python基础知识整理
1.列表去重
#方法一
def delList(L):
L1 = [ ]
for i in L:
if i not in L1:
L1.append(i)
return L1
print(delList(L1))
#方法二:去重
L1=list(set(L))
#a = [2,2,2,2,6,84,5,9]
#print(delList(a))
#a2 = list(set(a))
#print(a2)
2.Python中如何拷贝一个对象
1).浅拷贝:
使用copy.copy,它可以进行对象的浅拷贝(shallow copy),它复制了对象,但对于对象中的元素,依然使用引用(换句话说修改拷贝对象元素,则被拷贝对象元素也被修改)
2).深拷贝:
使用copy.deepcopy,它可以进行深拷贝,不仅拷贝了对象,同时也拷贝了对象中的元素,获得了全新的对象,与被拷贝对象完全独立,但这需要牺牲一定的时间和空间。
3).特殊拷贝:
如要复制列表L,使用list(L),要复制一个字典d,使用dict(d),要复制一个集合s,使用set(s)。
总结一下的话:如果你要复制某个对象object, 它属于python内建的类型type,那么你可以使用type(object)来 获得一个拷贝。
4) 举例:
import copy
list = [1, 2, 3, 4, ['a', 'b']] #原始对象
b = list #赋值,传对象的引用,依然指向list
c = copy.copy(list) #对象拷贝,浅拷贝(元素依然是共享的引用)
d = copy.deepcopy(list) #对象拷贝,深拷贝
list.append(5) #修改对象list
list[4].append('c') #修改对象list中的['a', 'b']数组对象
print ('list = ', list)
print ('b = ', b)
print ('c = ', c)
print ('d = ', d)
#输出结果:
list = [1, 2, 3, 4, ['a', 'b', 'c'], 5]
b = [1, 2, 3, 4, ['a', 'b', 'c'], 5]
c = [1, 2, 3, 4, ['a', 'b', 'c']]
d = [1, 2, 3, 4, ['a', 'b']]
3.赋值、深拷贝与浅拷贝的区别
一、赋值
在 Python 中,对象的赋值就是简单的对象引用,这点和 C++不同,如下所示:
a = [1,2,"hello",['python', 'C++']]
b = a
在上述情况下,a 和 b 是一样的,他们指向同一片内存,b 不过是 a 的别名,是引用。我们可以使用bisa去判断,返回 True,表明他们地址相同,内容相同,也可以使用 id()函数来查看两个列表的地址是否相同。赋值操作(包括对象作为参数、返回值)不会开辟新的内存空间,它只是复制了对象的引用。也就是说除了 b 这个名字之外,没有其他的内存开销。修改了 a,也就影响了 b,同理,修改了 b,也就影响了 a。
二、浅拷贝(shallow copy)
浅拷贝会创建新对象,其内容非原对象本身的引用,而是原对象内第一层对象的引用。
浅拷贝有三种形式:
切片操作
工厂函数
copy 模块中的 copy 函数
比如上述的列表 a;
b = a[:] 或者 b = [x for x in a] #切片操作
b = list(a) #工厂函数
b = copy.copy(a) #copy函数
浅拷贝产生的列表 b 不再是列表 a 了,使用 is 判断可以发现他们不是同一个对象,使用 id 查看,他们也不指向同一片内存空间。但是当我们使用 id(x) for x in a 和 id(x) for x in b 来查看 a 和 b 中元素的地址时,可以看到二者包含的元素的地址是相同的。在这种情况下,列表 a 和 b 是不同的对象,修改列表 b 理论上不会影响到列表 a。但是要注意的是,浅拷贝之所以称之为浅拷贝,是它仅仅只拷贝了一层,在列表 a 中有一个嵌套的list,如果我们修改了它,情况就不一样了。
比如:
a[3].append('java')
查看列表 b,会发现列表 b 也发生了变化,这是因为,我们修改了嵌套的 list,修改外层元素,会修改它的引用,让它们指向别的位置,修改嵌套列表中的元素,列表的地址并未发生变化,指向的都是用一个位置。
三、深拷贝(deep copy)
深拷贝只有一种形式,copy 模块中的 deepcopy()函数。深拷贝和浅拷贝对应,深拷贝拷贝了对象的所有元素,包括多层嵌套的元素。因此,它的时间和空间开销要高。同样的对列表 a,如果使用 b = copy.deepcopy(a),再修改列表 b 将不会影响到列表 a,即使嵌套的列表具有更深的层次,也不会产生任何影响,因为深拷贝拷贝出来的对象根本就是一个全新的对象,不再与原来的对象有任何的关联。
四、拷贝的注意点
对于非容器类型,如数字、字符,以及其他的“原子”类型,没有拷贝一说,产生的都是原对象的引用。
如果元组变量值包含原子类型对象,即使采用了深拷贝,也只能得到浅拷贝
4.列表插入
l = [1,2,3]
l.insert(0,4) #在列表的索引处插入
print(l)
5.列表元素替换
x = "hello world "
y = x.replace("hello","hi")
print(y) # 结果为:hi world
6.a=1,b=2,不用中间变量交换 a 和 b 的值?
#方法一:
a = a+b
b = a-b
a = a-b
#方法二:
a = a^b
b =b^a
a = a^b
#方法三:
a,b = b,a
7.代码中要修改不可变数据会出现什么问题? 抛出什么异常?
代码不会正常运行,抛出 TypeError 异常。
8.print 调用 Python 中底层的什么方法?
print 方法默认调用 sys.stdout.write 方法,即往控制台打印字符串。
9.下面这段代码的输出结果将是什么?请解释?
class Parent(object):
x=1
class Child1(Parent):
pass
class Child2(Parent):
pass
print(Parent.x, Child1.x, Child2.x)
Child1.x = 2
print( Parent.x, Child1.x, Child2.x)
Parent.x = 3
print( Parent.x, Child1.x, Child2.x)
#结果为:
1 1 1 #继承自父类的类属性 x,所以都一样,指向同一块内存地址。
1 2 1 #更改 Child1,Child1 的 x 指向了新的内存地址。
3 2 3 #更改 Parent,Parent 的 x 指向了新的内存地址。
10.简述你对 input()函数的理解?
在 Python3 中,input()获取用户输入,不论用户输入的是什么,获取到的都是字符串类型的。
在 Python2 中有 raw_input()和 input(), raw_input()和 Python3 中的 input()作用是一样的,input()输入的是什么数据类型的,获取到的就是什么数据类型的。
11.阅读下面的代码,写出 A0,A1 至 An 的最终值。
A0 = dict(zip(('a','b','c','d','e'),(1,2,3,4,5)))
A1 = range(10)
A2 = [i for i in A1 if i in A0]
A3 = [A0[s] for s in A0] #[]
A4 = [i for i in A1 if i in A3]
A5 = {i:i*i for i in A1}
A6 = [[i,i*i] for i in A1]
#结果为:
A0 = {'a': 1, 'c': 3, 'b': 2, 'e': 5, 'd': 4}
A1 = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
A2 = []
A3 = [1, 3, 2, 5, 4]
A4 = [1, 2, 3, 4, 5]
A5 = {0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
A6 = [[0, 0], [1, 1], [2, 4], [3, 9], [4, 16], [5, 25], [6, 36],[7, 49],[8, 64] [9,81]]
12.考虑以下 Python 代码,如果运行结束,命令行中的运行结果是什么?
l = []
for i in range(10):
l.append({'num':i})
print (l)
#结果为:
[{'num':0},{'num':1},{'num':2},{'num':3},{'num':4},{'num':5},{'num':6},{'num':7},{'num':8},{'num':9}]
再考虑以下代码,运行结束后的结果是什么?
l = []
a = {'num':0}
for i in range(10):
a['num'] = i
l.append(a)
print(l)
#结果为:
[{'num':9},{'num':9},{'num':9},{'num':9},{'num':9},{'num':9},{'num':9},{'num':9},{'num':9},{'num':9}]
原因是:字典是可变对象,在下方的 l.append(a)的操作中是把字典 a 的引用传到列表 l 中,当后续操作修改 a[‘num’]的值的时候,l 中的值也会跟着改变,相当于浅拷贝。
13.4G 内存怎么读取一个 5G 的数据?
方法一:
可以通过生成器,分多次读取,每次读取数量相对少的数据(比如 500MB)进行处理,处理结束后在读取后面的 500MB 的数据。
方法二:
可以通过 linux 命令 split 切割成小文件,然后再对数据进行处理,此方法效率比较高。可以按照行数切割,可以按照文件大小切割。
将一个大文件分成若干个小文件方法
例如将一个BLM.txt文件分成前缀为 BLM_ 的1000个小文件,后缀为系数形式,且后缀为4位数字形式
先利用
wc -l BLM.txt #读出 BLM.txt 文件一共有多少行
再利用 split 命令
split -l 2482 ../BLM/BLM.txt -d -a 4 BLM_
将文件 BLM.txt 分成若干个小文件,每个文件2482行(-l 2482),文件前缀为BLM_ ,系数不是字母而是数字(-d),后缀系数为四位数(-a 4)
linux下文件分割可以通过split命令来实现,可以指定按行数分割和按大小分割两种模式。Linux下文件合并可以通过cat命令来实现,非常简单。
在Linux下用split进行文件分割:
模式一:指定分割后文件行数
对与txt文本文件,可以通过指定分割后文件的行数来进行文件分割。
命令:split -l 300 large_file.txt new_file_prefix
模式二:指定分割后文件大小
命令: split -b 10m server.log waynelog
对二进制文件我们同样也可以按文件大小来分隔。
在Linux下用cat进行文件合并:
命令:cat small_files* > large_file
将a.txt的内容输入到b.txt的末尾
cat a.txt >> b.txt
14.修改代码
现在考虑有一个 jsonline 格式的文件 file.txt 大小约为 10K,之前处理文件的代码如下所示:
def get_lines():
l = []
with open('file.txt','rb') as f:
for eachline in f:
l.append(eachline)
return l
if __name__ == '__main__':
for e in get_lines():
process(e) #处理每一行数据
现在要处理一个大小为 10G 的文件,但是内存只有 4G,如果在只修改 get_lines 函数而其他代码保持不变的情况下,应该如何实现?需要考虑的问题都有哪些?
def get_lines():
l = []
with open('file.txt','rb') as f:
data = f.readlines(60000)
l.append(data)
yield l
if __name__ == '__main__':
for e in get_lines():
process(e)
要考虑到的问题有:
内存只有 4G 无法一次性读入 10G 的文件,需要分批读入。分批读入数据要记录每次读入数据的位置。分批每次读入数据的大小,太小就会在读取操作上花费过多时间。
15.read、readline 和 readlines 的区别
read() : 一次性读取整个文件内容。推荐使用read(size)方法,size越大运行时间越长
readline() :每次读取一行内容。内存不够时使用,一般不太用.使用生成器方法
readlines() :一次性读取整个文件内容,并按行返回到list,方便我们遍历
一般小文件我们都采用read(),不确定大小你就定个size,大文件就用readlines()
16.返回文件及其子文件路径
def print_directory_contents(sPath):
"""
这个函数接收文件夹的名称作为输入参数
返回该文件夹中文件的路径
以及其包含文件夹中文件的路径
"""
# ------------代码如下--------------------
import os
for sChild in os.listdir(sPath):
sChildPath = os.path.join(sPath, sChild)
if os.path.isdir(sChildPath):
print_directory_contents(sChildPath)
else:
print(sChildPath)
17.在 except 中 return 后还会不会执行 finally 中的代码?怎么抛出自定义异常?
会继续处理 finally 中的代码;用 raise 方法可以抛出自定义异常。
18.介绍一下 except 的作用和用法?
except #捕获所有异常
except: <异常名> #捕获指定异常
except:<异常名 1, 异常名 2> #捕获异常 1 或者异常 2
except:<异常名>,<数据> #捕获指定异常及其附加的数据
except:<异常名 1,异常名 2>:<数据> #捕获异常名 1 或者异常名 2,及附加的数据
19.常用的 Python 标准库都有哪些?
os #操作系统
time #时间
random #随机
pymysql #连接数据库
threading #线程
multiprocessing #进程
queue #队列
第三方库:
django 和 flask 也是第三方库,
requests,
virtualenv,
selenium,
scrapy,
xadmin,
celery,
re,
hashlib,
md5。
常用的科学计算库(如 Numpy,Scipy,Pandas)。
20.init 和__new__的区别?
init 在对象创建后,对对象进行初始化。
new 是在对象创建之前创建一个对象,并将该对象返回给 init。
21.Python 里面如何生成随机数?
在 Python 中用于生成随机数的模块是 random,在使用前需要 import. 如下例子可以酌情列
举:
import random
random.random() #生成一个 0-1 之间的随机浮点数;
random.uniform(a, b) #生成[a,b]之间的浮点数;
random.randint(a, b) #生成[a,b]之间的整数;
random.randrange(a, b, step) #在指定的集合[a,b)中,以 step 为基数随机取一个数;
random.choice(sequence) #从特定序列中随机取一个元素,这里的序列可以是字符串,列表,元组等。
22.输入某年某月某日,判断这一天是这一年的第几天?(可以用 Python 标准库)
import datetime
def dayofyear():
year = input("请输入年份:")
month = input("请输入月份:")
day = input("请输入天:")
date1 = datetime.date(year=int(year),month=int(month),day=int(day))
date2 = datetime.date(year=int(year),month=1,day=1)
return (date1 - date2 + 1).days
23.打乱一个排好序的 list 对象 alist?
import random
alist = [1,2,3,4,5,98,56]
random.shuffle(alist)
print(alist)
24.说明一下 os.path 和 sys.path 分别代表什么?
os.path 主要是用于对系统路径文件的操作。
sys.path 主要是对 Python 解释器的系统环境参数的操作(动态的改变 Python 解释器搜索路径)。
25.Python 中的 os 模块常见方法?
os.remove() #删除文件
os.rename() #重命名文件
os.walk() #生成目录树下的所有文件名
os.chdir() #改变目录
os.mkdir/makedirs #创建目录/多层目录
os.rmdir/removedirs #删除目录/多层目录
os.listdir() #列出指定目录的文件
os.getcwd() #取得当前工作目录
os.chmod() #改变目录权限
os.path.basename() #去掉目录路径,返回文件名
os.path.dirname() #去掉文件名,返回目录路径
os.path.join() #将分离的各部分组合成一个路径名
os.path.split() #返回(dirname(),basename())元组
os.path.splitext() #(返回 filename,extension)元组
os.path.getatime\ctime\mtime #分别返回最近访问、创建、修改时间
os.path.getsize() #返回文件大小
os.path.exists() #是否存在
os.path.isabs() #是否为绝对路径
os.path.isdir() #是否为目录
os.path.isfile() #是否为文件
26.Python 的 sys 模块常用方法?
sys.argv #命令行参数 List,第一个元素是程序本身路径
sys.modules.keys() #返回所有已经导入的模块列表
sys.exc_info() #获取当前正在处理的异常类,exc_type、exc_value、exc_traceback 当前处理的异常详细信息
sys.exit(n) #退出程序,正常退出时 exit(0)
sys.hexversion #获取 Python 解释程序的版本值,16 进制格式如:0x020403F0
sys.version #获取 Python 解释程序的版本信息
sys.maxint #最大的 Int 值
sys.maxunicode #最大的 Unicode 值
sys.modules #返回系统导入的模块字段,key 是模块名,value 是模块
sys.path #返回模块的搜索路径,初始化时使用 PYTHONPATH 环境变量的值
sys.platform #返回操作系统平台名称
sys.stdout #标准输出
sys.stdin #标准输入
sys.stderr #错误输出
sys.exc_clear() #用来清除当前线程所出现的当前的或最近的错误信息
sys.exec_prefix #返回平台独立的 python 文件安装的位置
sys.byteorder #本地字节规则的指示器,big-endian 平台的值是'big',little-endian 平台的是'little'
sys.copyright #记录 python 版权相关的东西
sys.api_version #解释器的 C 的 API 版本
sys.version_info #元组则提供一个更简单的方法来使你的程序具备 Python 版本要求功能
27.unit test 是什么?
在 Python 中,unittest 是 Python 中的单元测试框架。它拥有支持共享搭建、自动测试、在测试中暂停代码、将不同测试迭代成一组,等的功能。
28.模块和包是什么?
在 Python 中,模块是搭建程序的一种方式。每一个 Python 代码文件都是一个模块,并可以引用其他的模块,比如对象和属性。
一个包含许多 Python 代码的文件夹是一个包。一个包可以包含模块和子文件夹。
29.Python 是强语言类型还是弱语言类型?
Python 是强类型的动态脚本语言。
强类型:不允许不同类型相加。
动态:不使用显示数据类型声明,且确定一个变量的类型是在第一次给它赋值的时候。
脚本语言:一般也是解释型语言,运行代码只需要一个解释器,不需要编译。
30.谈一下什么是解释性语言,什么是编译性语言?
计算机不能直接理解高级语言,只能直接理解机器语言,所以必须要把高级语言翻译成机器语言,计算机才能执行高级语言编写的程序。
解释性语言在运行程序的时候才会进行翻译。
编译型语言写的程序在执行之前,需要一个专门的编译过程,把程序编译成机器语言(可执行文件)。
31.Python 中有日志吗?怎么使用?
Python 自带 logging 模块,调用 logging.basicConfig()方法,配置需要的日志等级和相应的参数,Python 解释器会按照配置的参数生成相应的日志。
32.Python 是如何进行类型转换的?
int(x,base=10) #x字符串或数字,base进制数,默认十进制 浮点转为整数
float #整数转换为浮点型
complex(1,2) #转换为复数
str(10) #将对象转换为字符串
repe() #将对象转换为表达式字符串
repr(dict) #将对象转换为表达式字符串
eval(str) #用来计算在字符串中有效的python表达式,返回一个对象
tuple(listi) #将列表转化为元组
list() #将元组转换为列表
set #转换集合
33.Python2 与 Python3 的区别?
1)核心类差异
1.Python3 对 Unicode 字符的原生支持。
Python2 中使用 ASCII 码作为默认编码方式导致 string 有两种类型 str和 unicode,Python3 只支持 unicode 的 string。Python2 和 Python3 字节和字符对应关系为:
| python2 | python3 | 表现 | 装换 | 作用 |
|---|---|---|---|---|
| str | bytes | 字节 | encode | 存储 |
| unicode | str | 字符 | decode | 显示 |
2.Python3 采用的是绝对路径的方式进行 import。
Python2 中相对路径的 import 会导致标准库导入变得困难(想象一下,同一目录下有 file.py,如
何同时导入这个文件和标准库 file)。Python3 中这一点将被修改,如果还需要导入同一目录的文件必须使用绝对路径,否则只能使用相关导入的方式来进行导入。
3.Python2 中存在老式类和新式类的区别,Python3 统一采用新式类。新式类声明要求继承 object,必须用新式类应用多重继承。
4.Python3 使用更加严格的缩进。Python2 的缩进机制中,1 个 tab 和 8 个 space 是等价的所以在缩进中可以同时允许 tab 和 space 在代码中共存。这种等价机制会导致部分 IDE 使用存在问题。
Python3 中 1 个 tab 只能找另外一个 tab 替代,因此 tab 和 space 共存会导致错:TabError:
inconsistent use of tabs and spaces in indentation.
2)废弃类差异
1.print 语句被 Python3 废弃,统一使用 print 函数
2.exec 语句被 python3 废弃,统一使用 exec 函数
3.execfile 语句被 Python3 废弃,推荐使用 exec(open("./filename").read())
4.不相等操作符"<>“被 Python3 废弃,统一使用”!="
5.long 整数类型被 Python3 废弃,统一使用 int
6.xrange 函数被 Python3 废弃,统一使用 range,Python3 中 range 的机制也进行修改并提高了大数据集生成效率
7.Python3 中这些方法再不再返回 list 对象:dictionary 关联的 keys()、values()、items(),zip(),map(),filter(),但是可以通过 list 强行转换:
1. mydict={"a":1,"b":2,"c":3}
2. mydict.keys() #8.迭代器 iterator 的 next()函数被 Python3 废弃,统一使用 next(iterator)
9.raw_input 函数被 Python3 废弃,统一使用 input 函数
10.字典变量的 has_key 函数被 Python 废弃,统一使用 in 关键词
11.file 函数被 Python3 废弃,统一使用 open 来处理文件,可以通过 io.IOBase 检查文件类型
12.apply 函数被 Python3 废弃
13.异常 StandardError 被 Python3 废弃,统一使用 Exception
3) 修改类差异
1.浮点数除法操作符“/”和“//”的区别
“ / ”:
Python2:若为两个整形数进行运算,结果为整形,但若两个数中有一个为浮点数,则结果为
浮点数;
Python3:为真除法,运算结果不再根据参加运算的数的类型。
“//”:
Python2:返回小于除法运算结果的最大整数;从类型上讲,与"/"运算符返回类型逻辑一致。
Python3:和 Python2 运算结果一样。
2.异常抛出和捕捉机制区别
#python2
raise IOError, "file error" #抛出异常
except NameError, err: #捕捉异常
#python3
raise IOError("file error") #抛出异常
except NameError as err: 捕捉异常
3.for 循环中变量值区别
#Python2,for 循环会修改外部相同名称变量的值
i = 1
print ('comprehension: ', [i for i in range(5)])
print ('after: i =', i) #i=4
#Python3,for 循环不会修改外部相同名称变量的值
i = 1
print ('comprehension: ', [i for i in range(5)])
print ('after: i =', i) #i=1
4.round 函数返回值区别
#Python2,round 函数返回 float 类型值
isinstance(round(15.5),int) #True
#Python3,round 函数返回 int 类型值
isinstance(round(15.5),float) #True
5.比较操作符区别
#Python2 中任意两个对象都可以比较
1. 11 < 'test' #True
#Python3 中只有同一数据类型的对象可以比较
1. 11 < 'test' # TypeError: unorderable types: int() < str()
4)第三方工具包差异
我们在 pip 官方下载源 pypi 搜索 Python2.7 和 Python3.5 的第三方工具包数可以发现,Python2.7版本对应的第三方工具类目数量是 28523,Python3.5 版本的数量是 12457,这两个版本在第三方工具包支持数量差距相当大。
我们从数据分析的应用角度列举了常见实用的第三方工具包(如下表),并分析这些工具包在Python2.7 和 Python3.5 的支持情况:
| 分类 | 工具名 | 用途 |
|---|---|---|
| 数据收集 | scrapy | 网页采集,爬虫 |
| 数据收集 | scrapy-redis | 分布式爬虫 |
| 数据收集 | selenium | web 测试,仿真浏览器 |
| 数据处理 | beautifulsoup | 网页解释库,提供 lxml 的支持 |
| 数据处理 | lxml | xml 解释库 |
| 数据处理 | xlrd | excel 文件读取 |
| 数据处理 | xlwt | excel 文件写入 |
| 数据处理 | xlutils | excel 文件简单格式修改 |
| 数据处理 | pywin32 | excel 文件的读取写入及复杂格式定制 |
| 数据处理 | Python-docx | Word 文件的读取写入 |
| 数据分析 | numpy | 基于矩阵的数学计算库 |
| 数据分析 | pandas | 基于表格的统计分析库 |
| 数据分析 | scipy | 科学计算库,支持高阶抽象和复杂模型 |
| 数据分析 | statsmodels | 统计建模和计量经济学工具包 |
| 数据分析 | scikit-learn | 机器学习工具库 |
| 数据分析 | gensim | 自然语言处理工具库 |
| 数据分析 | jieba | 中文分词工具库 |
| 数据存储 | MySQL-python | mysql 的读写接口库 |
| 数据存储 | mysqlclient | mysql 的读写接口库 |
| 数据存储 | SQLAlchemy | 数据库的 ORM 封装 |
| 数据存储 | pymssql | sql server 读写接口库 |
| 数据存储 | redis | redis 的读写接口 |
| 数据存储 | PyMongo | mongodb 的读写接口 |
| 数据呈现 | matplotlib | 流行的数据可视化库 |
| 数据呈现 | seaborn | 美观的数据可是湖库,基于 matplotlib |
| 工具辅助 | jupyter | 基于 web 的 python IDE,常用于数据分析 |
| 工具辅助 | chardet | 字符检查工具 |
| 工具辅助 | ConfigParser | 配置文件读写支持 |
| 工具辅助 | requests | HTTP 库,用于网络访问 |
5) 工具安装问题
windows 环境
Python2 无法安装 mysqlclient。Python3 无法安装 MySQL-python、 flup、functools32、Gooey、Pywin32、 webencodings。
matplotlib 在 python3 环境中安装报错:The following required packages can not be built:freetype, png。需要手动下载安装源码包安装解决。
scipy 在 Python3 环境中安装报错,numpy.distutils.system_info.NotFoundError,需要自己手工下载对应的安装包,依赖 numpy,pandas 必须严格根据 python 版本、操作系统、64 位与否。运行matplotlib 后发现基础包 numpy+mkl 安装失败,需要自己下载,国内暂无下载源。
centos 环境下
Python2 无法安装 mysql-python 和 mysqlclient 包,报错:EnvironmentError: mysql_config not found,解决方案是安装 mysql-devel 包解决。使用 matplotlib 报错:no module named _tkinter,安装 Tkinter、tk-devel、tc-devel 解决。
pywin32 也无法在 centos 环境下安装。
34.关于 Python 程序的运行方面,有什么手段能提升性能?
1、使用多进程,充分利用机器的多核性能
2、对于性能影响较大的部分代码,可以使用 C 或 C++编写
3、对于 IO 阻塞造成的性能影响,可以使用 IO 多路复用来解决
4、尽量使用 Python 的内建函数
5、尽量使用局部变量
35.Python 中的作用域?
Python 中,一个变量的作用域总是由在代码中被赋值的地方所决定。当 Python 遇到一个变量的话它会按照这的顺序进行搜索:
本地作用域(Local)—>当前作用域被嵌入的本地作用域(Enclosing locals)—>全局/模块作用域(Global)—>内置作用域(Built-in)。
36.什么是 Python?
Python 是一种编程语言,它有对象、模块、线程、异常处理和自动内存管理,可以加入其他语言的对比。
Python 是一种解释型语言,Python 在代码运行之前不需要解释。
Python 是动态类型语言,在声明变量时,不需要说明变量的类型。
Python 适合面向对象的编程,因为它支持通过组合与继承的方式定义类。
在 Python 语言中,函数是第一类对象。
Python 代码编写快,但是运行速度比编译型语言通常要慢。
Python 用途广泛,常被用走"胶水语言",可帮助其他语言和组件改善运行状况。
使用 Python,程序员可以专注于算法和数据结构的设计,而不用处理底层的细节。
37.什么是 Python 自省?
