FastDFS的工作机制及优劣分析
一、FastDFS简介
FastDFS是一款开源的轻量级分布式文件系统,最早在ali,为易道用车架构师余庆所写。它用纯C语言实现,支持Linux、FreeBSD、AIX等UNIX系统。FastDFS为互联网应用量身定做,追求高性能和高扩展性,更适合称作应用级的分布式文件存储服务。它只能通过专有API对文件进行存取访问,不支持POSIX接口方式,通用性较低。
在语言支持方面,目前提供了C、java、php、.NET的API。
现应用在jd、taobao、58、uc、51cto。
二、FastDFS用途
1)FastDFS主要解决了大容量的文件存储和高并发访问的问题,文件存取时实现了负载均衡。
2)FastDFS实现了软件方式的RAID,可以使用廉价的IDE硬盘进行存储 ,支持存储服务器在线扩容。
3)FastDFS特别适合大中型网站使用,用来存储资源文件(如:图片、文档、音频、视频等等)。
三、FastDFS工作机制
1. 集群架构图

FastDFS集群架构由追踪服务器(tracker server)、存储服务器(storage server)和客户端(client)三个部分组成。
tracker server:主要做调度工作,在访问中起负载均衡作用,在内存中记录集群中group和storage server的状态信息,是连接client和storage server的枢纽,因为相关信息全部在内存中,tracker server的性能非常高(它本身所需负载很小),一个较大的集群中(如上百个group)有3台就足够。
storage server:文件和文件属性(如metadata)都保存在该server上,存储服务包括文件存储,文件同步,提供文件访问接口,同时以key-value的方式管理文件的元数据。
FastDFS架构解读
- 两个角色,tracker server和storage server,不需要存储文件索引信息。
- 所有服务器都是对等的,不存在Master-Slave关系。
- 存储服务器采用分组方式,同组内存储服务器上的文件完全相同(RAID 1)。
- storage集群中,组(或叫卷)和组之间不通信是相互独立的,storage主动向tracker汇报状态,所有组的容量累加就是整个存储系统中的文件容量,一个组可由一台或多台storage server组成,一个组内的所有单个存储服务器中的文件都是相同的,一组中的多台存储服务器起到了冗余备份和负载均衡的作用,在组中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务,当存储空间不足或即将耗尽时,可动态添加组,只需要增加一台或多台服务器,并将它们配置为一个新的组,这样就扩大了存储系统的容量。
- 扩展整个FastDFS集群容量,在storage里加group即可。
2. 上传下载机制
2.1 上传机制
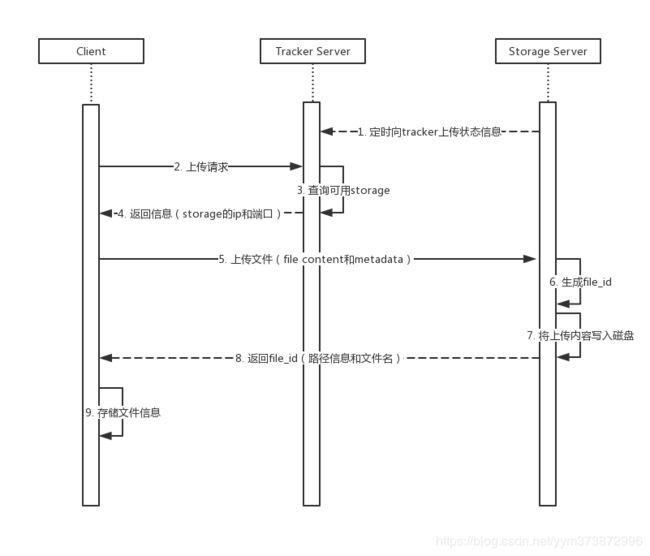
1、选择tracker server
当集群中不止一个tracker server时,由于tracker之间是完全对等的关系,客户端在upload文件时可以任意选择一个trakcer。
选择存储的group
当tracker接收到upload file的请求时,会为该文件分配一个可以存储该文件的group,支持如下选择group的规则:
- 1、Round robin,所有的group间轮询
- 2、Specified group,指定某一个确定的group
- 3、Load balance,剩余存储空间多多group优先
2、选择storage server
当选定group后,tracker会在group内选择一个storage server给客户端,支持如下选择storage的规则:
- 1、Round robin,在group内的所有storage间轮询
