58同城离线计算平台设计与实践(大数据进阶)
编者荐语:
58离线计算平台基于 Hadoop 生态体系打造,单集群4000+台服务器,数百 PB 存储,日40万计算任务,面临挑战极大。本次分享将聚焦大数据平台离线计算和大家一起系统的探讨58在离线计算平台建设实践的思路、方案和问题解决之道。
分享嘉宾:余意 58同城 高级架构师
编辑整理:史士博
内容来源:58大数据系列直播
出品平台:DataFun
导读:58离线计算平台基于 Hadoop 生态体系打造,单集群4000+台服务器,数百 PB 存储,日40万计算任务,面临挑战极大。58大数据平台的定位主要是服务数据业务开发人员,提高数据开发效率,提供便捷的开发分析流程,有效支持数据仓库及数据应用建设。通常大数据平台通用基础能力包括:数据存储、实时计算、离线计算、数据查询分析,本次分享将聚焦大数据平台离线计算和大家一起系统的探讨58在离线计算平台建设实践的思路、方案和问题解决之道。
本文主要内容包括:
-
58在集群快速增长的过程中遇到的问题以及解决之道;
-
58大数据集群跨机房迁移的相关工作,如何在5个月时间快速完成3000台集群服务的迁移工作。
▌数据平台部简介

数据平台部是负责58统一大数据基础平台能力建设。平台负责的工作主要包括以下几部分:
-
数据接入:文本的收集,我们采用 flume 接入,然后用 kafka 做消息缓冲,我们基于 kafka client 打造了一个实时分发平台,可以很方便的把 kafka 的中间数据打到后端的各种存储系统上。
-
离线计算:我们主要基于 Hadoop 生态的框架做了二次定制开发。包括 HDFS、YARN、MR、SPARK。
-
实时计算:目前主要是基于 Flink 打造了一个一栈式的流式计算开发平台 Wstream。
-
多维分析:我们主要提供两组多维分析的解决方案。离线的使用 Kylin,实时的使用 Druid。
-
数据库:在数据库的这个场景,我们主要还是基于 HBase 的这个技术体系来打造了出来,除了 HBase 提供海量的 K-V 存储意外,我们也基于 HBase 之上提供 OpenTSDB 的时序存储、JanusGraph 图存储。
我们综合以上技术框架支撑了公司上层的业务:如商业、房产、招聘等核心业务。 此外,整个数据平台部打造了统一的运营管理平台,各个用户在整个数据平台上 ( 包括离线平台、实时平台等 ) 使用的是同一套主账号在管理平台上做数据方面的管理,包括:元数据管理、成本预算、数据自助治理、以及运营监控的一些细节。
在上图的右半部分我们简单的介绍了几个数据平台的指标。Flume 每天的日志采集量 240T,Haddop 单集群服务器台数4000+,Flink 每天进行超过6000亿次的计算,Druid 已经构建超过 600 亿条实时数据索引。
▌Hadoop 平台建设优化
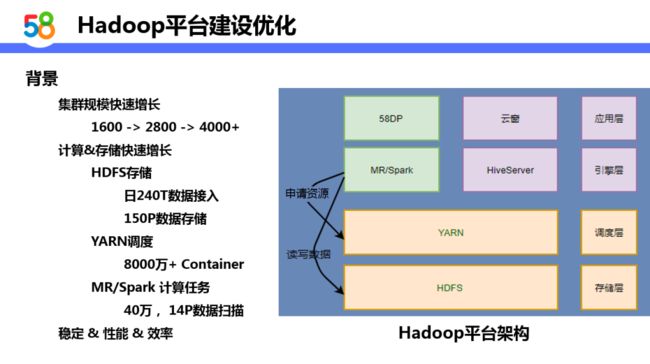
我们的 Hadoop 集群从17年的1600台->18年的2800台->19年的4000台。可以看到集群的增长速度还是非常迅速的。在整个集群中:HDFS 存储数据150P+,YARN 每天调度超过8000万的 Container, MR/Spark 每日计算任务总数40万+、中间处理数据量超过 14P。在此基础上集群规模也在不断增长,集群稳定性能和效率对我们来说是一个比较大的挑战。下面我将给大家介绍在上述背景下,我们关于 Hadoop 平台建设以及优化的具体实践。
我们将从以下几个方面来做介绍:
1. 规模扩展

