es复合条件查询
在es中,使用组合条件查询是其作为搜索引擎检索数据的一个强大之处,在前几篇中,简单演示了es的查询语法,但基本的增删改查功能并不能很好的满足复杂的查询场景,比如说我们期望像mysql那样做到拼接复杂的条件进行查询该如何做呢?es中有一种语法叫bool,通过在bool里面拼接es特定的语法可以做到大部分场景下复杂条件的拼接查询,也叫复合查询
首先简单介绍es中常用的组合查询用到的关键词,
filter:过滤,不参与打分
must:如果有多个条件,这些条件都必须满足 and与
should:如果有多个条件,满足一个或多个即可 or或
must_not:和must相反,必须都不满足条件才可以匹配到 !非
发生 描述
must
该条款(查询)必须出现在匹配的文件,并将有助于得分。
filter
子句(查询)必须出现在匹配的文档中。然而不像 must查询的分数将被忽略。Filter子句在过滤器上下文中执行,这意味着评分被忽略,子句被考虑用于高速缓存。
should
子句(查询)应该出现在匹配的文档中。如果 bool查询位于查询上下文中并且具有mustor filter子句,则bool即使没有should查询匹配,文档也将匹配该查询 。在这种情况下,这些条款仅用于影响分数。如果bool查询是过滤器上下文 或者两者都不存在,must或者filter至少有一个should查询必须与文档相匹配才能与bool查询匹配。这种行为可以通过设置minimum_should_match参数来显式控制 。
must_not
子句(查询)不能出现在匹配的文档中。子句在过滤器上下文中执行,意味着评分被忽略,子句被考虑用于高速缓存。因为计分被忽略,0所有文件的分数被返回。
下面用实验演示一下上述查询的相关语法,
1、首先,我们创建一个索引,并且在索引里添加几条数据,方便后面使用,
我这里直接批量插入数据,也可以通过PUT的语法单条执行插入,
POST /forum/article/_bulk
{ "index": { "_id": 1 }}
{ "articleID" : "XHDK-A-1293-#fJ3", "userID" : 1, "hidden": false, "postDate": "2019-07-01","title":"java contains hadoop and spark","topic":"java" }
{ "index": { "_id": 2 }}
{ "articleID" : "KDKE-B-9947-#kL5", "userID" : 1, "hidden": false, "postDate": "2019-07-02",title":"php contains admin","topic":"java and php" }
{ "index": { "_id": 3 }}
{ "articleID" : "JODL-X-1937-#pV7", "userID" : 2, "hidden": false, "postDate": "2019-07-03" ,title":"spark is new language","topic":"spark may use java"}
