这就是神经网络 1:早期分类网络之LeNet-5、AlexNet、ZFNet、OverFeat、VGG
概述
本系列文章计划介绍总结经典的神经网络结构,先介绍分类网络,后续会包括通用物体检测、语义分割,然后扩展到一些相对较细的领域如人脸检测、行人检测、行人重识别、姿态估计、文本检测等。
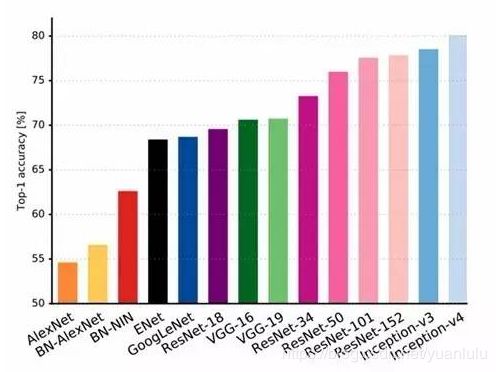
一些经典网络的年代、性能及参数趋势如下表所示:

LeNet-5 (1998)
LeNet-5来自Yann LeCun在1998年的论文,这个网络用于识别手写数字。作者有个很出名的数据集MNIST,也是本论文用到的。
网络结构如下:

LeNet-5网络是针对灰度图进行训练的,输入图像大小为32*32*1,不包含输入层的情况下共有7层,每层都包含可训练参数(连接权重)。可以看到,卷积神经网络的基本框架已经有了,卷积、激活、池化和全连接,这几个基本组件都完备了。

可训练参数共有61706个,大部分都集中在全连接层。
使用数据增强技术之后,在MNIST数据集上的测试错误率为0.8%。
模型特征:
- 卷积网络使用一个三层的序列:卷积、池化、非线性。这个三个特性奠定了后续深度学习的基础。
- 局部感知。使用卷积提取局部特征。人对外界的认知是从局部到全局的,相邻局部的像素联系较为紧密。每个神经元没必要对全局图像进行感知,只需要对局部进行感知,然后更高层将局部的信息综合起来得到全局的信息。
- 参数共享。每个卷积核都是一种提取特征的方式,大大降低了参数的数目。
- 使用平均池化降采样。
- 使用多层神经网络(MLP)作为最终的分类器
AlexNet(2012)
ILSVRC2012冠军,展现出了深度CNN在图像任务上的惊人表现,掀起CNN研究的热潮,是如今深度学习和AI迅猛发展的重要原因。ImageNet比赛为一直研究神经网络的Hinton提供了施展平台,AlexNet就是由hinton和他的两位学生发表的,在AlexNet之前,深度学习已经沉寂了很久。
ImageNet Top5 错误率:16.4%,而两年前非深度学习的方法的最好错误率是28.2%。
AlexNet结构如下:

AlexNet 使用 3GB 显存的 GTX 580 显卡(好古老),一块显卡不够用,所以如上图所示将模型分为两部分放到了两块显卡上并行运算。
上述是论文里的结构图,画的有残缺,我找了一个相对完整的图,如下:

吴恩达课程里的插图(没有区分两块显卡):

详细结构请参考《[caffe]深度学习之图像分类模型AlexNet解读》
网络结构可分为以下三种模块:

AlexNet网络共有:卷积层 5个,池化层 3个,全连接层3个(其中包含输出层), 最终输出1000个分类。前两层卷积就是上图左边的结构,中间三层卷积就是上图中间的部分,两个全连接层就是上图右边的部分。最有是一个softmax输出层。
参数大约有6000万(计算方法参考《AlexNet中的参数数量》),参数大部分集中在后面的全连接层。
AlexNet的主要特点:
- 使用ReLU作为非线性激活函数,解决了simmoid在网络较深时的梯度弥散问题。
- 全连接层使用dropout技术选择性忽略训练中的单个神经元,避免过拟合
- 使用重叠最大池化,避免平均池化的模糊效果。
- 使用多GPU训练,大大加快了训练速度
- 提出了局部响应归一化LRN(Local Response Normalization),虽然后来证明作用不大,逐渐让位于BatchNorm
- 数据增强。随机从256*256数据中截取224*224大小的区域(以及水平翻转的镜像),大大减轻过拟合,增强泛化能力。
ZFNet(2013)
ZFNet是2013年做的比较好的一个(第三名),但并不是冠军,现在去查imagenet网站,2013年分类的冠军是Clarifai,但是这个网络没看到相关论文。
ZFNet的Z和F指的是Zeiler和Fergus,曾是hinton的学生,后在纽约大学读博的Zeiler,联手纽约大学研究神经网络的Fergus提出了ZFNet。Zeiler是Clarifai的创建者和CEO。所以,都算是一家人吧。
网络结构类似于AlexNet,卷积核的大小减小。
图像预处理和训练过程中的参数设置也和AlexNet很像。