Python 自省是 Python 具有的一种能力,使程序员面向对象的语言所写的程序在运行时,能够获得对象的类 Python 型。Python 是一种解释型语言,为程序员提供了极大的灵活性和控制力。
详见:https://blog.csdn.net/yuelai_217/article/details/97628979
Python中常用的自省函数
1)help() 用来查看很多Python自带的帮助文档信息。
2)dir() 可以列出对象的所有属性。
3)type() 返回对象的类型。
4)id() 返回对象的“唯一序号”。对于引用对象来说,返回的是被引用对象的id()。
5)hasattr()和getattr() 分别判断对象是否有某个属性及获得某个属性值。
6)callable() 判断对象是否可以被调用。
7)isinstance() 可以确认某个变量是否有某种类型。
38.什么是 Python 的命名空间?
在 Python 中,所有的名字都存在于一个空间中,它们在该空间中存在和被操作——这就是命名空间。它就好像一个盒子,每一个变量名字都对应装着一个对象。当查询变量的时候,会从该盒子里面寻找相应的对象。
39.你所遵循的代码规范是什么?请举例说明其要求?
PEP8 规范。
1.变量
常量:大写加下划线 USER_CONSTANT。
私有变量 : 小写和一个前导下划线 _private_value。
Python 中不存在私有变量一说,若是遇到需要保护的变量,使用小写和一个前导下划线。但这只是程序员之间的一个约定,用于警告说明这是一个私有变量,外部类不要去访问它。但实际上,外部类还是可以访问到这个变量。
内置变量 : 小写,两个前导下划线和两个后置下划线 class
两个前导下划线会导致变量在解释期间被更名。这是为了避免内置变量和其他变量产生冲突。用户定义的变量要严格避免这种风格。以免导致混乱。
2.函数和方法
总体而言应该使用,小写和下划线。但有些比较老的库使用的是混合大小写,即首单词小写,之后每个单词第一个字母大写,其余小写。但现在,小写和下划线已成为规范。
私有方法 :小写和一个前导下划线
这里和私有变量一样,并不是真正的私有访问权限。同时也应该注意一般函数不要使用两个前导下划线(当遇到两个前导下划线时,Python 的名称改编特性将发挥作用)。
特殊方法 :小写和两个前导下划线,两个后置下划线
这种风格只应用于特殊函数,比如操作符重载等。
函数参数 : 小写和下划线,缺省值等号两边无空格
3.类
类总是使用驼峰格式命名,即所有单词首字母大写其余字母小写。类名应该简明,精确,并足以从中理解类所完成的工作。常见的一个方法是使用表示其类型或者特性的后缀,例如:
SQLEngine,MimeTypes 对于基类而言,可以使用一个 Base 或者 Abstract 前缀 BaseCookie,AbstractGroup
4.模块和包
除特殊模块 init 之外,模块名称都使用不带下划线的小写字母。
若是它们实现一个协议,那么通常使用 lib 为后缀,例如:
import smtplib
import os
import sys
5.关于参数
5.1 不要用断言来实现静态类型检测。断言可以用于检查参数,但不应仅仅是进行静态类型检测。
Python 是动态类型语言,静态类型检测违背了其设计思想。断言应该用于避免函数不被毫无意义的调用。
5.2 不要滥用 *args 和 **kwargs。*args 和 **kwargs 参数可能会破坏函数的健壮性。它们使签名变得模糊,而且代码常常开始在不应该的地方构建小的参数解析器。
6.其他
6.1 使用 has 或 is 前缀命名布尔元素
is_connect = True
has_member = False
6.2 用复数形式命名序列
members = ['user_1', 'user_2']
6.3 用显式名称命名字典
person_address = {'user_1':'10 road WD', 'user_2' : '20 street huafu'}
6.4 避免通用名称
诸如 list, dict, sequence 或者 element 这样的名称应该避免。
6.5 避免现有名称
诸如 os, sys 这种系统已经存在的名称应该避免。
6.4 避免通用名称
诸如 list, dict, sequence 或者 element 这样的名称应该避免。
6.5 避免现有名称
诸如 os, sys 这种系统已经存在的名称应该避免。
6.3 用显式名称命名字典
person_address = {‘user_1’:‘10 road WD’, ‘user_2’ : ‘20 street huafu’}
6.4 避免通用名称
诸如 list, dict, sequence 或者 element 这样的名称应该避免。
6.5 避免现有名称
诸如 os, sys 这种系统已经存在的名称应该避免。
6.2 用复数形式命名序列
members = [‘user_1’, ‘user_2’]
6.3 用显式名称命名字典
person_address = {‘user_1’:‘10 road WD’, ‘user_2’ : ‘20 street huafu’}
6.4 避免通用名称
诸如 list, dict, sequence 或者 element 这样的名称应该避免。
6.5 避免现有名称
诸如 os, sys 这种系统已经存在的名称应该避免。
7.一些数字
一行列数 : PEP 8 规定为 79 列。根据自己的情况,比如不要超过满屏时编辑器的显示列数。
一个函数 : 不要超过 30 行代码, 即可显示在一个屏幕类,可以不使用垂直游标即可看到整个函数。
一个类 : 不要超过 200 行代码,不要有超过 10 个方法。一个模块 不要超过 500 行。
8.验证脚本
可以安装一个 pep8 脚本用于验证你的代码风格是否符合 PEP8。
40.Linux 的基本命令(怎么区分一个文件还是文件夹)?
ls -F 在显示名称的时候会在文件夹后添加“/”,在文件后面加“*”。
41.日志以什么格式,存放在哪里?
日志以文本可以存储在“/var/log/”目录下后缀名为.log。
42.Linux 查看某个服务的端口?
netstat -anp | grep service_name
43.ubuntu 系统如何设置开机自启动一个程序?
直接修改/etc/rc0.d ~ /etc/rc6.d 和/etc/rcS.d 文件夹的内容,添加需启动的程序,S 开头的表示启动,K 开头的表示不启动。
44.在 linux 中 find 和 grep 的区别
Linux 系统中 grep 命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。grep 全称是 Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
linux 下的 find:
功能:在目录结构中搜索文件,并执行指定的操作。此命令提供了相当多的查找条件,功能很强大。
语法:find 起始目录寻找条件操作
说明:find 命令从指定的起始目录开始,递归地搜索其各个子目录,查找满足寻找条件的文件并对之采取相关的操作。
简单点说说,grep 是查找匹配条件的行,find 是搜索匹配条件的文件。
45.Linux 重定向命令有哪些?有什么区别?
1、重定向 ‘>’
Linux 允许将命令执行结果重定向到一个文件,本应显示在终端上的内容保存到指定文件中。如:ls >test.txt ( test.txt 如果不存在,则创建,存在则覆盖其内容 )。
2、重定向’>>’
'>>'这个是将输出内容追加到目标文件中。如果文件不存在,就创建文件;如果文件存在,则将新的内容追加到那个文件的末尾,该文件中的原有内容不受影响。
46.软连接和硬链接的区别?
软连接类似 Windows 的快捷方式,当删除源文件时,那么软链接也失效了。硬链接可以理解为源文件的一个别名,多个别名所代表的是同一个文件。当 rm 一个文件的时候,那么此文件的硬链接数减1,当硬链接数为 0 的时候,文件被删除。
47.10 个常用的 Linux 命令?
pwd #显示工作路径
ls #查看目录中的文件
cd /home #进入 '/ home' 目录'
cd .. #返回上一级目录
cd ../.. #返回上两级目录
mkdir dir1 #创建一个叫做 'dir1' 的目录'
rm -f file1 #删除一个叫做 'file1' 的文件',-f 参数,忽略不存在的文件,从不给出提示。
rmdir dir1 #删除一个叫做 'dir1' 的目录'
groupadd group_name 创建一个新用户组
groupdel group_name #删除一个用户组
tar -cvf archive.tar file1 #创建一个非压缩的 tarball
tar -cvf archive.tar file1 file2 dir1 #创建一个包含了 'file1', 'file2' 以及 'dir1'的档案文件
tar -tf archive.tar #显示一个包中的内容
tar -xvf archive.tar #释放一个包
tar -xvf archive.tar -C /tmp #将压缩包释放到 /tmp 目录下
tar -cvfj archive.tar.bz2 dir1 #创建一个 bzip2 格式的压缩包
tar -xvfj archive.tar.bz2 #解压一个 bzip2 格式的压缩包
tar -cvfz archive.tar.gz dir1 #创建一个 gzip 格式的压缩包
tar -xvfz archive.tar.gz #解压一个 gzip 格式的压缩包
48.Linux 关机命令有哪些?
reboot #重新启动操作系统
shutdown –r now #重新启动操作系统,shutdown 会给别的用户提示
shutdown -h now #立刻关机,其中 now 相当于时间为 0 的状态
shutdown -h 20:25 #系统在今天的 20:25 会关机
shutdown -h +10 #系统再过十分钟后自动关机
init 0 #关机
init 6 #重启
49.git 合并文件有冲突,如何处理?
1、git merge 冲突了,根据提示找到冲突的文件,解决冲突如果文件有冲突,那么会有类似的标记
2、修改完之后,执行 git add 冲突文件名
3、git commit 注意:没有-m 选项 进去类似于 vim 的操作界面,把 conflict 相关的行删除掉直接 push 就可以了,因为刚刚已经执行过相关 merge 操作了。
50.现有字典 d={‘a’:24,‘g’:52,‘i’:12,‘k’:33}请按字典中的 value值进行排序?
sorted(d.items(),key = lambda x:x[1])
51.说一下字典和 json 的区别?
json的key只能是字符串,python的dict可以是任何可hash对象。
json的key可以是有序、重复的,python的dict的key不可以重复。
json的key存在默认值undefined,dict没有默认值。
json的value只能是字符串、浮点数、布尔值或者null,或者它们构成的数组或者对象。
json访问方式可以是[],也可以是.,遍历方式分in、of,dict的value仅可以通过下标[]访问。
json的字符串强制双引号,dict字符串可以单引号、双引号。
json里只有数组,dict可以嵌套tuple。
json中的中文必须是unicode编码,如“你好”在json中应为"\u4f60\u597d"。
json的数据类型是字符串(str),字典的数据类型是字典(dict)。
json定义布尔值和空值:true、false、null。
python定义布尔值和空值:True、False、None。
52.什么是可变、不可变类型?元组里添加字典,会改变 id 吗?
可变不可变指的是内存中的值是否可以被改变,不可变类型指的是对象所在内存块里面的值不可以改变,有数值、字符串、元组;可变类型则是可以改变,主要有列表、字典。
元组的顶层元素中包含可变类型,在可变类型中修改或添加字典 id 不会改变
53.存入字典里的数据有没有先后排序?
存入的数据不会自动排序,可以使用 sort 函数对字典进行排序。
54.字典推导式
d = {key: value for (key, value) in iterable}
55.如何理解 Python 中字符串中的\字符?
有三种不同的含义:
1、转义字符
2、路径名中用来连接路径名
3、编写太长代码手动软换行。
56.反转字符串"aStr"?
print('aStr'[::-1])
57.将字符串"k:1|k1:2|k2:3|k3:4",处理成 Python 字典:{k:1, k1:2, … } # 字典里的 K 作为字符串处理
str1 = "k:1|k1:2|k2:3|k3:4"
def str2dict(str1):
dict1 = {}
for iterms in str1.split('|'):
key,value = iterms.split(':')
dict1[key] = value
return dict1
re = str2dict(str1)
print(re)
58.python中for循环原理?
for循环的工作原理:
1、执行in后对象的dic.__iter__()方法,得到一个迭代器对象iter_dic
2、执行next(iter_dic),将得到的值赋值给k,然后执行循环体代码
3、重复过程2,直到捕捉到异常StopIteration,结束循环
可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list、tuple、dict、set、str等;
一类是生成器generator,包括生成器和带yield的generator function。
59.请按 alist 中元素的 age 由大到小排序
alist =[{'name':'a','age':20},{'name':'b','age':30},{'name':'c','age':25}]
def sort_by_age(list1):
return sorted(alist,key=lambda x:x['age'],reverse=True)
re = sort_by_age(alist)
print(re)
60.列表的常用操作
name_list = ["zhangsan", "lisi", "wangwu", "zhaoliu"]
1)增加
列表名.insert(index, 数据):在指定位置插入数据(位置前有空元素会补位)。
1.# 往列表 name_list 下标为 0 的地方插入数据
2.In [3]: name_list.insert(0, "Sasuke")
3.In [4]: name_list
4.Out[4]: ['Sasuke', 'zhangsan', 'lisi', 'wangwu', 'zhaoliu']
5.# 现有的列表下标是 0-4,如果我们要在下标是 6 的地方插入数据,那个会自动插入到下标为 5 的地方,也就是# 插入到最后
6.In [5]: name_list.insert(6, "Tom")
7.In [6]: name_list
8.Out[6]: ['Sasuke', 'zhangsan', 'lisi', 'wangwu', 'zhaoliu', 'Tom']
列表名.append(数据):在列表的末尾追加数据(最常用的方法)。
1.In [7]: name_list.append("Python")
2.In [8]: name_list
3.Out[8]: ['Sasuke', 'zhangsan', 'lisi', 'wangwu', 'zhaoliu', 'Tom', 'Python']
列表.extend(Iterable):将可迭代对象中的元素追加到列表。
1.# 有两个列表 a 和 b a.extend(b) 会将 b 中的元素追加到列表 a 中
2.In [10]: a = [11, 22, 33]
3.In [11]: b = [44, 55, 66]
4.In [12]: a.extend(b)
5.In [13]: a
6.Out[13]: [11, 22, 33, 44, 55, 66]# 有列表 c和 字符串 d c.extend(d)会将字符串 d 中的每个字符拆开作为元素插入到列表c
7.In [14]: c = ['j', 'a', 'v', 'a']
8.In [15]: d = "python"
9.In [16]: c.extend(d)
10.In [17]: c
11.Out[17]: ['j', 'a', 'v', 'a', 'p', 'y', 't', 'h', 'o', 'n']
2)取值和修改
取值:列表名[index] :根据下标来取值。
1.In [19]: name_list = ["zhangsan", "lisi", "wangwu", "zhaoliu"]
2.In [20]: name_list[0]
3.Out[20]: 'zhangsan'
4.In [21]: name_list[3]
5.Out[21]: 'zhaoliu'
修改:列表名[index] = 数据:修改指定索引的数据。
1.In [22]: name_list[0] = "Sasuke"
2.In [23]: name_list
3.Out[23]: ['Sasuke', 'lisi', 'wangwu', 'zhaoliu']
3)删除
del 列表名[index]:删除指定索引的数据。
1.In [25]: name_list = ["zhangsan", "lisi", "wangwu", "zhaoliu"]# 删除索引是 1 的数据
2.In [26]: del name_list[1]
3.In [27]: name_list
4.Out[27]: ['zhangsan', 'wangwu', 'zhaoliu']
列表名.remove(数据):删除第一个出现的指定数据。
5.In [30]: name_list = ["zhangsan", "lisi", "wangwu", "zhaoliu", "lisi"]# 删除 第一次出现的 lisi 的数据
6.In [31]: name_list.remove("lisi")
7.In [32]: name_list
8.Out[32]: ['zhangsan', 'wangwu', 'zhaoliu', 'lisi']
列表名.pop():删除末尾的数据,返回值: 返回被删除的元素。
9.In [33]: name_list = ["zhangsan", "lisi", "wangwu", "zhaoliu"]# 删除最后一个元素 zhaoliu 并将元素 zhaoliu 返回
10.In [34]: name_list.pop()
11.Out[34]: 'zhaoliu'
12.In [35]: name_list
13.Out[35]: ['zhangsan', 'lisi', 'wangwu']
列表名.pop(index):删除指定索引的数据,返回被删除的元素。
14.In [36]: name_list = ["zhangsan", "lisi", "wangwu", "zhaoliu"]# 删除索引为 1 的数据 lisi
15.In [37]: name_list.pop(1)
16.Out[37]: 'lisi'
17.In [38]: name_list
18.Out[38]: ['zhangsan', 'wangwu', 'zhaoliu']
列表名.clear():清空整个列表的元素。
19.In [40]: name_list = ["zhangsan", "lisi", "wangwu", "zhaoliu"]
20.In [41]: name_list.clear()
21.In [42]: name_list
22.Out[42]: []
4)排序
列表名.sort():升序排序 从小到大。
23.In [43]: a = [33, 44, 22, 66, 11]
24.In [44]: a.sort()
25.In [45]: a
26.Out[45]: [11, 22, 33, 44, 66]
列表名.sort(reverse=True):降序排序 从大到小。
27.In [46]: a = [33, 44, 22, 66, 11]
28.In [47]: a.sort(reverse=True)
29.In [48]: a
30.Out[48]: [66, 44, 33, 22, 11]
列表名.reverse():列表逆序、反转。
31.In [50]: a = [11, 22, 33, 44, 55]
32.In [51]: a.reverse()
33.In [52]: a
34.Out[52]: [55, 44, 33, 22, 11]
5)统计相关
len(列表名):得到列表的长度。
35.In [53]: a = [11, 22, 33, 44, 55]
36.In [54]: len(a)
37.Out[54]: 5
列表名.count(数据):数据在列表中出现的次数。
38.In [56]: a = [11, 22, 11, 33, 11]
39.In [57]: a.count(11)
40.Out[57]: 3
列表名.index(数据):数据在列表中首次出现时的索引,没有查到会报错。
41.In [59]: a = [11, 22, 33, 44, 22]
42.In [60]: a.index(22)
43.Out[60]: 1
if 数据 in 列表: 判断列表中是否包含某元素。
44.a = [11, 22, 33, 44 ,55]
45.if 33 in a:
46. print("找到了....")
6)循环遍历
使用 while 循环:
a = [11, 22, 33, 44, 55]
i = 0
while i < len(a):
print(a[i])
i += 1
使用 for 循环:
a = [11, 22, 33, 44, 55]
for i in a:
print(i)
61.下面代码的输出结果将是什么?
list = ['a', 'b', 'c', 'd', 'e']
print (list[10:]) #[]
print(list[10]) #IndexError: list index out of range
62.写一个列表生成式,产生一个公差为 11 的等差数列?
print([x*11 for x in range(10)])
63.给定两个列表,怎么找出他们相同的元素和不同的元素?
1. list1 = [1,2,3]
2. list2 = [3,4,5]
3. set1 = set(list1)
4. set2 = set(list2)
5. print(set1&set2)
6. print(set1^set2)
64.请写出一段 Python 代码实现删除一个 list 里面的重复元素?
比较容易记忆的是用内置的 set:
l1 = ['b','c','d','b','c','a','a']
l2 = list(set(l1))
print(l2)
如果想要保持他们原来的排序:
用 list 类的 sort 方法:
l1 = ['b','c','d','b','c','a','a']
l2 = list(set(l1))
l2.sort(key=l1.index)
print (l2)
也可以这样写:
l1 = ['b','c','d','b','c','a','a']
l2 = sorted(set(l1),key=l1.index)
print (l2)
也可以用遍历:
l1 = ['b', 'c', 'd', 'b', 'c', 'a', 'a']
l2 = []
for i in l1:
if not i in l2:
l2.append(i)
print (l2)
65.有如下数组 list = range(10)我想取以下几个数组,应该如何切片?
1. [1,2,3,4,5,6,7,8,9]
2. [1,2,3,4,5,6]
3. [3,4,5,6]
4. [9]
5. [1,3,5,7,9]
1. [1:]
2. [1:7]
3. [3:7]
4. [-1]
5. [1::2]
66.下面这段代码的输出结果是什么?请解释?
def extendList(val, list=[]):
list.append(val)
return list
list1 = extendList(10) #原列表为空,变为【10】
print("list1 = %s" % list1) # list1 = [10]
list2 = extendList(123,[]) #创建新列表,新的列表为【123】
print("list2 = %s" % list2) # list2 = [123]
list3 = extendList('a') #在列表【10】中加入【‘a']
print("list3 = %s" % list3) # list3 = [10, 'a']
print("list1 = %s" % list1 ,id(list1)) # list1 = [10, 'a']
print("list2 = %s" % list2 ,id(list1)) # list2 = [123]
print("list3 = %s" % list3 ,id(list1)) # list3 = [10, 'a']
新的默认列表只在函数被定义的那一刻创建一次。当 extendList 被没有指定特定参数 list 调用时,这组 list 的值随后将被使用。这是因为带有默认参数的表达式在函数被定义的时候被计算,不是在调用的时候被计算.
67.将以下 3 个函数按照执行效率高低排序
def f1(lIn):
l1 = sorted(lIn)
l2 = [i for i in l1 if i<0.5]
return [i*i for i in l2]
def f2(lIn):
l1 = [i for i in l1 if i<0.5]
l2 = sorted(l1)
return [i*i for i in l2]
def f3(lIn):
l1 = [i*i for i in lIn]
l2 = sorted(l1)
return [i for i in l1 if i<(0.5*0.5)]
按执行效率从高到低排列:f2、f1 和 f3。要证明这个答案是正确的,你应该知道如何分析自己代码的性能。Python
中有一个很好的程序分析包,可以满足这个需求。
import random
import cProfile
lIn = [random.random() for i in range(100000)]
cProfile.run('f1(lIn)')
cProfile.run('f2(lIn)')
cProfile.run('f3(lIn)')
68.获取 1~100 被 6 整除的偶数?
def A():
alist = []
for i in range(1,100):
if i % 6 == 0:
alist.append(i)
print(alist)
A()
69.集合常用操作
快速去除列表中的重复元素
1.In [4]: a = [11,22,33,33,44,22,55]
3.In [5]: set(a)
4.Out[5]: {11, 22, 33, 44, 55}
交集:共有的部分
1.In [7]: a = {11,22,33,44,55}
2.In [8]: b = {22,44,55,66,77}
3.In [9]: a&b
4.Out[9]: {22, 44, 55}
并集:总共的部分
1.In [11]: a = {11,22,33,44,55}
2.In [12]: b = {22,44,55,66,77}
3.In [13]: a | b
4.Out[13]: {11, 22, 33, 44, 55, 66, 77}
差集:另一个集合中没有的部分
1.In [15]: a = {11,22,33,44,55}
2.In [16]: b = {22,44,55,66,77}
3.In [17]: b - a
4.Out[17]: {66, 77}
对称差集(在 a 或 b 中,但不会同时出现在二者中)
1.In [19]: a = {11,22,33,44,55}
2.In [20]: b = {22,44,55,66,77}
3.In [21]: a ^ b
4.Out[21]: {11, 33, 66, 77}
70.简述内键函数Map reduce filter 区别
从参数方面来讲:
map()包含两个参数,第一个是参数是一个函数,第二个是序列(列表或元组)。其中,函数(即 map 的第一个参数位置的函数)可以接收一个或多个参数。
reduce() 第一个参数是函数,第二个是 序列(列表或元组)。但是,其函数必须接收两个参数。
从对传进去的数值作用来讲:
map()是将传入的函数依次作用到序列的每个元素,每个元素都是独自被函数“作用”一次;(请看下面的例子)
reduce()是将传人的函数作用在序列的第一个元素得到结果后,把这个结果继续与下一个元素作用(累积计算)。
map() 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
reduce()函数
reduce 函数可以按照给定的方法把输入参数中上序列缩减为单个的值,具体的做法如下:首先从序列中去除头两个元素并把它传递到那个二元函数中去,求出一个值,再把这个加到序列中循环求下一个值,直到最后一个值 。
71.python 的魔法方法
魔法方法是指Python内部已经包含的,被双下划线所包围的方法,这些方法在进行特定的操作时会自动被调用,它们是Python面向对象下智慧的结晶。使用Python的魔法方法可以使Python的自由度变得更高,当不需要重写时魔法方法也可以在规定的默认情况下生效,在需要重写时也可以让使用者根据自己的需求来重写部分方法来达到自己的期待。而且众所周知Python是支持面向对象的语言Python的基本魔法方法就使得Python在面对对象方面做得更好。
魔法方法就是可以给你的类增加魔力的特殊方法,如果你的对象实现(重载)了这些方法中的某一个,那么这个方法就会在特殊的情况下被 Python 所调用,你可以定义自己想要的行为,而这一切都是自动发生的。它们经常是两个下划线包围来命名的(比如 init,lt),Python 的魔法方法是非常强大的,所以了解其使用方法也变得尤为重要!
