Learning as Decoding the World to Approach the Intelligence Upper-bound: Applying UICM to AlphaZero
This paper would be fully open-access.
The recently released AlphaZero algorithm achieves superhuman performance in the games of chess, shogi and Go, which raises two open questions.
- Firstly, as there is a finite number of possibilities in the game, is there an upper-bound for measuring AlphaZero’s intelligence and can we quantify it?
- Secondly, AlphaZero introduces sophisticated reinforcement learning and self-play to efficiently encode the possible states, is there a simple information-theoretic model to represent the learning process and offer more insights?
**This paper explores the above two questions by proposing a simple variance of the Unified Intelligence-Communication Model (UICM) that provides an intelligence upper-bound for intelligent agents in the form of Shannon’s channel capacity, and applies to AlphaZero as an illustrating example. This paper also explains the learning process of AlphaZero as turbo-like iterative decoding, and the learning performance may be quantitatively evaluated via a well-developed information-theoretic tools called EXIT charts. **
Finally, conclusions are provided along with theoretical and practical remarks.
Introduction
This is a previewed version of treatise.
A brief review of the related research would be given in detail of a later version for journal publication. Let us directly get through the jungle of the AI’s history and referred the latest success of DeepMind’s AlphaZero to the recent report in Science (1), and use Shannon’s communication model (2) to analyze the intelligence upper-bound and the learning process of intelligent agents, and provide a case study of AlphaZero.
Unified Intelligence-Communication Model in a Two-Player Game of Go
In Figure 1, we apply our universal intelligence-communication model (UICM) proposed in (3) to AlphaZero. Specifically, there are two agents in AlphaZero to enable self-play, and they interact with each other via the environment, e.g. a 19*19 chessboard. Each agent observes the move of its opponent, evaluates the situation of the chessboard, recognizes the pattern and predicts the future actions, before it makes a decision and takes the next move. The information exchanging and processing flow is equivalent to a two-way reciprocal Shannon’s communication model between agent A and B, where the communication channel is the chessboard.
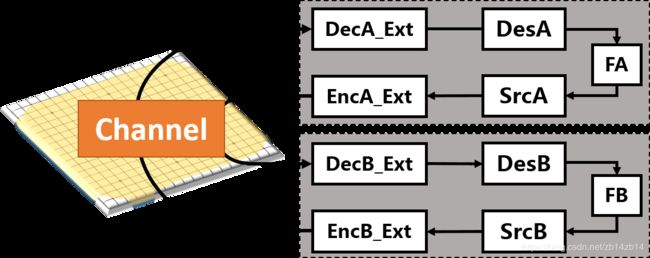
Fig. 1: The universal intelligence-communication model for AlphaZero.
The perception and action of two self-playing AlphaZero agents may be modelled as decoders and encoders, which capture the interaction between agents and the environment.
In chess or Go, both agents try to win the game so that each agent tries to predict the behavior of each other. Therefore, we may generalize Shannon’s communication model by adding internal communication channels, which is depicted in Figure 2. In agent A, it builds an internal environment model, including representations of the chessboard, the agent B and a critic (which is not illustrated in the figure) for evaluating the probability of winning. Therefore, agent A may play the game within itself with a virtual agent B over a virtual chessboard. This internal thinking process may also be modelled as a two-way reciprocal Shannon’s communication model. In order to distinguish between the different channels, we denote the communications between the real agent A and B as external communications, and the communication within agents itself as internal communications.
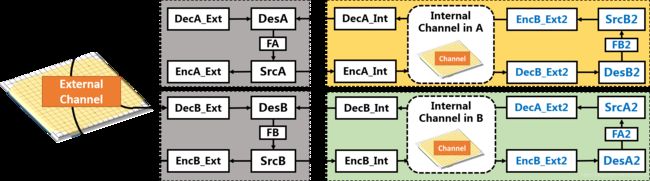
Fig. 2: The UICM for AlphaZero with internal world models and internal channels.
Each AlphaZero agent may build an internal channel or world model, where it virtually plays with the model of its opponent agent, predicts the effects of actions taken and learns the behavior of its opponent agent.