{ "index": { "_id": 4 }}
{ "articleID" : "QQPX-R-3956-#aD8", "userID" : 2, "hidden": true, "postDate": "2019-07-04" ,title":"hadoop may involve java","topic":"big data used"}
或者使用put语法
PUT /forum/article/4
{
"articleID": "QQPX-R-3956-#aD8",
"userID": 2,
"hidden": true,
"postDate": "2019-07-04",
"title": "hadoop may involve java",
"topic": "big data used"
}
4条数据插入成功,
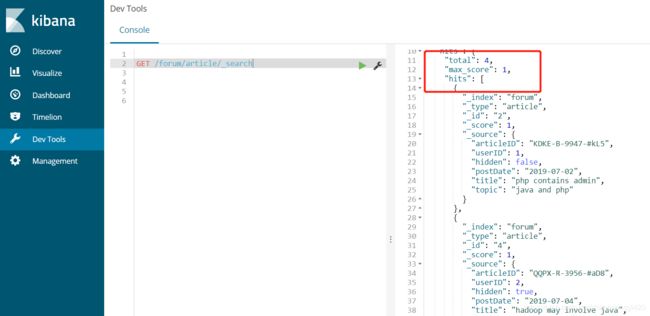
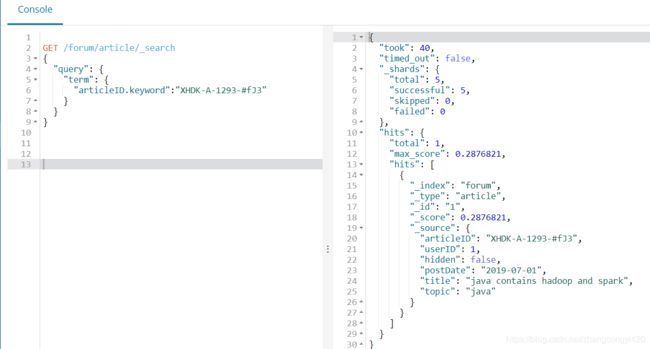
2、termQuery,term查询不分词,类似于mysql的where filedName = ? 语法,即精准匹配,比如我们查询articleID = XHDK-A-1293-#fJ3的这条数据,
GET /forum/article/_search
{
"query": {
"term": {
"articleID.keyword":"XHDK-A-1293-#fJ3"
}
}
}
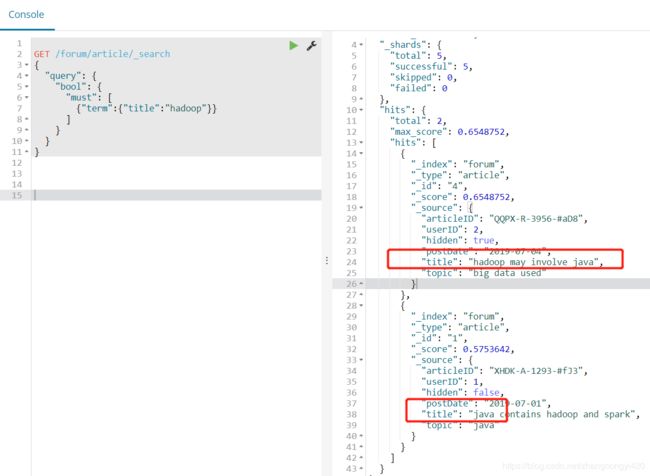
2、must查询,即查询的条件中必须匹配的字段,例如,查询title中必须包含java的数据,
GET /forum/article/_search
{
"query": {
"bool": {
"must": [
{"term":{"title":"hadoop"}}
]
}
}
}
查出两条数据
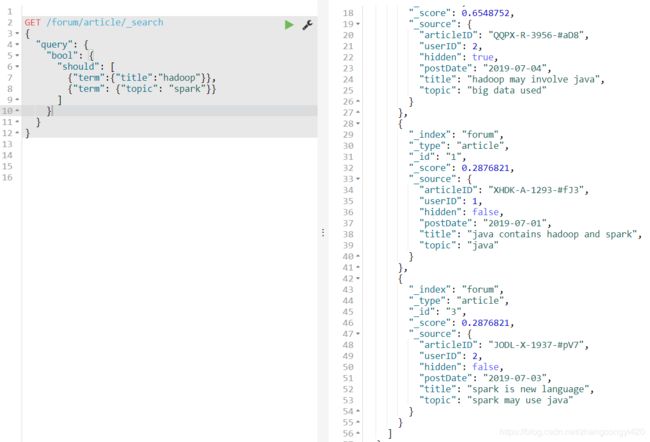
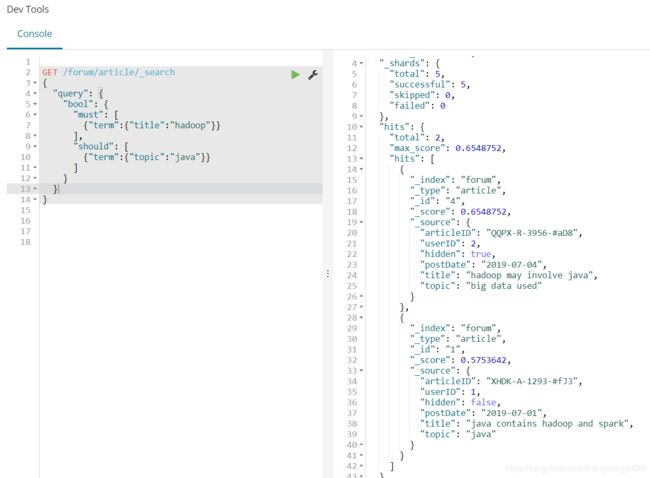
如果是should呢?如下语法,即查询title中包含hadoop或者topic中包含spark,二者满足其一即可,
GET /forum/article/_search
{
"query": {
"bool": {
"should": [
{"term":{"title":"hadoop"}},
{"term": {"topic": "spark"}}
]
}
}
}
查询出3条数据,
must和should结合使用,
最后再来一个比较复杂的嵌套查询,我们先看一下这条sql语句,
select *
from forum.article
where article_id=‘XHDK-A-1293-#fJ3’
or (article_id=‘JODL-X-1937-#pV7’ and post_date=‘2017-01-01’),
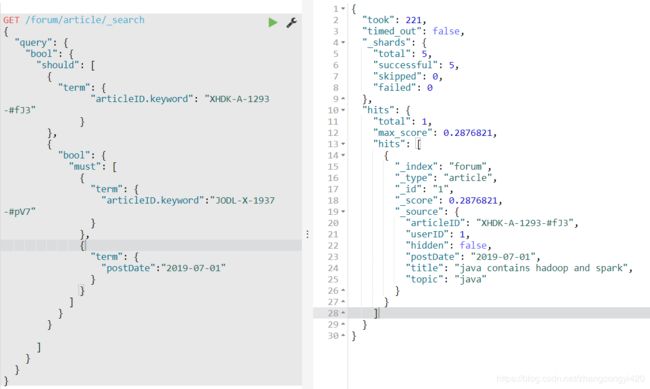