手动计算了一下,该网络的参数量大约6232万,与原版的AlexNet相差不大。作者的单个模型(conv1 11 -> 7,4 -> 2)和AlexNet单个模型进行比较,top-5 error 降低了1.7%,证明了这样改进的正向效果。
该论文是在AlexNet基础上进行了一些细节的改动,网络结构上并没有太大的突破。该论文最大的贡献在于通过使用可视化技术揭示了神经网络各层到底在干什么,起到了什么作用。作者使用一个多层的反卷积网络来可视化训练过程中特征的演化及发现潜在的问题;同时根据遮挡图像局部对分类结果的影响来探讨对分类任务而言到底那部分输入信息更重要。
通过可视化发现AlexNet第一层中有大量的高频和低频信息的混合,却几乎没有覆盖到中间的频率信息;且第二层中由于第一层卷积用的步长为4太大了,导致了有非常多的混叠情况;因此改变了AlexNet的第一层即将滤波器的大小11x11变成7x7(提取更多的底层特征),并且将步长4变成了2。增加第二层卷积的步长stride(1->2),从而取得到了和AlexNei基本相同的感知野,featureMap的大小相同,后面的卷积计算量也保持不变。
一些其它结论
特征不变性
一般来说,小的变化对于模型的第一层都有非常大的影响,但对于最高层的影响却几乎没有。对于图像的平移、尺度、旋转的变化来说,网络的输出对于平移和尺度变化都是稳定的,但却不具有旋转不变性,除非目标图像时旋转对称的。
遮挡实验
整个模型它自己清楚目标在图像中的具体位置吗? 如果图像中的目标被遮挡,那么被正确分类的概率会显著降低,这表明这种可视化与激发特征图的图像结构是真正对应上的。遮挡实验说明图像的关键区域被遮挡之后对分类性能有很大的影响,说明分类过程中模型明确定位出了场景中的物体。
一致性分析
不同图像的指定目标局部块之间是否存在一致性的关联,作者认为深度模型可能默认学习到了这种关联关系。
训练过程中的特征演化
低层特征经过较少epoch的训练过程之后就学习的比较稳定了,层数越高越需要更多的epoch进行训练。因此需要足够多的epoch过程来保证顺利的模型收敛。
特征可视化
通过对各层卷积核学习到的特征进行可视化发现神经网络学习到的特征存在层级结构。第二层是学习到边缘和角点检测器,第三层学习到了一些纹理特征,第四层学习到了对于指定类别图像的一些不变性的特征,例如狗脸、鸟腿,第五层得到了目标更显著的特征并且获取了位置变化信息。

