一、彻底理解一元线性回归——梯度下降法
本次推论会从最小二乘法去讲解一元线性回归

代价函数(损失函数):
![]()
核心思想是通过改变 θ0 和 θ1 , 使代价函数的值最小
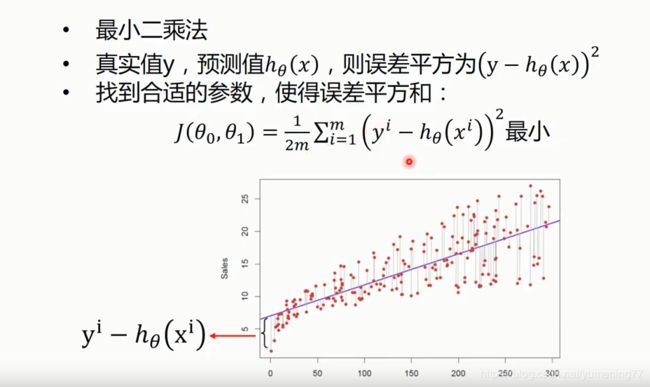
公式的含义是,用所有点的误差的平方(这里用平方是为了变成正数好处理)累加,再除上点的数量,算出每个点误差平方的平均数,而前面加的1/2 是为了求导的时候好化简。m代表实验点的个数。
如果令 θ0 = 0,则公式可以化简为:
![]()
假设有三个样本点,用红叉表示。当θ1 = 1 时 , 函数如左图所示:
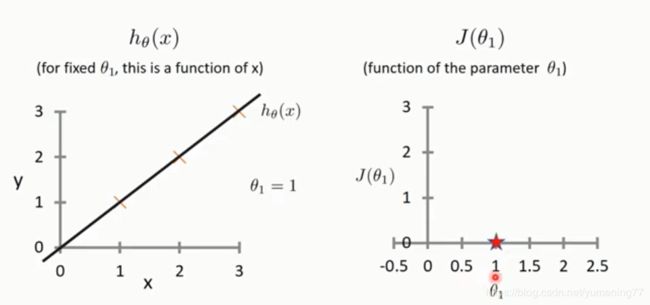
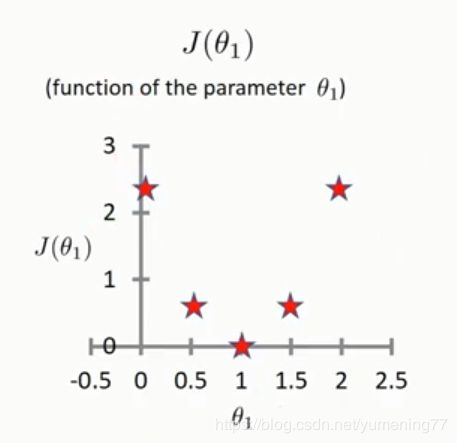
上述右图中x轴表示θ1的取值,y轴表示损失函数的值,可以看出当前损失函数的值为0。
当θ1 = 0.5 时,通过代价函数公式可以计算出代价函数的值为:
1/(2*3)[(1-0.5)^2 + (2-1)^2 + (3-1.5)^2] = 1/6 * 3.5 约等于 0.583
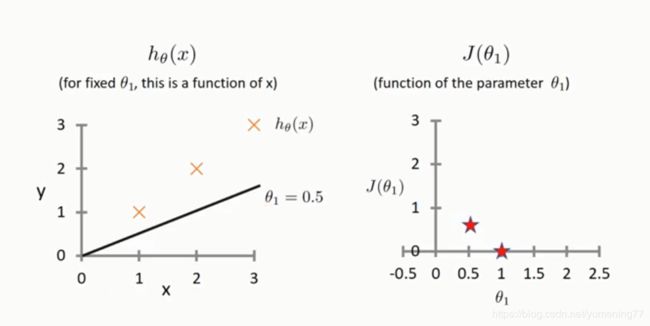
当θ1 = 0 时,通过代价函数公式可以计算出代价函数的值为:
1/(2*3)[(1-0)^2 + (2-0)^2 + (3-0)^2] = 1/6 * 14 约等于 2.333
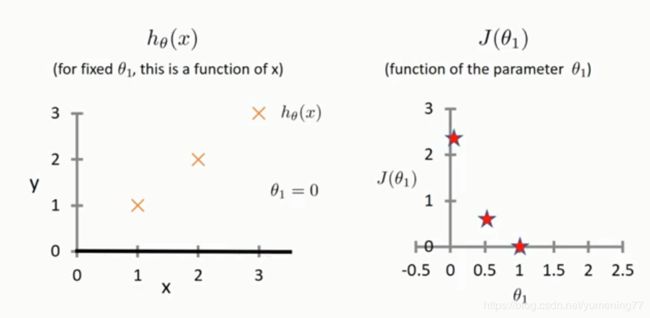
取了多个θ1的值后,可以得出如下图形:
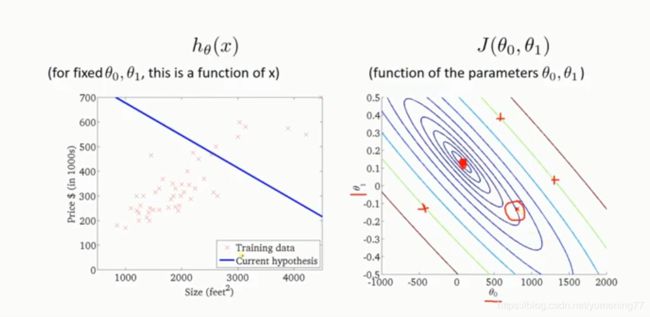
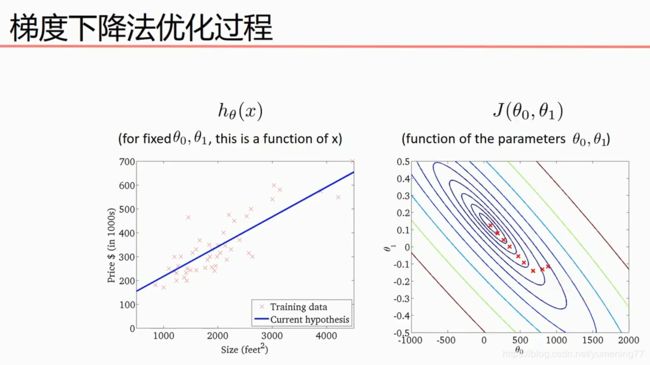
可以把θ0和θ1的取值画一个等高线(每一个圈上对应的所有点,代表取不同的斜率和截距,代价函数的值相同),中心的红点代表代价函数的最小值。当截距大概在七八百的位置,斜率为负数时,线性方程如左图,对应的代价函数的值如右图。
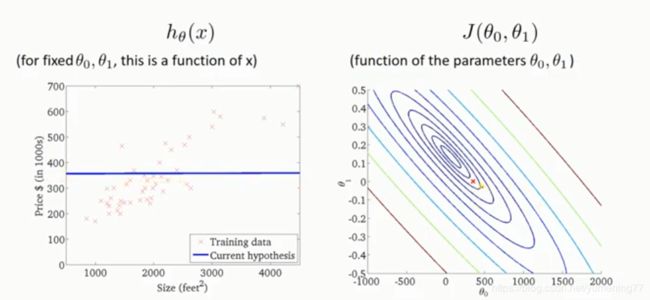
当斜率=0,截距=300多的时候,代价函数的值小了一些,线性方程与样本点会更加拟合一些。
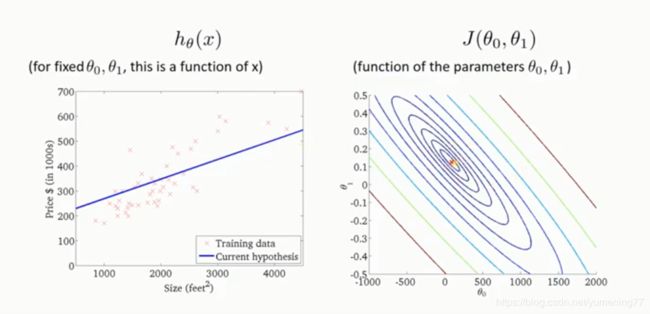
逐渐找出了一个代价函数最小值的斜率和截距,如下图:
相关系数:
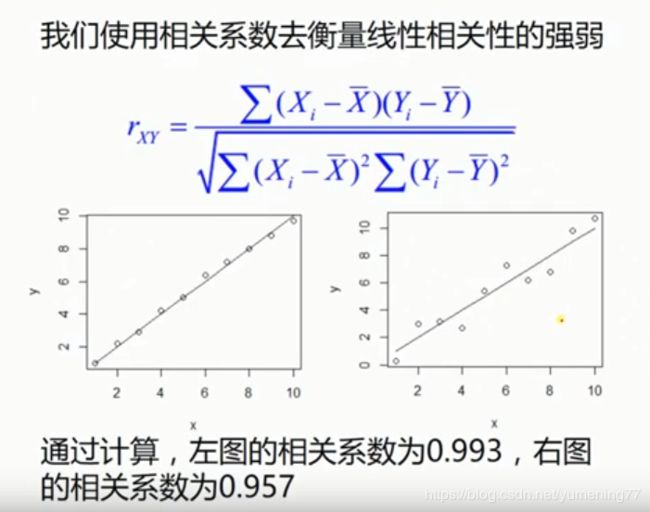
相关系数越接近于1,x和y的相关性越强,相关系数越接近于0,x和y的相关性越弱。相关系数越接近于-1,x和y的负相关性越强。
决定系数


决定系数越接近于1,则x和y越接近于线性的关系,决定系数越接近于0,则x和y越不接近于线性的关系。

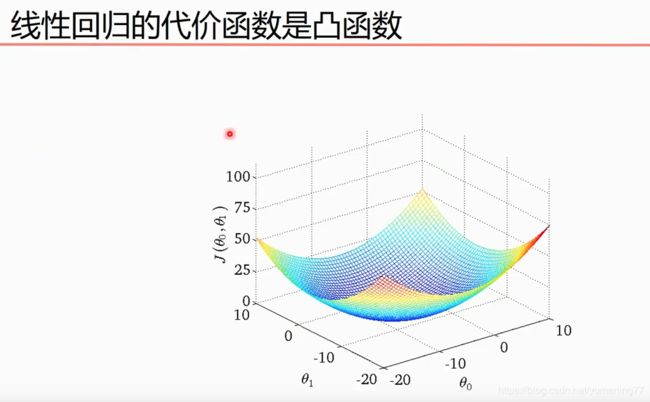
可以先下图三维坐标看出,θ0和θ1存在某个值,使得代价函数J(θ0,θ1)的值最小
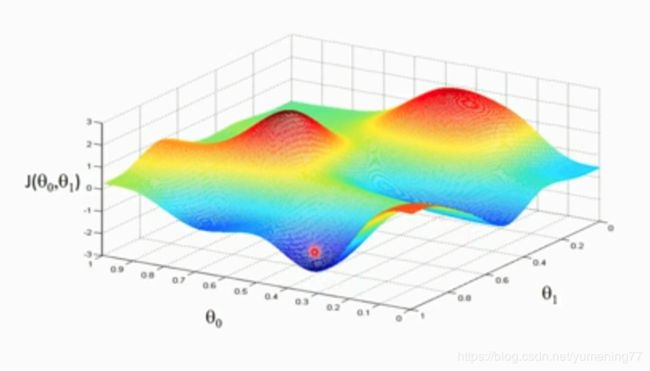
根据梯度下降法,可以得到一个全局最小值或局部极小值。
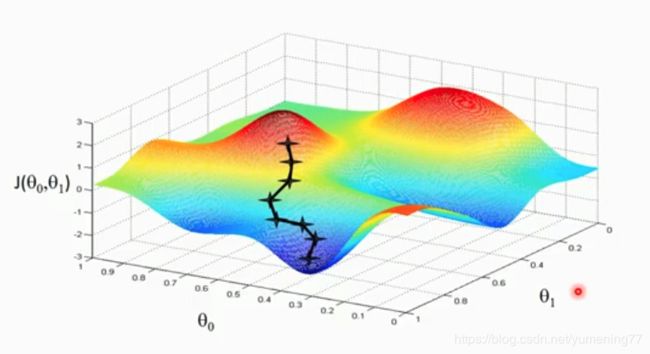
