HashMap的扩容机制---resize() & 死循环的问题
1.8 与1.7 变化较大,
http://www.cnblogs.com/RGogoing/p/5285361.html
学习内容:
1.HashMap
当初学Java的时候只是知道HashMap
那么这一章也就仅仅针对这个问题来说一下,至于如何使用HashMap这个东西,也就不进行介绍了.在面对这个问题之前,我们先看一下HashMap
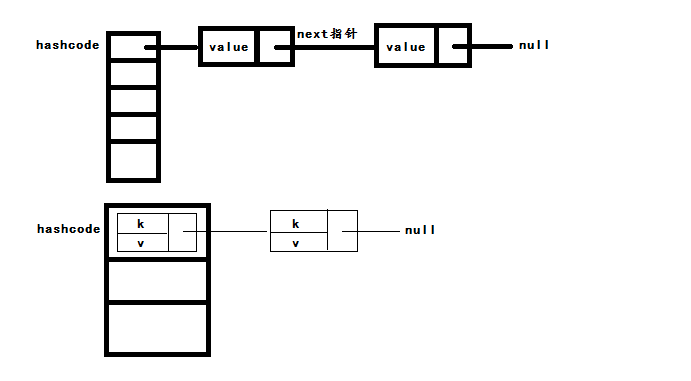
这就是二者的数据结构,上面那个是C语言的数据结构,也就是哈希表,下面的则是Java中HashMap
简单介绍完毕之后,就说一下正题吧.其实在单线程的情况下,HashMap
resize()函数..

void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
boolean oldAltHashing = useAltHashing;
useAltHashing |= sun.misc.VM.isBooted() &&
(newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean rehash = oldAltHashing ^ useAltHashing;
transfer(newTable, rehash); //transfer函数的调用
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
上面说过,但HashMap
关键问题是transfer函数的调用过程..我们来看一下transfer的源码..
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry e : table) { //这里才是问题出现的关键..
while(null != e) {
Entry next = e.next; //寻找到下一个节点..
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity); //重新获取hashcode
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
transfer函数其实是在并发情况下导致死循环的因素..因为这里涉及到了指针的移动的过程..transfer的源码一开始我并有完全的看懂,主要还是newTable[i]=e的这个过程有点让人难理解..其实这个过程是一个非常简单的过程..我们来看一下下面这张图片..
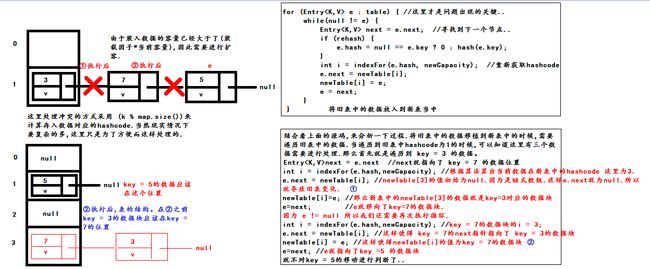
这是在单线程的正常情况下,当HashMap
这样在单线程的情况下就完成了扩容的操作.其中不会出现其他的问题..但是如果是在并发的情况下就不一样了.并发的情况出现问题会有很多种情况.这里我简单的说明俩种情况.我们来看图。

这张图可能有点小,大家可以通过查看图像来放大,就能够看清晰内容了...