对应着转化为es的复合查询语法是怎样的呢?拆分来看,就是一个should语句的嵌套,
GET /forum/article/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"articleID.keyword": "XHDK-A-1293-#fJ3"
}
},
{
"bool": {
"must": [
{
"term": {
"articleID.keyword":"JODL-X-1937-#pV7"
}
},
{
"term": {
"postDate":"2019-07-01"
}
}
]
}
}
]
}
}
}
查询到一条结果,按照这种思路,如果我们对一个复杂的查询不知道如何构建查询语句时,可以考虑先按照sql的语法进行拆分,然后再组织es查询语句是个不错的突破口,
到这里,可能我们会有疑问,复合条件中的term查询和单纯的match区别在哪里呢?既然都是查询,究竟原理有何不同呢?
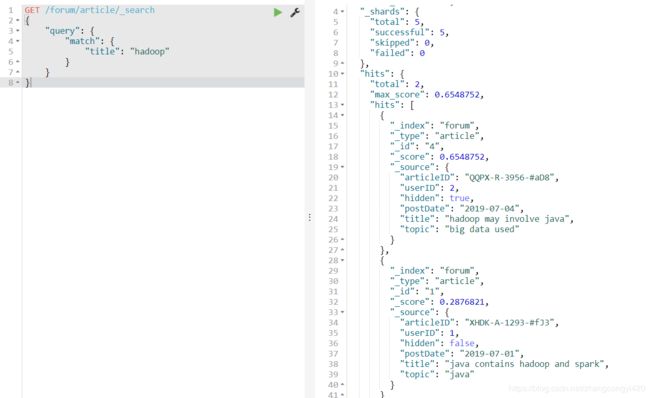
我们知道match query是需要全文检索的,是进行full text的全文检索,当然如果搜索的字段值做了not_analyzed,match query也相当于是term query了,比如下面这个搜索,由于在插入数据的时候我们没有对title这个字段进行规定,默认就是text类型的,会被自动分词,这样查询的时候只要title中包含了 hadoop,就可以匹配到,
GET /forum/article/_search
{
"query": {
"match": {
"title": "hadoop"
}
}
}
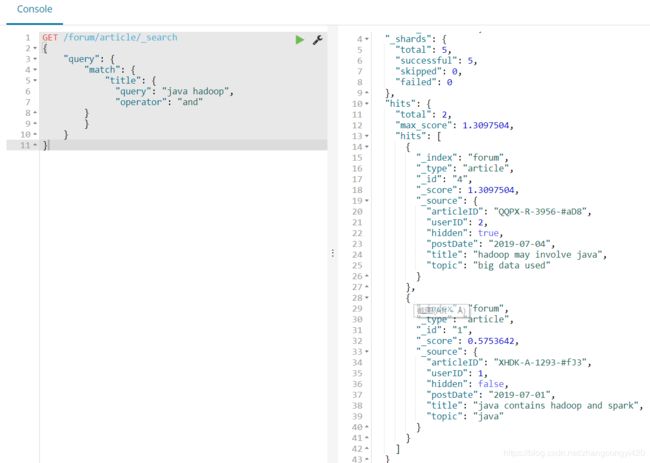
2、有些情况下,假如我们直接使用match进行查询,又希望查出来的结果尽可能是我们期望的包含更多关键词的结果,则在match进行匹配的时候可以添加其他的条件,以便提升结果的匹配精确度,
GET /forum/article/_search
{
"query": {
"match": {
"title": {
"query": "java hadoop",
"operator": "and"
}
}
}
}
这样匹配出来的结果包含了更多我们期望的关键词,即query中可以指定我们查询的结果中包含的关键词,
es还有其他的语法达到上述的效果,minimum_should_match ,通过这个语法,可以指定匹配的百分数,就是查询的关键词至少要达到的百分数,下面这个表示全部匹配,只查询到一条结果,

假如我们将百分数调低点,比如75%,可以看到查到两条结果,
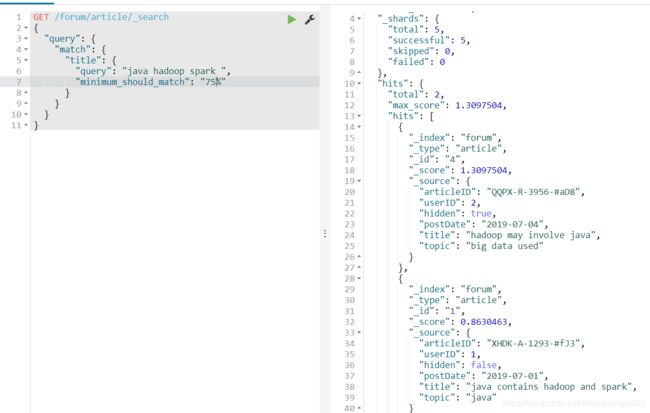
3、当然,我们也可以将bool和match结合起来使用,如下,
GET /forum/article/_search
{
"query": {
"bool": {
"must": [
{"match": {"title": "java"}}
],
"must_not": [
{ "match": { "title": "spark"}}
]