![]()

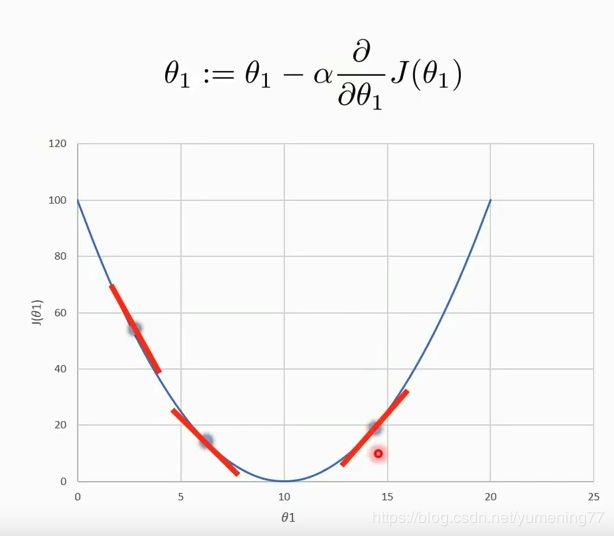
梯度下降法的公式:
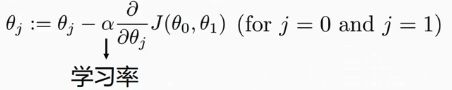
梯度下降法中:
α 是学习率
![]()
是对当前θ的代价函数求导
为什么要求导?
因为:
函数求导主要是研究函数值随自变量的值的变化而变化的趋势,如果导数小于零,那么函数单调递减,如果导数大于零,那么函数单调递增
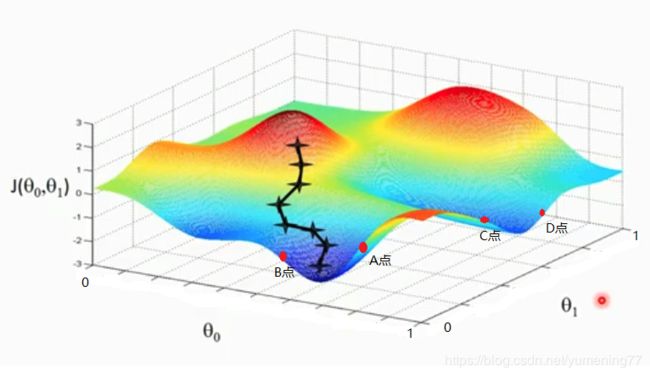
给θ0和θ1设一个初始值。
对θ0求导后,设导数值为p。
p的表达式如下:
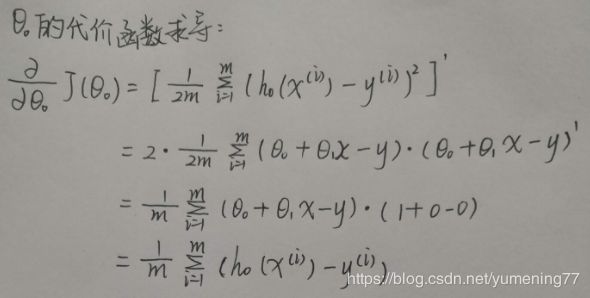
通过θ0和θ1的初始值,可以得出一组与真实值对应的预测值,可以算出p的具体值。
如果p大于0,代价函数随着θ0的增大而增大,可能在上图A点或相似位置,可以看出要减小代价函数的值,需要减小θ0的值。根据公式:
θ0 = θ0 - αp
α是正数,p也大于0,所以αp大于零。公式可以让θ0减小。
θ0减小后,会再次得出一组与真实值对应的预测值。再重复上述操作。
如果p小于0,可能在上图B点或相似位置,可以看出要减小代价函数的值,需要增大θ0的值。此时αp是一个负数,θ0 = θ0 - αp会让θ0的值增大。会再次得出一组与真实值对应的预测值。再重复上述操作。
对θ1也是同理。

根据上述化简得出的公式,整理得到:

再来说说学习率

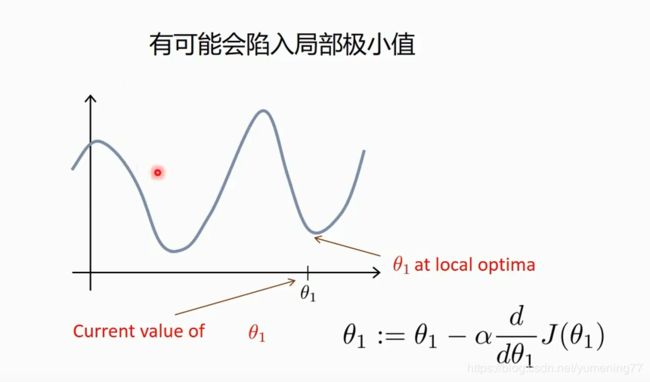