首先,对于大规模 HDFS 集群可扩展性这一块,我们采用的解决方案是 HDFS Fedoration。HDFS 最大的痛点的话是 NameNode 单点瓶颈的问题,这其中包括内存的问题以及小文件的问题。通过 Fedoration 使用多个 NN 来缓解元数据内存的压力以及均衡元数据访问的 RPC。
其次,通过 ViewFileSystem 对业务做统一。ViewFileSystem 有一个好处是它在客户端实现,这样它的稳定性和性能就有保证。当然,社区原生版本有一些缺点,就是不支持跨 mount 点 mv,这一点我们对它做了修复。另外,它的维护成本比较高,在58我们是通过控制用户规模来保证低维护的成本,具体如下:通过58数据平台运营管理一套主账号体系,我们给每个业务一个大的根目录,在第一层子目录下只分配四个目录,通过这种方式来管控目录的数量来保证低成本维护,同时这样做在发生业务变更时影响也非常小。
2. 稳定性杀手

虽然有 Fedoration 机制来均衡各个 NN 的压力,但是对于单个 NN 压力仍然非常大,各种问题时刻在挑战 HDFS 稳定性,比如:NN RPC 爆炸,我们线上最大的 NS 有15亿的 RPC 调用,4000+ 并发连接请求,如此高的连接请求对业务稳定影响很大。针对这个问题,我们使用"拆解+优化"的两种手段相结合的方式来改进。拆解就是说我们把一些大的访问,能不能拆解到不同的集群上,或者我们能不能做些控制,具体案例如下:
-
Hive Scratch:我们经过分析 Hive Scratch 的临时目录在 RPC 调用占比中达到 20%,对于 Hive Scratch 实际上每个业务不需要集中到一个 NS 上,我们把它均衡到多个 NS 上。
-
Yarn 日志聚合:Yarn 的日志聚合主要是给业务查看一些日志,实际上他没有必要那个聚合到 HDFS 上,只需要访问本地就可以了。
-
ResourceLocalize:同样把它均衡到各个 NS 上。
经过这种拆解就可以降低单个 NS 的压力。

对于 RPC 的性能瓶颈还有很多,本文主要介绍以下几种典型案例:
-
DN BlockReport:即 DataNode 全量块汇报,目前 DN 都是大存储的机器,存在单机 60T 数据、100w+ Block,这种情况下单机做一次 BlockReport 对性能的影响非常大。针对这种情况,我们的改进措施是降低汇报频率,从1小时/次 降低到 10小时/次 ;
-
DN IBR ( Incremental Block Report ):即 DN 的增量块汇报。在集群比较繁忙的时候,增量块汇报的规模也是比较庞大的,在这块的优化中参考社区新版本的 issue,就是我们使用批量块汇报的方式来降低增量块汇报的频率;
-
DN Liveless:即 DN 假死。有时候 NN 或者 DN 比较繁忙的时候会出现心跳超时的情况,这样会导致 NN 会对心跳超时的情况做冗余操作,单个 NN 的块数量非常大,做冗余的话对 RPC 的性能压力也是很大的。这里的做法是使用独立心跳,避免"假死"导致百万 block 冗余。
核心链路优化:我们对线上出现的一些问题对核心链路做的优化,主要思想是提高并行度,比如:
-
PermissionCheck ---减少持锁时间
-
QuotaManager ---避免递归,提高效率
-
ReplicationMonitor ---增加吞吐
-
choseTarget ---提高匹配效率
3. NS 间负载均衡

对于 NS 间负载均衡,提供了 FastCopy 工具来做数据的拷贝,因为 Fedoration 已经做到了很好的数据本地化,没有必要去做跨集群拷贝,通过 FastCopy HardLink 的机制可以直接将 block 指向到目标 block。当然这种方案在做 NS 之间元数据拷贝的时候,还是有一些迁移的成本,这时候就需要业务来做一些配合。
4. GC 调优

在 GC 这块,NN 线上最大堆内存达到了 230G,GC 调优我们使用的 CMS GC,这是一个比较成熟的调优方式。主要通过下述手段:
-
降低 Young GC 的频率和时间:通过一些参数来减少它的频率和参数
-
CMS GC initialmark & Remark
-
避免 Concurrent mode failure 和 Promotion failure ,避免它做 Full GC
5. 慢节点问题