Intelligence Upper-bound of AlphaZero
Now we may formalize the goal of a single agent in AlphaZero:
In the two-player zero-sum game over a communication channel, the amount of source information of agent B decoded by agent A is denoted as IB-A, and that of agent A decoded by agent B is denoted as IA-B. The condition of agent A dominates is IB-A > IA-B, namely, agent A conquers agent B in terms of being more certain of its opponent’s strategies so that more effective actions may be taken.
Therefore, the maximum amount of information that can be decoded by agent A may be quantified by the entropy of information source, which in turn, would be upper-bounded by the well-defined Shannon capacity of the external communication channel. In the case of Go, the channel capacity may be roughly quantified by the (361!) possible states of the chessboard, where the inequality stands for effects that the rules of Go may prohibit some of the actions taken.
MAX ( I(B-A), I(A-B) ) ≤ C ≤ log2(361!) ≈ 2552.
As the information-theoretic upper-bound of AlphaZero is formulated as the Shannon channel capacity, we may now take a closer look at how AlphaZero approaches the capacity by designing a sophisticated decoder.
AlphaZero Self-Play Models as an Iterative Decoder
Both competing agents are co-evolving in the internal communication channel of AlphaZero, and each agent decodes the information from the external and internal communication channel independently and iteratively. We may formulate each agent as an component decoder, as a variance of the famous turbo decoder in the information-theoretic society (3), which made a breakthrough in approaching the Shannon capacity for error-correction code design. The decoder structure can be directly extracted from the architecture of Figure 2, but we re-plot it in Figure 3 to make it more explicit.
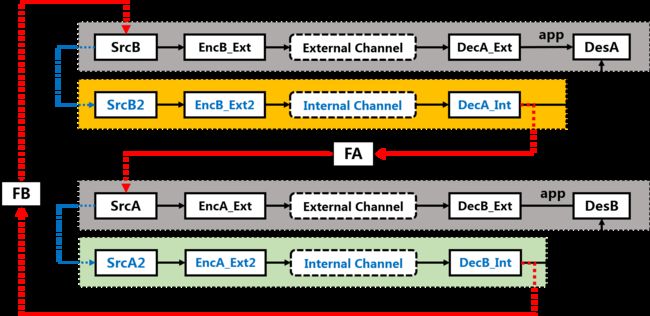
Figure 3. The Iterative Decoder in AlphaZero. Each AlphaZero agent forms a decoder for extracting information about its opponent, from a pair of external and the internal channels, which outputs extrinsic information for removing uncertainty of its opponent agent.
The main difference between a conventional turbo decoder and the proposed turbo decoder is the information source. The twin-component decoders in an interactive turbo decoder attempt to extract information from a single source. For example, the objective of agent A is to decode the information source from agent B conveyed over the external noise-free chessboard channel, so that it may decide the right move and win the game. However, as agent A cannot directly hack into the thinking pattern of agent B, a model for agent B is built within agent A itself.
Therefore, the source information of agent B rebuilt within agent A is an approximation, which improves during the learning process as well, the conversion from SrcA to SrcA2 along with the conversion in EncA_Ext2 may be integrated, forming a single encoder that may evolve over time. Also, the feedback design of FA and FB may be designed to be fully reciprocal. Hence, the structure of the iterative decoder in AlphaZero would be equivalent to standard turbo decoder (3).
Quantitative Analysis of the Learning Process
Before delving into the quantitative analysis, an important insights is given as follows. Even though the self-playing agents are competing in terms of reducing uncertainty of each other, they work together to jointly decode the information over the external channel and aims at achieving the channel capacity.
Here, we take a look at the Elo-rating metric used during the learning process of AlphaZero, where e(·) denotes the Elo-ratings and a higher rating increases the probability of winning.
Pr{A defeats B} = 1/ ( 1 + 10 ^ (C_elo*(e(B) - e(A)))).
where e(A) or e(B) may not have an upper-bound, as long as the self-play agents matched well so that e(A)=e(B), the two component agents in AlphaZero are of equal probability of winning or losing.
Therefore, we switch our viewpoint to use Shannon’s information entropy for measuring the learning process. Firstly, the intelligence upper-bound of AlphaZero is also an upper-bound for the self-playing agent A or B. Secondly, as seen in Fig. 3, if the extrinsic information exchanged between the component decoders formed by the self-playing agents no longer increases, the learning process also stopped and the intelligence-level of Agent A or B stopped improving. Please note that the extrinsic information IE(A) and IE(B) does not necessary to reach 1.0, as the learning process may stop at a local optimum.