- 2、First server ordered by ip,按ip排序
- 3、First server ordered by priority,按优先级排序(优先级在storage上配置)
3、选择storage path
当分配好storage server后,客户端将向storage发送写文件请求,storage将会为文件分配一个数据存储目录,支持如下规则:
- 1、Round robin,多个存储目录间轮询
- 2、剩余存储空间最多的优先
4、生成文件名
选定存储目录之后,storage会为文件生一个文件名,由storage server ip、文件创建时间、文件大小、文件校验码和一个随机数生成。
选择两级目录,每个存储目录下有两级256*256的子目录,storage会按文件名进行两次hash(猜测),路由到其中一个子目录,然后将文件存储到该子目录下。
5、生成文件索引
当文件存储到某个子目录后,即认为该文件存储成功,接下来会为该文件生成一个文件索引,即Fileid。Fileid由group、存储目录、两级子目录、文件名、文件后缀名(由客户端指定,主要用于区分文件类型)拼接而成。
2.2 下载机制
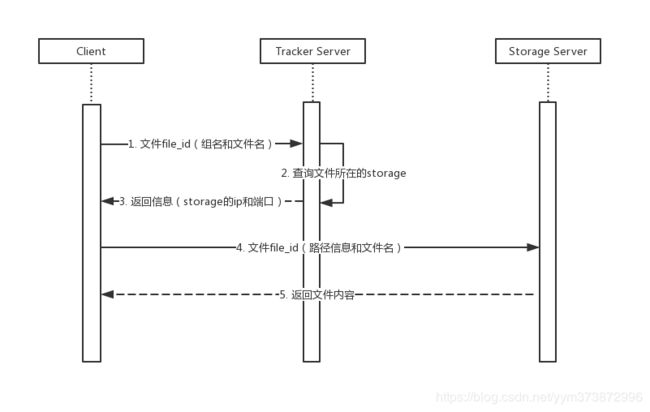
客户端带上文件名信息请求Tracker服务获取到存储服务器的ip地址和端口,然后客户端根据返回的IP地址和端口号请求下载文件,存储服务器接收到请求后返回文件给客户端。
3. 文件索引解析
文件索引示例:
group1/M00/00/0C/wKjRbExx2K0AAAAAAAANiSQUgyg37275.h
“group1"为组名,”/M00/00/0C/"为磁盘和目录,"wKjRbExx2K0AAAAAAAANiSQUgyg37275.h"为文件名及后缀。
其中文件名由源头storage server ip、创建时的时间戳、文件大小、文件校验码和一个随机数进行hash计算后生成,最后基于base64进行文本编码,转换为可打印的字符。
4. 文件同步机制
storage server采用binlog文件记录文件上传、删除等更新操作。binlog不记录文件内容,只记录文件名等元数据信息。
storage server中由专门的线程根据binlog进行文件同步。为了最大程度地避免相互影响以及出于系统简洁性考虑,storage server对组内除自己以外的每台服务器都会启动一个线程来进行文件同步。文件同步采用增量同步方式,系统记录已同步的位置(binlog文件偏移量)到标识文件中。标识文件名格式:{dest storage IP}_{port}.mark
文件同步只在同组内的storage server之间进行,采用push方式,即源头服务器同步给目标服务器。只有源头数据才需要同步,备份数据并不需要再次同步,否则就构成环路了。
新增加一台storage server时,由已有的一台storage server将已有的所有数据(包括源头数据和备份数据)同步给该新增服务器。
客户端将一个文件上传到一台storage server后,文件上传工作就结束了。由storage server根据binlog中的上传记录将这个文件同步到同组的其他storage server。这样的文件同步方式是异步方式,异步方式带来了文件同步延迟的问题。新上传文件后,在尚未被同步过去的Storage server上访问该文件,会出现找不到文件的现象。
四、优劣分析
1. 优点
- 系统无需支持POSIX(可移植操作系统),降低了系统的复杂度,处理效率更高
- 支持在线扩容机制,增强系统的可扩展性
- 实现了软RAID,增强系统的并发处理能力及数据容错恢复能力
- 支持主从文件,支持自定义扩展名
- 支持多台备用Tracker,增强系统的可用性
- 支持Nginx和Apache扩展,可提供http下载
什么是主从文件?