, "should": [
{
"match": {
"title": "php"
}
}
]
}
}
}
通过这种方式,也可以达到更精准的匹配我们期望的查询结果,

简单总结来说,当我们使用match进行查询的时候,如果查询的field包含多个词,比如像下面这个,
{
"match": { "title": "java elasticsearch"}
}
其实es会在底层自动将这个match query转换为bool的语法bool should,指定多个搜索词,同时使用term query,则转化后的语法如下,
{
"bool": {
"should": [
{ "term": { "title": "java" }},
{ "term": { "title": "elasticsearch" }}
]
}
}
而上面所说的match中加and的查询,对应于bool查询,转化后为 term+must 的语法如下,
{
"match": {
"title": {
"query": "java elasticsearch",
"operator": "and"
}
}
}
{
"bool": {
"must": [
{ "term": { "title": "java" }},
{ "term": { "title": "elasticsearch" }}
]
}
}
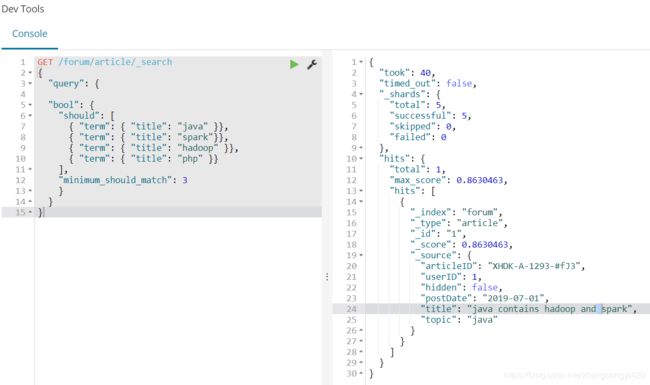
对于minimum_should_match这种语法来说,道理类似,
{
"match": {
"title": {
"query": "java elasticsearch hadoop spark",
"minimum_should_match": "75%"
}
}
}
{
"bool": {
"should": [
{ "term": { "title": "java" }},
{ "term": { "title": "elasticsearch" }},
{ "term": { "title": "hadoop" }},
{ "term": { "title": "spark" }}
],
"minimum_should_match": 3
}
}
我们来看一个具体的操作实例,也就是说必须至少包含3个关键词的数据才会出现在搜索结果中,
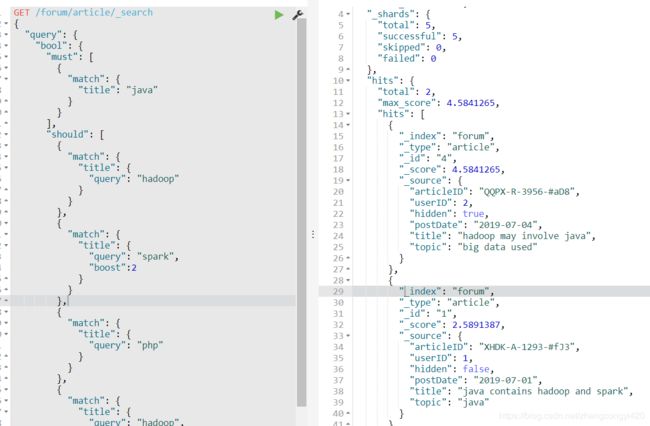
3、在搜索中,我们有这样一种需求,期望搜索的结果中包含java 如果标题中包含hadoop或spark就优先搜索出来,同时呢,如果一个帖子包含java hadoop,一个帖子包含java spark,包含hadoop的帖子要比spark优先搜索出来,
对于这样的需求,通俗来讲,就是需要通过增大某些搜索条件的权重,从而在搜索的结果中,更多符合和满足我们业务场景的数据靠前搜索出来,在es中可以通过boost关键词来增加搜索条件的权重,
GET /forum/article/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "java"
}
}
],
