Selenium学习四——利用Python爬取网页多个页面的表格数据并存到已有的excel中
利用Python爬取网页多个页面的表格数据并存到已有的excel中
1、具体要求
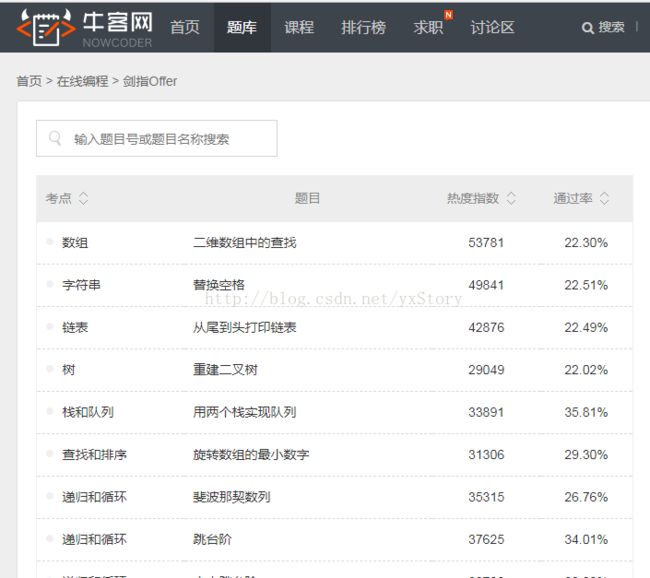
获取牛客网->题库->在线编程->剑指Offer网页,获取表格中的全部题目,保存到本地excel中
2、技术要求
利用Selenium+Python获取网页,操作到table页面
通过xlwt、xlrd、xlutils模块,将表格保存到本地excel
xlwt:写入excel(新建)
xlrd:读取excel
xlutils:将xlrd.Book转为xlwt.workbook,在原有的excel基础上进行修改,添加等。
技术博客参考:http://www.cnblogs.com/jiangzhaowei/p/5856604.html
3、主要代码
from xlutils.copy import copy
import xlwt
import xlrd
import os
def load_Table(page):
#创建工作簿
wbk = xlwt.Workbook(encoding='utf-8', style_compression=0)
#创建工作表
sheet = wbk.add_sheet('sheet 1', cell_overwrite_ok=True)
excel = r"C:\xxx\test.xls"
table_rows = driver.find_element_by_xpath("//*[@class='module-body offer-body']/table/tbody").find_elements_by_tag_name('tr')
row = 20
for i, tr in enumerate(table_rows):
if i==0 and page==0:
table_cols1 = tr.find_elements_by_tag_name('th')
for j, tc in enumerate(table_cols1):
sheet.write(i, j, tc.text)
wbk.save(excel)
else:
table_cols2 = tr.find_elements_by_tag_name('td')
for j, tc in enumerate(table_cols2):
#老的工作簿,打开excel
oldWb = xlrd.open_workbook(excel, formatting_info=True)
#新的工作簿,复制老的工作簿
newWb = copy(oldWb)
#新的工作表
newWs = newWb.get_sheet(0)
newWs.write(i + page * row, j, tc.text)
#os.remove(excel)
newWb.save(excel)
def switch_page():
#获取页数(除去首页 、尾页、上一页和下一页)
pages = driver.find_element_by_xpath("//*[@class='pagination']/ul").find_elements_by_tag_name('li')
t = len(pages)-4
for i in range(t):
driver.find_element_by_link_text(str(i+1)).click()
print i
load_Table(i)4、xlutils
引入模块
from xlutils.copy import copy
import xlwt
import xlrd用xlwt创建工作簿工作表
#创建工作簿
wbk = xlwt.Workbook(encoding='utf-8', style_compression=0)
#创建工作表
sheet = wbk.add_sheet('sheet 1', cell_overwrite_ok=True)写入excel,并保存到本地原有的excel中(用xlwt这样保存会覆盖之前的内容)
sheet.write(i, j, tc.text)
wbk.save(excel)
用xlrd打开excel(formatting_info=true保证时间数据在copy时保持原样)
oldWb = xlrd.open_workbook(excel, formatting_info=True)复制excel文件
newWb = copy(oldWb)读取复制的excel文件的第一个sheet
newWs = newWb.get_sheet(0)向这个sheet写入数据
newWs.write(i, j, tc.text)删除原先存在的excel
os.remove(excel)保存这个新的excel文件
newWb.save(excel)5、全部代码
#coding:utf-8 from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains from xlutils.copy import copy import xlwt import xlrd import os import time ''' 下载牛客网首页 > 在线编程 > 剑指Offer的题目表到excel 读取excel里的值 ''' driver = webdriver.Chrome() driver.get("https://www.nowcoder.com/") time.sleep(2) def switch_window(): #获取当前句柄 h = driver.current_window_handle print h #跳转到指定页面 element = driver.find_element_by_xpath("//*[@class='nowcoder-navbar']/li[2]/a") ActionChains(driver).move_to_element(element).perform() driver.find_element_by_xpath("//*[@class='sub-nav']/li[3]/a").click() time.sleep(2) driver.find_element_by_xpath("//*[@class='topic-list clearfix']/li[1]").click() #切换到指定页面 driver.close() all_h = driver.window_handles for i in all_h: if i != h: driver.switch_to.window(i) def load_Table(page): #创建工作簿 wbk = xlwt.Workbook(encoding='utf-8', style_compression=0) #创建工作表 sheet = wbk.add_sheet('sheet 1', cell_overwrite_ok=True) excel = r"C:\xxx\test.xls" table_rows = driver.find_element_by_xpath("//*[@class='module-body offer-body']/table/tbody").find_elements_by_tag_name('tr') row = 20 print row for i, tr in enumerate(table_rows): if i==0 and page==0: table_cols1 = tr.find_elements_by_tag_name('th') for j, tc in enumerate(table_cols1): sheet.write(i, j, tc.text) wbk.save(excel) else: table_cols2 = tr.find_elements_by_tag_name('td') for j, tc in enumerate(table_cols2): #老的工作簿,打开excel oldWb = xlrd.open_workbook(excel, formatting_info=True) #新的工作簿,复制老的工作簿 newWb = copy(oldWb) #新的工作表 newWs = newWb.get_sheet(0) newWs.write(i + page * row, j, tc.text) os.remove(excel) newWb.save(excel) print 'save done' def switch_page(): pages = driver.find_element_by_xpath("//*[@class='pagination']/ul").find_elements_by_tag_name('li') t = len(pages) for i in range(t-4): driver.find_element_by_link_text(str(i+1)).click() print i load_Table(i) switch_window() switch_page() print 'done'
6、遇到的问题
本次试验代码对于table换页的处理较为粗暴,直接通过点击页码操作,for循环将每一页添加到excel中去。由于是学的阶段,还有其他的方法以后再完善。
①在添加过程中,一开始没有使用xlutils,导致每次只有最后一页数据,因为覆盖了。
②后来添加的时候for语句没有写好,导致行乱序了,仔细一点就ok
注:数字变为字符串前面要加str转换,table的index从0开始,页面元素定位从1开始
如
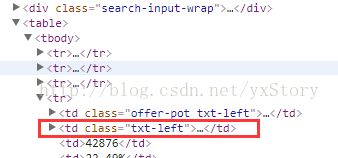
定位find_element_by_xxpath("//*[@class='search-input-wrap']/table/tbody/tr[4]/td[2]")