ElasticSearch与Kibana简介及使用入门
Elasticsearch一款基于Apache Lucene™开源搜索引擎,其核心是迄今为止最先进、性能最好的、功能最全的搜索引擎库Lucene。Elasticsearch使用简单,具有非常强大的全文搜索功能:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
ElasticSearch中使用到的概念
准实时
Elasticsearch是一个准实时系统:一个文档从存储到它能够被检索只有一个很短的延迟(通常情况下为一秒)。
集群(Cluster)
为所有数据提供存储和检索等服务的结点(服务器)集合。默认的名字为“elasticsearch”,结点(服务器)也依据名字被指定要加入哪个集群。
结点(Node)
作为集群的一部分,为数据提供存储和检索服务的一台服务器。
索引(Index)
索引的概念类似于关系数据库中的数据库,是相关文档存储的地方。相应的,“索引一个文档”表示把一个文档存储在某个索引中。
类型(Type)
索引中文档的逻辑分类,类似于关系数据库中的表。
Elasticsearch 6.0.0.已经不支持在一个索引中建立多个类型,在以后版本中会移除类型这一个概念。
文档(Document)
一条完整的记录,类似于关系数据库中的元组。
域(Fields)
类似于关系数据库中的属性。
倒排索引
Elasticsearch会为文档中的每个字段都建立倒排索引,这是它实现高效搜索的基础之一。
ElasticSearch类比传统数据库
| Relational DB | Elasticsearch |
|---|---|
| Databases | Indices |
| Tables | Types |
| Rows | Documents |
| Columns | Fields |
安装
Elasticsearch 需要 Java8 或更新的 Java 环境。Java 下载
下载 Elasticsearch 6.0.1 压缩包并解压
$ curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.0.1.tar.gz
$ tar -xvf elasticsearch-6.0.1.tar.gz
启动
$ cd elasticsearch-6.0.1/bin
$ ./elasticsearch
如果你不想使用默认的集群名和结点名,可以在启动时指定相应的参数:
$ ./elasticsearch -Ecluster.name=my_cluster_name -Enode.name=my_node_name
交互
Elasticsearch启动后是一个 http 服务,默认在本地的 9200 端口。可以通过 curl 或者 Kibana 控制台进行操作。使用 curl 的命令格式如下:
$ curl -X<VERB> ':/?' -d ''
- VERB:HTTP 方法,如 GET、POST、PUT、HEAD、DELETE
- PROTOCOL:http 或者 https 协议
- HOST: Elasticsearch集群中的任何一个节点的主机名,如果是在本地的节点,那么就叫localhost
- PORT: Elasticsearch HTTP服务所在的端口,默认为 9200
- PATH: API路径
- QUERY_STRING: 一些可选的查询请求参数,例如
?pretty参数将使请求返回更加美观易读的JSON数据 - BODY: 一个JSON格式的请求主体(如果请求需要的话)
例. 查询集群中结点的健康状况
$ curl -X GET "localhost:9200/_cat/health?v"
- 绿色:一切安好
- 黄色:所有结点均可用,某些结点没有备份
- 红色:某些结点不可用
增
添加一个名为“customer”的索引
$ curl -X PUT "localhost:9200/customer?pretty"
查看现有的所有索引
$ curl -X GET "localhost:9200/_cat/indices?v"
在索引“customer”中添加一个 ID 为 1 顾客的信息,即一个文档(文档类型为 doc)
$ curl -X PUT "localhost:9200/customer/doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"name": "John Doe"
}
'
查看顾客1的信息
$ curl -X GET "localhost:9200/customer/doc/1?pretty"
改
将顾客1的姓名改为 “Jane Doe”
$ curl -X PUT "localhost:9200/customer/doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"name": "Jane Doe"
}
'
查看顾客1的信息
$ curl -X GET "localhost:9200/customer/doc/1?pretty"