"should": [
{
"match": {
"title": {
"query": "hadoop"
}
}
},
{
"match": {
"title": {
"query": "spark",
"boost":2
}
}
},
{
"match": {
"title": {
"query": "php"
}
}
},
{
"match": {
"title": {
"query": "hadoop",
"boost": 5
}
}
}
]
}
}
}
上面这个例子意思是我们赋予搜索的title中包含hadoop的条件权重更大,hadoop的结果会有限被搜索出来
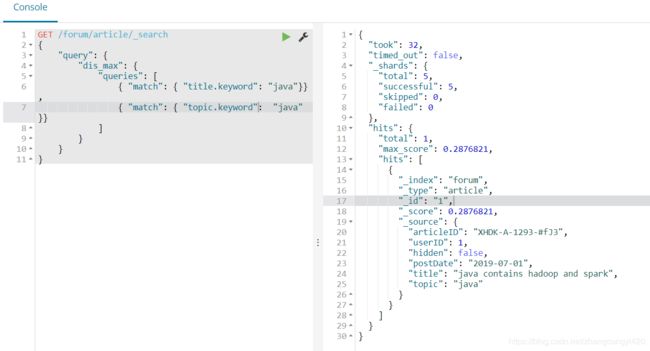
4、dis_max语法,也叫best_field,在某些情况下,假如我们在bool查询中用多个字段进行查询,但是查询一样,就可能导致说查询出来的结果并不是按照我们期望的那个字段将其排在前面,也就是说,我们只需要包含指定字段的内容展示在前面,如下,
GET /forum/article/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "java solution" }},
{ "match": { "content": "java solution" }}
]
}
}
}
title和content的搜索条件相同,但我们希望的是结果中title 包含java solution的靠前展示,但直接这样查询可能达不到预期的效果,如果使用dis_max进行拼接就可以了,
GET /forum/article/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "java solution" }},
{ "match": { "content": "java solution" }}
]
}
}
}
通过这样的方式,使得查询的结果更符合预期值,
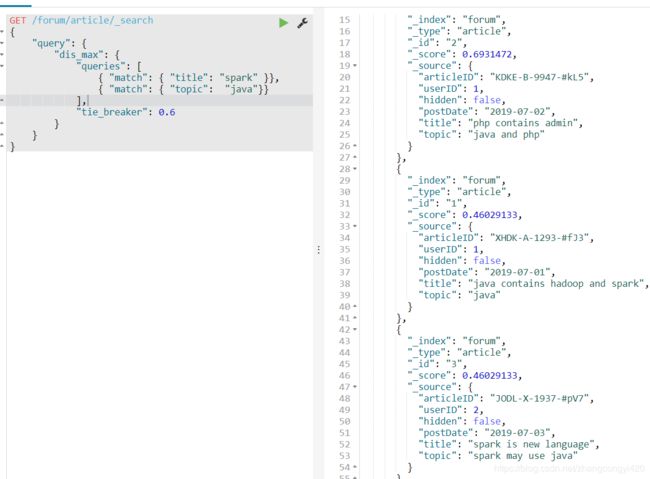
5、但是使用dis_max,只取某一个query最大的分数,完全不考虑其他query的分数,即假如说某个结果中包title含了java,但topic中没有包含java,另一却是相反,还有的结果是两者都包含java,在dis_max语法下,只会拿到相关度得分最高的那一个,而不会考虑其他的结果,这时,如果需要获取其他的title或者topic包含java的结果,可以使用tie_breaker进一步包装,如下,
GET /forum/article/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "spark" }},
{ "match": { "topic": "java"}}
],
"tie_breaker": 0.6
}
}
}
这样查到3条结果,综合来说,最终还是需要结合实际业务场景进行使用,但是在大多数情况相爱,我们还是希望搜索的结果中是按照我们给定的条件包含更多的关键词的内容被优先搜索出来,
本篇的内容比较多,到这里就结束了,最后,感谢观看!