【文献阅读】SAAA——堆叠多层注意力的VQA网络(T. Do等人,ArXiv,2017,有代码)
一、背景
文章题目:《Show, Ask,Attend, and Answer: A Strong Baseline For Visual Question Answering》
ArXiv上的一篇文章,虽然是17年的比较早,但是比较经典,后面看到很多新的模型都与这个模型进行了对比。看了一下模型结构,算是SAN网络的升级版吧。
文章下载地址:https://arxiv.org/pdf/1704.03162.pdf
文章引用格式:Vahid Kazemi and Ali Elqursh. "Show, Ask,Attend, and Answer: A Strong Baseline For Visual Question Answering." arXiv preprint, arXiv: 1704.03162, 2017.
项目地址:文章中并没有给,在github上找了一个https://github.com/momih/vqa_tensorflow
二、文章导读
先附上文章的摘要:
This paper presents a new baseline for visual question answering task. Given an image and a question in natural language, our model produces accurate answers according to the content of the image. Our model, while being architecturally simple and relatively small in terms of trainable parameters, sets a new state of the art on both unbalanced and balanced VQA benchmark. On VQA 1.0 [2] open ended challenge, our model achieves 64.6% accuracy on the teststandard set without using additional data, an improvement of 0.4% over state of the art, and on newly released VQA 2.0 [8], our model scores 59.7% on validation set outperforming best previously reported results by 0.5%. The results presented in this paper are especially interesting because very similar models have been tried before [32] but significantly lower performance were reported. In light of the new results we hope to see more meaningful research on visual question answering in the future.
这篇文章对于VQA提出了一种新的方法。该方法在VQA 1.0数据集上比最好的方法还多提高了0.4%的精度,达到了64.6%。在VQA 2.0数据集上,比最好的模型提高了0.5%,精度达到了59.7%。作者也提到了,这篇文章与SAN很像,(关于SAN之前的解读:【文献阅读】SAN——一种利用双层注意力的VQA网络(T. Do等人,ArXiv,2015,有代码)),但表现比SAN更好一些。
三、文章详细介绍
早期的VQA模型都比较简单,作者结合了软注意力,设计的VQA模型如下图所示:
同理,作者还是将VQA视作一个分类问题,即给定问题Q和图像I,来预测备选答案的概率:

1. 图像嵌入部分
获得图像嵌入,作者使用的是ResNet,取最后一个池化层,得到的特征大小是14×14×2048维的,然后再对深度维度进行l2范数约束。
2.问题嵌入部分
思路和SAN网络中的处理思路一样,先将问题嵌入到长度为p的向量中,然后将这个向量传入LSTM获得最后的问题嵌入。
3.堆叠注意力
这部分思路也和SAN一样。图像注意力是图像特征在所有空间位置上的加权平均,注意力权值是对每一个注意力对象分别归一化。实践中的注意力对象是通过两层卷积层建模获得,每一个对象都在第一层共享参数。作者仅依靠不同的初始化来产生不同的注意力分布。
4.分类器
最后将得到的图像注意力和LSTM的结果相连,最后输入到一个非线性层中输出正确答案的概率,这里的非线性层使用的是两层全连接网络。
最终模型的loss函数表示为:
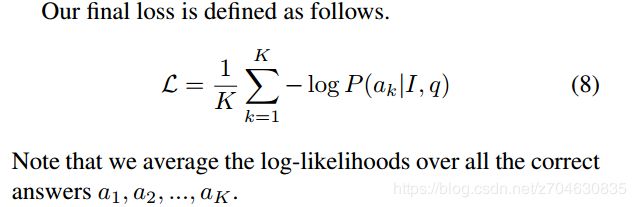
5.实验
输入图像都做中心裁剪,裁剪为299×299的;ResNet采用152层的,图像特征采用最后一个平均池化层,大小14×14×2048,并在深度维度上使用l2范数;
输入的问题嵌入到长度为300的向量,然后先传入tanh层激活;接下来再传入LSTM层,LSTM的unit设置为1024,最大问题的长度设置为15。
为了计算注意力,将LSTM的输出拉平后,连接在图像的深度维度上;在传入1×1的卷积层,深度为512,后面跟一个ReLU激活层;输出的特征再输入另一个1×1卷积层,深度为2,再跟一个softmax层来获得注意力。
最后再进一步的将图像注意力和LSTM的结果连接,传入全连接层,大小为1024,后跟一个ReLU激活层;将输出传入大小为3000的线性层,后再跟一个softmax层,获得最后答案的概率。这里3000就是答案的数量设置,这大概占据了VQA答案数量的92%,剩下的一些低频的答案,都不在考虑范围,他们对loss的贡献也很少。
实验中,dropout设置为0.5,优化器为Adam optimizer,batch size为128,训练10万个epoch。初始学习率为0.001,并在5万个epoch后开始衰减,下图为实验结果:
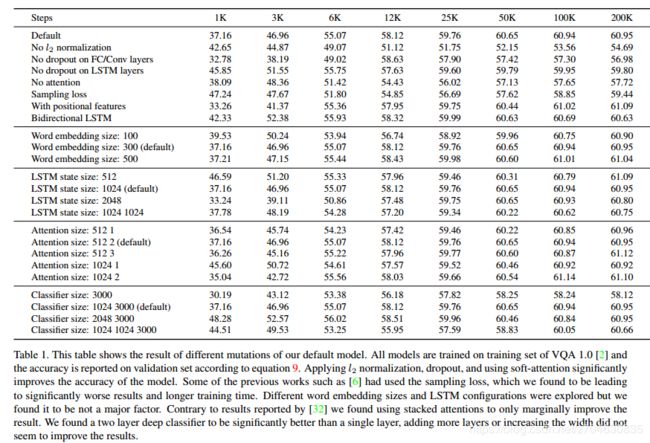
其中:
• No l2 norm: ResNet features are not l2 normalized. 指ResNet没有经过l2范数归一化
• No dropout on FC/Conv: Dropout is not applied to the inputs of fully connected and convolution layers. 在全连接和卷积层中没有使用dropout
• No dropout on LSTM: Dropout is not applied to the inputs of LSTM layers. 在LSTM中没有使用dropout
• No attention: Instead of using soft-attention we perform average spatial pooling before feeding image features to the classifier. 用空间池化替代空间注意力
• Sampled loss: Instead of averaging the log-likelihood of correct answers we sample one answer at a time. 只有一个正确答案(之前给出的是10个正确答案,然后计算预测答案和这10个答案的正确得分)
• With positional features: Image features φ are augmented with x and y coordinates of each cell along the depth dimension producing a tensor of size 14 × 14 × 2050. 图像特征增加了x和y坐标
• Bidirectional LSTM: We use a bidirectional LSTM to encode the question. 编码问题时采用双向LSTM
• Word embedding size: We try word embeddings of different sizes including 100, 300 (default), and 500. 单词嵌入的维度分别设置为100, 300,500
• LSTM state size: We explore different configurations of LSTM state sizes, this include a one layer LSTM of size 512, 1024 (default), and 2048 or a stacked two layer LSTM of size 1024. LSTM的输出大小分别设置为512,1024,2048(或者2个1024的叠加)
• Attention size: Different attention configurations are explored. First number indicates the size of first convolution layer and the second number indicates the number of attention glimpses. 不同的注意力层数和注意力数量。
• Classifier size: By default classifier G is consisted of a fully connected layer of size 1024 with ReLU nonlinearity followed by a M = 3000 dimensional linear layer followed by softmax. We explore shallower, deeper, and wider alternatives. 使用更浅层或者更深层或者对应替代的分类器