为顾客1添加一项年龄属性
$ curl -X POST "localhost:9200/customer/doc/1/_update?pretty" -H 'Content-Type: application/json' -d'
{
"doc": { "name": "Jane Doe", "age": 20 }
}
'
删
删除“customer”索引
$ curl -X DELETE "localhost:9200/customer?pretty"
查看现有的所有索引
$ curl -X GET "localhost:9200/_cat/indices?v"
批处理
_bulkAPI 可以帮助我们一次进行多项操作。添加两个顾客 John Doe 和 Jane Doe
$ curl -X POST "localhost:9200/customer/doc/_bulk?pretty" -H 'Content-Type: application/json' -d'
{"index":{"_id":"1"}}
{"name": "John Doe" }
{"index":{"_id":"2"}}
{"name": "Jane Doe" }
'
将顾客1的名字改为 Jane Done, 并删除顾客2的信息
$ curl -X POST "localhost:9200/customer/doc/_bulk?pretty" -H 'Content-Type: application/json' -d'
{"update":{"_id":"1"}}
{"doc": { "name": "John Doe becomes Jane Doe" } }
{"delete":{"_id":"2"}}
'
查询
上面已经介绍了如何使用 curl 进行简单的查询。若要对数据进行复杂查询与分析,推荐结合使用 Kibana。
kibana简介
Kibana是一个与Elasticsearch协同工作的开源分析和可视化平台,Kibana 可以让你更方便地对 Elasticsearch 中数据进行操作,包括高级的数据分析以及在图表中可视化您的数据。
安装
Kibana 的主版本号和次版本号不要超过 Elasticsearch,最好使用同版本号的 Kibana 与 Elasticsearch。
下载 Kibana 6.0.1压缩包并解压
$ wget https://artifacts.elastic.co/downloads/kibana/kibana-6.0.1-linux-x86_64.tar.gz
$ tar -xzf kibana-6.0.1-linux-x86_64.tar.gz
启动
$ cd kibana-6.0.1-linux-x86_64/
$ ./bin/kibana
Kibana 默认运行在 5601 端口,打开浏览器访问 localhost:5601 即可看到 Kibana 控制台,打开 Dev Tools 便签栏即可与 Elasticsearch 进行交互。
准备数据
在体验Kibana之前先让我们准备一些更加复杂的数据,以便更好地体现出Kibana的效果。官网上有三个数据集可供使用:shakespeare.json、accounts.zip、logs.jsonl.gz。这里我们选择其中的accounts.zip、logs.jsonl.gz。
下载完成后需要解压
$ unzip accounts.zip
$ gunzip logs.jsonl.gz
在我们导入数据集前,需要先指定一些数据域的属性。
logs 数据的结构很复杂,此次示例我们只关心以下几个域:
{
"memory": INT,
"geo.coordinates": "geo_point"
"@timestamp": "date"
}
在 Kibana的Dev Tools 控制台中输入一下命令对其中某些域指定特性:
PUT /logstash-2015.05.18
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}
PUT /logstash-2015.05.19
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}
PUT /logstash-2015.05.20
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}
accounts 数据不需要指定域特性,现在我们已经准备好了,可以向 Elasticsearch 导入数据了,在放有三个解压好的数据文件的同级目录下运行以下shell命令:
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary @accounts.json
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/_bulk?pretty' --data-binary @logs.jsonl
等待数据导入完成,再看一眼是否导入成功:
GET /_cat/indices?v
制定索引模式