init 构造器,当一个实例被创建的时候初始化的方法。但是它并不是实例化调用的第一个方法。
__ new__才是实例化对象调用的第一个方法,它只取下 cls 参数,并把其他参数传给 init。 __new__很少使用,但是也有它适合的场景,尤其是当类继承自一个像元组或者字符串这样不经常改变的类型的时候。
call 允许一个类的实例像函数一样被调用
getitem 定义获取容器中指定元素的行为,相当于 self[key]
getattr 定义当用户试图访问一个不存在属性的时候的行为
setattr 定义当一个属性被设置的时候的行为
getattribute 定义当一个属性被访问的时候的行为
- 基础魔方方法:
| 魔法名 | 说明 |
|---|---|
| new(cls[, …]) | 1. new 是在一个对象实例化的时候所调用的第一个方法 2. 它的第一个参数是这个类,其他的参数是用来直接传递给 init 方法 3. new 决定是否要使用该 init 方法,因为 new 可以调用其他类的构造方法或者直接返回别的实例对象来作为本类的实例,如果 new 没有返回实例对象,则 init 不会被调用 4. new 主要是用于继承一个不可变的类型比如一个 tuple 或者 string |
| init(self[, …]) | 构造方法,初始化类的时候被调用 |
| del(self) | 析构方法,当实例化对象被彻底销毁时被调用(实例化对象的所有指针都被销毁时被调用) |
| call(self[, args…]) | 允许一个类的实例像函数一样被调用:x(a, b) 调用 x.call(a, b) |
| len(self) | 定义当被 len() 调用时的行为 |
| repr(self) | 定义当被 repr() 调用时的行为 |
| str(self) | 定义当被 str() 调用时的行为 |
| bytes(self) | 定义当被 bytes() 调用时的行为 |
| hash(self) | 定义当被 hash() 调用时的行为 |
| bool(self) | 定义当被 bool() 调用时的行为,应该返回 True 或 False |
| format(self, format_spec) | 定义当被 format() 调用时的行为 |
- 属性相关的方法
| 魔法名 | 说明 |
|---|---|
| getattr(self, name) | 定义当用户试图获取一个不存在的属性时的行为 |
| getattribute(self, name) | 定义当该类的属性被访问时的行为 |
| setattr(self, name, value) | 定义当一个属性被设置时的行为 |
| delattr(self, name) | 定义当一个属性被删除时的行为 |
| dir(self) | 定义当 dir() 被调用时的行为 |
| get(self, instance, owner) | 定义当描述符的值被取得时的行为 |
| set(self, instance, value) | 定义当描述符的值被改变时的行为 |
| delete(self, instance) | 定义当描述符的值被删除时的行为 |
- 比较操作符
| 魔法名 | 说明 |
|---|---|
| lt(self, other) | 定义小于号的行为:x < y 调用 x.lt(y) |
| le(self, other) | 定义小于等于号的行为:x <= y 调用 x.le(y) |
| eq(self, other) | 定义等于号的行为:x == y 调用 x.eq(y) |
| ne(self, other) | 定义不等号的行为:x != y 调用 x.ne(y) |
| gt(self, other) | 定义大于号的行为:x > y 调用 x.gt(y) |
| ge(self, other) | 定义大于等于号的行为:x >= y 调用 x.ge(y) |
- 算术运算符
| 魔方名 | 说明 |
|---|---|
| add(self, other) | 定义加法的行为:+ |
| sub(self, other) | 定义减法的行为:- |
| mul(self, other) | 定义乘法的行为:* |
| truediv(self, other) | 定义真除法的行为:/ |
| floordiv(self, other) | 定义整数除法的行为:// |
| mod(self, other) | 定义取模算法的行为:% |
| divmod(self, other) | 定义当被 divmod()调用时的行为 |
| pow(self, other[, modulo]) | 定义当被 power() 调用或 ** 运算时的行为 |
| lshift(self, other) | 定义按位左移位的行为:<< |
| rshift(self, other) | 定义按位右移位的行为:>> |
| and(self, other) | 定义按位与操作的行为:& |
| xor(self, other) | 定义按位异或操作的行为:^ |
| or(self, other) | 定义按位或操作的行为:| |
- 反运算(类似于运算方法)
| 魔法名 | 说明 |
|---|---|
| radd(self, other) | 当被运算对象(左边的操作对象)不支持该运算时被调用 |
| rsub(self, other) | 当被运算对象(左边的操作对象)不支持该运算时被调用 |
| rmul(self, other) | 当被运算对象(左边的操作对象)不支持该运算时被调用 |
| rtruediv(self, other) | 当被运算对象(左边的操作对象)不支持该运算时被调用 |
| rfloordiv(self, other) | 当被运算对象(左边的操作对象)不支持该运算时被调用 |
| rmod(self, other) | 当被运算对象(左边的操作对象)不支持该运算时被调用 |
| rdivmod(self, other) | 当被运算对象(左边的操作对象)不支持该运算时被调用 |
| rpow(self, other) | 当被运算对象(左边的操作对象)不支持该运算时被调用 |
| rlshift(self, other) | 当被运算对象(左边的操作对象)不支持该运算时被调用 |
| rrshift(self, other) | 当被运算对象(左边的操作对象)不支持该运算时被调用 |
| rxor(self, other) | 当被运算对象(左边的操作对象)不支持该运算时被调用 |
| ror(self, other) | 当被运算对象(左边的操作对象)不支持该运算时被调用 |
- 增量赋值运算
| 魔方名 | 说明 |
|---|---|
| iadd(self, other) | 定义赋值加法的行为:+= |
| isub(self, other) | 定义赋值减法的行为:-= |
| imul(self, other) | 定义赋值乘法的行为:*= |
| itruediv(self, other) | 定义赋值真除法的行为:/= |
| ifloordiv(self, other) | 定义赋值整数除法的行为://= |
| imod(self, other) | 定义赋值取模算法的行为:%= |
| ipow(self, other[, modulo]) | 定义赋值幂运算的行为:**= |
| ilshift(self, other) | 定义赋值按位左移位的行为:<<= |
| irshift(self, other) | 定义赋值按位右移位的行为:>>= |
| iand(self, other) | 定义赋值按位与操作的行为:&= |
| ixor(self, other) | 定义赋值按位异或操作的行为:^= |
| ior(self, other) | 定义赋值按位或操作的行为:|= |
- 一元操作符
| 魔方名 | 说明 |
|---|---|
| neg(self) | 定义正号的行为:+x |
| pos(self) | 定义负号的行为:-x |
| abs(self) | 定义当被 abs() 调用时的行为 |
| invert(self) | 定义按位求反的行为:~x |
- 类型转换
| 魔方名 | 说明 |
|---|---|
| complex(self) | 定义当被 complex() 调用时的行为(需要返回恰当的值) |
| int(self) | 定义当被 int() 调用时的行为(需要返回恰当的值) |
| float(self) | 定义当被 float() 调用时的行为(需要返回恰当的值) |
| round(self[, n]) | 定义当被 round() 调用时的行为(需要返回恰当的值) |
| index(self) | 1. 当对象是被应用在切片表达式中时,实现整形强制转换2. 如果你定义了一个可能在切片时用到的定制的数值型,你应该定义 __index__3. 如果 index 被定义,则 int 也需要被定义,且返回相同的值 |
- 上下文管理(with 语句)
| 魔方名 | 说明 |
|---|---|
| enter(self) | 1. 定义当使用 with 语句时的初始化行为2. enter 的返回值被 with 语句的目标或者 as 后的名字绑定 |
| exit(self, exc_type, exc_value, traceback) | 1. 定义当一个代码块被执行或者终止后上下文管理器应该做什么2. 一般被用来处理异常,清除工作或者做一些代码块执行完毕之后的日常工作 |
10)容器类型(一般用于操作容器类)
| 魔方名 | 说明 |
|---|---|
| len(self) | 定义当被 len() 调用时的行为(一般返回容器类的长度) |
| getitem(self, key) | 定义获取容器中指定元素的行为,相当于 self[key] |
| setitem(self, key, value) | 定义设置容器中指定元素的行为,相当于 self[key] = value |
| delitem(self, key) | 定义删除容器中指定元素的行为,相当于 del self[key] |
| iter(self) | 定义当迭代容器中的元素的行为 |
| reversed(self) | 定义当被 reversed() 调用时的行为 |
| contains(self, item) | 定义当使用成员测试运算符(in 或 not in)时的行为 |
72.求输出结果
def multipliers():
return [lambda x : i * x for i in range(4)]
print ([m(2) for m in multipliers()])
#[6, 6, 6, 6]
上面代码输出的结果是[6, 6, 6, 6] (不是我们想的[0, 2, 4, 6])。
你如何修改上面的 multipliers 的定义产生想要的结果?
上述问题产生的原因是 Python 闭包的延迟绑定。这意味着内部函数被调用时,参数的值在闭包内进行查找。因此,当任何由 multipliers()返回的函数被调用时,i 的值将在附近的范围进行查找。那时,不管返回的函数是否被调用,for 循环已经完成,i 被赋予了最终的值 3。
因此,每次返回的函数乘以传递过来的值 3,因为上段代码传过来的值是 2,它们最终返回的都是 6。(3*2)碰巧的是,《The Hitchhiker’s Guide to Python》也指出,在与 lambdas 函数相关也有一个被广泛被误解的知识点,不过跟这个 case 不一样。由 lambda 表达式创造的函数没有什么特殊的地方,它其实是和 def 创造的函数式一样的。
下面是解决这一问题的一些方法。
一种解决方法就是用 Python 生成器。
def multipliers():
for i in range(4): yield lambda x : i * x
另外一个解决方案就是创造一个闭包,利用默认函数立即绑定。
def multipliers():
return [lambda x, i=i : i * x for i in range(4)]
73.对缺省参数的理解?
缺省参数指在调用函数的时候没有传入参数的情况下,调用默认的参数,在调用函数的同时赋值时,所传入的参数会替代默认参数.
*args 是不定长参数,他可以表示输入参数是不确定的,可以是任意多个。
**kwargs 是关键字参数,赋值的时候是以键 = 值的方式,参数是可以任意多对在定义函数的时候不确定会有多少参数会传入时,就可以使用两个参数。
74.对装饰器的理解,并写出一个计时器记录方法执行性能的装饰器?
装饰器本质上是一个 Python 函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象.
import time
def timeit(func):
def wrapper():
start = time.clock()
func()
end =time.clock()
print('used:', end - start)
return wrapper
@timeit
def foo():
print('in foo()'foo())
75.什么是线程安全,什么是互斥锁?
每个对象都对应于一个可称为" 互斥锁" 的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象。
同一个进程中的多线程之间是共享系统资源的,多个线程同时对一个对象进行操作,一个线程操作尚未结束,另一个线程已经对其进行操作,导致最终结果出现错误,此时需要对被操作对象添加互斥锁,保证每个线程对该对象
的操作都得到正确的结果.
76.什么单例模式,其应用场景都有哪些?
确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例,这个类称为单例类,单例模式是一种对象创建型模式。
Windows 的 Task Manager(任务管理器)、Recycle Bin(回收站)、网站计数器
单例模式应用的场景一般发现在以下条件下:
(1)资源共享的情况下,避免由于资源操作时导致的性能或损耗等。如上述中的日志文件,应用配置。
(2)控制资源的情况下,方便资源之间的互相通信。如线程池等。
1.网站的计数器 2.应用配置 3.多线程池 4.数据库配置,数据库连接池 5.应用程序的日志应用…
77.递归函数停止的条件?
递归的终止条件一般定义在递归函数内部,在递归调用前要做一个条件判断,根据判断的结果选择是继续调用自身,还是 return;返回终止递归。
终止的条件:
1.判断递归的次数是否达到某一限定值
2.判断运算的结果是否达到某个范围等,根据设计的目的来选择
78.python 的内存管理机制及调优手段?
内存管理机制:引用计数、垃圾回收、内存池
引用计数
引用计数是一种非常高效的内存管理手段, 当一个 Python 对象被引用时其引用计数增加 1, 当其不再被一个变量引用时则计数减 1. 当引用计数等于 0 时对象被删除.
垃圾回收
1.引用计数
引用计数也是一种垃圾收集机制,而且也是一种最直观,最简单的垃圾收集技术。当 Python 的某个对象的引用计数降为 0 时,说明没有任何引用指向该对象,该对象就成为要被回收的垃圾了。比如某个新建对象,它被分配给某个引用,对象的引用计数变为 1。如果引用被删除,对象的引用计数为 0,那么该对象就可以被垃圾回收。不过如果出现循环引用的话,引用计数机制就不再起有效的作用了
2.标记清除
如果两个对象的引用计数都为 1,但是仅仅存在他们之间的循环引用,那么这两个对象都是需要被回收的,也就是说,它们的引用计数虽然表现为非 0,但实际上有效的引用计数为 0。所以先将循环引用摘掉,就会得出这两个对象的有效计数。
3.分代回收
从前面“标记-清除”这样的垃圾收集机制来看,这种垃圾收集机制所带来的额外操作实际上与系统中总的内存块的数量是相关的,当需要回收的内存块越多时,垃圾检测带来的额外操作就越多,而垃圾回收带来的额外操作
就越少;反之,当需回收的内存块越少时,垃圾检测就将比垃圾回收带来更少的额外操作。
举个例子:
4当某些内存块 M 经过了 3 次垃圾收集的清洗之后还存活时,我们就将内存块 M 划到一个集合 A 中去,而新分配的内存都划分到集合 B 中去。当垃圾收集开始工作时,大多数情况都只对集合 B 进行垃圾回收,而对集合 A 进行垃圾回收要隔相当长一段时间后才进行,这就使得垃圾收集机制需要处理的内存少了,效率自然就提高了。在这个过程中,集合 B 中的某些内存块由于存活时间长而会被转移到集合 A 中,当然,集合 A 中实际上也存在一些垃圾,这些垃圾的回收会因为这种分代的机制而被延迟。
内存池
1.Python 的内存机制呈现金字塔形状,-1,-2 层主要有操作系统进行操作;
2.第 0 层是 C 中的 malloc,free 等内存分配和释放函数进行操作;
3.第 1 层和第 2 层是内存池,有 Python 的接口函数 PyMem_Malloc 函数实现,当对象小于 256K 时有该层直接分配内存;
4.第 3 层是最上层,也就是我们对 Python 对象的直接操作;Python 在运行期间会大量地执行 malloc 和 free 的操作,频繁地在用户态和核心态之间进行切换,这将严重影响 Python 的执行效率。为了加速Python 的执行率,Python 引入了一个内存池机制,用于管理对小块内存的申请和释放。
Python 内部默认的小块内存与大块内存的分界点定在 256 个字节,当申请的内存小于 256 字时,PyObject_Malloc 会在内存池中申请内存;当申请的内存大于 256 字节时,PyObject_Malloc 的行为将蜕化为 malloc 的行为。当然,通过修改 Python 源代码,我们可以改变这个默认值,从而改变 Python的默认内存管理行为。
调优手段(了解)
1.手动垃圾回收
2.调高垃圾回收阈值
3.避免循环引用(手动解循环引用和使用弱引用)
79.用自己的话说明迭代器和生成器,它们之间的关系?
迭代指的是一个重复的过程,每一次重复称为一次迭代,迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。并且每一次重复的结果是下一次重复的初始值,迭代器只能往前不会后退,迭代器是一个可以记住遍历的位置的对象.
在 Python 中,一边循环一边计算的机制,称为生成器:generator,生成器是可以迭代对象,但是生成器可以通过 send 传值返回到前面;只要在函数体内出现yield关键字,那么执行函数就不会执行函数代码,会得到一个结果,该结果就是生成器.
迭代器是一个更抽象的概念,任何对象,如果它的类有 next 方法和 iter 方法返回自己本身,对于 string、list、dict、tuple 等这类容器对象,使用 for 循环遍历是很方便的。在后台 for 语句对容器对象调用 iter()函数,iter()是 python 的内置函数。iter()会返回一个定义了 next()方法的迭代器对象,它在容器中逐个访问容器内元素,next()也是 python 的内置函数。在没有后续元素时,next()会抛出一个 StopIteration 异常。
生成器(Generator)是创建迭代器的简单而强大的工具。它们写起来就像是正规的函数,只是在需要返回数据的时候使用 yield 语句。每次 next()被调用时,生成器会返回它脱离的位置(它记忆语句最后一次执行的位置和所有的数据值)
区别:生成器能做到迭代器能做的所有事,而且因为自动创建了 iter()和 next()方法,生成器显得特别简洁,而且生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保存程序状态的自动方法,当发生器终结时,还会自动抛出 StopIteration 异常。
迭代器是一个带状态的对象,它能在你调用next()方法的时候返回容器中的下一个值,任何实现了inter和next()(Python2中实现next())方法的对象都是迭代器,iter返回迭代器自身,next返回容器的下一个值,如果容器中没有更多的元素了,则抛出Stopiteration异常,至于它们到底是如何实现的并不重要。正是因为他是通过next()来返回迭代器中的元素,所以它是一种延迟计算方式返回对象,这种特点对于大数据量元素进行遍历时具有明显优势,他不会一次性把所有元素载入内存,而是遍历一个载入一个,大大降低了内存的占用。
生成器,简单来说就是使用了yield关键字的函数,都叫做生成器。例如:
def func():
yield
f = func()
type(f)
<type 'generator'>
yield的作用是发起当前执行的函数,并返回,直到调用next(),继续执行后续指令,直到再次遇到yield或者抛出StopIteration异常。上面的例子第一次运行生成器f,需要首先调用f.next()启动生成器。
生成器的优点:代码实现更加简洁,可以提高代码的可读性。同时当然也具有迭代器的优点,大量数据遍历时内存占用少。
需要注意的是:生成器一定是迭代器,但是迭代器不一定是生成器,因为创建一个迭代器只需要实现iter和next()方法就可以了,并不一定要使用yield实现。生成器的唯一注意事项就是:生成器只能遍历一次。
80.对不定长参数的理解?
不定长参数有两种:*args 和kwargs;
*args:是不定长参数,用来将参数打包成 tuple 给函数体调用
kwargs:是关键字参数,打包关键字参数成 dict 给函数体调用在定义函数的时候不确定要传入的参数个数会有多少个的时候就可以使用不定长参数作为形参
如果我们不确定要往函数中传入多少个参数,或者我们想往函数中以列表和元组 的形式传参数时,那就使要用*args;
如果我们不知道要往函数中传入多少个关键词参数,或者想传入字典的值作为关 键词参数时,那就要使用**kwargs。
args和kwargs这两个标识符是约定俗成的用法,你当然还可以用*bob和**billy, 但是这样就并不太妥。
81.什么是lambda函数?它有什么好处?
概念:lambda函数是一个可以接收任意多个参数(包括可选参数)并且返回单个表达式值的函数。
好处:
1)使用Python写一些执行脚本时,使用lambda可以省去定义函数的过程,让代码更加精简。
2)对于一些抽象的,不会别的地方再复用的函数,有时候给函数起个名字也是个难题,使用lambda不需要考虑命名的问题。
3)使用lambda在某些时候让代码更容易理解。
语法说明:
1).lambda 只是一个表达式 ,它用来创建一个函数对象
2).当lambda表达式执行时,返回的是冒号(:)后 的表达式的值
3).lambda表达式创建的函数只能包含一条语句
4).lambda比函数简单,且可以随时创建和销毁,有利于减少程序的偶合度
82.解释一下什么是闭包
在函数内部再定义一个函数,并且这个函数用到了外边函数的变量,那么将这个函数以及用到的一些变量称之为闭包
83.解释一下什么是锁,有哪几种锁?
锁(Lock)是 python 提供的对线程控制的对象
有互斥锁、可重入锁、死锁
84.什么是死锁以及怎么解决?
死锁:在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁
给互斥锁添加超时时间
程序设计时要尽量避免(银行家算法)
85.什么是僵尸进程和孤儿进程,怎么避免僵尸进程?
孤儿进程:父进程退出,子进程还在运行的这些子进程都是孤儿进程,孤儿进程将被 init 进程(进程号为 1)所收养,并由 init 进程对它们完成状态收集工作
僵尸进程:进程使用 fork 创建子进程,如果子进程退出,而父进程并没有调用 wait 或 waitpid 获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中的这些进程是僵尸进程
避免僵尸进程的方法:
1.fork 两次用孙子进程去完成子进程的任务
2.用 wait()函数使父进程阻塞
3.使用信号量,在 signal handler 中调用 waitpid,这样父进程不用阻塞
86.python 中的进程与线程的使用场景?
多进程适合在 CPU 密集型操作(cpu 操作指令比较多,如位数多的浮点运算)
多线程适合在 IO 密集型操作(读写数据操作较多的,比如爬虫)
87.回调函数,如何通信的?
回调函数是把函数的指针(地址)作为参数传递给另一个函数,将整个函数当作一个对象,赋值给调用的函数
88.浮点数如何进行比较大小?
浮点数的表示是不精确的,不能直接比较两个数是否完全相等,一般都是在允许的某个范围内认为像个浮点数相等,如有两个浮点数 a,b,允许的误差范 围为 1e-6,则 abs(a-b)<=1e-6,即可认为 a 和 b 相等
python3.5 的 math 模块新增一个 isclose 函数用来判断两个浮点数的值是否接近或相等
import math
print(math.isclose(1.25,1.25))# 返回一个布尔值 True
print(math.isclose(2.1,2.2,rel_tol=0.1))
参数:
a,b:两个需要比较的浮点数;
rel_tol: 相对于输入值的大小,被认为是“接近”的最大差异;
abs_tol: 无论输入值的大小,被认为“接近”的最大差异
89.线程是并发还是并行,进程是并发还是并行?
线程是并发,进程是并行;进程之间相互独立,是系统分配资源的最小单位,同一个线程中的所有线程共享资源
90.解释一下 Python 中的 and-or 语法?
逻辑运算 and-or,在计算机运算中的短路规则(以尽量少运算,得出正确结果)可以提高计算效率,
在 result = a and b 运算中:
当 a 为假时,无论 b 为真或假,结果都为假,此时 b 的运算就不会进行,结果直接为 a 即可;
当 a 为真时,结果还得看 b,b 为真则真,b 为假则假,此时结果即为 b;
在 result = a or b 运算中:
如果 a 为真则无论 b 为什么结果都会是真,结果即为 b
如果 a 为假则看 b 的情况了,b 为真则结果为真,b 为假则结果为假,即结果为 b
91.Python 中类方法、类实例方法、静态方法有何区别?
一、先是在语法上面的区别:
1).静态方法不需要传入self参数,类成员方法需要传入代表本类的cls参数;
2).静态方法是无妨访问实例变量和类变量的,类成员方法无法访问实例变量但是可以访问类变量
类方法:是类对象的方法,在定义时需要在上方使用“@classmethod”进行装饰,形参为 cls,表示类对象,类对象和实例对象都可调用;
类实例方法:是类实例化对象的方法,只有实例对象可以调用,形参为self,指代对象本身;
静态方法:是一个任意函数,在其上方使用“@staticmethod”进行装饰,可以用对象直接调用,静态方法实际上跟该类没有太大关系
二、使用的区别:
由于静态方法无法访问类属性,实例属性,相当于一个相对独立的方法,跟类其实并没有什么关系。这样说来,静态方法就是在类的作用域里的函数而已。
92.Python 中 pass 语句的作用是什么
在编写代码时只写框架思路,具体实现还未编写就可以用 pass 进行占位,使程序不报错,不会进行任何操作
93.谈谈你对同步、异步、阻塞、非阻塞的理解
在计算机领域,同步就是指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息,那么这个进程就会一直等待下去,直到收到返回信息才继续执行下去,异步是值进程不需要一直等下去,而继续执行下面的操作,不管其他进程的状态。当有消息返回时系统会通知进程进行处理,这样可以提高执的效率。举个例子,打电话时就是同步通信,发短息时就是异步通信。
阻塞调用是指调用结果返回之前,当前线程会被挂起。函数只有在得到结果之后才会返回。有人也许会把阻塞调用和同步调用等同起来,实际上他是不同的。对于同步调用来说,很多时候当前线程还是激活的,只是从逻辑上当前函数没有返回而已。例如,我们在 CSocket 中调用 Receive 函数,如果缓冲区中没有数据,这个函数就会一直等待,直到有数据才返回。而此时,当前线程还会继续处理各种各样的消息。如果主窗口和调用函数在同一个线程中,除非你在特殊的界面操作函数中调用,其实主界面还是应该可以刷新。socket 接收数据的另外一个函数 recv 则是一个阻塞调用的例子。当 socket工作在阻塞模式的时候,如果没有数据的情况下调用该函数,则当前线程就会被挂起,直到有数据为止。
非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回。
94.介绍一下 Python 下 range()和 xrange()函数的用法?
range(start,stop,step)函数按照从 start 到 stop 每个 step 生成一个数值,生成的是列表对象,一次性将所有数据都返回;
xrange(start,stop,step)函数按照从 start 到 stop 每个 step 生成一个数值,返回的是可迭代对象,每次调用返回其中的一个值
95.用 Python 匹配 HTML tag 的时候,<.>和<.?>有什么区别?
<.>是贪婪匹配,会从第一个“<”开始匹配,直到最后一个“>”中间所有的字符都会匹配到,中间可能会包含“<>”
<.*?>是非贪婪匹配,从第一个“<”开始往后,遇到第一个“>”结束匹配,这中间的字符串都会匹配到,但是不会有“<>”
96.如何用 Python 来进行查询和替换一个文本字符串?
使用正则表达式
re.findall(r'目的字符串','原有字符串') #查询
re.findall(r'cast','itcast.cn')[0]
re.sub(r'要替换原字符','要替换新字符','原始字符串')
re.sub(r'cast','heima','itcast.cn')
97.说明一下 os.path 和 sys.path 分别代表什么?
os.path 主要是用于用户对系统路径文件的操作
sys.path 主要用户对 python 解释器的系统环境参数的操作
98.请尝试用“一行代码”实现将 1-N 的整数列表以 3 为单位分组,比如 1-100 分组后为?
print([[x for x in range(1,100)][i:i+3] for i in range(0,len(list_a),3)])
99.已知路径 path,写一个函数并以前向遍历的方式打印目录中的所有文件?
(可使用 os.listdir,os.path.isdir,os.path.join 和递归的方式来实现),比如如下的一个文件树结构:
root
|————a.file
|————b.dir
| ——ba.file
」——c.dir
」——d.file
|————e.file
」———f.dir
|———g.file
」——h.dir
」——i.file
将 root 的绝对路径传递给函数 lookup 后,打印的内容如下:
/root/testWork/test_dir/a.file
/root/testWork/test_dir/b.dir/ba.file
/root/testWork/test_dir/b.dir/c.dir/d.file
/root/testWork/test_dir/e.file
/root/testWork/test_dir/f.dir/g.file
/root/testWork/test_dir/f.dir/h.dir/i.file
请实现此函数。
def lookup(path):
# -*- coding:utf-8 -*-
# 要求:升序遍历指定目录中的所有文件名
import os
full_names = []
def lookup(path=None):
global full_names
if not path:
dirs = os.getcwd()
else:
if os.path.isdir(path):
dirs = path
else:
print(path)
return
# 遍历路径下的所有目录,并按顺序排序
os.chdir(dirs)
dirs = os.getcwd()
dir_files = os.listdir(dirs)
dir_files.sort()
for dir_file in dir_files:
if os.path.isfile(dir_file):
full_name = os.path.join(dirs,dir_file)
full_names.append(full_name)
elif os.path.isdir(dir_file):
lookup(dir_file)
os.chdir('../')
if __name__ == '__main__':
dir = input('请输入一个要遍历的目录:')
lookup(dir)
for full_name in full_names:
print(full_name)
100.并行(parallel)和并发(concurrency)?
并行:同一时刻多个任务同时在运行
并发:在同一时间间隔内多个任务都在运行,但是并不会在同一时刻同时运行,存在交替执行的情况
实现并行的库有:multiprocessing
实现并发的库有:threading
程序需要执行较多的读写、请求和回复任务的需要大量的 IO 操作,IO密集型操作使用并发更好
CPU 运算量大的程序程序,使用并行会更好
101.Python 主要的内置数据类型都有哪些?print dir(‘a’)的输出?
内建类型:布尔类型、数字、字符串、列表、元组、字典、集合;
输出字符串‘a’的内建方法
102.给定一个 int list a,满足 a[i + 1]>=a[i],给定 int key找出 list a 中第一个大于等于 key 的元素的 index,无满足要求的元素则返回-1
def findindex(int_list,int_key):
int_list = sorted(int_list)
for i in range(len(int_list)):
if int_list[i] == int_key:
return i
return -1
if __name__ == "__main__":
lista = [12,3,4,5,8,6]
index = findindex(lista,5)
print(index)
103.正则表达式
正则匹配中贪婪模式与非贪婪模式的区别?match、search 函数的使用及区别?请写出以字母或下划线开始,以数字结束的正则表达式?