慢节点问题是我们遇到典型问题之一,主要有三个场景:
慢节点问题一:DN IO Util 100%
我们线上集群在业务快速扩增的过程中,曾经出现过大量 DN IO Util 100%的现象,而且 DN IO Util 100%的持续时间很有可能会超过二十分钟甚至半个小时,这会导致业务读取数据非常缓慢,甚至超时、失败。对我们核心业务的影响是非常大的,比如对于某个有很多业务依赖的上游业务,如果这个上游业务的延时比较长,那么所有的下游业务的延时将会不可控。针对这个问题,我们分析主要是由以下三个操作会导致这个问题的出现并做了改进,改进整体效果良好,改进后计算任务的执行时间提速了 25%。
-
第一:10min 间隔 CheckDir 的操作,改进措施:不检查所有,只检查父目录,这样会做到基本无 IO 消耗。
-
第二:10min间隔 du 操作,改进措施:改成 df 实现,改进后基本无 IO 消耗。由于 du 会扫描磁盘上的所有的块,是非常重的一个操作,事实上在这里我们不需要那么精确,使用 df 是完全可行的。
-
第三:6h 间隔 directoryScan 操作,改进措施:扫描限速 & 低峰执行,改进后 IO 控制在30%。做限速避免持续占用带宽,避免高峰期执行操作,58 的高峰基本在凌晨至早晨时间 0:00 -9:00,我们在这个时间段不做这个操作,放在空闲时间。

慢节点问题二:读数据
-
预读支持:对于大数据量下客户端读 DN 的比较慢的情况,hadoop 本身提供的预读方案是在随机访问情况下的优化,但是对于离线计算基本是顺序读的场景不能使用,我们对此做了扩展,对顺序读提供了预读支持。
-
千兆机器持续负载优化:在58异构情况非常严重,之前1000多台千兆机器,千兆机器会持续打满负载。针对这种情况我们使用社区关于 DataNode 快速重启的方案 ( HDFS-7928 ),基本可以在30S时间内重启 DN,这样我们通过快速重启 DN 的方式把客户端的请求分配到其他的节点上再还给他。
慢节点问题三:写 pipeline 无限重试
客户端写一个块的操作会在三个节点上都一个块,我们线上遇到的一个比较严重的问题:在写的过程中如果一个节点出现故障,会去不断的重试将集群中所有的几点重试一遍然后失败,这种情况社区也有对应 issue ( HDFS-9178 ),原因是在做 DN 的 pipeline 恢复的时候把异常的节点当成了正常的节点来做 pipeline 恢复的对象。
6. YARN建设优化

Yarn 调度的优化主要是两个方面:一个是稳定性,另一个效率方面。
稳定性:
① 服务稳定性:
服务稳定性主要针对于系统的核心模块,下面介绍下线上易出现的核心问题:
-
YARN-4741:升级过程中大规模的 NM 重启的时候容易出现千万级的冗余事件,这样会造成 NM OOM 从而集群会挂掉,因此需要对冗余事件过滤。
-
异常 APP 过滤:在做 RM 切换的时候遇到的 App 异常状态,导致 RM 直接挂掉
-
DNS:DNS 服务挂掉导致集群宕机,主要是通过 cache 机制来解决,包括在集群层面、硬件层面做 cache。
② 计算稳定性:
-
业务方面:提供标签调度隔离,把业务做物理隔离保证重点业务的执行
-
Quene & APP 方面:提供优先级的支持,保证高优先级的任务先拿到资源
-
节点层面:container 做 Cgroup 的隔离,保证 container 的稳定性
③ 过载保护:
-
在集群层面有过载保护措施,比如:最大用户数,最大 APP 数,最大 container 数等。
YARN 调度吞吐保证:
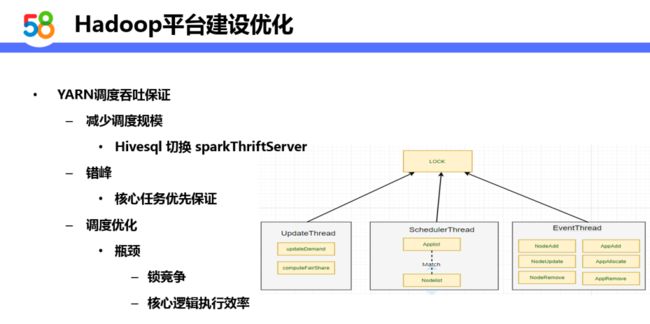
-
减少调度规模怕从而减轻压力:Hivesql 切换 sparkThriftServer,因为 sparkThriftServer 是一个常驻的服务,在初始化时申请下资源后基本不会再去向 YARN 申请资源,切换后可以减少吞吐。
-
错峰:核心任务优先保证,在空闲阶段再跑一些非核心业务。
-
调度优化:YARN 调度主要有三个线程,三个线程共享一把锁来做各自的锁逻辑,所以一个优化思路就是解决这个锁竞争的问题,另一个思路是对核心的调度逻辑做优化。
持锁时间优化:

通过 Profiling 发现调度进程在排序操作的过程种需要消耗90%的 CPU 时间,而且在做排序的时候基本上只是读的操作,没有必要去拿锁。另外调度的三个线程没有必要都用排他锁,我们可以做一个锁降解,对于更新线程 updateThread 用读锁就可以了,另外我们需要做一个加锁顺序的保证来避免死锁的情况。
核心计算逻辑 Profiling:
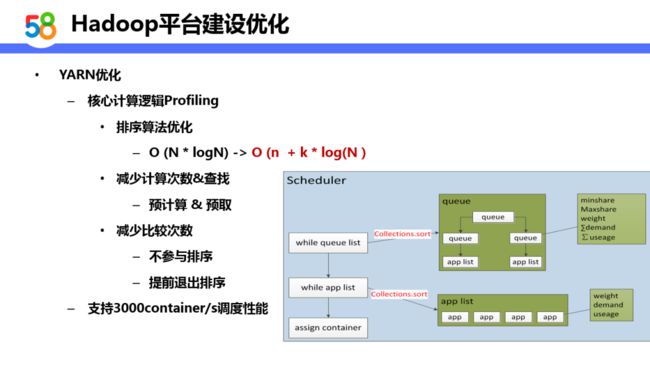
核心逻辑 Profiling 的几种思路:
-
一是降低时间复杂度,社区使用的归并排序的思想,复杂度为 O(N * logN),实际上调度的时候我们只需要找到一个适配的节点,通过优化可以将复杂度降为 O(n + k * logN);
-
二是通过空间换时间的思想,比如通过预计算、预取数来减少计算次数;
-
三是在做排序的时候对于一些已经不需要排序的,不需要资源的地方做优化。
整体优化完成以后调度系统提高到 3000 container/s,基本上满足了我们的需求。
7. 计算引擎优化

接下来我们来介绍下关于计算引擎方面的优化,主要是下面几个方面:
云窗 Hive –> SparkSql:
云窗是 58 使用非常广泛的 Sql 查询平台,主要用在即席查询场景。之前一直存在一个痛点问题:查询引擎只有 Hive,因此查询效率很受局限。17年底的时候我们开始将查询引擎由 Hive 转向 SparkSql,在做即席查询引擎转换升级的时候我们做了一些调研,对比了 Impala,Presto 等等,结合 58 现状我们最终使用 SparkSql 来替换了 Hive。当时 Spark 最新版本为 Spark 2.2,基于稳定性考虑没有激进的选择使用最新的版本而是选择了比较稳定的版本 Spark 2.1.2。另外支持 SparkSql 引擎,也对 SparkThriftServer、Zeppelin 等解决方案做了调研,综合以下几个方面我们选择了 SparkThriftServer:
一是由于云窗 Hive 主要是和前端 JDBC 的使用方式,这时候用 SparkThriftServer 改造起来就非常简单;
二是需要在应用性上做些保证,比如业务可以实时查询执行进度,可以组取消等相关操作;
三是云窗 Hive 是提供给多个用户使用需要,所以需要支持多租户。
SparkThriftServer 多租户:
多租户的问题主要在权限这一块,需要把各个业务的权限打通,这样各个业务在做查询的时候做到安全隔离;此外在计算方面,由于 SparkThriftServer 业务使用公共资源,也需要把重点业务的资源做隔离。
SparkSql 兼容 Hive 的实现:

我们需要保证云窗 Hive 用户的查询和 SparkSql 的查询做到一致性。主要用到下面四个问题:UDF 支持问题,语法兼容性问题,数据质量问题,参数兼容问题。这块的解决方案比较简单,当时是把云窗 Hive 的所有语句迁移到 SparkSql 来做测试,根据测试的结果来修复相关的问题,最后修复了50+个 issue 把成功率提高到95%以上。
SparkThriftServer 平台稳定性建设:

SparkThriftServer 平台稳定性建设也做了比较多的工作,重点说以下几点:
-
Spark 自身稳定性问题种 Spark Driver 内存管理的问题
-
保障服务的稳定性方面,通过 HA 机制提供多台 SparkThriftServer 支持,另外在云窗上层提供重试策略,这样在下游出现问题但不影响上游情况下通过上游重试来提高运行成功率
-
通过一些任务管控做集群的过载保护
-
降低集群压力:Spark 对集群的压力还是非常大的,特别是在不正确使用的情况下,我们需要对它对 HDFS 的压力做一些管控,比如输入输出这一块
SparkSql 上线运行后发现的一些问题:

比如在云窗上 Hive 和 Spark 默认情况下使用了同样的配置,在云窗上用户不会关心使用的是 Hive 还是 SparkSql,这样存在一个问题就是很难对业务做一个针对性的调优,这里我们做了一些优化,优化过程中主要参考了 Intel SparkAE 的一些特性。
-
最优 Shuffle Partition:Partition 数量的指定在各个阶段都是一样的,事实上很难达到一个最优的效果;
-
Join 的策略:原生的 join 策略是根据初始数据来做 join 策略,我们可以通过一些中间结果来做一些策略的改变;
-
数据倾斜:在做 Sql 查询中我们遇到的比较多的情况就是数据倾斜,我们也是做了自动的数据倾斜的优化。做完这些优化后,线上的任务基本上都有2-3倍的提升,效果还是非常明显的。
8. WSSM 平台建设
对于大规模的集群,运营能力还是很重要的,否则集群开发人员会花费大量时间来做运维。运营主要在存储和计算。
海量存储一站式运营管理:

存储运营有很多要做,比如目录配额管控,权限控制,告警机制,成本的优化等。我们主要是通过 FSImage + EditLog 的方式拿到需要分析的数据存储信息,集群运营者分析获取到的信息然后做相应的存储优化策略。使用 FSImage + EditLog 一个好处就是对 NN 无影响。我们集群运营每天可以对4000万+目录做冷热、增长等方面的分析;运营用户可以根据数据目录的冷热情况自定义生命周期等策略来管理数据目录,通过目录增长信息用户可以知道数据的增长情况是否正常。我们也提供了自动化目录压缩的接入,业务想做数据治理的化可以一键接入;自动化压缩有以下几个特点:冷数据使用 GZIP 压缩,热数据使用 LZO 压缩;提供数据完整性校验机制。数据压缩带来效果还是比较明显的,以19年实践为例:通过压缩数据累计节省了 100P+ 空间,相当于千台服务器的节省。
海量计算自主运营分析:

海量计算自助运营分析平台可以避免很多重复工作,减少资源的浪费,提高业务开发以及集群运维开发的工作效率。
我们是基于 LinkedIn 开源的大象医生 Dr-elephant 做的扩展改进,在改进过程中主要解决几个问题:
-
Dr-elephant 的扩展性问题,我们通过 AppList 派发到多台 Dr-elephant 来支持扩展性问题。
-
对 spark 的各个版本做了兼容性的实现,比如:Spark2.1,Spark2.3
-
Dr-elephant 原生启发式算法改进。改进后支持分析:MR 是否分配在慢节点上,container 的资源是否合理等。
下图是我们运营管理的界面,其中左半部分是存储方面,右半部分是计算方面的。

