次Young GC;
- 测算:当然我们也可以通过 执行
jstat -gc PID 1000命令进行真实测算;- 只需要观察 YGC列每多少秒新增1次,也就知道真实多少秒发生一次Young GC了;
- 对于Young GC的平均耗时:在YGC列的后面一列 YGCT中,展示的是发生了当前次数YGC的总耗时;
比如系统运行了24小时之后,发生了100次YGC,总耗时YGCT为200ms,则平均下来每次Young GC大概耗时就2毫秒左右; - 也就是说你的系统,每次Young GC会导致停顿2毫秒(可以忽略不计);
- 解释:其实在知道了对象的增长速率的情况下,根据你设定的Eden区内存大小,可以很容易推算出来多久发生一次Young GC;
- 每次 Young GC之后,有多少对象能够存活 和进入老年代:
- 解释:对于每次Young GC后有多少对象能够存活,我们是没法直接看出来的,但是可以进行推算;
- 之前我们已经测试出来了,大概80s左右发生一次Young GC;
- 测算:那我们此时执行
jstat -gc PID 80000 10,每80秒执行一次,连续执行10次;- 这个时候就可以观测到,每隔80秒发生了一次Young GC后,此时 Eden区、Survivor区、老年代的对象变化;
- 比如 800M的Eden区,在发生了Young GC之后,正常情况下Eden区肯定对象很少了,比如剩几十M(新生成的);
但是对于存活的对象,要么进入Survivor区,要么进入老年代; - 有多少对象进入老年代:我们可以通过 OU列的大小变化,知道每次Young GC后进入老年代的对象大小;比如有 10M对象进入老年代;
- 老年代对象增长的速率:每80s发生一次Young GC,有10M对象进入了老年代,也就是说 老年代的对象增长速率为 每80秒10M;
- 有多少对象存活:并且通过 S1U列的大小变化,知道每次Young GC后进入 Survivor区的对象大小;-> 这样也就能得出每次Young GC之后存活的对象大小(进入老年代 + Survivor区);
- 另外,老年代的对象是不应该不停的快速增长的,甚至在正常运行情况下,极少的增长;因为普通系统没有那么多长期存活的对象,只要新生代内存分配合理,老年代的对象增长会很少的;
- 解释:对于每次Young GC后有多少对象能够存活,我们是没法直接看出来的,但是可以进行推算;
- Full GC 的发生频率 和耗时:
- 解释:跟Young GC的发生频率和耗时一样,在知道了老年代对象的增长速率的情况下,根据你设定的老年代内存大小,也可以很容易推算出多久发生一次Full GC;
- 比如老年代大小也为800M,然后每80s有10M对象进入老年代,那么就是6400s也就是接近2小时左右发生一次Full GC;
- 对于Full GC的平均耗时,也一样可以通过FGC列的后面一列 FGCT,也就是发生了当前次数的FGC的总耗时计算出来;
- 比如一共执行了 10次 FGC,总耗时为2s,也就是说 每次Full GC大概需要耗时 0.2s 左右;
- 解释:跟Young GC的发生频率和耗时一样,在知道了老年代对象的增长速率的情况下,根据你设定的老年代内存大小,也可以很容易推算出多久发生一次Full GC;
对于这些指标的获取与分析,都可以使用 jstat这个命令实现;并且结合jvm的运行原理,可以比较容易的掌握到线上系统的jvm的运行情况,也可以对于jvm的具体运行情况进行针对性的优化。