python获取百度迁徙大数据
python获取百度迁徙大数据
在疫情期间,百度迁徙大数据大放异彩,很多研究都是基于百度迁徙数据来进行的,由于本次研究也依赖与百度迁徙数据,所以小试牛刀。
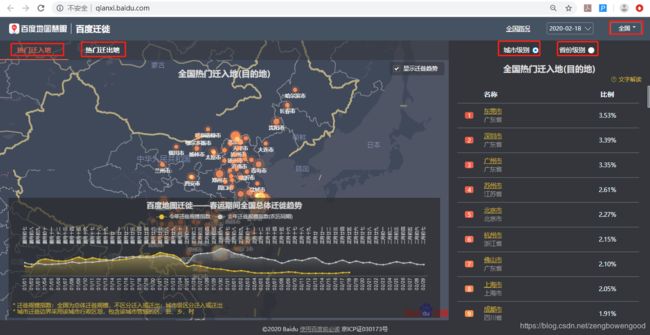
首先,打开目标网站 http://qianxi.baidu.com/,观察网页布局
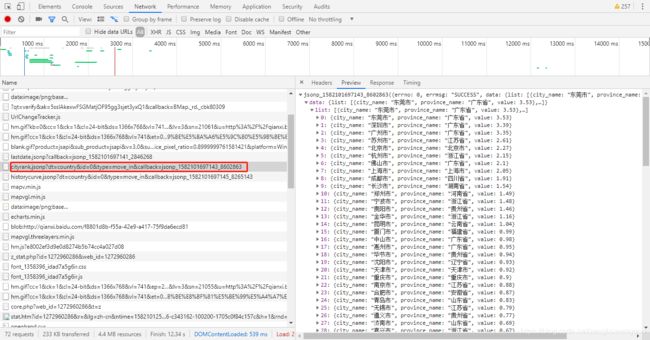
其次,F12打开源网页,Ctrl+R刷新,找到数据对应item
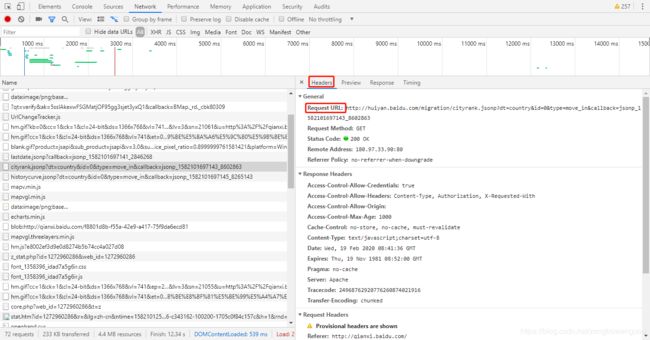
接着,切换源网页的header,找到请求url
然后,复制url到浏览器打开
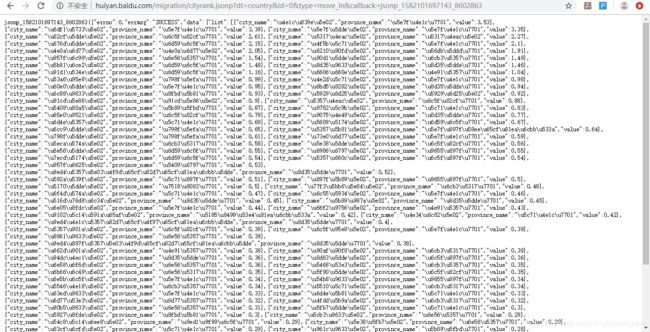
发现两者一毛一样,接下来就是分析数据结构和写代码提取数据,先来一个按照省份级别迁入,并写入到csv里面
def get_country_province(): #获取全国省份级别流入
url='http://huiyan.baidu.com/migration/provincerank.jsonp?dt=country&id=0&type=move_in&date=20200218'
response=requests.get(url, timeout=10) # #发出请求并json化处理
time.sleep(1) #挂起一秒
r=response.text[3:-1] #去头去尾
data_dict=json.loads(r) #字典化
if data_dict['errmsg']=='SUCCESS':
data_list=data_dict['data']['list']
with open("全国省份级别流入.csv", "w+", newline="") as csv_file:
writer=csv.writer(csv_file)
header=["province_name", "value"] #表头"city_name",
writer.writerow(header) #把表头写入
for i in range(len(data_list)):
province_name=data_list[i]['province_name'] #省份名
value=data_list[i]['value']
writer.writerow([ province_name, value]) #city_name
有进就有出,回击原网页点击热门迁出地,然后会发现源网页多了一条item
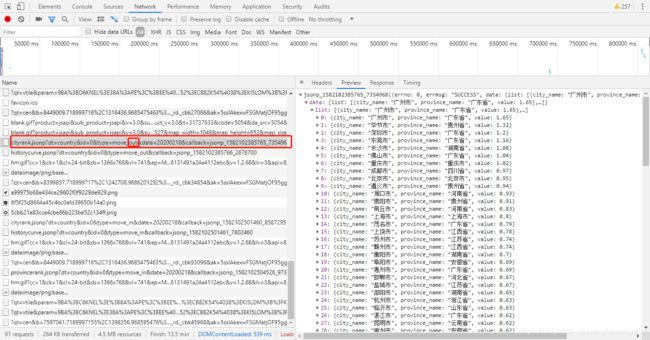
获取相应的url,写代码如下获取全国城市级别迁出数据
def get_country_city(): #获取全国城市级别流出
url='http://huiyan.baidu.com/migration/cityrank.jsonp?dt=country&id=0&type=move_out&date=20200218'
response=requests.get(url, timeout=10) # #发出请求并json化处理
time.sleep(1) #挂起一秒
r=response.text[3:-1] #去头去尾
data_dict=json.loads(r) #字典化
if data_dict['errmsg']=='SUCCESS':
data_list=data_dict['data']['list']
with open("全国城市级别流出.csv", "w+", newline="") as csv_file:
writer=csv.writer(csv_file)
header=["city_name", "province_name", "value"] #表头city_name
writer.writerow(header) #把表头写入
for i in range(len(data_list)):
city_name=data_list[i]['city_name'] #城市名
province_name=data_list[i]['province_name'] #省份名
value=data_list[i]['value']
writer.writerow([city_name, province_name, value]) #city_name
代码成功运行后,文件夹下会多出两个csv文件,截图如下

获取两个全国层面的数据,你或许会有所感悟,那就是不同日期,不同城市,不同迁徙方向,不同层级(省份,城市)的请求都体现在url的参数里面
- cityrank 表示城市级别
- provincerank表示省份级别
- id表示中华人民共和国县以上行政区划代码,这个可以通过如下网站获取 http://www.mca.gov.cn/article/sj/xzqh/2019/2019/201912251506.html
- move_out表示迁出
- move_in表示迁入
- date表示日期
下面给出如何循环构造不同组合的url代码
def generate_url(): #定义生成不同时期,不同城市,不同迁徙方向,不同层级的请求url
date_list=['20200129', '20200130', '20200131', '20200201', '20200202', '20200203',
'20200204', '20200205', '20200206', '20200207', '20200208', '20200209'] #初五到初十六时间段
directions=['in', 'out'] #迁徙方向
level_list=['province','city'] #数据级别
city_list={'北京':'110000', '上海': '310000', '广州':'440100', '深圳': '440300',
'杭州': '330100', '南京': '320100', '天津': '120000', '成都':
'510100', '武汉': '420100', '苏州': '320500'} #构造重点10城字典
urls=[] #用来存放url
for city_id in list(city_list.values()): #城市id