▌跨机房迁移
下面给大家介绍下数据平台部在19年下半年做的跨机房迁移这方面的事情。

迁移背景:
-
全量迁移:3000台机器,130P数据,40万计算任务
-
老机房资源紧张,无法扩容,业务持续增长
-
低成本迁移,控制时耗,Hadoop 机位半年内腾空
-
其它:跨机房带宽比较充裕 ( 2Tb ),延迟 2ms 左右 ( 机房内 0.1ms );离线 Hbase 集群混部,80台 RS,100+表
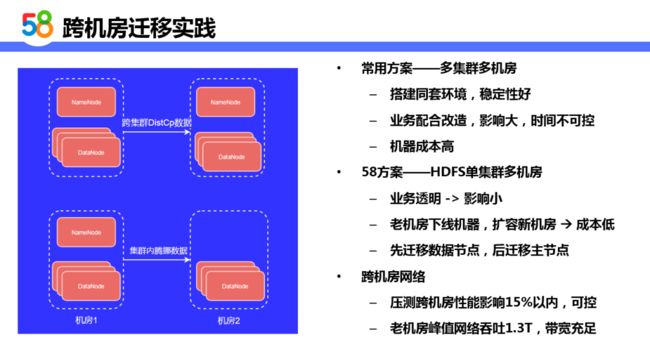
方案预研以及选型结果:
常用方案——多集群多机房
-
新机房搭建同套环境,稳定性好,改造少 ( 新版本特性可以直接使用 )
-
业务配合 ( 数据一致性验证等 ),影响大,时间不可控
-
机器成本高
58方案——HDFS 单集群多机房
-
业务透明 -> 影响小
-
老机房下线机器,扩容新机房 -> 成本低
-
先迁移数据节点,后迁移主节点
跨机房网络
-
压测跨机房性能影响15% 以内,网络延时较好,可控
-
老机房峰值网络吞吐 1.3T,带宽充足
下面介绍迁移具体方案和实践:
1. 单集群跨机房 HDFS 数据迁移

数据从老机房迁移到新机房主要用到了 HDFS 的 Decommision 特性。这里我们针对 decommision 存在的一些问题做了一些改进,改进后性能提升超过6倍,具体问题与方案如下:
不可指定机房:decommision 的数据目标节点是不确定的,如果直接使用 decommision 会产生较多的数据冗余,所以我们在数据路由上做了改进,让 decommision 可以支持指定机房,这样下线的时候就可以将数据直接 decommision 到新机房。
性能:decommision 本身性能较差吞吐量小且对 NameNode 的压力较大,在这里做了如下的改进:
-
dfs.namenode.replication.max-streams
-
降低 NN RPC 负载,充分利用 DN 机器带宽 ( HDFS-7411,HDFS-14854 )
稳定性:decommision 存在一些稳定性问题,比如:不能正常结束,这里我们参考社区 issue(HDFS-11847),做了 decommision 的监控工具,分析 decommision 不能结束的具体原因然后做针对性的处理。另外在 decommision 的执行过程中可能会出现块丢失问题,线上曾经出现丢失几百万个块,还好后来数据做了及时修复,此处参考 HDFS-11609。
此外,我们是在低峰期执行 decommision 以降低影响。为保证服务稳定下线速率保持在每天下线50台,基本在5个月的时间内完成集群迁移。
2. 网络

在实践过程中,我们发现网络急剧增长,最大到 1.8T 接近上限,非常危险了,针对这个问题我们做了如下分析。
-
第一,因为集群是异构的,集群中有大量千兆机器,在迁移过程中千兆机器在持续的下线,这样很多计算落在了万兆机器,从而增长了带宽;
-
第二,在迁移完成后,我们会千兆机器的网卡升级到万兆,因为网络的性能提升,把带宽提升上去了。
在网络降低带宽方面的优化策略:
-
跨机房读写策略,整体策略完成后跨机房带宽降低50%,具体如下:首先需要支持机房网络拓扑结构,支持本机房写。另外考虑到老机房很少有存储的情况,这里做动态配置策略:默认是本机房写,通过修改配置可以随机写或者指定机房写。在读方面优先级顺序由高到低为: 同节点 -> 同机架 -> 同机房 –> 跨机房
-
控制大业务带宽,主要是以下两点:一是 Flume sink HDFS 实现压缩机制,峰值带宽 200Gb 降低到 40Gb 左右;二是分析计算依赖,对计算迁移控制跨机房计算的规模。
-
其他管控:比如硬件层面保证控制流优先,这样即使带宽打满也不会发生心跳信息无法传递导致集群崩溃
3. 新机房磁盘倾斜
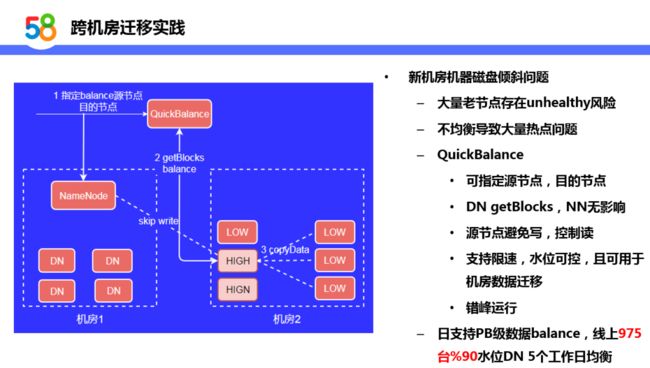
在迁移过程中,遇到第二个比较大问题:新机房磁盘倾斜比较严重,大量机器存储超过了95%,此时节点出现 unhealthy 情况。由于机器在计算方面做了标签隔离,如果存储占满对重要业务运行稳定性影响非常大,需要有一个快速均衡方案来均衡高负载节点。这里我们使用 HDFS Balance 作为一个解决方案,同时优化了 HDFS Balance 的几个痛点问题:
-
支持可指定源节点,目的节点
-
直接从 DN 获取 Blocks 信息,减轻 NN 压力同时提高并发
-
源节点避免写,控制读
-
支持限速,水位可控,且可用于
-
机房数据迁移错峰运行
通过以上方案,日支持 PB 级数据 balance,线上975台90%水位 DN5 个工作日完成均衡。
4. 计算迁移