1 贪婪模式:正则会尽量多的匹配字符串,被匹配到的字符串里面可能包含多个可以终止匹配的字符,但是会匹配到最后一个字符才会停止;非贪婪模式:正则会保证符合规则的情况下尽量少匹配字符,不会出现匹配到的字符中包含可以终止匹配的字符的情况。
2 match 是从字符串的第一个字符开始依次往后匹配,中途若出现不匹配的情况则立即终止匹配,返回寄过为空,匹配到第一个满足要求的字符串也停止匹配并返回匹配到的字符串;search 也是有第一个字符开始,若第个字符不匹配则从下一个字符开始匹配(即可以从中间开始匹配),知道匹配到第一个符合条件字符串,或者匹配到最后一个字符终止匹配。
match方法从头开始找,找到就返回,否则为None,只匹配一次
search从头依次搜索,只匹配一次,若对象中含有目标,则返回目标。否则返回None
re.match() 从第一个字符开始找, 如果第一个字符就不匹配就返回None, 不继续匹配. 用于判断字符串开头或整个字符串是否匹配,速度快.
re.search() 会整个字符串查找,直到找到一个匹配。
3 r’1|[_].*\d$’
正则表达式的优缺点:
缺点
1).正则表达式只适合匹配文本字面,不适合匹配文本意义:像匹配url,email这种纯文本的字符就很好,但比如匹配多少范围到多少范围的数字,如果你这个范围很复杂的话用正则就很麻烦。或者匹配html,这个是很多人经常遇到的,写一个复杂匹配html的正则很麻烦,不如使用针对特定意义的处理器来处理(比如写语法分析器,dom分析器等)
2).容易引起性能问题:像.*这种贪婪匹配符号很容易造成大量的回溯,性能有时候会有上百万倍的下降,编写好的正则表达式要对正则引擎执行方式有很清楚的理解才可以
3).正则的替换功能较差:甚至没有基本的截取字符串或者把首字母改变大小写的功能,这对于url重写引擎有时候是致命的影响
优点:只要熟练应用正则表达式,而且匹配的目标是纯文本,那么相比于写分析器来说,正则可以更快速的完成工作。还有在捕获字符串的能力,正则也可以很好的完成工作,比如截取url的域名或者其他的内容等等


104.描述 Python GIL 的概念,以及它对 Python 多线程的影响?
线程全局锁(Global Interpreter Lock),即 Python 为了保证线程安全而采取的独立线程运行的限制,说白了就是一个核只能在同一时间运行一个线程.
GIL:又叫全局解释器锁,每个线程在执行的过程中都需要先获取GIL,保证同一时刻只有一个线程在运行,目的是解决多线程同时竞争程序中的全局变量而出现的线程安全问题。它并不是python语言的特性,仅仅是由于历史的原因在CPython解释器中难以移除,因为python语言运行环境大部分默认在CPython解释器中。
多线程下每个线程在执行的过程中都需要先获取GIL,保证同一时刻只有一个线程在运行。
即使在多核CPU中,多线程同一时刻也只有一个线程在运行,这样不仅不能利用多核CPU的优势,反而由于每个线程在多个CPU上是交替执行的,导致在不同CPU上切换时造成资源的浪费,反而会更慢。即原因是一个进程只存在一把GIL锁,当在执行多个线程时,内部会争抢GIL锁,这会造成当某一个线程没有抢到锁的时候会让CPU等待,进而不能合理利用多核CPU资源。
计算密集型:要进行大量的数值计算,例如进行上亿的数字计算、计算圆周率、对视频进行高清解码等等。这种计算密集型任务虽然也可以用多任务完成,但是花费的主要时间在任务切换的时间,此时CPU执行任务的效率比较低。
IO密集型:涉及到网络请求(time.sleep())、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。
GIL:全局解释器锁。每个线程在执行的过程都需要先获取 GIL,保证同一时刻只有一个线程可以执行字节码。
线程释放 GIL 锁的情况:
在 IO 操作等可能会引起阻塞的 system call 之前,可以暂时释放 GIL,但在执行完毕后,必须重新获取 GIL
Python 3.x 使用计时器(执行时间达到阈值后,当前线程释放 GIL)或Python 2.x,tickets 计数达到 100
Python 使用多进程是可以利用多核的 CPU 资源的。
多线程爬取比单线程性能有提升,因为遇到 IO 阻塞会自动释放 GIL 锁
解决GIL问题的方案:
1.使用其它语言,例如C,Java
2.使用其它解释器,如java的解释器jython
3.使用多进程
105.Python 中如何动态获取和设置对象的属性?
if hasattr(Parent,'x'):
print(getattr(Parent,'x'))
setattr(Parent,'x',3)
print(getattr(Parent,'x'))
106.git merge 和 git rebase 有什么区别?git reset 和 git revert 有什么区别?
merge 操作会生成一个新的节点,之前的提交分开显示。而 rebase 操作不会生成新的节点,是将两个分支融合成一个线性的提交
git revert 是生成一个新的提交来撤销某次提交,此次提交之前的commit 都会被保留
git reset 是回到某次提交,提交及之前的 commit 都会被保留,但是此次之后的修改都会被退回到暂存区
107.dict 的 items()和 iteritems()方法的不同?
items()返回的是列表对象,而 iteritems()返回的是 iterator 对象
108.函数调用一个变量的顺序?
Python 变量访问时有个 LEGB 原则,也就是说,变量访问时搜索顺序为Local ==> Enclosing ==> Global ==> Builtin
简单地说,访问变量时,先在当前作用域找,如果找到了就使用,如果没找到就继续到外层作用域看看有没有,找到了就使用,如果还是没找到就继续到更外层作用域找,如果已经到了最外层作用域了还是实在找不到就看看是不是内置对象,如果也不是,抛出异常。
109.面向对象中怎么实现只读属性?
将对象私有化,通过共有方法提供一个读取数据的接口
class person:
def __init__(self,x):
self.__age = 10
def age(self):
return self.__age
t = person(22)
# t.__age = 100
print(t.age())
最好的方法
class MyCls(object):
__weight = 50
@property #以访问属性的方式来访问 weight 方法
def weight(self):
return self.__weight
if __name__ == '__main__':
obj = MyCls()
print(obj.weight)
obj.weight = 12
# raceback (most recent call last):
# 50
# File "C:/PythonTest/test.py", line 11, in 110.内存泄露是什么?如何避免?
指由于疏忽或错误造成程序未能释放已经不再使用的内存的情况。内存泄漏并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,失去了对该段内存的控制,因而造成了内存的浪费。导致程序运行速度减慢甚至系统崩溃等严重后果。
有 del() 函数的对象间的循环引用是导致内存泄漏的主凶。
不使用一个对象时使用:del object 来删除一个对象的引用计数就可以有效防止内存泄漏问题。
通过 Python 扩展模块 gc 来查看不能回收的对象的详细信息。
可以通过 sys.getrefcount(obj) 来获取对象的引用计数,并根据返回值是否为 0 来判断是否内存泄漏。
111.Python 函数调用的时候参数的传递方式是值传递还是引用传递?
Python 的参数传递有:位置参数、默认参数、可变参数、关键字参数。
函数的传值到底是值传递还是引用传递,要分情况:
不可变参数用值传递:
像整数和字符串这样的不可变对象,是通过拷贝进行传递的,因为你无论如何都不可能在原处改变不可变对象
可变参数是引用传递的:
比如像列表,字典这样的对象是通过引用传递、和 C 语言里面的用指针传递数组很相似,可变对象能在函数内部改变。
112.有这样一段代码,print c 会输出什么,为什么?
a = 10
b = 20
c = [a]
print(c) #[10]
a = 15
print(c) #[10]
113.print(list(map(lambda x: x * x, [y for y in range(3)])))的输出?
[0,1,4]
114.hasattr() getattr() setattr() 函数使用详解?
hasattr(object, name)函数:
判断一个对象里面是否有 name 属性或者 name 方法,返回 bool 值,有 name 属性(方法)返回 True,否则返False。
注意:name 要使用引号括起来。
class function_demo(object):
name = 'demo'
def run(self):
return "hello function"
functiondemo = function_demo()
res = hasattr(functiondemo, 'name')
#判断对象是否有 name 属性,True
# res = hasattr(functiondemo, "run") #判断对象是否有 run 方法,True
# res = hasattr(functiondemo, "age") #判断对象是否有 age 属性,Falsw
print(res)
getattr(object, name[,default]) 函数:
获取对象 object 的属性或者方法,如果存在则打印出来,如果不存在,打印默认值,默认值可选。
注意:如果返回的是对象的方法,则打印结果是:方法的内存地址,如果需要运行这个方法,可以在后面添加括号()。
functiondemo = function_demo()
getattr(functiondemo, 'name') #获取 name 属性,存在就打印出来--- demo
getattr(functiondemo, "run") #获取 run 方法,存在打印出 方法的内存地址--->
getattr(functiondemo, "age") #获取不存在的属性,报错如下:
Traceback (most recent call last):
File "/Users/liuhuiling/Desktop/MT_code/OpAPIDemo/conf/OPCommUtil.py", line 39, in <module>
res = getattr(functiondemo, "age")
AttributeError: 'function_demo' object has no attribute 'age'
getattr(functiondemo, "age", 18)
#获取不存在的属性,返回一个默认值
setattr(object,name,values)函数:
给对象的属性赋值,若属性不存在,先创建再赋值
class function_demo(object):
name = 'demo'
def run(self):
return "hello function"
functiondemo = function_demo()
res = hasattr(functiondemo, 'age')
# 判断 age 属性是否存在,False
print(res)
setattr(functiondemo, 'age', 18 )
#对 age 属性进行赋值,无返回值
res1 = hasattr(functiondemo, 'age') #再次判断属性是否存在,True
综合使用:
class function_demo(object):
name = 'demo'
def run(self):
return "hello function"
functiondemo = function_demo()
res = hasattr(functiondemo, 'addr') # 先判断是否存在
if res:
addr = getattr(functiondemo, 'addr')
print(addr)
else:
addr = getattr(functiondemo, 'addr', setattr(functiondemo, 'addr', '北京首都'))
#addr = getattr(functiondemo, 'addr', '美国纽约')
print(addr)
115.一句话解决阶乘函数?
在 Python2 中:
1.reduce(lambda x,y: x*y, range(1,n+1))
注意:Python3 中取消了该函数。
116.请手写一个单例
class A(object):
__instance = None
def __new__(cls, *args, **kwargs):
if cls.__instance is None:
cls.__instance = object.__new__(cls)
return cls.__instance
else:
return cls.__instance
117.函数装饰器有什么作用?
装饰器本质上是一个 Python 函数,它可以在让其他函数在不需要做任何代码的变动的前提下增加额外的功能。装
饰器的返回值也是一个函数的对象,它经常用于有切面需求的场景。 比如:插入日志、性能测试、事务处理、缓存、
权限的校验等场景 有了装饰器就可以抽离出大量的与函数功能本身无关的雷同代码并发并继续使用。
118.X 是什么类型?
X = (for i in range(10))
X 是 generator 类型。
119.Python 中 yield 的用法?
yield 就是保存当前程序执行状态。你用 for 循环的时候,每次取一个元素的时候就会计算一次。用 yield 的函数叫 generator,和 iterator 一样,它的好处是不用一次计算所有元素,而是用一次算一次,可以节省很多空间。generator
每次计算需要上一次计算结果,所以用 yield,否则一 return,上次计算结果就没了。
def createGenerator():
mylist = range(3)
for i in mylist:
yield i*i
mygenerator = createGenerator() # create a generator
print(mygenerator) # mygenerator is an object!
<generator object createGenerator at 0xb7555c34>
for i in mygenerator:
print(i)
#0 1 4
120.Python 中的可变对象和不可变对象?
不可变对象,该对象所指向的内存中的值不能被改变。当改变某个变量时候,由于其所指的值不能被改变,相当
于把原来的值复制一份后再改变,这会开辟一个新的地址,变量再指向这个新的地址。
可变对象,该对象所指向的内存中的值可以被改变。变量(准确的说是引用)改变后,实际上是其所指的值直接
发生改变,并没有发生复制行为,也没有开辟新的出地址,通俗点说就是原地改变。
Python 中,数值类型(int 和 float)、字符串 str、元组 tuple 都是不可变类型。而列表 list、字典 dict、集合
set 是可变类型。
121.Python 中 is 和==的区别?
is 判断的是 a 对象是否就是 b 对象,是通过 id 来判断的。
==判断的是 a 对象的值是否和 b 对象的值相等,是通过 value 来判断的。
122.谈谈你对面向对象的理解?
面向对象是相对于面向过程而言的。面向过程语言是一种基于功能分析的、以算法为中心的程序设计方法;而面
向对象是一种基于结构分析的、以数据为中心的程序设计思想。在面向对象语言中有一个有很重要东西,叫做类。
面向对象有三大特性:封装、继承、多态。
123.请写出下列正则关键字的含义?
| 语法 | 说明 | 表达式实例 | 完整匹配的字符串 |
|---|---|---|---|
| . | 匹配任意除换行符"\n"外的字符。在 DOTALL 模式中也能匹配换行符。 | a.c | abc |
| \ | 转义字符,使后一个字符改变原来的意思。如果字符串中有字符需要匹配,可以使用*或者字符集[] | a.c 或a\c | a. c 或 a\c |
| […] | 字符集(字符类)。对应的位置可以是字符集中任意字符。字符集中的字符可以逐个列出,也可以给出范围,如[abc]或[a-c]。第一个字符如果是则表示取反,如[^abc]表示不是 abc的其他字符。所有的特殊字符在字符集中都失去其原有的特殊含义。在字符集中如果要使用]、-或,可以在前面加上反斜杠,或把]、-放在第一个字符,把放在非第—个字符。 | a[bcd]e | abe 或ace 或 ade |
| \d | 数字:[0-9] | a\dc | alc |
| \D | 非数字:[^\d] | a\Dc | abc |
| \s | 空白字符:[<空格>\ t\r\n\f\v] | a\sc | ac |
| \S | 非空白字符:[^\s] | a\Sc | abc |
| \w | 单词字符:[A-Za-z0-9_] | a\wc | abc |
| \W | 非单词字符:[^\W] | a\Wc | ac |
| * | 匹配前一个字符 0 或无限次。 | abc* | ab abccc |
| + | 匹配前一个字符 1 次或无限次 | abc+ | abc abccc |
| ? | 匹配前一个字符 0 次或 1 次。 | abc? | Ab abc |
| {m} | 匹配前一个字符 m 次 | ab{2}c | abbc |
124.进程总结
进程:程序运行在操作系统上的一个实例,就称之为进程。进程需要相应的系统资源:内存、时间片、pid。
创建进程:
1.首先要导入 multiprocessing 中的 Process;
2.创建一个 Process 对象;
3.创建 Process 对象时,可以传递参数;
1.p = Process(target=XXX, args=(元组,) , kwargs={key:value})
2.target = XXX 指定的任务函数,不用加()
3.args=(元组,) , kwargs={key:value} 给任务函数传递
4.使用 start()启动进程;
5.结束进程。
Process 语法结构:
Process([group [, target [, name [, args [, kwargs]]]]])
target:如果传递了函数的引用,可以让这个子进程就执行函数中的代码
args:给 target 指定的函数传递的参数,以元组的形式进行传递
kwargs:给 target 指定的函数传递参数,以字典的形式进行传递
name:给进程设定一个名字,可以省略
group:指定进程组,大多数情况下用不到
Process 创建的实例对象的常用方法有:
start():启动子进程实例(创建子进程)
is_alive():判断进程子进程是否还在活着
join(timeout):是否等待子进程执行结束,或者等待多少秒
terminate():不管任务是否完成,立即终止子进程
Process 创建的实例对象的常用属性:
name:当前进程的别名,默认为 Process-N,N 为从 1 开始递增的整数
pid:当前进程的 pid(进程号)
给子进程指定函数传递参数 Demo:
import os
from multiprocessing import Process
import time
def pro_func(name, age, **kwargs):
for i in range(5):
print("子进程正在运行中,name=%s, age=%d, pid=%d" %(name, age, os.getpid()))
print(kwargs)
time.sleep(0.2)
if __name__ == '__main__':
# 创建 Process 对象
p = Process(target=pro_func, args=('小明',18), kwargs={'m': 20})
# 启动进程
p.start()
time.sleep(1)
# 1 秒钟之后,立刻结束子进程
p.terminate()
p.join()
注意:进程间不共享全局变量。
进程之间的通信-Queue
在初始化 Queue()对象时,(例如 q=Queue(),若在括号中没有指定最大可接受的消息数量,或数量为负值时,那么就代表可接受的消息数量没有上限-直到内存的尽头)
Queue.qsize():返回当前队列包含的消息数量。
Queue.empty():如果队列为空,返回 True,反之 False。
Queue.full():如果队列满了,返回 True,反之 False。
Queue.get([block[,timeout]]):获取队列中的一条消息,然后将其从队列中移除,block 默认值为True。
如果 block 使用默认值,且没有设置 timeout(单位秒),消息列队如果为空,此时程序将被阻塞(停在读取状态),直到从消息列队读到消息为止,如果设置了 timeout,则会等待 timeout 秒,若还没读取到任何消息,则出"Queue.Empty"异常;
如果 block 值为 False,消息列队如果为空,则会立刻抛出"Queue.Empty"异常;
Queue.get_nowait():相当 Queue.get(False);
Queue.put(item,[block[, timeout]]):将 item 消息写入队列,block 默认值为 True;
如果 block 使用默认值,且没有设置 timeout(单位秒),消息列队如果已经没有空间可写入,此时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止,如果设置了 timeout,则会等待timeout 秒,若还没空间,则出"Queue.Full"异常;
如果 block 值为 False,消息列队如果没有空间可写入,则会立刻抛出"Queue.Full"异常;
Queue.put_nowait(item):相当 Queue.put(item, False);
进程间通信 Demo:
from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
def write(q):
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码:def read(q):
while True:
if not q.empty():
value = q.get(True)
print('Get %s from queue.' % value)
time.sleep(random.random())
else:
break
if __name__=='__main__':
# 父进程创建 Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程 pw,写入:
pw.start()
# 等待 pw 结束:
pw.join()
# 启动子进程 pr,读取:
pr.start()
pr.join()
# pr 进程里是死循环,无法等待其结束,只能强行终止:
print('')
print('所有数据都写入并且读完')
进程池 Pool
# -*- coding:utf-8 -*-
from multiprocessing import Pool
import os, time, random
def worker(msg):
t_start = time.time()
print("%s 开始执行,进程号为%d" % (msg,os.getpid()))
# random.random()随机生成 0~1 之间的浮点数
time.sleep(random.random()*2)
t_stop = time.time()
print(msg,"执行完毕,耗时%0.2f" % (t_stop-t_start))
po = Pool(3)
# 定义一个进程池,最大进程数 3
for i in range(0,10):
# Pool().apply_async(要调用的目标,(传递给目标的参数元祖,))
# 每次循环将会用空闲出来的子进程去调用目标
po.apply_async(worker,(i,))
print("----start----")
po.close() # 关闭进程池,关闭后 po 不再接收新的请求
po.join()
# 等待 po 中所有子进程执行完成,必须放在 close 语句之后
print("-----end-----")
multiprocessing.Pool 常用函数解析:
apply_async(func[, args[, kwds]]) :使用非阻塞方式调用 func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args 为传递给 func 的参数列表,kwds 为传递给 func的关键字参数列表;
close():关闭 Pool,使其不再接受新的任务;
terminate():不管任务是否完成,立即终止;
join():主进程阻塞,等待子进程的退出, 必须在 close 或 terminate 之后使用;
进程池中使用 Queue
如果要使用 Pool 创建进程,就需要使用 multiprocessing.Manager()中的 Queue(),而不是
multiprocessing.Queue(),否则会得到一条如下的错误信息:
RuntimeError: Queue objects should only be shared between processes through inheritance.
from multiprocessing import Manager,Pool
import os,time,random
def reader(q):
print("reader 启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in range(q.qsize()):
print("reader 从 Queue 获取到消息:%s" % q.get(True))
def writer(q):
print("writer 启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in "itcast":
q.put(i)
if __name__=="__main__":
print("(%s) start" % os.getpid())
q = Manager().Queue() # 使用 Manager 中的 Queue
po = Pool()
po.apply_async(writer, (q,))
time.sleep(1)
# 先让上面的任务向 Queue 存入数据,然后再让下面的任务开始从中取数据
po.apply_async(reader, (q,))
po.close()
po.join()
print("(%s) End" % os.getpid())
125.谈谈你对多进程,多线程,以及协程的理解,项目是否用?
这个问题被问的概率相当之大,其实多线程,多进程,在实际开发中用到的很少,除非是那些对项目性能要求特别高的,有的开发工作几年了,也确实没用过,你可以这么回答,给他扯扯什么是进程,线程(cpython 中是伪多线程)的概念就行,实在不行你就说你之前写过下载文件时,用过多线程技术,或者业余时间用过多线程写爬虫,提升效率。
进程:一个运行的程序(代码)就是一个进程,没有运行的代码叫程序,进程是系统资源分配的最小单位,进程拥有自己独立的内存空间,所以进程间数据不共享,开销大。
线程: 调度执行的最小单位,也叫执行路径,不能独立存在,依赖进程存在一个进程至少有一个线程,叫主线程,而多个线程共享内存(数据共享,共享全局变量),从而极大地提高了程序的运行效率。
协程:是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。 协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
126.什么是多线程竞争?
线程是非独立的,同一个进程里线程是数据共享的,当各个线程访问数据资源时会出现竞争状态即:
数据几乎同步会被多个线程占用,造成数据混乱 ,即所谓的线程不安全
那么怎么解决多线程竞争问题?-- 锁。
锁的好处:
确保了某段关键代码(共享数据资源)只能由一个线程从头到尾完整地执行能解决多线程资源竞争下的原子操作问题。
锁的坏处:
阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了
锁的致命问题:死锁。
127.IO 密集型和 CPU 密集型区别?