主从文件是指文件ID有关联的文件,一个主文件可以对应多个从文件。
主文件ID = 主文件名 + 主文件扩展名
从文件ID = 主文件名 + 从文件后缀名 + 从文件扩展名
使用主从文件的一个典型例子:以图片为例,主文件为原始图片,从文件为该图片的一张或多张缩略图。
FastDFS中的主从文件只是在文件ID上有联系。FastDFS server端没有记录主从文件对应关系,因此删除主文件,FastDFS不会自动删除从文件。
删除主文件后,从文件的级联删除,需要由应用端来实现。
主文件及其从文件均存放到同一个group中。
主从文件的生成顺序:
1)先上传主文件(如原文件),得到主文件ID
2)然后上传从文件(如缩略图),指定主文件ID和从文件后缀名(当然还可以同时指定从文件扩展名),得到从文件ID
2. 缺点
- 不支持断点续传,对大文件将是噩梦(FastDFS不适合大文件存储)
- 不支持POSIX通用接口访问,通用性较低
- 同步机制不支持文件正确性校验,降低了系统的可用性,对跨公网的文件同步,存在较大延迟,需要应用做相应的容错策略
- 通过API下载,存在单点的性能瓶颈
五、产生的实际问题与当前存在的解决方案
1. 文件同步延迟
文件同步方式是异步方式,新上传文件后,在尚未被同步过去的storage server上访问该文件,会出现找不到文件的现象。
解决方案:
需要说明的是,一个组包含的storage server不是通过配置文件设定的,而是通过tracker server获取到的。客户端和storage server主动连接tracker server。storage server主动向tracker server报告其状态信息,包括磁盘剩余空间、文件同步状况、文件上传下载次数等统计信息。storage server会连接集群中所有的tracker server,向他们报告自己的状态。storage server启动一个单独的线程来完成对一台tracker server的连接和定时报告。另外,每台storage server都会定时向tracker server报告它向同组的其他storage server同步到的文件时间戳。当tracker server收到一台storage server的文件同步报告后,它会依次找出该组内各个storage server被同步到的文件时间戳最小值,作为storage的一个属性记录到内存中。根据上述情况FastDFS提供下面简单解决方案:
1、和文件更新一样,优先选择源storage server下载文件即可。这可以在tracker server的配置文件中设置,对应的参数名为download_server。
2、选择storage server的方法是轮流选择(round-robin)。当client询问tracker server有哪些storage server可以下载指定文件时,tracker server返回满足如下四个条件之一的storage server:
- 该文件上传到的源storage server,文件直接上传到该服务器上的;
- 文件创建时间戳 < storage server被同步到的文件时间戳,这意味着当前文件已经被同步过来了;
- 文件创建时间戳 = storage server被同步到的文件时间戳,且(当前时间 - 文件创建时间戳) > 一个文件同步完成需要的最大时间(如5分钟);
- (当前时间 - 文件创建时间戳) > 文件同步延迟阈值,比如我们把阈值设置为1天,表示文件同步在一天内肯定可以完成。
2. 数据安全性
- 写一份即成功:从源storage写完文件至同步到组内其他storage的时间窗口内,一旦源storage出现故障,就可能导致用户数据丢失,而数据的丢失对存储系统来说通常是不可接受的。
- 缺乏自动化恢复机制:当storage的某块磁盘故障时,只能换存磁盘,然后手动恢复数据;由于按机器备份,似乎也不可能有自动化恢复机制,除非有预先准备好的热备磁盘,缺乏自动化恢复机制会增加系统运维工作。
- 数据恢复效率低:恢复数据时,只能从group内其他的storage读取,同时由于小文件的访问效率本身较低,按文件恢复的效率也会很低,低的恢复效率也就意味着数据处于不安全状态的时间更长。
- 缺乏多机房容灾支持:目前要做多机房容灾,只能额外使用工具来将数据同步到备份的集群,无自动化机制。
3. 存储空间利用率
单机存储的文件数受限于inode数量
每个文件对应一个storage本地文件系统的文件,平均每个文件会存在block_size/2的存储空间浪费。
文件合并存储能有效解决上述两个问题,但由于合并存储没有空间回收机制,删除文件的空间不保证一定能复用,也存在空间浪费的问题。
4. 负载均衡
group机制本身可用来做负载均衡,但这只是一种静态的负载均衡机制,需要预先知道应用的访问特性;同时group机制也导致不可能在group之间迁移数据来做动态负载均衡。
六、参考文献
FastDFS的介绍 [https://www.cnblogs.com/shenxm/p/8459292.html]
分布式文件系统FastDFS详解 [https://www.cnblogs.com/ityouknow/p/8240976.html]
FastDFS特性及问题思考 [https://www.cnblogs.com/jym-sunshine/p/6397705.html]
FastDFS同步问题讨论 [https://www.cnblogs.com/snake-hand/p/3161528.html]