for direction in directions: #迁入还是迁出
for date in date_list: #对日期循环
for level in level_list:
url='http://huiyan.baidu.com/migration/{}rank.jsonp?dt=country&id={}&type=move_{}&&date={}'.format(level, city_id, direction, date) #请求url
print(url)
urls.append(url) #追加进去
return urls
最后贴出完整代码
# -*- coding: utf-8 -*-
"""
Created on Tue Feb 18 14:25:58 2020
project name:百度迁徙
@author: 帅帅de三叔
"""
import requests #导入请求模块
import json #导入json模块
import csv #导入csv模块
import time #导入时间模块
def get_country_province(): #获取全国省份级别流入
url='http://huiyan.baidu.com/migration/provincerank.jsonp?dt=country&id=0&type=move_in&date=20200218'
response=requests.get(url, timeout=10) # #发出请求并json化处理
time.sleep(1) #挂起一秒
r=response.text[3:-1] #去头去尾
data_dict=json.loads(r) #字典化
if data_dict['errmsg']=='SUCCESS':
data_list=data_dict['data']['list']
with open("全国省份级别流入.csv", "w+", newline="") as csv_file:
writer=csv.writer(csv_file)
header=["province_name", "value"] #表头"city_name",
writer.writerow(header) #把表头写入
for i in range(len(data_list)):
province_name=data_list[i]['province_name'] #省份名
value=data_list[i]['value']
writer.writerow([ province_name, value]) #city_name
def get_country_city(): #获取全国城市级别流出
url='http://huiyan.baidu.com/migration/cityrank.jsonp?dt=country&id=0&type=move_out&date=20200218'
response=requests.get(url, timeout=10) # #发出请求并json化处理
time.sleep(1) #挂起一秒
r=response.text[3:-1] #去头去尾
data_dict=json.loads(r) #字典化
if data_dict['errmsg']=='SUCCESS':
data_list=data_dict['data']['list']
with open("全国城市级别流出.csv", "w+", newline="") as csv_file:
writer=csv.writer(csv_file)
header=["city_name", "province_name", "value"] #表头city_name
writer.writerow(header) #把表头写入
for i in range(len(data_list)):
city_name=data_list[i]['city_name'] #城市名
province_name=data_list[i]['province_name'] #省份名
value=data_list[i]['value']
writer.writerow([city_name, province_name, value]) #city_name
def generate_url(): #定义生成不同时期,不同城市,不同迁徙方向,不同层级的请求url
date_list=['20200129', '20200130', '20200131', '20200201', '20200202', '20200203',
'20200204', '20200205', '20200206', '20200207', '20200208', '20200209'] #初五到初十六时间段
directions=['in', 'out'] #迁徙方向
level_list=['province','city'] #数据级别
city_list={'北京':'110000', '上海': '310000', '广州':'440100', '深圳': '440300',
'杭州': '330100', '南京': '320100', '天津': '120000', '成都':
'510100', '武汉': '420100', '苏州': '320500'} #构造重点10城字典
urls=[] #用来存放url
for city_id in list(city_list.values()): #城市id
for direction in directions: #迁入还是迁出
for date in date_list: #对日期循环
for level in level_list:
url='http://huiyan.baidu.com/migration/{}rank.jsonp?dt=country&id={}&type=move_{}&&date={}'.format(level, city_id, direction, date) #请求url
print(url)
urls.append(url) #追加进去
return urls
if __name__=="__main__":
get_country_province()
get_country_city()
generate_url()
Python爬虫仅为学习交流,如有冒犯,请告知删。