IO 密集型:系统运作,大部分的状况是 CPU 在等 I/O (硬盘/内存)的读/写。
CPU 密集型:大部份时间用来做计算、逻辑判断等 CPU 动作的程序称之 CPU 密集型。
128.UDP总结
UDP 协议
UDP 是User Datagram Protocol的简称, 中文名是用户数据报协议,是OSI(Open System Interconnection,开放式系统互联) 参考模型中一种无连接的传输层协议,提供面向事务的简单不可靠信息传送服务,IETF RFC 768是UDP的正式规范。UDP在IP报文的协议号是17。
UDP的优点
快,比TCP稍安全
UDP没有TCP的握手、确认、窗口、重传、拥塞控制等机制,UDP是一个无状态的传输协议,所以它在传递数据时非常快。没有TCP的这些机制,UDP较TCP被攻击者利用的漏洞就要少一些。但UDP也是无法避免攻击的,比如:UDP Flood攻击……
UDP的缺点
不可靠,不稳定
因为UDP没有TCP那些可靠的机制,在数据传递时,如果网络质量不好,就会很容易丢包。
UDP应用场景
当对网络通讯质量要求不高的时候,要求网络通讯速度能尽量的快,这时就可以使用UDP。在日常生活中,常见使用UDP协议的应用比如:QQ语音、QQ视频、TFTP等。
TCP和UDP使用IP协议从一个网络传送数据包到另一个网络。把IP想像成一种高速公路,它允许其它协议在上面行驶并找到到其它电脑的出口。TCP和UDP是高速公路上的“卡车”,它们携带的货物就是像HTTP,文件传输协议FTP这样的协议等。
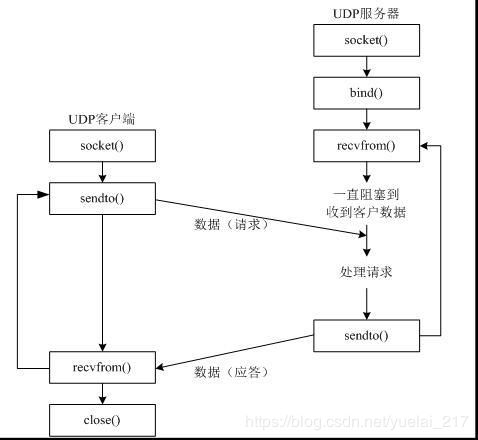
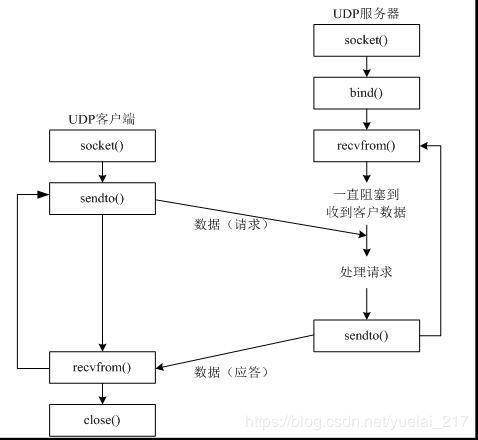
使用 udp 发送/接收数据步骤:
1.创建客户端套接字
2.发送/接收数据
3.关闭套接字
import socket
def main():
# 1、创建 udp 套接字
# socket.AF_INET
# socket.SOCK_DGRAM 数据报套接字,只要用于 udp 协议
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 2、准备接收方的地址
# 元组类型 ip 是字符串类型 端口号是整型
dest_addr = ('192.168.113.111', 8888)
# 要发送的数据
send_data = "我是要发送的数据"
# 3、发送数据
udp_socket.sendto(send_data.encode("utf-8"), dest_addr)
# 4、等待接收方发送的数据 如果没有收到数据则会阻塞等待,直到收到数据
# 接收到的数据是一个元组(接收到的数据, 发送方的 ip 和端口)
# 1024 表示本次接收的最大字节数
recv_data, addr = udp_socket.recvfrom(1024)
# 5、关闭套接字
udp_socket.close()
if __name__ == '__main__':
main()
编码的转换
str -->bytes: encode 编码
bytes–> str: decode()解码
UDP 绑定端口号:
1.创建 socket 套接字
2.绑定端口号
3.接收/发送数据
4.关闭套接字
import socket
def main():
# 1、创建 udp 套接字
# socket.AF_INET表示 IPv4 协议 AF_INET6 表示 IPv6 协议
# socket.SOCK_DGRAM 数据报套接字,只要用于 udp 协议
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 2、绑定端口
# 元组类型 ip 一般不写 表示本机的任何的一个 ip
local_addr = ('', 7777)
udp_socket.bind(local_addr)
# 3、准备接收方的地址
# 元组类型 ip 是字符串类型 端口号是整型
dest_addr = ('192.168.113.111', 8888)
# 要发送的数据
send_data = "我是要发送的数据"
# 4、发送数据
udp_socket.sendto(send_data.encode("utf-8"), dest_addr)
# 5、等待接收方发送的数据 如果没有收到数据则会阻塞等待,直到收到数据
# 接收到的数据是一个元组(接收到的数据, 发送方的 ip 和端口)
# 1024 表示本次接收的最大字节数
recv_data, addr = udp_socket.recvfrom(1024)
# 6、关闭套接字
udp_socket.close()
if __name__ == '__main__':
main()
129.TCP总结
TCP协议
TCP(Transmission Control Protocol 传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC 793定义。在简化的计算机网络OSI模型中,它完成第四层传输层所指定的功能,用户数据报协议(UDP)是同一层内另一个重要的传输协议。
在因特网协议族(Internet protocol suite)中,TCP层是位于IP层之上,应用层之下的中间层。不同主机的应用层之间经常需要可靠的、像管道一样的连接,但是IP层不提供这样的流机制,而是提供不可靠的包交换。
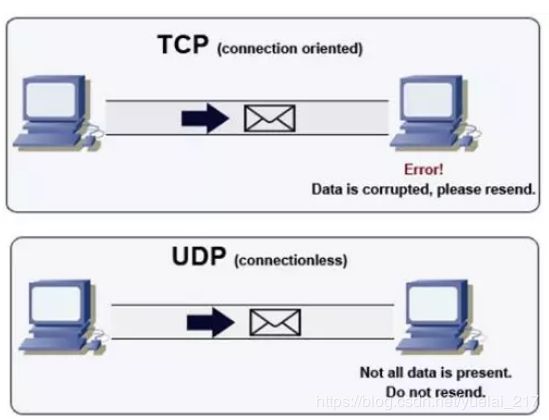
TCP的优点
可靠,稳定
TCP的可靠体现在TCP在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源。
TCP的缺点
慢,效率低,占用系统资源高,易被攻击
TCP在传递数据之前,要先建连接,这会消耗时间,而且在数据传递时,确认机制、重传机制、拥塞控制机制等都会消耗大量的时间,而且要在每台设备上维护所有的传输连接,事实上,每个连接都会占用系统的CPU、内存等硬件资源。
由于TCP存在确认机制和三次握手机制,这些是导致TCP容易被人利用,实现DOS、DDOS、CC等攻击。
TCP应用场景
当对网络通讯质量有要求的时候,比如:整个数据要准确无误的传递给对方,这往往用于一些要求可靠的应用,比如HTTP、HTTPS、FTP等传输文件的协议,POP、SMTP等邮件传输的协议。
在日常生活中,常见使用TCP协议的应用比如:浏览器使用HTTP,Outlook使用POP、SMTP,QQ文件传输等。
tcp/ip协议
TCP/IP是个协议组,可分为三个层次:网络层、传输层和应用层。
在网络层有:IP协议、ICMP协议、ARP协议、RARP协议和BOOTP协议。
在传输层中有:TCP协议与UDP协议。
在应用层有:FTP、HTTP、TELNET、SMTP、DNS等协议。
因此,HTTP本身就是一个协议,是从Web服务器传输超文本到本地浏览器的传送协议。
TCP和UDP是FTP,HTTP和SMTP之类使用的传输层协议。虽然TCP和UDP都是用来传输其他协议的,它们却有一个显著的不同:TCP提供有保证的数据传输,而UDP不提供。这意味着TCP有一个特殊的机制来确保数据安全的不出错的从一个端点传到另一个端点,而UDP不提供任何这样的保证。
TCP 客户端的创建流程:
1.创建 TCP 的 socket 套接字
2.连接服务器
3.发送数据给服务器端
4.接收服务器端发送来的消息
5.关闭套接字
import socket
def main():
# 1、创建客户端的 socket
# socket.AF_INET表示 IPv4 协议 AF_INET6 表示 IPv6 协议
# socket.SOCK_STREAM 流式套接字,只要用于 TCP 协议
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 2、构建目标地址
server_ip = input("请输入服务器端的 IP 地址:")
server_port = int(input("请输入服务器端的端口号:"))
# 3、连接服务器
# 参数:元组类型 ip 是字符串类型 端口号是整型
client_socket.connect((server_ip, server_port))
# 要发送给服务器端的数据
send_data = "我是要发送给服务器端的数据"
# 4、发送数据
client_socket.send(send_data.encode("gbk"))
# 5、接收服务器端恢复的消息, 没有消息会阻塞
# 1024 表示接收的最大字节数
recv_date= client_socket.recv(1024)
print("接收到的数据是:", recv_date.decode('gbk'))
# 6、关闭套接字
client_socket.close()
if __name__ == '__main__':
main()
TCP 服务器端的创建流程
1.创建 TCP 服务端的 socket
2.bing 绑定 ip 地址和端口号
3.listen 使套接字变为被动套接字
4.accept 取出一个客户端连接,用于服务
5.recv/send 接收和发送消息
6.关闭套接字
import socket
def main():
# 1、创建 tcp 服务端的 socket
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 2、绑定
server_socket.bind(('', 8888))
# 3、listen 使套接字变为被动套接字
server_socket.listen(128)
# 4、如果有新的客户端来链接服务器,那么就产生一个新的套接字专门为这个客户端服务
# client_socket 用来为这个客户端服务
# tcp_server_socket 就可以省下来专门等待其他新客户端的链接
client_socket, client_addr = server_socket.accept()
# 5、接收客户端发来的消息
recv_data = client_socket.recv(1024)
print("接收到客户端%s 的数据:%s" % (str(client_addr), recv_data.decode('gbk')))
# 6、回复数据给客户端
client_socket.send("收到消息".encode('gbk'))
# 7、关闭套接字
client_socket.close()
server_socket.close()
if __name__ == '__main__':
main()
注意点:
tcp 服务器一般都需要绑定,否则客户端找不到服务器
tcp 客户端一般不绑定,因为是主动链接服务器,所以只要确定好服务器的 ip、port 等信息就好,本地客户端可以随机
tcp 服务器中通过 listen 可以将 socket 创建出来的主动套接字变为被动的,这是做 tcp 服务器时必须要做的
当客户端需要链接服务器时,就需要使用 connect 进行链接,udp 是不需要链接的而是直接发送,但是 tcp 必须先链接,只有链接成功才能通信
当一个 tcp 客户端连接服务器时,服务器端会有 1 个新的套接字,这个套接字用来标记这个客户端,单独为这个客户端服务
listen 后的套接字是被动套接字,用来接收新的客户端的连接请求的,而 accept 返回的新套接字是标识这个新客户端的
关闭 listen 后的套接字意味着被动套接字关闭了,会导致新的客户端不能够链接服务器,但是之前已经链接成功的客户端正常通信。
关闭 accept 返回的套接字意味着这个客户端已经服务完毕
当客户端的套接字调用 close 后,服务器端会 recv 解阻塞,并且返回的长度为 0,因此服务器可以通过返回数据的长度来区别客户端是否已经下线;同理 当服务器断开 tcp 连接的时候 客户端同样也会收到 0 字节数据。
130.怎么实现强行关闭客户端和服务器之间的连接?
在 socket 通信过程中不断循环检测一个全局变量(开关标记变量),一旦标记变量变为关闭,则 调用 socket 的 close 方法,循环结束,从而达到关闭连接的目的。
131.简述 TCP 和 UDP 的区别以及优缺点?
UDP 是面向无连接的通讯协议,UDP 数据包括目的端口号和源端口号信息。
优点:UDP 速度快、操作简单、要求系统资源较少,由于通讯不需要连接,可以实现广播发送
缺点:UDP 传送数据前并不与对方建立连接,对接收到的数据也不发送确认信号,发送端不知道数据是否会正确接收,也不重复发送,不可靠。
TCP 是面向连接的通讯协议,通过三次握手建立连接,通讯完成时四次挥手
优点:TCP 在数据传递时,有确认、窗口、重传、阻塞等控制机制,能保证数据正确性,较为可靠。
缺点:TCP 相对于 UDP 速度慢一点,要求系统资源较多。
区别:
1、TCP 面向连接(如打电话要先拨号建立连接);UDP 是无连接的,即发送数据之前不需要建立连接
2、TCP 提供可靠的服务。也就是说,通过 TCP 连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP 尽最大努力交付,即不保证可靠交付
3、TCP 面向字节流,实际上是 TCP 把数据看成一连串无结构的字节流;UDP 是面向报文的,UDP 没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如 IP 电话,实时视频会议等)
4、每一条 TCP 连接只能是点到点的;UDP 支持一对一,一对多,多对一和多对多的交互通信
5、TCP 首部开销 20 字节;UDP 的首部开销小,只有 8 个字节
6、TCP 的逻辑通信信道是全双工的可靠信道,UDP 则是不可靠信道
| 选项 | UDP | TCP |
|---|---|---|
| 连接 | 无连接 | 面向连接 |
| 速度 | 无需建立连接,速度较快 | 需要建立连接,速度较慢 |
| 目的主机 | 一对一,一对多 | 仅能一对一 |
| 带宽 | UDP报头较短,消耗带宽更少 | 消耗更多带宽 |
| 消息边界 | 有 | 无 |
| 可靠性 | 低 | 高 |
| 顺序 | 无序 | 有序 |
132.简述浏览器通过 WSGI 请求动态资源的过程?
1.发送 http 请求动态资源给 web 服务器
2.web 服务器收到请求后通过 WSGI 调用一个属性给应用程序框架
3.应用程序框架通过引用 WSGI 调用 web 服务器的方法,设置返回的状态和头信息。
4.调用后返回,此时 web 服务器保存了刚刚设置的信息
5.应用程序框架查询数据库,生成动态页面的 body 的信息
6.把生成的 body 信息返回给 web 服务器
7.web 服务器吧数据返回给浏览器
133.描述用浏览器访问 www.baidu.com 的过程
先要解析出 baidu.com 对应的 ip 地址
要先使用 arp 获取默认网关的 mac 地址
组织数据发送给默认网关(ip 还是 dns 服务器的 ip,但是 mac 地址是默认网关的 mac 地址)
默认网关拥有转发数据的能力,把数据转发给路由器
路由器根据自己的路由协议,来选择一个合适的较快的路径转发数据给目的网关
目的网关(dns 服务器所在的网关),把数据转发给 dns 服务器
dns 服务器查询解析出 baidu.com 对应的 ip 地址,并原路返回请求这个域名的 client得到了 baidu.com 对应的 ip 地址之后,会发送 tcp 的 3 次握手,进行连接
使用 http 协议发送请求数据给 web 服务器
web 服务器收到数据请求之后,通过查询自己的服务器得到相应的结果,原路返回给浏览器。
浏览器接收到数据之后通过浏览器自己的渲染功能来显示这个网页。
浏览器关闭 tcp 连接,即 4 次挥手结束,完成整个访问过程
134.Post 和 Get 请求的区别?
概念:
GET 请求,请求的数据会附加在 URL 之后,以?分割 URL 和传输数据,多个参数用&连接。URL 的编码格式采用的是 ASCII 编码,而不是 uniclde,即是说所有的非 ASCII 字符都要编码之后再传输。
POST 请求:POST 请求会把请求的数据放置在 HTTP 请求包的包体中。上面的 item=bandsaw 就是实际的传输数据。
因此,GET 请求的数据会暴露在地址栏中,而 POST 请求则不会。
传输数据的大小:
在 HTTP 规范中,没有对 URL 的长度和传输的数据大小进行限制。但是在实际开发过程中,对于 GET,特定的浏览器和服务器对 URL 的长度有限制。因此,在使用 GET 请求时,传输数据会受到 URL 长度的限制。
对于 POST,由于不是 URL 传值,理论上是不会受限制的,但是实际上各个服务器会规定对 POST提交数据大小进行限制,Apache、IIS 都有各自的配置。
安全性:
POST 的安全性比 GET 的高。这里的安全是指真正的安全,而不同于上面 GET 提到的安全方法中的安全,上面提到的安全仅仅是不修改服务器的数据。比如,在进行登录操作,通过 GET 请求,用户名和密码都会暴露再 URL 上,因为登录页面有可能被浏览器缓存以及其他人查看浏览器的历史记录的原因,此时的用户名和密码就很容易被他人拿到了。除此之外,GET 请求提交的数据还可能会造成 Cross-site request frogery 攻击。
效率:
GET 比 POST 效率高。
请求过程:
POST 请求的过程:
1.浏览器请求 tcp 连接(第一次握手)
2.服务器答应进行 tcp 连接(第二次握手)
3.浏览器确认,并发送 post 请求头(第三次握手,这个报文比较小,所以 http 会在此时进行第一次数据发送)
4.服务器返回 100 continue 响应
5.浏览器开始发送数据
6.服务器返回 200 ok 响应
GET 请求的过程:
1.浏览器请求 tcp 连接(第一次握手)
2.服务器答应进行 tcp 连接(第二次握手)
3.浏览器确认,并发送 get 请求头和数据(第三次握手,这个报文比较小,所以 http 会在此时进行第一次数据发送)
4.服务器返回 200 OK 响应
| 操作 | GET | POST |
|---|---|---|
| 后退按钮/刷新 | 无害 | 数据会被重新提交(浏览器应该告知用户数据会被重新提交) |
| 书签 | 可收藏为书签 | 不可收藏为书签 |
| 缓存 | 能被缓存 | 不能缓存 |
| 编码类型 | application/x-www-form-urlencoded | application/x-www-form-urlencoded 或multipart/form-data。为二进制数据使用多重编码。 |
| 历史 | 参数保留在浏览器历史中。 | 参数不会保存在浏览器历史中。 |
| 对数据长度的限制 | 是的。当发送数据时,GET 方法向 URL 添加数据;URL 的长度是受限制的(URL 的最大长度是 2048 个字符)。 | 无限制。 |
| 对数据类型的限制 | 只允许 ASCII 字符。 | 没有限制。也允许二进制数据。 |
| 安全性 | 与 POST 相比,GET 的安全性较差,因为所发送的数据是 URL 的一部分。在发送密码或其他敏感信息时绝不要使GET ! | POST 比 GET 更安全,因为参数不会被保存在浏览器历史或 web 服务器日志中 |
| 可见性 | 数据在 URL 中对所有人都是可见的。 | 数据不会显示在 URL 中。 |
135.cookie 和 session 的区别?
cookie(储存在用户本地终端上的数据):指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)。
Session技术:
是一种将会话状态保存在服务器端的技术,它可以比喻成是医院发放给病人的病历卡和医院为每个病人保留的病历档案的结合方式。客户端需要接收、记忆和回送Session的会话标识号,Session可以且通常是借助Cookie来传递会话标识号。
1、cookie 数据存放在客户的浏览器上,session 数据放在服务器上。
2、cookie 不是很安全,别人可以分析存放在本地的 cookie 并进行 cookie 欺骗考虑到安全应当使用 session。
3、session 会在一定时间内保存在服务器上。当访问增多,会比较占用服务器的性能考虑到减轻服务器性能方面,应当使用 cookie。
4、单个 cookie 保存的数据不能超过 4K,很多浏览器都限制一个站点最多保存 20 个 cookie。
5、建议: 将登陆信息等重要信息存放为 SESSION 其他信息如果需要保留,可以放在 cookie 中
136.HTTP 协议状态码有什么用,列出你知道的 HTTP 协议的状态码,然后讲出他们都表示什么意思?
通过状态码告诉客户端服务器的执行状态,以判断下一步该执行什么操作。
常见的状态机器码有:
1xx:指示信息–表示请求已接收,继续处理
2xx:成功–表示请求已被成功接收、理解、接受
3xx:重定向–要完成请求必须进行更进一步的操作
4xx:客户端错误–请求有语法错误或请求无法实现
5xx:服务器端错误–服务器未能实现合法的请求
100-199:表示服务器成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程。
200-299:表示服务器成功接收请求并已完成处理过程,常用 200(OK 请求成功)。
300-399:为完成请求,客户需要进一步细化请求。302(所有请求页面已经临时转移到新的 url)。
304、307(使用缓存资源)。
400-499:客户端请求有错误,常用 404(服务器无法找到被请求页面),403(服务器拒绝访问,权限不够)。
500-599:服务器端出现错误,常用 500(请求未完成,服务器遇到不可预知的情况)。
| 状态码 | 简明解释 | 详细阐述 |
|---|---|---|
| 2开头 (请求成功)表示成功处理了请求的状态代码。 | ||
| 200 | 成功 | 服务器已成功处理了请求。通常这表示服务器提供了请求的网页。 |
| 201 | 已创建 | 请求成功并且服务器创建了新的资源。 |
| 202 | 已接受 | 服务器已接受请求,但尚未处理。 |
| 203 | 非授权信息 | 服务器已成功处理了请求,但返回的信息可能来自另一来源。 |
| 204 | 无内容 | 服务器成功处理了请求,但没有返回任何内容。 |
| 205 | 重置内容 | 服务器成功处理了请求,但没有返回任何内容。 |
| 206 | 部分内容 | 服务器成功处理了部分 GET 请求。 |
| 3开头 (请求被重定向)表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向。 | ||
| 300 | 多种选择 | 针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。 |
| 301 | 永久移动 | 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。 |
| 302 | 临时移动 | 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。 |
| 303 | 查看其他位置 | 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。 |
| 304 | 未修改 | 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。 |
| 305 | 使用代理 | 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。 |
| 307 | 临时重定向 | 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。 |
| 4开头 (请求错误)这些状态代码表示请求可能出错,妨碍了服务器的处理。 | ||
| 400 | 错误请求 | 服务器不理解请求的语法。 |
| 401 | 未授权 | 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。 |
| 403 | 禁止 | 服务器拒绝请求。 |
| 404 | 未找到 | 服务器找不到请求的网页。 |
| 405 | 方法禁用 | 禁用请求中指定的方法。 |
| 406 | 不接受 | 无法使用请求的内容特性响应请求的网页。 |
| 407 | 需要代理授权 | 此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理。 |
| 408 | 请求超时 | 服务器等候请求时发生超时。 |
| 409 | 冲突 | 服务器在完成请求时发生冲突。 服务器必须在响应中包含有关冲突的信息。 |
| 410 | 已删除 | 如果请求的资源已永久删除,服务器就会返回此响应。 |
| 411 | 需要有效长度 | 服务器不接受不含有效内容长度标头字段的请求。 |
| 412 | 未满足前提条件 | 服务器未满足请求者在请求中设置的其中一个前提条件。 |
| 413 | 请求实体过大 | 服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。 |
| 414 | 请求的 URl 过长 | 请求的 URl(通常为网址)过长,服务器无法处理。 |
| 415 | 不支持的媒体类型 | 请求的格式不受请求页面的支持。 |
| 416 | 请求范围不符合要求 | 如果页面无法提供请求的范围,则服务器会返回此状态代码。 |
| 417 | 未满足期望值 | 服务器未满足”期望”请求标头字段的要求。 |
| 5开头(服务器错误)这些状态代码表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身的错误,而不是请求出错。 | ||
| 500 | 服务器内部错误 | 服务器遇到错误,无法完成请求。 |
| 501 | 尚未实施 | 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。 |
| 502 | 错误网关 | 服务器作为网关或代理,从上游服务器收到无效响应。 |
| 503 | 服务不可用 | 服务器目前无法使用(由于超载或停机维护).通常,这只是暂时状态。 |
| 504 | 网关超时 | 服务器作为网关或代理,但是没有及时从上游服务器收到请求。 |
| 505 | HTTP 版本不受支持 | 服务器不支持请求中所用的 HTTP 协议版本。 |
137.请简单说一下三次握手和四次挥手?
[外链图片转存失败(img-ESdWuT4x-1567394093107)(/home/tarena/图片/三次握手.png)]
三次握手过程:
1 首先客户端向服务端发送一个带有 SYN 标志,以及随机生成的序号 100(0 字节)的报文
2 服务端收到报文后返回一个报文(SYN200(0 字节),ACk1001(字节+1))给客户端
3 客户端再次发送带有 ACk 标志 201(字节+)序号的报文给服务端至此三次握手过程结束,客户端开始向服务端发送数据.
1 客户端向服务端发起请求:我想给你通信,你准备好了么?
2 服务端收到请求后回应客户端:I’ok,你准备好了么
3 客户端礼貌的再次回一下客户端:准备就绪,咱们开始通信吧!
整个过程跟打电话的过程一模一样:1 喂,你在吗 2 在,我说的你听得到不 3 恩,听得到(接下来请开始你的表演)
补充:SYN:请求询问,ACk:回复,回应。
四次挥手过程:
由于 TCP 连接是可以双向通信的(全双工),因此每个方向都必须单独进行关闭(这句话才是精辟,后面四个挥手过程都是其具体实现的语言描述)
四次挥手过程,客户端和服务端都可以先开始断开连接
1 客户端发送带有 fin 标识的报文给服务端,请求通信关闭
2 服务端收到信息后,回复 ACK 答应关闭客户端通信(连接)请求
3 服务端发送带有 fin 标识的报文给客户端,也请求关闭通信
4 客户端回应 ack 给服务端,答应关闭服务端的通信(连接)请求
138.说一下什么是 tcp 的 2MSL?
主动发送 fin 关闭的一方,在 4 次挥手最后一次要等待一段时间我们称这段时间为 2MSL
TIME_WAIT 状态的存在有两个理由:
1.让 4 次挥手关闭流程更加可靠
2.防止丢包后对后续新建的正常连接的传输造成破坏
139.为什么客户端在 TIME-WAIT 状态必须等待 2MSL 的时间?
1、为了保证客户端发送的最后一个 ACK 报文段能够达到服务器。 这个 ACK 报文段可能丢失,因而使处在 LAST-ACK 状态的服务器收不到确认。服务器会超时重传 FIN+ACK 报文段,客户端就能在 2MSL 时间内收到这个重传的 FIN+ACK 报文段,接着客户端重传一次确认,重启计时器。最好,客户端和服务器都正常进入到 CLOSED 状态。如果客户端在 TIME-WAIT 状态不等待一段时间,而是再发送完 ACK 报文后立即释放连接,那么就无法收到服务器重传的 FIN+ACK 报文段,因而也不会再发送一次确认报文。这样,服务器就无法按照正常步骤进入 CLOSED 状态。
2、防止已失效的连接请求报文段出现在本连接中。客户端在发送完最后一个 ACK 确认报文段后,再经过时间2MSL,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失。这样就可以使下一个新的连接中不会出现这种旧的连接请求报文段。
140.说说 HTTP 和 HTTPS 区别?
HTTP 协议传输的数据都是未加密的,也就是明文的,因此使用 HTTP 协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了 SSL(Secure Sockets Layer)协议用于对 HTTP 协议传输的数据进行加密,从而就诞生了 HTTPS。简单来说,HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,要比 http 协议安全。
HTTPS 和 HTTP 的区别主要如下:
1、https 协议需要到 ca 申请证书,一般免费证书较少,因而需要一定费用。
2、http 是超文本传输协议,信息是明文传输,https 则是具有安全性的 ssl 加密传输协议。
3、http 和 https 使用的是完全不同的连接方式,用的端口也不一样,前者是 80,后者是 443。
4、http 的连接很简单,是无状态的;HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 http 协议安全。
141.谈一下 HTTP 协议以及协议头部中表示数据类型的字段?
HTTP 协议是 Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web)服务器传输超文本到本地浏览器的传送协议。
HTTP 是一个基于 TCP/IP 通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
HTTP 是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于 1990 年提出,经过几年的使用与发展,得到不断地完善和扩展。目前在 WWW 中使用的是 HTTP/1.0 的第六版,HTTP/1.1 的规范化工作正在进行之中,而且 HTTP-NG(NextGeneration of HTTP)的建议已经提出。
HTTP 协议工作于客户端-服务端架构为上。浏览器作为 HTTP 客户端通过 URL 向 HTTP 服务端即 WEB 服务器发送所有请求。Web 服务器根据接收到的请求后,向客户端发送响应信息。
表示数据类型字段: Content-Type
142.HTTP 请求方法都有什么?
根据 HTTP 标准,HTTP 请求可以使用多种请求方法。
HTTP1.0 定义了三种请求方法: GET, POST 和 HEAD 方法。
HTTP1.1 新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
1、 GET 请求指定的页面信息,并返回实体主体。
2、HEAD 类似于 get 请求,只不过返回的响应中没有具体的内容,用于获取报头
3、POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。
4、PUT 从客户端向服务器传送的数据取代指定的文档的内容。
5、DELETE 请求服务器删除指定的页面。
6、CONNECT HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。
7、OPTIONS 允许客户端查看服务器的性能。
8、TRACE 回显服务器收到的请求,主要用于测试或诊断。
143.使用 Socket 套接字需要传入哪些参数 ?
Address Family 和 Type,分别表示套接字应用场景和类型。
family 的值可以是 AF_UNIX(Unix 域,用于同一台机器上的进程间通讯),也可以是 AF_INET(对于 IPV4 协议的 TCP 和 UDP),至于 type 参数,SOCK_STREAM(流套接字)或者SOCK_DGRAM(数据报文套接字),SOCK_RAW(raw 套接字)。
144.HTTP 常见请求头及其作用?
-
Host (主机和端口号)
-
Connection (链接类型)
-
Upgrade-Insecure-Requests (升级为 HTTPS 请求)
-
User-Agent (浏览器名称)
-
Accept (传输文件类型)
-
Referer (页面跳转处)
-
Accept-Encoding(文件编解码格式)
-
Cookie (Cookie)
-
x-requested-with :XMLHttpRequest (是 Ajax 异步请求)
Accept:指浏览器或其他客户可以接爱的MIME文件格式。可以根据它判断并返回适当的文件格式。
Accept-Charset:指出浏览器可以接受的字符编码。英文浏览器的默认值是ISO-8859-1.
Accept-Language:指出浏览器可以接受的语言种类,如en或en-us,指英语。
Accept-Encoding:指出浏览器可以接受的编码方式。编码方式不同于文件格式,它是为了压缩文件并加速文件传递速度。浏览器在接收到Web响应之后先解码,然后再检查文件格式。
Cache-Control:设置关于请求被代理服务器存储的相关选项。一般用不到。
Connection:用来告诉服务器是否可以维持固定的HTTP连接。HTTP/1.1使用Keep-Alive为默认值,这样,当浏览器需要多个文件时(比如一个HTML文件和相关的图形文件),不需要每次都建立连接。
Content-Type:用来表名request的内容类型。可以用HttpServletRequest的getContentType()方法取得。
Cookie:浏览器用这个属性向服务器发送Cookie。Cookie是在浏览器中寄存的小型数据体,它可以记载和服务器相关的用户信息,也可以用来实现会话功能。
145.七层模型? IP ,TCP/UDP ,HTTP ,RTSP ,FTP 分别在哪层?
IP: 网络层
TCP/UDP: 传输层
HTTP、RTSP、FTP: 应用层协议
[外链图片转存失败(img-6ByQtFUy-1567394093109)(/home/tarena/图片/七层模型.png)]
146.url 的形式?
