kafka发送消息至指定分区
前言
在实际使用中,我们可能需要对某个topic下不同的消息进行分类管理,比如确保消费的顺序性,在这种场景下,我们可以首先确保生产者发送消息到指定的分区即可
本文的测试基于docker搭建的一个双节点的简单集群,有兴趣搭建的同学可参考我的另一篇博客
1、创建一个名为second的topic
在该topic下,有3个分区,两个副本
$KAFKA_HOME/bin/kafka-topics.sh --create --zookeeper zoo1:2181 --replication-factor 2 --partitions 3 --topic second
2、从某个docker节点下进入控制台,输入如下命令等待消费
$KAFKA_HOME/bin/kafka-console-consumer.sh --bootstrap-server kafka1:9092 --from-beginning --topic second
在使用Java客户端连接kafka进行消息发送时,提供了2种发送消息到指定的分区的方式,下面分别进行演示
3、pom文件添加如下依赖
org.apache.kafka
kafka-clients
0.11.0.0
方式1:直接在发送消息时指定
下面贴出生产者的主要代码
/**
* 生产者将消息发到指定的主题分区下
*/
public class SpecialPartionProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "106.15.37.147:9092")
properties.put("acks", "all");
properties.put("retries", "3");
properties.put("batch.size", "16384");
properties.put("linger.ms", 1);
properties.put("buffer.memory", 33554432);
//key和value的序列化
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//构造生产者对象
KafkaProducer producer = new KafkaProducer(properties);
//发送消息
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord("second", 0,"congge " ,"val = "+ i)
, new ProducerCallBackV2());
}
//关闭连接资源
producer.close();
}
}
/**
* 生产者回调消息
*/
class ProducerCallBackV2 implements Callback {
public void onCompletion(RecordMetadata metadata, Exception e) {
if(e == null){
System.out.println("offset : " + metadata.offset());
System.out.println("partition : " + metadata.partition());
System.out.println("topic : " +metadata.topic());
System.out.println("===============================");
}
}
}
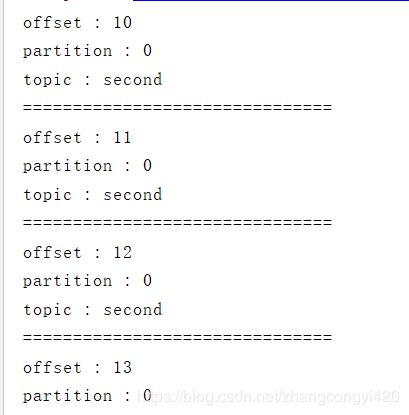
在这种方式下,我们只需要在producer.send()方法中指定具体的分区值即可,运行这段代码,从控制台可以看到,消息发送到分区为0的里面
方式2:实现Partitioner接口
这种方式看起来更加灵活,重写里面的partition方法,可以更好的结合具体的业务场景对分区进行指定,因此首先需提供一个自定义的分区类,假如我这里直接返回分区1,当然,也可以通过一定的取模算法,或者根据业务逐渐写个路由算法进行指定也可
public class MyPartion implements Partitioner {
public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) {
return 1;
}
public void close() {
}
public void configure(Map map) {
}
}
生产者代码,这一次,通过上面的这种方式做,则需要在参数里面进行分区的指定,即只需要将实现上面Partitioner接口的完整的类加上即可
public class PartionProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "106.15.37.147:9092");
properties.put("acks", "all");
properties.put("retries", "3");
properties.put("batch.size", "16384");
properties.put("linger.ms", 1);
properties.put("buffer.memory", 33554432);
//key和value的序列化
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//添加自定义分区器
properties.put("partitioner.class", "com.congge.partion.MyPartion");
//构造生产者对象
KafkaProducer producer = new KafkaProducer(properties);
//发送消息
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord("second", "congge-self ", "val = " + i)
, new ProducerCallBackV3());
}
//关闭连接资源
producer.close();
}
}
/**
* 生产者回调消息
*/
class ProducerCallBackV3 implements Callback {
public void onCompletion(RecordMetadata metadata, Exception e) {
if (e == null) {
System.out.println("offset : " + metadata.offset());
System.out.println("partition : " + metadata.partition());
System.out.println("topic : " + metadata.topic());
System.out.println("===============================");
}
}
}
运行上面的代码,观察控制台输出,同样也能达到预期的效果