这张图说明了两种死循环的情况.第一种相对而严还是很容易理解的.第二种可能有点费劲..但是有一点我们需要记住,图中t1和t2拿到的是同一个内存单元对应的数据块.而不是t1拿到了一个独立的数据块,t2拿到了一个独立的数据块..这是不对的..之所以发生系循环的原因就是因为拿到的数据块是同一个内存单元对应的数据块.这点我们需要注意..正是因为在高并发的情况下线程的工作方式是不确定的,我们无法预知线程的工作情况.因此在高并发的情况下,我们不要使用多线程对HashMap
可能看起来很复杂,但是只要去思考,还是感觉蛮简单的,我这只是针对两个线程来分析了一下死循环的情况,当然发生死循环的问题不仅仅只是这两种方式,方式可能会有很多,我这里只是针对了两个类型进行了分析,目的是方便大家理解.发生死循环的方式绝不仅仅只是这两种情况.至于其他的情况,大家如果愿意去了解,可以自己再去研磨研磨其他的方式.按照这种思路分析,还是能研磨出来的.并且这还是两个线程,如果数据量非常大,线程的使用还比较多,那么就更容易发生死循环的现象.因此这就是导致HashMap
虽然我们都知道当多线程对Map进行操作的时候,我们只需要使用ConcurrentHashMap
http://blog.csdn.net/aichuanwendang/article/details/53317351
虽然在hashmap的原理里面有这段,但是这个单独拿出来讲rehash或者resize()也是极好的。
什么时候扩容:当向容器添加元素的时候,会判断当前容器的元素个数,如果大于等于阈值---即当前数组的长度乘以加载因子的值的时候,就要自动扩容啦。
扩容(resize)就是重新计算容量,向HashMap对象里不停的添加元素,而HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。当然Java里的数组是无法自动扩容的,方法是使用一个新的数组代替已有的容量小的数组,就像我们用一个小桶装水,如果想装更多的水,就得换大水桶。
我们分析下resize的源码,鉴于JDK1.8融入了红黑树,较复杂,为了便于理解我们仍然使用JDK1.7的代码,好理解一些,本质上区别不大,具体区别后文再说。
- void resize(int newCapacity) { //传入新的容量
- Entry[] oldTable = table; //引用扩容前的Entry数组
- int oldCapacity = oldTable.length;
- if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了
- threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
- return;
- }
- Entry[] newTable = new Entry[newCapacity]; //初始化一个新的Entry数组
- transfer(newTable); //!!将数据转移到新的Entry数组里
- table = newTable; //HashMap的table属性引用新的Entry数组
- threshold = (int) (newCapacity * loadFactor);//修改阈值
- }
这里就是使用一个容量更大的数组来代替已有的容量小的数组,transfer()方法将原有Entry数组的元素拷贝到新的Entry数组里。
- void transfer(Entry[] newTable) {
- Entry[] src = table; //src引用了旧的Entry数组
- int newCapacity = newTable.length;
- for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组
- Entry
- if (e != null) {
- src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)
- do {
- Entry
- int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置
- e.next = newTable[i]; //标记[1]
- newTable[i] = e; //将元素放在数组上
- e = next; //访问下一个Entry链上的元素
- } while (e != null);
- }
- }
- }
- static int indexFor(int h, int length) {
- return h & (length - 1);
- }
文章中间部分:四、存储实现;详细解释了为什么indexFor方法中要h & (length-1)
newTable[i]的引用赋给了e.next,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置;这样先放在一个索引上的元素终会被放到Entry链的尾部(如果发生了hash冲突的话),这一点和Jdk1.8有区别,下文详解。在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
下面举个例子说明下扩容过程。
这句话是重点----hash(){return key % table.length;}方法,就是翻译下面的一行解释:
假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。
其中的哈希桶数组table的size=2, 所以key = 3、7、5,put顺序依次为 5、7、3。在mod 2以后都冲突在table[1]这里了。这里假设负载因子 loadFactor=1,即当键值对的实际大小size 大于 table的实际大小时进行扩容。接下来的三个步骤是哈希桶数组 resize成4,然后所有的Node重新rehash的过程。
下面我们讲解下JDK1.8做了哪些优化。经过观测可以发现,我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,
经过rehash之后,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。对应的就是下方的resize的注释。
[java] view plain copy
- /**
- * Initializes or doubles table size. If null, allocates in
- * accord with initial capacity target held in field threshold.
- * Otherwise, because we are using power-of-two expansion, the
- * elements from each bin must either stay at same index, or move
- * with a power of two offset in the new table.
- *
- * @return the table
- */
- final Node
看下图可以明白这句话的意思,n为table的长度,图(a)表示扩容前的key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,其中hash1是key1对应的哈希与高位运算结果。
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”,可以看看下图为16扩充为32的resize示意图:
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点。有一点注意区别,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但是从上图可以看出,JDK1.8不会倒置。有兴趣的同学可以研究下JDK1.8的resize源码,写的很赞,如下:
final Node[] resize() {
Node[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node[] newTab = (Node[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
else { // preserve order
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}