形式: scheme://host[:port#]/path/…/[?query-string][#anchor]
scheme:协议(例如:http, https, ftp)
host:服务器的 IP 地址或者域名
port:服务器的端口(如果是走协议默认端口,80 or 443)
path:访问资源的路径
query-string:参数,发送给 http 服务器的数据
anchor:锚(跳转到网页的指定锚点位置)
http://localhost:4000/file/part01/1.2.html
147.服务器处理响应的顺序有哪些方式? select 和 epoll 区别?
Select/epoll/poll
区别:
1.select 的句柄数目受限,在 linux/posix_types.h 头文件有这样的声明:
#define __FD_SETSIZE 1024 表示 select 最多同时监听 1024 个 fd。而 epoll 没有,它的限制是最大的打开文件句柄数目。
2.epoll 的最大好处是不会随着 FD 的数目增长而降低效率,在 selec 中采用轮询处理,其中的数据结构类似一个数组的数据结构,而 epoll 是维护一个队列,直接看队列是不是空就可以了。epoll 只会对"活跃"的 socket 进行操作—
这是因为在内核实现中 epoll 是根据每个 fd 上面的 callback 函数实现的。那么,只有"活跃"的 socket 才会主动的去调用 callback 函数(把这个句柄加入队列),其他 idle 状态句柄则不会,在这点上,epoll 实现了一个"伪"AIO。但是如果绝大部分的 I/O 都是“活跃的”,每个 I/O 端口使用率很高的话,epoll 效率不一定比 select 高(可能是要维护队列复杂)。
3.使用 mmap 加速内核与用户空间的消息传递。无论是 select,poll 还是epoll 都需要内核把 FD 消息通知给用户空间,如何避免不必要的内存拷贝就很重要,在这点上,epoll 是通过内核于用户空间 mmap 同一块内存实现的。
目前的常用的IO复用模型有三种:select,poll,epoll。
(1)select==>时间复杂度O(n)
它仅仅知道了,有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
(2)poll==>时间复杂度O(n)
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的.
(3)epoll==>时间复杂度O(1)
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
epoll跟select都能提供多路I/O复用的解决方案。在现在的Linux内核里有都能够支持,其中epoll是Linux所特有,而select则应该是POSIX所规定,一般操作系统均有实现
select:
select的调用过程如下所示:
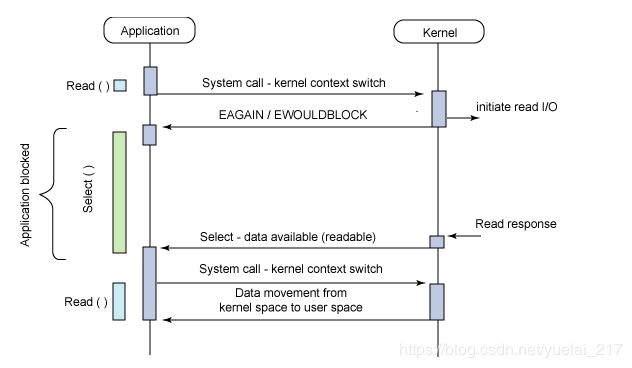
1)使用copy_from_user从用户空间拷贝fd_set到内核空间
(2)注册回调函数__pollwait
(3)遍历所有fd,调用其对应的poll方法(对于socket,这个poll方法是sock_poll,sock_poll根据情况会调用到tcp_poll,udp_poll或者datagram_poll)
(4)以tcp_poll为例,其核心实现就是__pollwait,也就是上面注册的回调函数。
(5)__pollwait的主要工作就是把current(当前进程)挂到设备的等待队列中,不同的设备有不同的等待队列,对于tcp_poll来说,其等待队列是sk->sk_sleep(注意把进程挂到等待队列中并不代表进程已经睡眠了)。在设备收到一条消息(网络设备)或填写完文件数据(磁盘设备)后,会唤醒设备等待队列上睡眠的进程,这时current便被唤醒了。
(6)poll方法返回时会返回一个描述读写操作是否就绪的mask掩码,根据这个mask掩码给fd_set赋值。
(7)如果遍历完所有的fd,还没有返回一个可读写的mask掩码,则会调用schedule_timeout是调用select的进程(也就是current)进入睡眠。当设备驱动发生自身资源可读写后,会唤醒其等待队列上睡眠的进程。如果超过一定的超时时间(schedule_timeout指定),还是没人唤醒,则调用select的进程会重新被唤醒获得CPU,进而重新遍历fd,判断有没有就绪的fd。
(8)把fd_set从内核空间拷贝到用户空间。
select本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理。这样所带来的缺点是:
1、 单个进程可监视的fd数量被限制,即能监听端口的大小有限。
一般来说这个数目和系统内存关系很大,具体数目可以cat /proc/sys/fs/file-max察看。32位机默认是1024个。64位机默认是2048.
2、 对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低:
当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询,这正是epoll与kqueue做的。
(1)每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
(2)同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
3、需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大
poll:
poll的实现和select非常相似,只是描述fd集合的方式不同,poll使用pollfd结构而不是select的fd_set结构,其他的都差不多,管理多个描述符也是进行轮询,根据描述符的状态进行处理,但是poll没有最大文件描述符数量的限制。poll和select同样存在一个缺点就是,包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大。
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。
它没有最大连接数的限制,原因是它是基于链表来存储的,但是同样有一个缺点:
1、大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。
2、poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。
epoll:
epoll有EPOLL LT和EPOLL ET两种触发模式,LT是默认的模式,ET是“高速”模式。LT模式下,只要这个fd还有数据可读,每次 epoll_wait都会返回它的事件,提醒用户程序去操作,而在ET(边缘触发)模式中,它只会提示一次,直到下次再有数据流入之前都不会再提示了,无 论fd中是否还有数据可读。所以在ET模式下,read一个fd的时候一定要把它的buffer读光,也就是说一直读到read的返回值小于请求值,或者 遇到EAGAIN错误。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。
epoll为什么要有EPOLL ET触发模式?
如果采用EPOLL LT模式的话,系统中一旦有大量你不需要读写的就绪文件描述符,它们每次调用epoll_wait都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率.。而采用EPOLL ET这种边沿触发模式的话,当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符。
epoll的优点:
1、没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口);
2、效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;
即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
3、 内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
epoll既然是对select和poll的改进,就应该能避免上述缺点。那epoll都是怎么解决的呢?在此之前,我们先看一下epoll和select和poll的调用接口上的不同,select和poll都只提供了一个函数——select或者poll函数。而epoll提供了三个函数,epoll_create,epoll_ctl和epoll_wait,epoll_create是创建一个epoll句柄;epoll_ctl是注册要监听的事件类型;epoll_wait则是等待事件的产生。
对于第一个缺点,epoll的解决方案在epoll_ctl函数中。每次注册新的事件到epoll句柄中时(在epoll_ctl中指定EPOLL_CTL_ADD),会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝一次。
对于第二个缺点,epoll的解决方案不像select或poll一样每次都把current轮流加入fd对应的设备等待队列中,而只在epoll_ctl时把current挂一遍(这一遍必不可少)并为每个fd指定一个回调函数,当设备就绪,唤醒等待队列上的等待者时,就会调用这个回调函数,而这个回调函数会把就绪的fd加入一个就绪链表)。epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd(利用schedule_timeout()实现睡一会,判断一会的效果,和select实现中的第7步是类似的)。
epoll没有FD个数这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
select、poll、epoll 区别总结:
1、支持一个进程所能打开的最大连接数
select:单个进程所能打开的最大连接数有FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是3232,同理64位机器上FD_SETSIZE为3264),当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响,这需要进一步的测试。
poll:poll本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的。
epoll:虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接。
2、FD剧增后带来的IO效率问题
select:因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的“线性下降性能问题”。
poll:同上
epoll:因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。
3、 消息传递方式
select:内核需要将消息传递到用户空间,都需要内核拷贝动作
poll:同上
epoll:epoll通过内核和用户空间共享一块内存来实现的。
总结:
综上,在选择select,poll,epoll时要根据具体的使用场合以及这三种方式的自身特点。
1、表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
2、select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善
select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内部定义的等待队列)。这也能节省不少的开销。
148.Ip 包中有哪些字段,以及 ip 包的大小是多少?
字段:版本号/ IP 包头长度/服务类型/ IP 包总长/标识符/标记/片偏移/生存时间/协议/头部校验/起源和目标地址/可选项/填充
大小:最大长度 65535 字节
149.知道 arp 报文吗?全称叫什么以及有什么作用?
ARP (Address Resolution Protocol) 是个地址解析协议。最直白的说法是:在 IP 以太网中,当一个上层协议要发包时,有了该节点的 IP 地址,ARP 就能提供该节点的 MAC 地址。 报文在传输的过程中在路由器中的处理过程
150.长链接与短链接的区别?
短连接
连接->传输数据->关闭连接
HTTP 是无状态的,浏览器和服务器每进行一次 HTTP 操作,就建立一次连接,但任务结束后就中断连接。短连接是指 SOCKET 连接后发送后接收完数据后马上断开连接。
长连接
连接->传输数据->保持连接->传输数据->…->关闭连接
长连接指建立 SOCKET 连接后不管是否使用都保持连接,但安全性较差。
151.从输入 http://www.baidu.com/ 到页面返回,中间都是发生了什么?(浏览器发送一个请求到返回一个页面的具体过程)
第一步,解析域名,找到 ip
浏览器会缓存 DNS 一段时间,一般 2-30 分钟不等,如果有缓存,直接返回ip,否则下一步。
缓存中无法找到 ip,浏览器会进行一个系统调用,查询 hosts 文件。如果找到,直接返回 ip,否则下一步。
进行 1 和 2 本地查询无果,只能借助于网络,路由器一般都会有自己的 DNS缓存,ISP 服务商 DNS 缓存,这时一般都能够得到相应的 ip,如果还是无果,只能借助于 DNS 递归解析了。
这时 ISP 的 DNS 服务器就会开始从根域名服务器开始递归搜索,从.com 顶级域名服务器,到 baidu 的域名服务器。
到这里,浏览器就获得网络 ip,在 DNS 解析过程中,常常解析出不同的 IP。
第二步,浏览器于网站建立 TCP 连接
浏览器利用 ip 直接网站主机通信,浏览器发出 TCP 连接请求,主机返回 TCP应答报文,浏览器收到应答报文发现 ACK 标志位为 1,表示连接请求确认,浏览器返回 TCP()确认报文,主机收到确认报文,三次握手,TCP 连接建立完成。
第三步, 浏览器发起默认的 GET 请求
浏览器向主机发起一个 HTTP-GET 方法报文请求,请求中包含访问的 URL,也就是 http://www.baidu.com/还有 User-Agent 用户浏览器操作系统信息,编码等,值得一提的是 Accep-Encoding 和 Cookies 项。Accept-Encoding 一般采用 gzip,压缩之后传输 html 文件,Cookies 如果是首次访问,会提示服务器简历用户缓存信息,如果不是,可以利用 Cookies 对应键值,找到相应缓存,缓存里面存放着用户名,密码和一些用户设置项
第四步,显示页面或返回其他
返回状态码 200 OK,表示服务器可以响应请求,返回报文,由于在报头中Content-type 为“text/html”,浏览器以 HTML 形式呈现,而不是下载文件。但是对于大型网站存在多个主机站点,往往不会直接返回请求页面,而是重定向。返回的状态码就不是 200 OK, 而是 301,302 以 3 开头的重定向吗。浏览器在获取了重定向响应后,在响应报文中 Location 项找到重定向地址,浏览器重新第一步访问即可。
152.对 react 和 vue 的了解?
React 是一个用于构建用户界面的 js 库 React 主要用于构建 UI, 是MVC 中的 V(视图)拥有较高的性能,代码逻辑非常简单
Vue 是一套用于构建用户界面的渐进式框架 Vue 被设计为可以自底向上逐层应用。Vue 的核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整合
153.请简述标准库中functools.wraps的作用
Python 中使用装饰器对在运行期对函数进行一些外部功能的扩展。但是在使用过程中,由于装饰器的加入导致解释器认为函数本身发生了改变,在某些情况下——比如测试时——会导致一些问题。Python 通过 functool.wraps 为我们解决了这个问题:在编写装饰器时,在实现前加入 @functools.wraps(func) 可以保证装饰器不会对被装饰函数造成影响。
154.单引号,双引号,和三引号的区别
1)单引号跟双引号的普通用法是相同的,str1 = ‘abc’ str2 = “abc”
2)单引号跟双引号的主要区别体现在当单引号抱起来的字符串含有双引号是,不需要使用转义字符,同样,在双引号抱起来的字符串含有单引号时,不需要使用转义字符
3)三引号:’’’str‘’’, “””str”””, 核心用法体现在跨行的字符串上
Str = ‘’’abc
def’’’
python中没有多行注释,一般使用三引号
155.Python如何生成图片的缩略图
from PIL import Image
img = Image.open('pic.jpg')
img = img.resize((250, 156), Image.ANTIALIAS)
img.save('pic_small.jpg')
156.字典转换为字符串
a = {"name":"jack","age":30}
#现在需要生成字符串:name=jack|age=30
#请用一行代码实现:
s = '|'.join([str(x)+'='+str(a[x]) for x in a])
157.NOW()和CURRENT_DATE()有什么区别?
Now() #获取当前时期+时间
CURRENT_DATE() #获取当前日期
158.在Django项目中,要实现打印一部分view方法的运行时间(精确到毫秒),请写一个名叫log_timeuse的装饰器完成此功能,以便通过如下方式就能使用。
import time
def log_timeuse(fun):
def fx(request):
s = time.time()
fun(request)
y = time.time()
print(int((y-s)*1000))
return fun(request)
return fx
159.请写出校验邮箱合法性的正则表达式
^[a-zA-Z0-9_.-]+@[a-zA-Z0-9-]+(\.[a-zA-Z0-9-]+)*\.[a-zA-Z0-9]{2,6}$
160.请将这两个list合并,去重并按照升序排列
list1 = [2, 3, 8, 4, 9, 5, 6]
list2 = [5, 6, 10, 17, 11, 2]
list_new = list1 + list2
list = []
for x in list_new:
if x not in list:
list.append(x)
list.sort()
print(list)
161.什么是多态
多态性是指具有不同功能的函数可以使用相同的函数名,这样就可以用一个函数名调用不同内容的函数。在面向对象方法中一般是这样表述多态性:向不同的对象发送同一条消息,不同的对象在接收时会产生不同的行为(即方法)。也就是说,每个对象可以用自己的方式去响应共同的消息。所谓消息,就是调用函数,不同的行为就是指不同的实现,即执行不同的函数.
162.写一段程序,判断字符串内左右括号是否配对
class SStack():
def __init__(self):
self.__elem = []
def is_empty(self):
return self.__elem == []
def top(self):
return self.__elem[-1]
def push(self,elem):
self.__elem.append(elem)
def pop(self):
return self.__elem.pop()
def kuohao(text):
kinds = "()[]{}" #用来定义出现的括号,因为待匹配的字符中含有其他的字符,我们值检查括号是否匹配,而且是只有出现括号后再进行匹配
zuo = "([{" #定义左括号,如果是左括号就入栈
dict0 = {")":"(","]":"[","}":"{"} #匹配字典,这个字典定义了匹配规则,如果字典的键值对匹配就可以认定括号是匹配的
def pipei(text): #将等待匹配的文本输入,这个函数的目标是从文本中过滤出括号
i,text_len = 0,len(text) #扫描指针用来记录匹配位置
while True:
while i< text_len and text[i] not in kinds: #用来寻找到括号
i += 1
if i >= text_len: #如果字符串中没有包含括号则结束
return
yield text[i],i #返回括号字符和字符对应的下标
i += 1
st = SStack()
for text0,i in pipei(text):#获取得到的符号进行匹配,因为pipei()是一个含有yield函数,所以是一个生成器,调用它会产生一个可迭代的对象
if text0 in zuo: #如果是左括号就让它入栈
#print(text0)
st.push(text0)
elif st.pop() != dict0[text0]:#如果是右括号,就弹出栈顶元素进行匹配检查
print("本次不匹配")
return False #遇到不匹配的,就直接退出函数,结束匹配
print("所有的括号都已经匹配完毕,匹配成功!") #如果函数还能够执行到这里说明所有的括号都是匹配的
return True
#kuohao("({{[]}})")
kuohao("[{}]")
163.写一段程序,求最大值,不可使用内置函数
def getMax(arr):
for i in range(0, len(arr)):
for j in range(i + 1, len(arr)):
first = int(arr[i])
second = int(arr[j])
if first < second:
arr[i] = arr[j]
arr[j] = first
print(arr[0])
arr = [19, 29, 30, 48]
getMax(arr)
164.进程和线程的区别
1)运行方式不同
进程不能单独执行,它只是资源的集合。
进程要操作CPU,必须要先创建一个线程。
所有在同一个进程里的线程,是同享同一块进程所占的内存空间。
2)关系
进程中第一个线程是主线程,主线程可以创建其他线程;其他线程也可以创建线程;线程之间是平等的。
进程有父进程和子进程,独立的内存空间,唯一的标识符:pid。
3)速度
启动线程比启动进程快。
运行线程和运行进程速度上是一样的,没有可比性。
线程共享内存空间,进程的内存是独立的。
4)创建
父进程生成子进程,相当于复制一份内存空间,进程之间不能直接访问
创建新线程很简单,创建新进程需要对父进程进行一次复制。
一个线程可以控制和操作同级线程里的其他线程,但是进程只能操作子进程。
5)交互
同一个进程里的线程之间可以直接访问。
两个进程想通信必须通过一个中间代理来实现。
165.Session 的存储位置,怎样跨服务器共享
1)基于NFS的Session共享
NFS是Net FileSystem的简称,最早由Sun公司为解决Unix网络主机间的目录共享而研发。
这个方案实现最为简单,无需做过多的二次开发,仅需将共享目录服务器mount到各频道服务器的本地session目录即可,缺点是NFS依托 于复 杂的安全机制和文件系统,因此并发效率不高,尤其对于session这类高并发读写的小文件, 会由于共享目录服务器的io-wait过高,最终拖累前端WEB应用程序的执行效率。
2)基于数据库的Session共享
首选当然是大名鼎鼎的Mysql数据库,并且建议使用内存表Heap,提高session操作的读写效率。这个方案的实用性比较强,相信大家普 遍在 使用,它的缺点在于session的并发读写能力取决于Mysql数据库的性能,同时需要自己实现session淘汰逻辑,以便定时从数据表中更新、删除 session记录,当并发过高时容易出现表锁,虽然我们可以选择行级锁的表引擎,但不得不否认使用数据库存储Session还是有些杀鸡用牛刀的架势。
3)基于Cookie的Session共享
这个方案我们可能比较陌生,但它在大型网站中还是比较普遍被使用。原理是将全站用户的Session信息加密、序列化后以Cookie的方式, 统一 种植在根域名下(如:.host.com),利用浏览器访问该根域名下的所有二级域名站点时,会传递与之域名对应的所有Cookie内容的特性,从而实现 用户的Cookie化Session 在多服务间的共享访问。
这个方案的优点无需额外的服务器资源;缺点是由于受http协议头信心长度的限制,仅能够存储小部分的用户信息,同时Cookie化的 Session内容需要进行安全加解密(如:采用DES、RSA等进行明文加解密;再由MD5、SHA-1等算法进行防伪认证),另外它也会占用一定的带 宽资源,因为浏览器会在请求当前域名下任何资源时将本地Cookie附加在http头中传递到服务器。
4)基于Memcache的Session共享
Memcache由于是一款基于Libevent多路异步I/O技术的内存共享系统,简单的Key + Value数据存储模式使得代码逻辑小巧高效,因此在并发处理能力上占据了绝对优势,目前本人所经历的项目达到2000/秒 平均查询,并且服务器CPU消耗依然不到10%。
另外值得一提的是Memcache的内存hash表所特有的Expires数据过期淘汰机制,正好和Session的过期机制不谋而合,降低了 过期Session数据删除的代码复杂度,对比“基于数据库的存储方案”,仅这块逻辑就给数据表产生巨大的查询压力。
166.详细说说tuple、list、dict的用法,它们的特点
列表,元组,字典,都是可迭代对象
列表和元组都是序列,列表是可变的序列, 元组是不可变的序列;列表可以通过索引改变列表的元素, 元组不可以;列表可以通过切片赋值插入和删除数据,也可以改变数据, 元组不可以
字典是可变的容器,字典可以存储任意类型的数据;字典中的数据都是用键进行索引的;字典的存储是无序的;字典中的数据是以 键-值(key-value)对的形式进行存储的;字典的键不能重复,且只能用不可变类型作为字典的键。
| 名称 | 可变性 | 存在形式 | 可重复性 | 有序性 | 其他特点 |
|---|---|---|---|---|---|
| list(列表) | 可以修改元素 | 值的形式[1,2] | 值可以重复 | 有序 | 相比dict拥有占有内存小的特点,常用于堆栈等的处理 |
| tuple(元组) | 可以修改元素 | 值的形式(1,2) | 值可以重复 | 有序 | 本身不可变,相对比较稳定 |
| dict(字典) | 键不可变,值可以变 | 键值对形式{1:1,2:2} | 键不可以重复,值可以重复 | 无序 | 符合内存换速度思想,常用于查找 |
| set(集合) | 可以修改元素 | 值的形式([1,2]) | 值不可以重复 | 无序 | 常用于判断值是否存在 |
167.观察输出,用自己的话解释*args,**kwargs这两个参数是什么意思,我问为什么使用它?
def func(*args,**kwargs):
print(args,kwargs)
l=[1,2,3]
t=(4,5,6)
d={'a':7,'b':8,'c':9}
func(1,2,3)#(1,2,3) {}
func(a=1,b=2,c=3)#() {'a':1,'c':3,'b':2}
func((1,2,3),a=1,b=2,c=3) #(1,2,3) {'a':1,'c':3,'b':2}
func(*l,**d)#(1,2,3) {'a': 7, 'c': 9, 'b': 8}
func(l,2,*t)#([1, 2, 3], 2, 4, 5, 6) {}
func(q='winning',**d)#(){'a':7,'c':9,'b':8,'q': 'winning'}
如果我们不确定要往函数中传入多少个参数,或者我们想往函数中以列表和元组 的形式传参数时,那就使要用args; 如果我们不知道要往函数中传入多少个关键词参数,或者想传入字典的值作为关 键词参数时,那就要使用**kwargs。 args和kwargs这两个标识符是约定俗成的用法,你当然还可以用bob和**billy, 但是这样就并不妥。
168.将一个正整数分解质因数。例如输入90,打印90=2*3*3*5.