在正常的使用过程中,你的Elasticsearch库中可能有非常多的索引,通过制定一些索引模式(即含有统配符的索引名匹配模板)可以在进行检索时有效地制定搜索的范围。在Kibana的 Management 标签栏下添加新的索引模式,这里我们添加了两个索引模式:ba*、logstash*
shakespeare和accounts数据都是没有时间信息的,所以在添加shakes*和ba*索引模式时“Index contains time-based events box ”一栏应该置为空,logs数据集带有时间信息,在添加logstash-*索引模式时在这一项选择“@timestamp”。
索引模式可以自由制定,但必须保证所添加的索引模式能够匹配到Elasticsearch中现有的某些索引,并且这些索引中还必须有数据。
在控制台输入 GET _cat/indices 可以查看 Elasticsearch中现存的所有索引。
检索
进入 Kibana 的 Discover 标签栏,通过在顶部的搜索框中输入 Elasticsearch 查询语句可以对数据进行各种检索。当前使用的索引模式显示在搜索栏下面,Elasticsearch只会在与当前的索引模式相匹配索引中执行搜索。
举个例子,将当前的索引模式选择为 ba*,并在顶部的搜索栏中输入:
account_number:<100 AND balance:>47500
来查询 accounts 数据中 accounts_number 属性小于100,并且balance属性大于47500的文档。

可以看到一共有五条文档符合我们的检索要求,Kibana默认会列出所有匹配文档的所有域,通过将鼠标悬停在相关域点击后面的“add”按钮可以要查看的域进行筛选。
数据可视化
在 Kibana 的 Visualize 标签栏下对你的数据进行可视化。
例:点击“Create a visualization”新建一个数据视图。Kibana 提供了多种数据视图,这里我们选择饼图,再选择索引模式ba*。
在初始的默认值下,所有的文档都被匹配上了,所以我们看到的是一个单色的饼图。这里我们使用Buckets聚合来将对数据的balance进行一下分析:
1.点击“Split Slices”按钮
2.在Aggregation列表中选择Range选项
3.在Field列表中选择balance选项
4.通过点击“Add Range”按钮,制定6个区间
5.每个区间的范围值如下
| 0 | 999 |
|---|---|
| 1000 | 2999 |
| 3000 | 6999 |
| 7000 | 14999 |
| 15000 | 30999 |
| 31000 | 50000 |
6.点击“Apply changes”显示分析结果
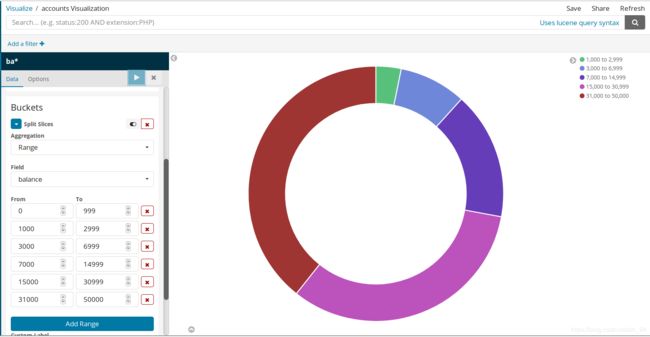
下面让我进行更进一步的分析,通过以下操作,我们来分析一下每个 balance range中开户人的年龄分布情况:
1.点击bucket列表下的“Add sub-buckets”按钮,新建一列子buckets
2.点击“Split Slices”按钮
3.在Aggregation列表中选择“Term”选项
4.在Field列表中选择age选项
5.在Order By中选择metric:Count选项
6.在Order中选择Descending,Size默认为5
7.点击“Apply changes”显示分析结果
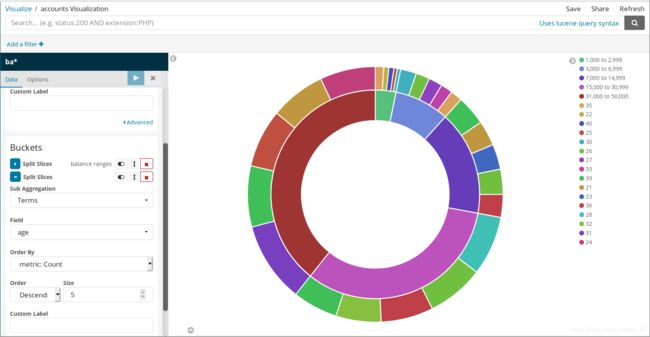
将鼠标悬停在相关区域可以显示更多信息,在Custom Label栏中可以为我们的坐标起名字,点击右上角的Save按钮可以保存我们的视图。
下面我们来对log数据进行一些分析:
1.点击左上角的Visualize按钮,回到Visualize标签栏的根目录,添加一个新的视图
2.选择Coordinate Map 视图
3.选择logstash-*索引模式
4.点击右上角的时间信息,打开时间过滤器
5.我们选择查看2015.5.18到2015.5.20的信息
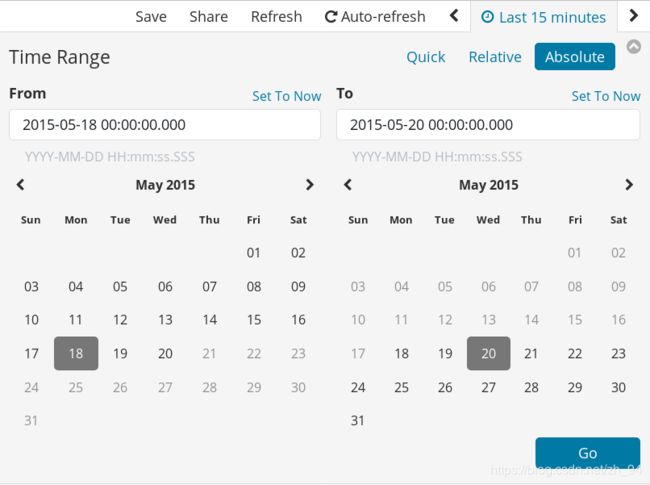
6.点击Go按钮,应用我们的时间过滤器
7.在buckets中选择Geo Coordinate指定我们要查询的内容,并点击Apply changes使查询生效

Kibana还支持绘制直方图,折线图等多种多样的视图以及更高级的数据可视化功能。
更多详情请参考:
Elasticsearch官方文档
Kibana官方文档
可能遇到的问题
can not run elasticsearch as root
切换到非root用户
main ERROR Could not register mbeans java.security.AccessControlException: access denied (“javax.management.MBeanTrustPermission” “register”)
改变elasticsearch文件夹所有者到当前用户:
$ sudo chown -R user_name elasticsearch