边缘凸,中间凹的叫凸函数。边缘凹,中间凸的叫凹函数。
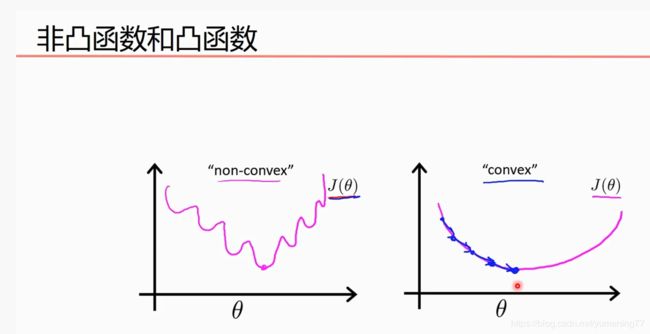
对于凸函数,随便选区一个初始值,使用梯度下降法,肯定会逐步得到一个全局最小值。
由于线性回归的代价函数是凸函数,所以肯定只有一个全局最小值,非常适合用梯度下降法。
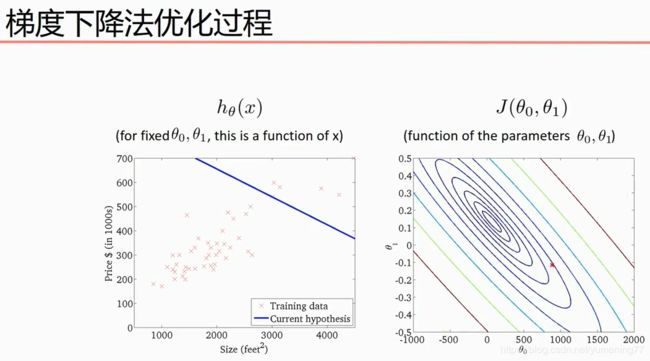
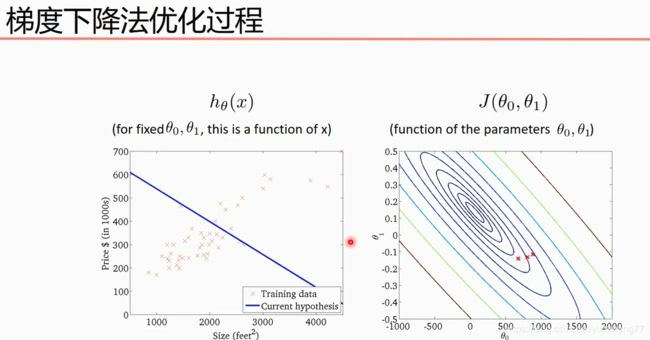
梯度下降法的实现,代码如下:
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('linear_regression.csv', header=None)
x_data = data[0]
y_data = data[1]
# plt.scatter(x_data, y_data)
# plt.show()
# 学习率learning rate
lr = 0.0001
# 截距
b = 0
# 斜率
k = 0
# 最大迭代次数
epochs = 50
def compute_error(b, k, x_data, y_data):
'''
最小二乘法,计算代价函数的值
:param b: 截距
:param k: 斜率
:param x_data: x轴的数据集
:param y_data: y轴的数据集
:return:
'''
totalError = 0
for i in range(0, len(x_data)):