n = num = int(input('请输入一个数字:')) # 用num保留初始值
f = [] # 存放质因数的列表
for j in range(int(num / 2) + 1): # 判断次数仅需该数字的一半多1次
for i in range(2, n):
t = n % i # i不能是n本身
if t == 0: # 若能整除
f.append(i) # 则表示i是质因数
# 除以质因数后的n重新进入判断,注意应用两个除号,使n保持整数
n = n // i
break # 找到1个质因数后马上break,防止非质数却可以整除的数字进入质因数列表
if len(f) == 0: # 若一个质因数也没有
print('该数字没有任何质因数。')
else: # 若至少有一个质因数
f.append(n) # 此时n已被某个质因数整除过,最后一个n也是其中一个质因数
f.sort() # 排下序
print('%d=%d' % (num, f[0]), end='')
for i in range(1, len(f)):
print('*%d' % f[i], end='')
169.简述以下内置函数的用法
1)数学运算类
| 内置函数 | 解释 |
|---|---|
| abs(x) | 求绝对值:1、参数可以是整型,也可以是复数2、若参数是复数,则返回复数的模 |
| complex([real[,imag]]) | 创建一个复数 |
| divmod(a, b) | 分别取商和余数。注意:整型、浮点型都可以 |
| float([x]) | 将一个字符串或数转换为浮点数。如果无参数将返回0.0 |
| int([x[, base]]) | 将一个字符转换为int类型,base表示进制 |
| long([x[, base]]) | 将一个字符转换为long类型 |
| pow(x, y[, z]) | 返回x的y次幂 |
| range([start], stop[, step]) | 产生一个序列,默认从0开始 |
| round(x[, n]) | 四舍五入 |
| sum(iterable[, start]) | 对集合求和 |
| oct(x) | 将一个数字转化为8进制 |
| hex(x) | 将整数x转换为16进制字符串 |
| chr(i) | 返回整数i对应的ASCII字符 |
| bin(x) | 将整数x转换为二进制字符串 |
| bool([x]) | 将x转换为Boolean类型 |
2) 集合类操作
| 内置函数 | 解释 |
|---|---|
| basestring() | str和unicode的超类不能直接调用,可以用作isinstance判断 |
| format(value [, format_spec]) | 格式化输出字符串格式化的参数顺序从0开始,如“I am {0},I like {1}” |
| unichr(i) | 返回给定int类型的unicode |
| enumerate(sequence [, start = 0]) | 返回一个可枚举的对象,该对象的next()方法将返回一个tuple |
| iter(o[, sentinel]) | 生成一个对象的迭代器,第二个参数表示分隔符 |
| max(iterable[, args…][key]) | 返回集合中的最大值 |
| min(iterable[, args…][key]) | 返回集合中的最小值 |
| dict([arg]) | 创建数据字典 |
| list([iterable]) | 将一个集合类转换为另外一个集合类 |
| set() | set对象实例化 |
| frozenset([iterable]) | 产生一个不可变的set |
| str([object]) | 转换为string类型 |
| sorted(iterable[, cmp[, key[, reverse]]]) | 队集合排序 |
| tuple([iterable]) | 生成一个tuple类型 |
| xrange([start], stop[, step]) | xrange()函数与range()类似,但xrnage()并不创建列表,而是返回一个xrange对象,它的行为与列表相似,但是只在需要时才计算列表值,当列表很大时,这个特性能为我们节省内存 |
3)逻辑判断
| 内置函数 | 解释 |
|---|---|
| all(iterable) | 1、集合中的元素都为真的时候为真2、特别的,若为空串返回为True |
| any(iterable) | 1、集合中的元素有一个为真的时候为真2、特别的,若为空串返回为False |
| cmp(x, y) | 如果x < y ,返回负数;x == y, 返回0;x > y,返回正数 |
4)反射
| 内置函数 | 解释 |
|---|---|
| callable(object) | 检查对象object是否可调用1、类是可以被调用的2、实例是不可以被调用的,除非类中声明了__call__方法 |
| classmethod() | 1、注解,用来说明这个方式是个类方法2、类方法即可被类调用,也可以被实例调用3、类方法类似于Java中的static方法4、类方法中不需要有self参数 |
| compile(source, filename,mode[,flags[, dont_inherit]]) | 将source编译为代码或者AST对象。代码对象能够通过exec语句来执行或者eval()进行求值。1、参数source:字符串或者AST(Abstract Syntax Trees)对象。2、参数 filename:代码文件名称,如果不是从文件读取代码则传递一些可辨认的值。3、参数model:指定编译代码的种类。可以指定为 ‘exec’,’eval’,’single’。4、参数flag和dont_inherit:这两个参数暂不介绍 |
| dir([object]) | 1、不带参数时,返回当前范围内的变量、方法和定义的类型列表;2、带参数时,返回参数的属性、方法列表。3、如果参数包含方法__dir__(),该方法将被调用。当参数为实例时。4、如果参数不包含__dir__(),该方法将最大限度地收集参数信息 |
| delattr(object, name) | 删除object对象名为name的属性 |
| eval(expression[,globals [, locals]]) | 计算表达式expression的值 |
| execfile(filename [, globals [, locals]]) | 用法类似exec(),不同的是execfile的参数filename为文件名,而exec的参数为字符串。 |
| filter(function, iterable) | 构造一个序列,等价于[ item for item in iterable if function(item)]1、参数function:返回值为True或False的函数,可以为None2、参数iterable:序列或可迭代对象 |
| getattr(object, name [, defalut]) | 获取一个类的属性 |
| globals() | 返回一个描述当前全局符号表的字典 |
| hasattr(object, name) | 判断对象object是否包含名为name的特性 |
| hash(object) | 如果对象object为哈希表类型,返回对象object的哈希值 |
| id(object) | 返回对象的唯一标识 |
| isinstance(object, classinfo) | 判断object是否是class的实例 |
| issubclass(class, classinfo) | 判断是否是子类 |
| len(s) | 返回集合长度 |
| locals() | 返回当前的变量列表 |
| map(function, iterable, …) | 遍历每个元素,执行function操作 |
| memoryview(obj) | 返回一个内存镜像类型的对象 |
| next(iterator[, default]) | 类似于iterator.next() |
| object() | 基类 |
| property([fget[, fset[, fdel[, doc]]]]) | 属性访问的包装类,设置后可以通过c.x=value等来访问setter和getter |
| reduce(function,iterable[ initializer]) | 合并操作,从第一个开始是前两个参数,然后是前两个的结果与第三个合并进行处理,以此类推 |
| reload(module) | 重新加载模块 |
| setattr(object, name, value) | 设置属性值 |
| repr(object) | 将一个对象变幻为可打印的格式 |
| slice() | |
| staticmethod | 声明静态方法,是个注解 |
| super(type[, object-or-type]) | 引用父类 |
| type(object) | 返回该object的类型 |
| vars([object]) | 返回对象的变量,若无参数与dict()方法类似 |
| bytearray([source [, encoding [, errors]]]) | 返回一个byte数组1、如果source为整数,则返回一个长度为source的初始化数组;2、如果source为字符串,则按照指定的encoding将字符串转换为字节序列;3、如果source为可迭代类型,则元素必须为[0 ,255]中的整数;4、如果source为与buffer接口一致的对象,则此对象也可以被用于初始化bytearray. |
| zip([iterable, …]) | 实在是没有看懂,只是看到了矩阵的变幻方面 |
5)IO操作
| 内置函数 | 解释 |
|---|---|
| file(filename [, mode [, bufsize]]) | file类型的构造函数,作用为打开一个文件,如果文件不存在且mode为写或追加时,文件将被创建。添加‘b’到mode参数中,将对文件以二进制形式操作。添加‘+’到mode参数中,将允许对文件同时进行读写操作1、参数filename:文件名称。2、参数mode:‘r’(读)、‘w’(写)、‘a’(追加)。3、参数bufsize:如果为0表示不进行缓冲,如果为1表示进行行缓冲,如果是一个大于1的数表示缓冲区的大小 。 |
| input([prompt]) | 获取用户输入推荐使用raw_input,因为该函数将不会捕获用户的错误输入 |
| open(name[, mode[, buffering]]) | 打开文件与file有什么不同?推荐使用open |
| 打印函数 | |
| raw_input([prompt]) | 设置输入,输入都是作为字符串处理 |
一、数学运算
1.abs:求数值的绝对值
abs(-2)
2
2.divmod:返回两个数值的商和余数
divmod(5,2)
(2, 1)
divmod(5.5,2)
(2.0, 1.5)
3.max:返回可迭代对象中的元素中的最大值或者所有参数的最大值
max(1,2,3) # 传入3个参数 取3个中较大者
3
max('1234') # 传入1个可迭代对象,取其最大元素值
'4'
max(-1,0) # 数值默认取数值较大者
0
max(-1,0,key = abs) # 传入了求绝对值函数,则参数都会进行求绝对值后再取较大者
-1
4.min:返回可迭代对象中的元素中的最小值或者所有参数的最小值
min(1,2,3) # 传入3个参数 取3个中较小者
1
min('1234') # 传入1个可迭代对象,取其最小元素值
'1'
min(-1,-2) # 数值默认去数值较小者
-2
min(-1,-2,key = abs) # 传入了求绝对值函数,则参数都会进行求绝对值后再取较小者
-1
5.pow:返回两个数值的幂运算值或其与指定整数的模值
pow(2,3)
2**3
pow(2,3,5)
pow(2,3)%5
6. round:对浮点数进行四舍五入求值
round(1.1314926,1)
1.1
round(1.1314926,5)
1.13149
7. sum:对元素类型是数值的可迭代对象中的每个元素求和
# 传入可迭代对象
sum((1,2,3,4))
10
# 元素类型必须是数值型
sum((1.5,2.5,3.5,4.5))
12.0
sum((1,2,3,4),-10)
0
二、类型转换
1.bool:根据传入的参数的逻辑值创建一个新的布尔值
bool() #未传入参数
False
bool(0) #数值0、空序列等值为False
False
bool(1)
True
2.int:根据传入的参数创建一个新的整数
int() #不传入参数时,得到结果0。
0
int(3)
3
int(3.6)
3
3.float:根据传入的参数创建一个新的浮点数
float() #不提供参数的时候,返回0.0
0.0
float(3)
3.0
float('3')
3.0
4.complex:根据传入参数创建一个新的复数
complex() #当两个参数都不提供时,返回复数 0j。
0j
complex('1+2j') #传入字符串创建复数
(1+2j)
complex(1,2) #传入数值创建复数
(1+2j)
5. str:返回一个对象的字符串表现形式(给用户)
str()
''
str(None)
'None'
str('abc')
'abc'
str(123)
'123'
6.bytearray:根据传入的参数创建一个新的字节数组
bytearray('中文','utf-8')
bytearray(b'\xe4\xb8\xad\xe6\x96\x87')
7.bytes:根据传入的参数创建一个新的不可变字节数组
bytes('中文','utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
8.memoryview:根据传入的参数创建一个新的内存查看对象
v = memoryview(b'abcefg')
v[1]
98
v[-1]
103
9.ord:返回Unicode字符对应的整数
ord('a')
97
10.chr:返回整数所对应的Unicode字符
chr(97) #参数类型为整数
'a'
11.bin:将整数转换成2进制字符串
bin(3)
'0b11'
12.oct:将整数转化成8进制数字符串
oct(10)
'0o12'
13.hex:将整数转换成16进制字符串
hex(15)
'0xf'
14.tuple:根据传入的参数创建一个新的元组
tuple() #不传入参数,创建空元组
()
tuple('121') #传入可迭代对象。使用其元素创建新的元组
('1', '2', '1')
15.list:根据传入的参数创建一个新的列表
list() # 不传入参数,创建空列表
[]
list('abcd') # 传入可迭代对象,使用其元素创建新的列表
['a', 'b', 'c', 'd']
16.dict:根据传入的参数创建一个新的字典
dict() # 不传入任何参数时,返回空字典。
{}
dict(a = 1,b = 2) # 可以传入键值对创建字典。
{'b': 2, 'a': 1}
dict(zip(['a','b'],[1,2])) # 可以传入映射函数创建字典。
{'b': 2, 'a': 1}
dict((('a',1),('b',2))) # 可以传入可迭代对象创建字典。
{'b': 2, 'a': 1}
17.set:根据传入的参数创建一个新的集合
set() # 不传入参数,创建空集合
set()
a = set(range(10)) # 传入可迭代对象,创建集合
a
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
18.frozenset:根据传入的参数创建一个新的不可变集合
a = frozenset(range(10))
a
frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9})
19.enumerate:根据可迭代对象创建枚举对象
seasons = ['Spring', 'Summer', 'Fall', 'Winter']
list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
list(enumerate(seasons, start=1)) #指定起始值
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
20.range:根据传入的参数创建一个新的range对象
a = range(10)
b = range(1,10)
c = range(1,10,3)
a,b,c # 分别输出a,b,c
(range(0, 10), range(1, 10), range(1, 10, 3))
list(a),list(b),list(c) # 分别输出a,b,c的元素
([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], [1, 2, 3, 4, 5, 6, 7, 8, 9], [1, 4, 7])
21.iter:根据传入的参数创建一个新的可迭代对象
a = iter('abcd') #字符串序列
a
<str_iterator object at 0x03FB4FB0>
next(a)
'a'
next(a)
'b'
next(a)
'c'
next(a)
'd'
next(a)
Traceback (most recent call last)
File "" , line 1, in <module>
next(a)
StopIteration
22.slice:根据传入的参数创建一个新的切片对象
c1 = slice(5) # 定义c1
c1
slice(None, 5, None)
c2 = slice(2,5) # 定义c2
c2
slice(2, 5, None)
c3 = slice(1,10,3) # 定义c3
c3
slice(1, 10, 3)
23.super:根据传入的参数创建一个新的子类和父类关系的代理对象
# 定义父类A
class A(object):
def __init__(self):
print('A.__init__')
# 定义子类B,继承A
class B(A):
def __init__(self):
print('B.__init__')
super().__init__()
# super调用父类方法
b = B()
B.__init__
A.__init
24.object:创建一个新的object对象
a = object()
a.name = 'kim' # 不能设置属性
Traceback (most recent call last):
File "" , line 1, in <module>
a.name = 'kim'
AttributeError: 'object' object has no attribute 'name'
三、序列操作
1.all:判断可迭代对象的每个元素是否都为True值
all([1,2]) #列表中每个元素逻辑值均为True,返回True
True
all([0,1,2]) #列表中0的逻辑值为False,返回False
False
all(()) #空元组
True
all({}) #空字典
True
2.any:判断可迭代对象的元素是否有为True值的元素
any([0,1,2]) #列表元素有一个为True,则返回True
True
any([0,0]) #列表元素全部为False,则返回False
False
any([]) #空列表
False
any({}) #空字典
False
3.filter:使用指定方法过滤可迭代对象的元素
a = list(range(1,10)) #定义序列
a
[1, 2, 3, 4, 5, 6, 7, 8, 9]
def if_odd(x): #定义奇数判断函数
return x%2==1
list(filter(if_odd,a)) #筛选序列中的奇数
[1, 3, 5, 7, 9]
4.map:使用指定方法去作用传入的每个可迭代对象的元素,生成新的可迭代对象
a = map(ord,'abcd')
a
<map object at 0x03994E50>
list(a)
[97, 98, 99, 100]
5.next:返回可迭代对象中的下一个元素值
a = iter('abcd')
next(a)
'a'
next(a)
'b'
next(a)
'c'
next(a)
'd'
next(a)
Traceback (most recent call last):
File "" , line 1, in <module>
next(a)
StopIteration
#传入default参数后,如果可迭代对象还有元素没有返回,则依次返回其元素值,如果所有元素已经返回,则返回default指定的默认值而不抛出StopIteration 异常
next(a,'e')
'e'
next(a,'e')
'e'
6.reversed:反转序列生成新的可迭代对象
a = reversed(range(10)) # 传入range对象
a # 类型变成迭代器
<range_iterator object at 0x035634E8>
list(a)
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
7.sorted:对可迭代对象进行排序,返回一个新的列表
a = ['a','b','d','c','B','A']
a
['a', 'b', 'd', 'c', 'B', 'A']
sorted(a) # 默认按字符ascii码排序
['A', 'B', 'a', 'b', 'c', 'd']
sorted(a,key = str.lower) # 转换成小写后再排序,'a'和'A'值一样,'b'和'B'值一样
['a', 'A', 'b', 'B', 'c', 'd']
8.zip:聚合传入的每个迭代器中相同位置的元素,返回一个新的元组类型迭代器
x = [1,2,3] #长度3
y = [4,5,6,7,8] #长度5
list(zip(x,y)) # 取最小长度3
[(1, 4), (2, 5), (3, 6)]
四、对象操作
1)help:返回对象的帮助信息
help(str)
Help on class str in module builtins:
class str(object)
str(object='') -> str
str(bytes_or_buffer[, encoding[, errors]]) -> str
Create a new string object from the given object.If encoding or errors is specified, then
the object must expose a data buffer that
will be decoded using the given encoding and error handler.Otherwise, returns the result of object.__str__()( if defined)
or repr(object).encoding defaults to sys.getdefaultencoding().errors defaults to 'strict'.
Methods defined here:
add(self, value, /)
Return self + value.
2)dir:返回对象或者当前作用域内的属性列表
import math
math
<module 'math' (built-in)>
dir(math)
['__doc__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'copysign', 'cos', 'cosh', 'degrees', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'gcd', 'hypot', 'inf', 'isclose', 'isfinite', 'isinf', 'isnan', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'log2', 'modf', 'nan', 'pi', 'pow', 'radians', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'trunc']
3)id:返回对象的唯一标识符
a = 'some text'
id(a)
69228568
4)hash:获取对象的哈希值
hash('good good study')
1032709256
5)type:返回对象的类型,或者根据传入的参数创建一个新的类型
type(1) # 返回对象的类型
<class 'int'>
# 使用type函数创建类型D,含有属性InfoD
D = type('D', (A, B), dict(InfoD='some thing defined in D'))
d = D()
d.InfoD
'some thing defined in D'
6)len:返回对象的长度
len('abcd') # 字符串
len(bytes('abcd','utf-8')) # 字节数组
len((1,2,3,4)) # 元组
len([1,2,3,4]) # 列表
len(range(1,5)) # range对象
len({'a':1,'b':2,'c':3,'d':4}) # 字典
len({'a','b','c','d'}) # 集合
len(frozenset('abcd')) #不可变集合
7)ascii:返回对象的可打印表字符串表现方式
ascii(1)
'1'
ascii('&')
"'&'"
ascii(9000000)
'9000000'
ascii('中文') #非ascii字符
"'\\u4e2d\\u6587'"
8)format:格式化显示值
# 字符串可以提供的参数 's' None
format('some string', 's')
'some string'
format('some string')
'some string'
# 整形数值可以提供的参数有 'b' 'c' 'd' 'o' 'x' 'X' 'n' None
format(3, 'b') # 转换成二进制
'11'
format(97, 'c') # 转换unicode成字符
'a'
format(11, 'd') # 转换成10进制
'11'
format(11, 'o') # 转换成8进制
'13'
format(11, 'x') # 转换成16进制 小写字母表示
'b'
format(11, 'X') # 转换成16进制 大写字母表示
'B'
format(11, 'n') # 和d一样
'11'
format(11) # 默认和d一样
'11'
# 浮点数可以提供的参数有 'e' 'E' 'f' 'F' 'g' 'G' 'n' '%' None
format(314159267, 'e') # 科学计数法,默认保留6位小数
'3.141593e+08'
format(314159267, '0.2e') # 科学计数法,指定保留2位小数
'3.14e+08'
format(314159267, '0.2E') # 科学计数法,指定保留2位小数,采用大写E表示
'3.14E+08'
format(314159267, 'f') # 小数点计数法,默认保留6位小数
'314159267.000000'
format(3.14159267000, 'f') # 小数点计数法,默认保留6位小数
'3.141593'
format(3.14159267000, '0.8f') # 小数点计数法,指定保留8位小数
'3.14159267'
format(3.14159267000, '0.10f') # 小数点计数法,指定保留10位小数
'3.1415926700'
format(3.14e+1000000, 'F') # 小数点计数法,无穷大转换成大小字母
'INF'
# g的格式化比较特殊,假设p为格式中指定的保留小数位数,先尝试采用科学计数法格式化,得到幂指数exp,如果-4<=exp
format(0.00003141566, '.1g') # p=1,exp=-5 ==》 -4<=exp
'3e-05'
format(0.00003141566, '.2g') # p=1,exp=-5 ==》 -4<=exp
'3.1e-05'
format(0.00003141566, '.3g') # p=1,exp=-5 ==》 -4<=exp
'3.14e-05'
format(0.00003141566, '.3G') # p=1,exp=-5 ==》 -4<=exp
'3.14E-05'
format(3.1415926777, '.1g') # p=1,exp=0 ==》 -4<=exp
'3'
format(3.1415926777, '.2g') # p=1,exp=0 ==》 -4<=exp
'3.1'
format(3.1415926777, '.3g') # p=1,exp=0 ==》 -4<=exp
'3.14'
format(0.00003141566, '.1n') # 和g相同
'3e-05'
format(0.00003141566, '.3n') # 和g相同
'3.14e-05'
format(0.00003141566) # 和g相同
'3.141566e-05'
9)vars:返回当前作用域内的局部变量和其值组成的字典,或者返回对象的属性列表
# 作用于类实例
class A(object):
pass
a.__dict__
{}
vars(a)
{}
a.name = 'Kim'
a.__dict__
{'name': 'Kim'}
vars(a)
{'name': 'Kim'}
五、反射操作
1)import:动态导入模块
index = __import__('index')
index.sayHello()
2)isinstance:判断对象是否是类或者类型元组中任意类元素的实例
isinstance(1,int)
True
isinstance(1,str)
False
isinstance(1,(int,str))
True
3)issubclass:判断类是否是另外一个类或者类型元组中任意类元素的子类
issubclass(bool ,int)
True
issubclass(bool ,str)
False
issubclass(bool ,(str ,int))
True
4)hasattr:检查对象是否含有属性
# 定义类A
class Student:
def __init__(self ,name):
self.name = name
s = Student('Aim')
hasattr(s ,'name') # a含有name属性
True
hasattr(s ,'age') # a不含有age属性
False
5)getattr:获取对象的属性值
# 定义类Student
class Student:
def __init__(self, name):
self.name = name
getattr(s, 'name') # 存在属性name
'Aim'
getattr(s, 'age', 6) # 不存在属性age,但提供了默认值,返回默认值
getattr(s, 'age') # 不存在属性age,未提供默认值,调用报错
Traceback(most recent call last):
File "" , line in < module >
getattr(s, 'age')
AttributeError: 'Stduent'object has no attribute 'age'
6)setattr:设置对象的属性值
class Student:
def __init__(self ,name):
self.name = name
a = Student('Kim')
a.name
'Kim'
setattr(a ,'name' ,'Bob')
a.name
'Bob'
7)delattr:删除对象的属性
# 定义类A
class A:
def __init__(self, name):
self.name = name
def sayHello(self):
print('hello', self.name)
# 测试属性和方法
a.name
'小麦'
a.sayHello()
hello 小麦
# 删除属性
delattr(a, 'name')
a.name
Traceback(most recent call last):
File "" , line in < module >
a.name
AttributeError: 'A' object has no attribute 'name'
8)callable:检测对象是否可被调用
class B: # 定义类B
def __call__(self):
print('instances are callable now.')
callable(B) # 类B是可调用对象
True
b = B() # 调用类B
callable(b) # 实例b是可调用对象
True
b() # 调用实例b成功
instances are callable now.
六、变量操作
1)globals:返回当前作用域内的全局变量和其值组成的字典
globals()
{'__spec__': None, '__package__': None, '__builtins__': <module 'builtins' (built-in)>, '__name__': '__main__', '__doc__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>}
a = 1
globals() #多了一个a
{'__spec__': None, '__package__': None, '__builtins__': <module 'builtins' (built-in)>, 'a': 1, '__name__': '__main__', '__doc__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>}
2)locals:返回当前作用域内的局部变量和其值组成的字典
def f():
print('before define a ')
print(locals()) # 作用域内无变量
a = 1
print('after define a')
print(locals()) # 作用域内有一个a变量,值为1
f
< function f at 0x03D40588 >
f()
before define a
{}
after define a
{'a': 1}
七、交互操作
1)print:向标准输出对象打印输出
print(1,2,3)
1 2 3
print(1,2,3,sep = '+')
1+2+3
print(1,2,3,sep = '+',end = '=?')
1+2+3=?
2)input:读取用户输入值
s = input('please input your name:')
please input your name:Ain
s
'Ain'
八、文件操作
1**)open:使用指定的模式和编码打开文件,返回文件读写对象**
#t为文本读写,b为二进制读写
a = open('test.txt','rt')
a.read()
'some text'
a.close()
九、编译执行
1)compile:将字符串编译为代码或者AST对象,使之能够通过exec语句来执行或者eval进行求值
# 流程语句使用exec
code1 = 'for i in range(0,10): print (i)'
compile1 = compile(code1, '', 'exec')
exec(compile1)
0
1
2
3
4
5
6
7
8
9
# 简单求值表达式用eval
code2 = '1 + 2 + 3 + 4'
compile2 = compile(code2, '', 'eval')
eval(compile2)
10
2)eval:执行动态表达式求值
eval('1+2+3+4')
10
3)exec:执行动态语句块
exec('a=1+2') #执行语句
a
3
4)repr:返回一个对象的字符串表现形式(给解释器)
a = 'some text'
str(a)
'some text'
repr(a)
"'some text'"
十、装饰器
1)property:标示属性的装饰器
class C:
def __init__(self):
self._name = ''
@property
def name(self):
"""i'm the 'name' property."""
return self._name
@name.setter
def name(self, value):
if value is None:
raise RuntimeError('name can not be None')
else:
self._name = value
c = C()
c.name # 访问属性
''
c.name = None # 设置属性时进行验证
Traceback(most recent call last):
File "" , line in < module >
c.name = None
File "" , line in name
raise RuntimeError('name can not be None')
RuntimeError: name can not be None
c.name = 'Kim' # 设置属性
c.name # 访问属性
'Kim'
del c.name # 删除属性,不提供deleter则不能删除
Traceback(most recent call last):
File "" , line in < module >
del c.name
AttributeError: can't delete attribute
c.name
'Kim'
2)classmethod:标示方法为类方法的装饰器
class C:
@classmethod
def f(cls, arg1):
print(cls)
print(arg1)
C.f('类对象调用类方法')
<class '__main__.C'>#类对象调用类方法
c = C()
c.f('类实例对象调用类方法')
<class '__main__.C'>#类实例对象调用类方
3)staticmethod:标示方法为静态方法的装饰器
# 使用装饰器定义静态方法
class Student(object):
def __init__(self, name):
self.name = name
@staticmethod
def sayHello(lang):
print(lang)
if lang == 'en':
print('Welcome!')
else:
print('你好!')