This extrinsic information exchanging process may be quantitatively analyzed and graphically presented in EXtrinsic Information Transfer chart (EXIT chart) developed for analyzing decoding performance of iterative decoders (5). A successful and a unsuccessful learning process may then be distinguished by the curves in the EXIT charts, and two illustrative examples are provided in Figure 4.
Further results for the case study in terms of the IE(A) and IE(B) curves would be provided in the version for publication.
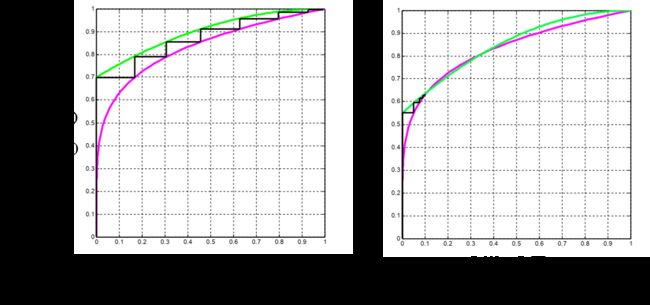
Fig. 4: Examples of Extrinsic Information Curves.If the curves of extrinsic information at the two component decoders form an open tunnel from (0,0) to (1,1), the learning process is likely to be successful, depending on the model for internal channels. If the two curves intersects other than (0,0) and (1,1), the learning process generally cannot reach a global optimum.
Conclusions and Future Works
In this paper, we modelled the interactions between an intelligent agent and its environment as a series of external and internal channels, where the intelligence upper-bound may be given by the Shannon’s channel capacity. The upper-bound approaching agent design was discussed, with a focus on iterative turbo-like decoder design in AlphaZero. The EXIT-chart is hence a quantitative tool for evaluating and predicting the learning process of an intelligence-bound approaching agent.
Some insights would be discussed in more detail in (3), and we briefly summarize the insights provided by AlphaZero as below:
The self-playing agents jointly decodes the information over the external channel (the world) iteratively, where the maximum amount of information is upper-bound by the channel capacity. The self-playing process may been seen as an iterative decoding process, where both agents are learning to adapt to the channel (environment), to build an internal channel model (world model) that operates arbitrary closed to the external model within itself, namely, capturing the (361!) possibilities in its internal channel (the world model).
As a theoretical remark, we may define an ultimate Go player as an agent, which has the capability of achieving the intelligence upper-bound quantified by the channel capacity. If two ultimate Go players compete with each other, they have full knowledge of each other. In this case, the probability of A wins equals 50% and therefore form a quantum superposition. The uncertainty would be reduced to 0 immediately after a first move of any agent is taken and the measurement of this move leads to a collapse from the quantum superposition to a certain end.
As a practical remark, motivated by the success of AlphaZero and the analysis provided in this paper, the iterative decoding or learning philosophy may be applied to other intelligent agent designs, and the internal channel may be modelled by component structure such as deep neural networks to approximate the external channel (world model). Hence, intelligence upper-bound approaching learning systems may be built following an iterative decoder architecture, which may bring about a breakthrough of performance in comparison to the state-of-art single component decoder design.
EXIT charts may serve as a powerful tool for evaluating the design of intelligence upper-bound approaching learning systems, meanwhile the tracking of the mutual information becomes an important issue in dealing with the dynamic and open world, as it is in general of much more uncertainty than the static and closed world of AlphaZero.
References
[1] Silver, D. et al., A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 362, 1140 – 1144 (2018).
[2] C. E. Shannon, A mathematical theory of communication. Bell Labs Technical Journal 27.4, 379-423 (1948).
[3] B. Zhang et al., An Unified Intelligence-Communication Model for Multi-Agent System Part-I: Overview. arXiv preprint arXiv:1811.09920 (2018).
[4] C. Berrou, A. Glavieux, P. Thitimajshima. Near Shannon limit error-correcting coding and decoding. IEEE International Conference on Communications. (1993).
[5] S. T. Brink, Convergence behavior of iteratively decoded parallel concatenated codes. IEEE Trans Commun 49.10, 1727-1737 (2001).