# 真实值减去预测值的平方再求和
totalError += (y_data[i] - (k * x_data[i] + b)) ** 2
return totalError / len(x_data) / 2
def gradient_descent_runner(b, k, x_data, y_data, lr, epochs):
'''
计算总数据量,算出b和k
:param b: 截距
:param k: 斜率
:param x_data: x轴的数据集
:param y_data: y轴的数据集
:param lr: 学习率
:param epochs: 迭代次数
:return:
'''
m = float(len(x_data))
for item in range(epochs):
b_temporary = 0
k_temporary = 0
for i in range(len(x_data)):
b_temporary += (k * x_data[i] + b) - y_data[i]
k_temporary += ((k * x_data[i] + b) - y_data[i]) * x_data[i]
b_temporary = b_temporary / m
k_temporary = k_temporary / m
# 更新截距和斜率
b = b - (lr * b_temporary)
k = k - (lr * k_temporary)
return b, k
if __name__ == '__main__':
# 打印初始截距和斜率对应的代价函数的值
print('Starting b = {0}, k = {1}, error = {2}'.format(b, k, compute_error(b, k, x_data, y_data)))
print('Running...')
b, k = gradient_descent_runner(b, k, x_data, y_data, lr, epochs)
# 打印经过50次迭代后的截距、斜率和对应代价函数的值
print('After {0} iterations b = {1}, k = {2}, error = {3}'.format(epochs, b, k, compute_error(b, k, x_data, y_data)))
# 绘图
plt.plot(x_data, y_data, 'b.')
plt.plot(x_data, k * x_data + b, 'r')
plt.show()
输出如下:
Starting b = 0, k = 0, error = 2782.553917241605
Running…
After 50 iterations b = 0.03056995064928798, k = 1.4788903781318354, error = 56.32488184238028
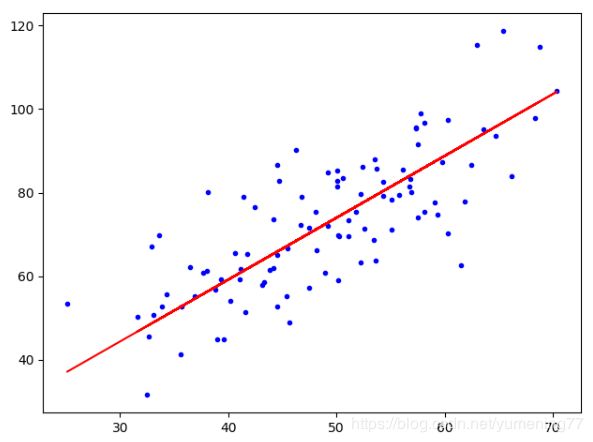
可以看出经过50次迭代,代价函数的值从2782减小到了56,如果把迭代次数改得更大,比如1000,代价函数的值还能再减小一点点,但是效果也不明显。