Student.sayHello('en') # 类调用,'en'传给了lang参数
en
Welcome!
b = Student('Kim')
b.sayHello('zh') # 类实例对象调用,'zh'传给了lang参数
zh
你好
170.简述什么是浏览器的同源策略
所谓同源是指,域名,协议,端口相同。不同源的客户端脚本在没有明确授权的情况下,不能读写对方的资源
171.git commit –amend有何用处
比方说,你的代码已经提交到git库,leader审核的时候发现有个Java文件代码有点问题,于是让你修改,通常有2种方法:
方法1:leader 将你提交的所有代码 abandon掉,然后你回去 通过git reset …将代码回退到你代码提交之前的版本,然后你修改出问题的Java文件,然后 git add xx.java xxx.java -s -m “Porject : 1.修改bug…”
最后通过 git push origin HEAD:refs/for/branches
方法2:leader不abandon代码,你回去之后,修改出问题的Java文件,修改好之后,git add 该出问题.java
然后 git commit –amend –no-edit,
最后 git push origin HEAD:refs/for/branches
172.git如何查看某次提交修改的内容
我们首先可以git log显示历史的提交列表:
之后我们用git show 便可以显示某次提交的修改内容
同样 git show filename 可以显示某次提交的某个内容的修改信息
173.git如何比较两个commit的区别
git diff commit-id-1 commit-id-2 > d:/diff.txt
结果文件diff.txt中:
"-"号开头的表示 commit-id-2 相对 commit-id-1 减少了的内容。
"+"号开头的表示 commit-id-2 相对 commit-id-1 增加了的内容。
174.git如何把分支A上某个commit应用到分支B上
1).执行git log -3 --graph A,查看A分支下的commit: 注:commit 后面的hash值代表某个commit,这里把”82f1fb7138c5860cc775b4b5ea71c5d19c4e6497“这个commit提交到B。
2).执行git checkout B,切换到B分支;
3).执行 git cherry-pick 82f1fb7138c5860cc775b4b5ea71c5d19c4e6497,该commit便被提交到了B分支;
4).git push //注:将该commit推到远程服务器
175.请简述HTTP缓存机制
简单来说就是把一个已经请求过的 Web 资源(如 html 页面,图片, js,数据等)拷贝一份副本储存在浏览器中。缓存会根据进来的请求保存输出内 容的副本。当下一个请求来到的时候,如果是相同的 URL,缓存会根据缓存机制 决定是直接使用副本响应访问请求,还是向源服务器再次发送请求。比较常见的 就是浏览器会缓存访问过网站的网页,当再次访问这个 URL 地址的时候,如果网 页没有更新,就不会再次下载网页,而是直接使用本地缓存的网页。只有当网站 明确标识资源已经更新,浏览器才会再次下载网页
好处:
减少请求次数,减小服务器压力,本地数据读取速度更快,让页面不会空白几百毫秒,在无网络的情况下提供数据。
176.实现一个函数,在给定数组中寻找第2 大的数。
def fn():
a=[1,3,5,7,9]
return sorted(a[1])
177.求二叉树深度
class TreeNode(object):
def __init__(self, x):
self.val = x
self.left = None
self.right = None
class Solution(object):
def isBalanced(self, root):
if root==None:
return 0
leftheight=self.isBalanced(root.left)
rightheight=self.isBalanced(root.right)
if leftheight>=rightheight:
return leftheight+1
else:
return rightheight+1
input_3=TreeNode(3)
input_4=TreeNode(4)
input_5 = TreeNode(5)
input_5.left=input_3
input_5.right=input_4
input_18 = TreeNode(18)
input_all = TreeNode(2)
input_all.left = input_5
input_all.right = input_18
slu_ = Solution()
print (input_all)
t = slu_.isBalanced(input_all)
print (t)
178.求两个字符串的最长公共子串
def initindexs(char, string):
index = []
length = len(string)
for i in range(length):
if char == string[i]:
index.append(i + 1) # 保存相同字符坐标+1的位置
return index
def Substring(str1, str2):
str1_len = len(str1)
str2_len = len(str2)
length = 0
longest = 0
startposition = 0
start = 0
for i in range(str1_len):
start = i
index = initindexs(str1[i], str2)
index_len = len(index)
for j in range(index_len):
end = i + 1
while end < str1_len and index[j] < str2_len and str1[end] == str2[index[j]]: # 保证下标不会超出列表范围
end += 1
index[j] += 1
length = end - start
if length > longest:
longest = length
startposition = start
return startposition, longest
str1 = "pmcdcdfe"
str2 = 'aoccddcdfe'
Substring(str1, str2)
(start, longest) = Substring(str1, str2)
print(start, longest)
for i in range(longest):
print(str1[start + i], end=' ')
178.请列举你所知道的Python代码检测工具及它们之间的区别
Flake8 是由Python官方发布的一款辅助检测Python代码是否规范的工具,相对于目前热度比较高的Pylint来说,Flake8检查规则灵活,支持集成额外插件,扩展性强。Flake8是对下面三个工具的封装:
1)PyFlakes:静态检查Python代码逻辑错误的工具。
2)Pep8: 静态检查PEP8编码风格的工具。
3)NedBatchelder’s McCabe script:静态分析Python代码复杂度的工具。
不光对以上三个工具的封装,Flake8还提供了扩展的开发接口
Pylint 是一个 Python 代码分析工具,它依据的标准是Guido van Rossum的PEP8。它分析 Python 代码中的错误,查找不符合代码风格标准和有潜在问题的代码。目前 Pylint 的最新版本是 pylint-0.18.1。
Pylint 是一个 Python 工具,除了平常代码分析工具的作用之外,它提供了更多的功能:如检查一行代码的长度,变量名是否符合命名标准,一个声明过的接口是否被真正实现等等。
Pylint 的一个很大的好处是它的高可配置性,高可定制性,并且可以很容易写小插件来添加功能。
如果运行两次 Pylint,它会同时显示出当前和上次的运行结果,从而可以看出代码质量是否得到了改进。
179.请简述你对单元测试的理解并列举Python单元测试相关的工具和库
在编写代码的时候,所有的错误都可以通过对代码的仔细测试检查出来,Unit testing特指在一个分隔的代码单元中的测试。一个单元可以是整个模块,一个单独的类或者函数,或者这两者间的任何代码。然而,重要的是,测试代码要与我们没有测试到的其他代码相互隔离,因为其他代码本身有错误的话会因此混淆测试结果,因此便有了单元测试的概念,单元测试的重要性就不多说了,python中有太多的单元测试框架和工具,什么unittest, testtools, subunit, coverage, testrepository, nose, mox, mock, fixtures, discover,再加上setuptools, distutils等等这些,先不说如何写单元测试,光是怎么运行单元测试就有N多种方法,再因为它是测试而非功能,是很多人没兴趣触及的东西。但是作为一个优秀的程序员,不仅要写好功能代码,写好测试代码一样的彰显你的实力。
180.简述代码抛出以下异常的原因
IndexError : 超出对象索引的范围时抛出的异常
AttributeError : 当访问的对象属性不存在的时候抛出的异常
AssertionError : 当assert断言条件为假的时候抛出的异常
NotImplementedError : 尚未实现的方法
StopIteration : 迭代器没有更多的值
TypeError : 类型错误,通常是不同类型之间的操作会出现此异常
181.如何快速计算两个list的交集、并集
#简单的方法:
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
b = [2, 5, 8, 11, 0]
# 交集(intersection)
intersection = [v for v in a if v in b]
# 并集( union)
union = b.extend([v for v in a])
#高效的方法:
# 交集(intersection)
intersection = list(set(a).intersection(set(b)))
# 并集(union)
union = list(set(a).union(set(b)))
182.翻转一个字符串s = “abcdef”
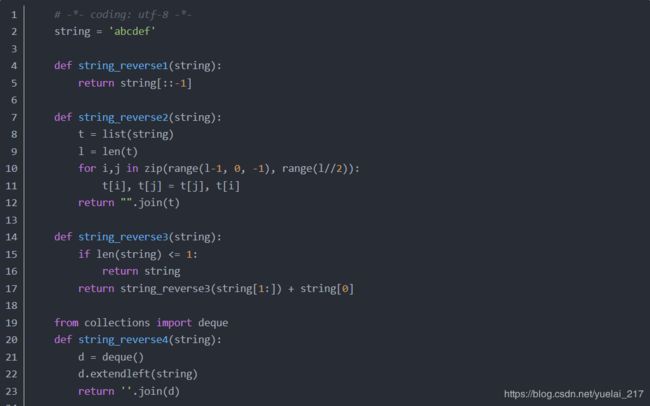
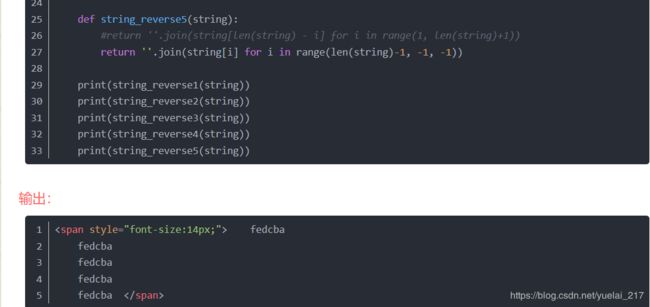
183.实现一个装饰器,用于鉴权(已经有鉴权函数user_auth(user_id,token))

184.用一条命令关掉所有的Python进程
quit() exit() 执行到此命令时,程序终止。
如果是程序陷入死循环,想强制结束,则按Ctrl + C
185.在用git提交中,如何避免提交pyc文件
一般来说每个Git项目中都需要一个“.gitignore”文件,这个文件的作用就是告诉Git哪些文件不需要添加到版本管理中。实际项目中,很多文件都是不需要版本管理的,比如Python的.pyc文件和一些包含密码的配置文件等等。这个文件的内容是一些规则,Git会根据这些规则来判断是否将文件添加到版本控制中。
有两种方法可以实现过滤掉Git里不想上传的文件:
1)第一种方法
针对单一工程排除文件,这种方式会让这个工程的所有修改者在克隆代码的同时,也能克隆到过滤规则,而不用自己再写一份,这就能保证所有修改者应用的都是同一份规则,而不是张三自己有一套过滤规则,李四又使用另一套过滤规则,个人比较喜欢这个。配置步骤如下:
在工程根目录下建立.gitignore文件,将要排除的文件或目录 写到.gitignore这个文件中,其中有两种写入方法。
a).使用命令行增加排除文件
排除以.class结尾的文件 echo “*.class” >.gitignore (>> 是在文件尾增加,> 是删除已经存在的内容再增加),之后会在当前目录下生成一个.gitignore的文件。
排除bin目录下的文件 echo “bin/” >.gitignore
b).最方便的办法是,用记事本打开,增加需要排除的文件或目录,一行增加一个,例如:
*.class
*.apk
bin/
gen/
.settings
proguards/
2)第二种方法
全局设置排除文件,这会在全局起作用,只要是Git管理的工程,在提交时都会自动排除不在控制范围内的文件或目录。这种方法对开发者来说,比较省事,只要一次全局配置,不用每次建立工程都要配置一遍过滤规则。但是这不保证其他的开发者在克隆你的代码后,他们那边的规则跟你的是一样的,这就带来了代码提交过程中的各种冲突问题。
配置步骤如下:
a)像方法(1)一样,也需要建立一个.gitignore文件,把要排除的文件写进去。
b)但在这里,我们不规定一定要把.gitnore文件放到某个工程下面,而是任何地方,比如我们这里放到了Git默认的Home路径下,比如:/home/wangshibo/hqsb_ios
c)使用命令方式可以配置全局排除文件 git config --global core.excludesfile /.gitignore,你会发现在/.gitconfig文件中会出现excludesfile = /home/wangshibo/hqsb_ios/.gitignore。
说明Git把文件过滤规则应用到了Global的规则中。
186.用户注册用户名时,如何做一些控制(如何防止注入攻击)
程序开发过程中不注意规范书写sql语句和对特殊字符进行过滤,导致客户端可以通过全局变量POST和GET提交一些sql语句正常执行。产生Sql注入。
SQL注入的产生原因通常表现在以下几方面:①不当的类型处理;②不安全的数据库配置;③不合理的查询集处理;④不当的错误处理;⑤转义字符处理不合适;⑥多个提交处理不当。
下面是防止办法:
1.永远不要信任用户的输入。对用户的输入进行校验,可以通过正则表达式,或限制长度;对单引号和
双"-"进行转换等。
2.永远不要使用动态拼装sql,可以使用参数化的sql或者直接使用存储过程进行数据查询存取。
3.永远不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的数据库连接。
4.不要把机密信息直接存放,加密或者hash掉密码和敏感的信息。
5.应用的异常信息应该给出尽可能少的提示,最好使用自定义的错误信息对原始错误信息进行包装
6.sql注入的检测方法一般采取辅助软件或网站平台来检测,软件一般采用sql注入检测工具jsky,网站平台就有亿思网站安全平台检测工具。MDCSOFT SCAN等。采用MDCSOFT-IPS可以有效的防御SQL注入,XSS攻击等。
187.怎么从request判断是哪个用户发来的
会话(Session)跟踪是Web程序中常用的技术,用来跟踪用户的整个会话。常用的会话跟踪技术是Cookie与Session。Cookie通过在客户端记录信息确定用户身份,Session通过在服务器端记录信息确定用户身份。
188.request有几种类型的请求
请求类型:
>>>r = request.post(‘https://httpbin.org/post’)
>>>r = request.put(‘http://httpbin.org/put’)
>>>r = request.delete(‘http://httpbin.org/delete’)
>>>r = request.head(‘http://httbin.org/head’)
>>>r = request.options(‘http://httpbin.org/options’)
189.post请求发送成功返回的状态码
2XX是请求正常处理完毕的意思,表示成功状态码
分为三类:
200 ok 表示从客户端发来的请求在服务器被正常处理了。
204 no content 表示从客户端发来的请求在服务器被正常处理了,但在返回的响应报文中不含实体的主体部分。
206 partial content 表示客户端进行了范围请求,而服务器成功执行了这部分的GET请求。
190.Linux和windows的区别
价格和开源
在中国,windows和linux都是免费的,至少对个人用户是如此,但是Windows盗版比较严重,如果严打,对Linux来说就是一大好处。
开源就是指对外部开放软件源代码。
windows平台:数量和质量的优势,不过大部分为收费软件;由微软官方提供重要支持和服务。
linux平台:大都为开源自由软件,用户可以修改定制和再发布,由于基本免费没有资金支持,部分软件质量和体验欠缺。
191.用户用登陆注册页面时报错400,403,500怎样排查出来错误
400错误:由于语法格式有误,服务器无法理解此请求。不作修改,客户程序就无法重复此请求。
403错误:
403.1 禁止:禁止执行访问
如果从并不允许执行程序的目录中执行 CGI、ISAPI或其他执行程序就可能引起此错误。
如果问题依然存在,请与 Web 服务器的管理员联系。
403.2 禁止:禁止读取访问
如果没有可用的默认网页或未启用此目录的目录浏览,或者试图显示驻留在只标记为执行。
脚本权限的目录中的HTML 页时就会导致此错误。
如果问题依然存在,请与 Web 服务器的管理员联系。
403.3 禁止:禁止写访问
如果试图上载或修改不允许写访问的目录中的文件,就会导致此问题。
如果问题依然存在,请与 Web服务器的管理员联系。
403.4 禁止:需要 SSL
此错误表明试图访问的网页受安全套接字层(SSL)的保护。要查看,必须在试图访问的地址前输入https:// 以启用 SSL。
如果问题依然存在,请与 Web服务器的管理员联系。
403.5 禁止:需要 SSL 128
此错误消息表明您试图访问的资源受 128位的安全套接字层(SSL)保护。要查看此资源。
需要有支持此SSL 层的浏览器。
请确认浏览器是否支持 128 位 SSL安全性。如果支持,就与 Web服务器的管理员联系,并报告问题。
403.6 禁止:拒绝 IP 地址
如果服务器含有不允许访问此站点的 IP地址列表,并且您正使用的 IP地址在此列表中,会导致此问题。
如果问题依然存在,请与 Web服务器的管理员联系。
403.7 禁止:需要用户证书
当试图访问的资源要求浏览器具有服务器可识别的用户安全套接字层(SSL)证书时就会导致此问题。可用来验证您是否为此资源的合法用户。
请与 Web服务器的管理员联系以获取有效的用户证书。
403.8 禁止:禁止站点访问
如果 Web服务器不为请求提供服务,或您没有连接到此站点的权限时,就会导致此问题。
请与 Web 服务器的管理员联系。
403.9 禁止访问:所连接的用户太多
如果 Web太忙并且由于流量过大而无法处理您的请求时就会导致此问题。请稍后再次连接。
如果问题依然存在,请与 Web 服务器的管理员联系。
403.10 禁止访问:配置无效
此时 Web 服务器的配置存在问题。
如果问题依然存在,请与 Web服务器的管理员联系。
403.11 禁止访问:密码已更改
在身份验证的过程中如果用户输入错误的密码,就会导致此错误。请刷新网页并重试。
如果问题依然存在,请与 Web服务器的管理员联系。
403.12 禁止访问:映射程序拒绝访问
拒绝用户证书试图访问此 Web 站点。
请与站点管理员联系以建立用户证书权限。如果必要,也可以更改用户证书并重试。
500错误:
500 服务器的内部错误
Web 服务器不能执行此请求。请稍后重试此请求。
如果问题依然存在,请与 Web服务器的管理员联系。
192.nginx部署具体操作
Nginx的特点:静态资源的高并发,反向代理加速,支持FastCGI,运行SSL、TSL
环境部署:
1)安装编译环境
yum install -y gcc gcc-c++ openssl openssl-devle pcre pcre-devel make get curl
pcre-devel 兼容正则表达式
2)创建安装目录,下载资源
mkdir -p /Application/tools
wget http://nginx.org/download/nginx-****.tar.gz
3)解压文件,并进入安装文件目录
tar zxf nginx-.tar.gz && cd nginx-
4)创建用户
创建一个没有家目录的且不能登录的用户nginx
sudo useradd nginx -s /sbin/nologin -M
sudo id nginx
uid=501(nginx) gid=501(nginx) groups=501(nginx)
5)配置
./configure --user=nginx --group=nginx --prefix=/Application/nginx-** --with-http_sub_module
指定运行软件的用户名 运行软件的组 指定安装路径 启用Nginx运行状态模块
6)编译并安装
make && make install
7)测试安装结果
7).1:查看进程
ps -ef |grep nginx |grep -v grep
root 2232 1 0 11:14 ? 00:00:00 nginx: master process /usr/local/nginx/sbin/nginx
nginx 9451 2232 0 13:58 ? 00:00:00 nginx: worker process
7).2:查看端口
netstat -antulp |grep nginx
tcp 0 0 0.0.0.0:80 0.0.0.0: LISTEN 2232/nginx
7).3:文本工具测试
7).3.1:curl 127.0.0.1
Welcome access www.52linux.club
7).3.2:www.52linux.club
8)创建软链接
8).1.用于版本升级中,代码的固定安装位置或参数的引用
8).2.ln -s /Application/nginx-1.12.1 /usr/loacl/nginx
lrwxrwxrwx 1 root root 25 Mar 16 15:49 nginx -> /Application/nginx-1.12.1
193.python常用的数据结构的类型及特性
数字型(整数型(int),浮点数型,复数型,布尔数型):
特性:
1)只能存放一个值
2)一经定义,不可更改
3)直接访问
字符串型:
特性:
1)用来存储文本信息的容器
2)不可变数据类型
3)序列
列表:
特性:
1)可存放多个值
2)可变数据类型
3)序列
4)表内元素直接无联系
元组:
特性:
1)可存放多个值
2)不可变数据类型
3)序列
4)表内元素直接无联系
字典:
特性:
1)可存放多个值
2)以键值对方式存储
3)无序
4)可变数据类型
5)键是唯一的
集合:
特性:
1)可存放多个值
2)元素唯一
3)无序
4)可变数据类型
5)可用作字典的键
字节型:存储以字节为单位的数据
特性:
1)只能存放一个值
2)不可变数据类型
3)有序
194.简述一下协议HTTP,tcp,udp
http: 规定了浏览器与服务器之间的请求和响应的格式与规则,它是万维网上能够可靠地交换文件的重要基础。
tcp:传输可靠性,无错序,无漏,无缺失,传输过程中有建立和断开连接过程即三次握手四次挥手的过程,适用情况:稳定传输文件,网络良好的情况。邮件等大型数据
udp:不能保证数据传输的可靠性,没有建立和断开连接的过程,信息收发比较自由。
适用情况:网络视频,群聊,发广播。
195.Python中的复制,底层是怎么实现的.
Python中,对象的赋值实际上是简单的对象引用。也就是说,当你创建一个对象,然后把它复制给另一个变量的时候,Python并没有拷贝这个对象,而是拷贝了这个对象的引用。
196.登录一个网站发生的过程,越详细越好
一个网页从请求到最终显示的完整过程一般可分为如下7个步骤:
1). 在浏览器中输入网址;
2). 发送至DNS服务器并获得域名对应的WEB服务器的IP地址;
3). 与WEB服务器建立TCP连接;
4). 浏览器向WEB服务器的IP地址发送相应的HTTP请求;
5). WEB服务器响应请求并返回指定URL的数据,或错误信息,如果设定重定向,则重定向到新的URL地址。
6). 浏览器下载数据后解析HTML源文件,解析的过程中实现对页面的排版,解析完成后在浏览器中显示基础页面。
7). 分析页面中的超链接并显示在当前页面,重复以上过程直至无超链接需要发送,完成全部显示。
197.说一下HTTP协议
超文本传输协议是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。HTTP是一个客户端和服务器端请求和应答的标准。客户端是终端用户,服务器端是网站。通过使用Web浏览器、网络爬虫或者其它的工具,客户端发起一个到服务器上指定端口的HTTP请求,叫用户代理。应答的服务器上存储着资源,比如HTML文件和图像。这个应答服务器为源服务器。在用户代理和源服务器中间可能存在http和其他几种网络协议多个中间层,比如代理,网关,或者隧道(tunnels)。尽管TCP/IP协议是互联网上最流行的应用,HTTP协议并没有规定必须使用它和它支持的层。 事实上,HTTP可以在任何其他互联网协议上,或者在其他网络上实现。HTTP只假定可靠的传输,任何能够提供这种保证的协议都可以被其使用。
特点:
1)一个应用层协议,传输层使用tcp传输
2)简单灵活,和多种语言对接方便
3)无状态协议,不记录用户的通信内容
4)成熟稳定http1.1
工作模式:
1)使用http双方均遵循http协议规定发送接收消息体。
2)请求方,根据协议住址请求内容发送给对象
3)服务方,收到内容按照协议解析
4)服务方,将回复内容按照协议组织发送给请求方
5)请求方,收到回复根据协议解析
HTTP(超文本传输协议)是利用TCP在两台电脑(通常是Web服务器和客户端)之间传输信息的协议。客户端使用Web浏览器发起HTTP请求给Web服务器,Web服务器发送被请求的信息给客户端。
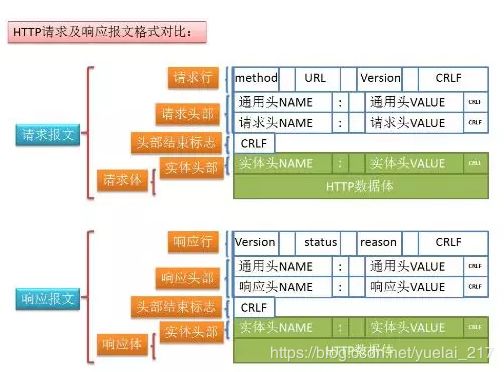
HTTP是短连接:客户端发送请求都需要服务器端回送响应.请求结束后,主动释放链接,因此为短连接。通常的做法是,不需要任何数据,也要保持每隔一段时间向服务器发送"保持连接"的请求。这样可以保证客户端在服务器端是"上线"状态。
HTTP连接使用的是"请求-响应"方式,不仅在请求时建立连接,而且客户端向服务器端请求后,服务器才返回数据。
Socket协议
网络上的两个程序通过一个双向的通信连接实现数据的交换,这个连接的一端称为一个socket。

建立网络通信连接至少要一对端口号(socket)。socket本质是编程接口(API),对TCP/IP的封装,TCP/IP也要提供可供程序员做网络开发所用的接口,这就是Socket编程接口;HTTP是轿车,提供了封装或者显示数据的具体形式;Socket是发动机,提供了网络通信的能力。
198.Selenium
Selenium [1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
199.字符串格式化:% 和 format的区别
字符串的format函数非常灵活,很强大,可以接受的参数不限个数,并且位置可以不按顺序,而且有较为强大的格式限定符(比如:填充,对齐,精度等).
200.主机与主机之间通讯的三要素有什么
(1).IP地址
(2).子网掩码
(3).IP路由
201.181.Linux下统计根目录下后缀为log的文件数量
find . -name '*.log' | wc -l
202.打印3天前的日期,格式如:2016-05-06
date -d 2016-05-06
203.解释ps aux 中的VSZ,RSS
VSZ 虚拟内存集,进程占用的虚拟内存空间
RSS 物理内存集,进程战用实际物理内存空间.
204.判断一个字符串是否为回文字符串(将字符串反转之后,得到的字符串同原字符串,称为回文字符串
s = input("请输入文字: ")
# 反转字符串s
r = s[::-1]
if s == r:
print(s, "是回文")
else:
print(s, "不是回文")
205.Python转义字符
| 转移符 | 说明 |
|---|---|
| (在行尾时) | 续行符 |
| \ | 反斜杠符号 |
| ’ | 单引号 |
| " | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy代表的字符,例如:\o12代表换行 |
| \xyy | 十六进制数,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
206.python格式化字符串(格式化操作符)(%)
| 格式化符号 | 说明 |
|---|---|
| %c | 转换成字符(ASCII 码值,或者长度为一的字符串) |
| %r | 优先用repr()函数进行字符串转换 |
| %s | 优先用str()函数进行字符串转换 |
| %d / %i | 转成有符号十进制数 |
| %u | 转成无符号十进制数 |
| %o | 转成无符号八进制数 |
| %x / %X | 转成无符号十六进制数(x/X代表转换后的十六进制字符的大小写) |
| %e / %E | 转成科学计数法(e / E控制输出e / E) |
| %f / %F | 转成浮点数(小数部分自然截断) |
| %g / %G | %e和%f / %E和%F 的简写 |
| %% | 输出% (格式化字符串里面包括百分号,那么必须使用%% |
格式化操作符辅助符
| 辅助符号 | 说明 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号(+) |
| # | 在八进制数前面显示零(0),在十六进制前面显示"0x"或者"0X"(取决于用的是"x"还是"X") |
| 0 | 显示的数字前面填充"0"而不是默认的空格 |
| (var) | 映射变量(通常用来处理字段类型的参数) |
| m.n | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
207.linux系统根目录下各个文件夹的含义

1)、/- 根
每一个文件和目录从根目录开始。
只有root用户具有该目录下的写权限。请注意,/root是root用户的主目录,这与/.不一样
2)、/bin中 - 用户二进制文件
包含二进制可执行文件。
在单用户模式下,你需要使用的常见linux命令都位于此目录下。系统的所有用户使用的命令都设在这里。
例如:ps、ls、ping、grep、cp
3)、/sbin目录 - 系统二进制文件
就像/bin,/sbin同样也包含二进制可执行文件。
但是,在这个目录下的linux命令通常由系统管理员使用,对系统进行维护。例如:iptables、reboot、fdisk、ifconfig、swapon命令
4)、/etc - 配置文件
包含所有程序所需的配置文件。
也包含了用于启动/停止单个程序的启动和关闭shell脚本。例如:/etc/resolv.conf、/etc/logrotate.conf
5)、/dev - 设备文件
包含设备文件。
这些包括终端设备、USB或连接到系统的任何设备。例如:/dev/tty1、/dev/usbmon0
6)、/proc - 进程信息
包含系统进程的相关信息。
这是一个虚拟的文件系统,包含有关正在运行的进程的信息。例如:/proc/{pid}目录中包含的与特定pid相关的信息。
这是一个虚拟的文件系统,系统资源以文本信息形式存在。例如:/proc/uptime
7)、/var - 变量文件
var代表变量文件。
这个目录下可以找到内容可能增长的文件。
这包括 - 系统日志文件(/var/log);包和数据库文件(/var/lib);电子邮件(/var/mail);打印队列(/var/spool);锁文件(/var/lock);多次重新启动需要的临时文件(/var/tmp);
8)、/tmp - 临时文件
包含系统和用户创建的临时文件。
当系统重新启动时,这个目录下的文件都将被删除。
9)、/usr - 用户程序
包含二进制文件、库文件、文档和二级程序的源代码。
/usr/bin中包含用户程序的二进制文件。如果你在/bin中找不到用户二进制文件,到/usr/bin目录看看。例如:at、awk、cc、less、scp。
/usr/sbin中包含系统管理员的二进制文件。如果你在/sbin中找不到系统二进制文件,到/usr/sbin目录看看。例如:atd、cron、sshd、useradd、userdel。
/usr/lib中包含了/usr/bin和/usr/sbin用到的库。
/usr/local中包含了从源安装的用户程序。例如,当你从源安装Apache,它会在/usr/local/apache2中。
10)、/home - HOME目录
所有用户用home目录来存储他们的个人档案。
例如:/home/john、/home/nikita
11)、/boot - 引导加载程序文件
包含引导加载程序相关的文件。
内核的initrd、vmlinux、grub文件位于/boot下。
例如:initrd.img-2.6.32-24-generic、vmlinuz-2.6.32-24-generic
12)、/lib - 系统库
包含支持位于/bin和/sbin下的二进制文件的库文件.
库文件名为 ld或lib.so.*
例如:ld-2.11.1.so,libncurses.so.5.7
13)、/opt - 可选的附加应用程序
opt代表可选的。
包含从个别厂商的附加应用程序。
附加应用程序应该安装在/opt/或者/opt/的子目录下。
14)、/mnt - 挂载目录
临时安装目录,系统管理员可以挂载文件系统。
15)、/media - 可移动媒体设备
用于挂载可移动设备的临时目录。
举例来说,挂载CD-ROM的/media/cdrom,挂载软盘驱动器的/media/floppy;
16)、/srv - 服务数据
srv代表服务。
包含服务器特定服务相关的数据。
例如,/srv/cvs包含cvs相关的数据。
A-Za-z ↩︎