计算服务更像是一个无状态的服务,也不需要做单集群跨机房,做起来就比较轻松。只需要在新机房部署一个新的 YARN 集群就可以,也可以保证计算任务不会跨机房。在整个迁移过程以队列为粒度,根据队列映射机房,在迁移初期给任务更富裕的资源以保证任务运行更加稳定。迁移期间会做一些灰度检验,此时需要业务配合,同时也会对迁移前后任务的运行情况做分析对比以确保迁移不影响业务的正确性。

整个迁移过程如上图所示,期间由业务与平台相互协作。业务主要评估迁移前后的差异,包括性能、成功率等。其他任务都是由平台来做,分为离线、实时、Hbase 等部分,其中离线部分流程为:
新机房资源准备,业务梳理 -> 测试新机房性能 –> 业务一队列粒度切换新机房 ->回收老机房资源 -> 搬迁至新机房扩容
实时任务迁移参考离线部分,大同小异;Hbase 集群迁移请参考另一篇关于58 大数据平台分享第三期:Hbase 专场。
整体迁移过程:先迁移计算和存储再迁移 HDFS 等核心服务,核心服务通过域名化变更来迁移,这里在源生 Hadoop 做了改进增加了对异常捕获的处理。
▌后续规划
后续规划主要对两个方面,一个 Hadoop3.X,一个是云融合。
①Hadoop3.X
Hadoop 现在版本是在 CDH-Hadoop 2.6 做的定制,后续计算对 Hadoop 升级到 3.X。主要对 Hadoop3.X 两个特性比较看好:
-
第一:对 EC ( erasure coding 纠删码 ) 的支持,可以节省很大的存储空间
-
第二:对象存储 ( ozone )
② 云融合探索
目前公司私有云主要支持在线的业务,大数据平台主要支持离线的业务。在线业务一般晚上资源比较空闲,离线业务晚上资源比较繁忙,因此考虑是否可以错峰相互借用资源以降低成本。
▌精选问题的回答
1. 批流统一怎么做?
答:目前在58 已经在将 Storm 迁移到了 Flink,这个具体方案的文章已经发布在 58 技术公众号上,感兴趣的同学可以去公众号查看。另外 Spark Streaming 我们也建议业务可以迁移到 Flink 上,根据部分迁移业务来看,资源的使用有比较大的提升,而且在流方面整理来看 Flink 比 SparkStreaming 更有优势,无论是功能方面还是架构方面,这些都有大量的文章介绍。
我们已经基于 Flink 开发了一栈式实时开发平台 Wstream,支持使用 Sql 开发实时程序,支持 DDL、Join,关于这些会在58大数据平台分享第二期做具体介绍。
2. OLAP 选型怎么做?
答:在58 OLAP 场景目前是使用 Kylin 来支持离线的业务,比如 BI 报表,Kylin 的话建议维度不要超过50维度,超过维度支持的会不友好;另外 Druid 来支持实时的场景,比如广告效果的评估,用户行为分析等。
Kylin 和 Druid 都是预计算的思想,因此查询场景比较受限,而且对其他组件依赖较重导致维护成本较高,目前业界也有一些新的优秀解决方案,比如 ClickHouse 这些没有对其他组件的依赖相对来说比较轻量。这些组件性能上基本上都是采用列式存储的思想,提高硬件使用效率等。
Kylin、Druid 目前从使用上来看是比较成熟的 ( 包括对 Sql 语法的支持等 ),58数据平台目前也在做 OLAP 相关的调研,争取尽早落地,届时再与大家分享。