结构调整
删除模型的两个卷积层或者两个全连接层,对分类结果影响不大,但是全部删除四层,效果下降很多,说明了模型层数很关键。单独改变全连接层的尺寸,对分类结果影响不大,但增大中间卷积层的尺寸对分类结果有正向的提高,同时增大卷积层和全连接层的尺寸造成了过拟合。
迁移学习
使用ImageNet预训练的模型用到其他数据集上也取得了很好的效果,说明了fine-tuning的价值。
总结
ZFNet最大的贡献是对于很多深度学习的底层理论的探索。让深度学习不再那么黑盒化。
OverFeat(2013)
本文是纽约大学Yann LeCun团队中Pierre Sermanet ,David Eigen和张翔等在14年发表的一篇论文,本文改进了Alex-net,并用图像缩放和滑窗方法在test数据集上测试网络;提出了一种图像定位的方法;最后通过一个卷积网络来同时进行分类,定位和检测三个计算机视觉任务,并在ILSVRC2013中获得了很好的结果。本网络在定位和检测上得到了第一,在分类上比ZFNet差了一点点。
文献中的OverFeat就是特征提取算子,因为作者把前五层网络用于生成特征,给分类、定位和检测任务共用。本文暂不探讨定位和检测的部分,只关注分类。
AlexNet测试的时候从图片的5个指定的方位(上下左右+中间)进行裁剪出5张224*224大小的图片,然后水平镜像一下再裁剪5张,这样总共有10张;然后我们把这10张裁剪图片分别送入已经训练好的CNN中,分别预测结果,最后用这10个结果的平均作为最后的输出。
这样的裁剪方式,把图片的很多区域都给忽略了,说不定这样的裁剪刚好把图片物体的一部分给裁剪掉了;另外一方面,裁剪窗口重叠存在很多冗余的计算,像上面我们要分别把10张图片送入网络,可见测试阶段的计算量还是蛮大的。
Overfeat算法在测试阶段不再是用一张221*221大小的图片了作为网络的输入,而是用了6张大小都不相同的图片,也就是所谓的多尺度输入预测,如下表格所示:

我们知道卷积计算是不限制图片大小的,只有全连接层要求固定大小。为了让一个已经设计完毕的网络,也可以输入任意大小的图片,需要用到FCN(Fully Convolutional Networks),它的精髓是:
- 把卷积层 -> 全连接层,看成是对一整张图片的卷积层运算。
- 把全连接层 -> 全连接层,看成是采用1*1大小的卷积核,进行卷积层运算。
举个例子:

- 传统的CNN:如果从以前的角度进行理解的话,那么这个过程就是全连接层,我们会把这个5*5大小的图片,展平成为一个一维的向量,进行计算。
- FCN :FCN并不是把5*5的图片展平成一维向量,再进行计算,而是直接采用5*5的卷积核,对一整张图片进行卷积运算。
其实这两个本质上是相同的,只是角度不同。
如果输入是16*16大小的图片,那么会是什么样的结果?具体请看下图:

网络最后的输出是一张2*2大小的图片。同时需要注意的是网络最后输出的图片大小是一个与输入图片大小息息相关的一张图片,输出特征图的每个值与图片的一个子区域对应(相当于滑窗了)。由于只计算了一次,相比裁剪成小图片分开计算,节省了中间部分多次计算的麻烦。
AlexNet有1000个输出,每个输出对应一个分类。OverFeat测试的图片分辨率都大于221*221,每个分类有多个输出,同时,对于卷积层层到全连接层,作者使用了offset max-pooling来丰富特征图的视角。在一个尺寸下取得每个分类的多个概率之后,通过全局最大池化就可以转为1x1个分类特征。然后在所有尺寸上进行投票获得最终的分类。
论文设计了两个版本的网络结构,一个快速版,一个高精度版。下面是高精度版的结构:
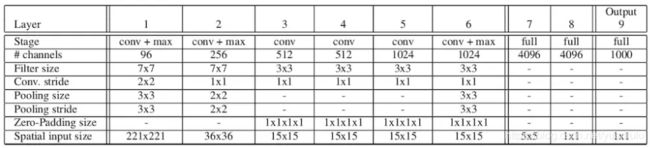
高精度版相对AlexNet有以下改进:
1,不使用LRN (Local Response Normalization);
2,不使用over-pooling使用普通pooling,更大的pooling间隔S=2或3;
3,第一个卷基层的间隔从4变为2(accurate 模型),卷积大小从11*11变为7*7;第二个卷基层filter从5*5升为7*7;
4,增加了一个第三层,是的卷积层变为6层;从Alex-net的384→384→256;变为512→512→1024→1024。
OverFeat两个版本的参数量都在1.44亿左右,约一亿参数都是第一层全连接产生的。高精度版本的计算量相对更大。
从测试结果来看,所尺度和多视角有一定的正向作用,但是作用不是很大:

上图中红框内的部分,同样的网络结构,使用AlexNet裁剪的方式和OverFeat的多尺度方法分别测试,top5的错误率只低了一点点,top1错误率还高了。这也许能解释为啥OverFeat没能在分类单项中夺冠。
总结
OverFeat更大的意义是将前五层网络在分类训练后固定下来,作为定位和检测任务的特征提取层,充分验证了深度卷积网络的抽象能力。在特征图后面加入bbox回归网络,也是后续物体检测的通用做法。同时本网络使用FCN对多尺度的探索启发了后来的不少论文。
Overfeat和ZFNet不约而同的减小AlexNet的卷积核大小,减小stride,这说明了这个方向的正确性。
VGG(2014)
VGGNet是牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发的深度卷积神经网络。该网络赢得了ILSVR(ImageNet)2014定位任务的冠军(Winner),分类任务的亚军(runner-up)。
该网络主要用于探索网络深度的影响。特点在于结构规整,通过反复堆叠3x3的卷积,卷积核数量逐渐加倍来加深网络,后续的很多CNN结构都采用了这种3x3卷积思想。和AlexNet一样,头两个全连接层后面加0.5的dropout。
实际上VGG不是一个网络,而是一组网络,如下:

可以看到,共有从A到E的6个网络,网络参数量在1.4亿左右。前4个主要用于验证作者的一些想法,真正效果好并用于比赛的是最后两个,也就是常说的VGG-16和VGG-19。
吴恩达课程里对VGG-16的结构图,应该更清晰:

请注意,最后三层虽然是全连接层,却是像OverFeat一样用全卷积(FCN)实现的。这样就可以在多尺度上对图像进行训练和测试,作者文章里有对此的详细描述。
作者通过测试对比逐渐加深的网络结构,有一些很有用的结论:
- 网络加深真的是有用的,否则作者也不会选深度最深的两个参赛。但是比VGG-19更深的网络应该不会很好,因为作者测试的VGG-19只比VGG-16好了一点点,可能已经开始过拟合了,所以才没有把网络加的更深(深度的问题要等ResNet去解决)。
- 使用较小的卷积核堆叠起来,可以获得相同的感受野,参数却少了很多,并获得了更多的非线性。比如通过两层3*3串联的效果相当于5*5,三层3*3串联相当于7*7。作者做了实验,将两层3*3换成5*5,效果变差了。
- LRN没啥作用。看上面图标,A配置和和A-LRN比没大区别,好了0.1%而已,所以后面几个网络就不用LRN了。
- 1*1卷积可以增加非线性,对测试结果是正向的。配置C相比B就增加了三层1*1。但是这种效果没有增加三层3*3效果好,因为3*3有更多的上下文信息。
- 数据增强。得益于FCN对图像尺寸的灵活性,作者在测试和训练中使用了不同的尺寸,最终发现,通过把图片在一定范围内随机变化(作者称之为尺度抖动)来训练,并在3个不同尺寸下测试能获得很好的效果。作者发现最好的结果是把多尺度抖动和多次裁剪结合起来求平均。
论文
LeNet-5: Gradient-based learning applied to document recognition
LeNet-5网站:http://yann.lecun.com/exdb/lenet/
ALexNet:ImageNet Classification with Deep Convolutional
Neural Networks
AlexNet论文翻译——中文版
ZFNet:Visualizing and Understanding Convolutional Networks
OverFeat OverFeat:
Integrated Recognition, Localization and Detection
using Convolutional Networks
VGG: Very Deep Convolutional Networks for Large-Scale Image Recognition
VGG论文翻译——中文版
参考资料
本文撰写过程参考了下列文章,在此感谢。
ImageNet历年冠军和相关CNN模型
深度学习——卷积神经网络的经典网络
常见卷积网络结构
详解计算机视觉五大技术:图像分类、对象检测、目标跟踪、语义分割和实例分割
论文笔记:CNN经典结构1(AlexNet,ZFNet,OverFeat,VGG,GoogleNet,ResNet)
ImageNet 历届冠军架构最新评析:哪个深度学习网络最适合你
[caffe]深度学习之图像分类模型AlexNet解读
AlexNet中的参数数量
ZFNet论文学习
深度学习之可视化ZFNet-解卷积
深度学习(二十)基于Overfeat的图片分类、定位、检测
基于OverFeat的图像分类、定位、检测