基于Docker的Spark环境搭建理论部分
1.镜像制作方案
我们要使用Docker来搭建hadoop,spark,hive及mysql集群,首先使用Dockerfile制作镜像,把相关的软件拷贝到约定好的目录下,把配置文件在外面先配置好,再使用docker and / docker run,拷贝移动到hadoop,spark,hive的配置目录。需要注意一点在spark中读取hive中的数据,需要把配置文件hive-site.xml拷贝到spark的conf目录(Spark在读取Hive表时,会从hive-site.xml要与Hive配置通信)此外,为了能使得mysql能从其他节点被访问到(要用mysql存储Hive元数据),要配置mysql的访问权限。
如果在容器里面配置文件,当我们使用docker rm将容器删除之后,容器里的内容如果没有使用docker commit更新到镜像中,删除后容器里的配置会全部丢失。
2.集群整体架构设计
一共5个节点,即启动5个容器。hadoop-maste,hadoop-node1,hadoop-node2这三个容器里面安装hadoop和spark集群,hadoop-hive这个容器安装Hive,hadoop-mysql这个容器安装mysql数据库。
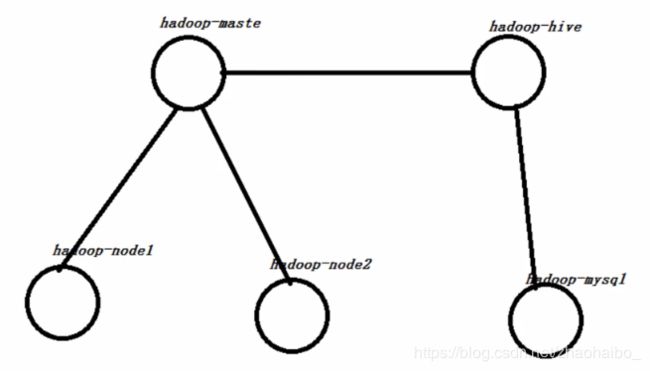
Spark中可以在SparkSession中的builder中通过enableHiveSupport()方法,启用对hive数据仓库表操作的支持。Mysql用于保存hive的元数据。当然spark中的DataFrame也可以通过write方法将数据写入Mysql中。
3. 集群网络规划及子网配置
网络可以通过Docker中的DockerNetworking的支持配置。首先设置网络,docker中设置子网可以通过docker network create方法,这里我们通过名利设置如下的子网。
docker network create --subnet=172.16.0.0/16 spark
–subnet制定自网络的网段,并为这个子网明明一个名字叫做spark.
接下来在我们创建的自网络spark中规划集群中每个容器的ip地址。网络ip分配如下:
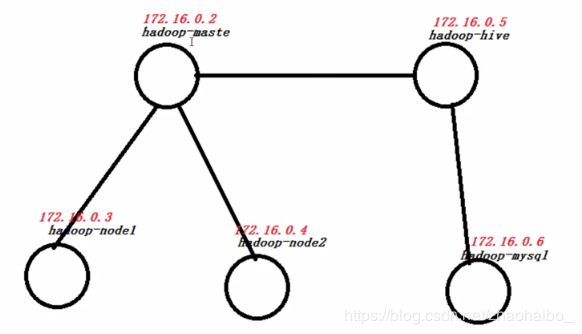
注意:5个容器的hostname都是以hadoop-*开头,因为我们要配置容器之间的SSH密钥登陆,在不生成id_rsa.pub公钥的条件下,我们可以通过配置SSH过滤规则来配置容器间的互通信。
4.软件版本
Spark:最新版本2.3.0
Hadoop:采用稳定的hadoop-2.7.3
Hive:最新的稳定版本hive-2.3.2
Scala:Scala-2.11.8
JDK:jdk-8u101-linux-x64
Mysql:mysql-5.5.45-linux2.6-x86_64
Hive和Spark连接Mysql的驱动程序:mysql-connector-java-5.1.37-bin.jar
5.SSH无密钥登陆规则配置
这里不使用ssh-keygen -t rsa -P这种方式生成id_rsa.pub,然后集群节点互拷贝id_rsa.pub到authorized_keys文件 ,而是通过在.ssh目录下配置ssh_conf文件的方式,ssh_conf中可以配置SSH的通信规则。
ssh_conf配置内容:
Host localhost
StrictHostKeyChecking no
Host 0.0.0.0
StrictHostKeyChecking no
Host hadoop-*
StrictHostKeyChecking no
6.Hadoop、HDFS、Yarn配置文件
hadoop的配置文件位于HADOOP_HOME/etc/hadoop文件下,重要的配置文件有core-site.xml hadoop-env.sh hdfs-site.xml mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml master slaves这九个配置文件。
其中core-site.xml用于配置hadoop默认的文件系统的访问路径,访问文件系统的用户及用户组等相关的配置。core-site.xml配置如下
fs.defaultFS
hdfs://hadoop-maste:9000/
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
hadoop.proxyuser.oozie.hosts
*
hadoop.proxyuser.oozie.groups
*
hadoop-env.sh这个配置文件用来匹配hadoop与逆行依赖的JDK环境,及一些JVM参数的配置,除了JDK路径的配置外,其他的我们不用管,内容如下:
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Set Hadoop-specific environment variables here.
# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use.
# 这里需要特殊配置! 导入JAVA_HOME
export JAVA_HOME=/usr/local/jdk1.8.0_101
# The jsvc implementation to use. Jsvc is required to run secure datanodes
# that bind to privileged ports to provide authentication of data transfer
# protocol. Jsvc is not required if SASL is configured for authentication of
# data transfer protocol using non-privileged ports.
#export JSVC_HOME=${JSVC_HOME}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
# Extra Java CLASSPATH elements. Automatically insert capacity-scheduler.
for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do
if [ "$HADOOP_CLASSPATH" ]; then
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f
else
export HADOOP_CLASSPATH=$f
fi
done
# The maximum amount of heap to use, in MB. Default is 1000.
#export HADOOP_HEAPSIZE=
#export HADOOP_NAMENODE_INIT_HEAPSIZE=""
# Extra Java runtime options. Empty by default.
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
# Command specific options appended to HADOOP_OPTS when specified
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS"
export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS"
export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS"
# The following applies to multiple commands (fs, dfs, fsck, distcp etc)
export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS"
#HADOOP_JAVA_PLATFORM_OPTS="-XX:-UsePerfData $HADOOP_JAVA_PLATFORM_OPTS"
# On secure datanodes, user to run the datanode as after dropping privileges.
# This **MUST** be uncommented to enable secure HDFS if using privileged ports
# to provide authentication of data transfer protocol. This **MUST NOT** be
# defined if SASL is configured for authentication of data transfer protocol
# using non-privileged ports.
export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER}
# Where log files are stored. $HADOOP_HOME/logs by default.
#export HADOOP_LOG_DIR=${HADOOP_LOG_DIR}/$USER
# Where log files are stored in the secure data environment.
export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER}
###
# HDFS Mover specific parameters
###
# Specify the JVM options to be used when starting the HDFS Mover.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# export HADOOP_MOVER_OPTS=""
###
# Advanced Users Only!
###
# The directory where pid files are stored. /tmp by default.
# NOTE: this should be set to a directory that can only be written to by
# the user that will run the hadoop daemons. Otherwise there is the
# potential for a symlink attack.
export HADOOP_PID_DIR=${HADOOP_PID_DIR}
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}
# A string representing this instance of hadoop. $USER by default.
export HADOOP_IDENT_STRING=$USER
之后配置hdfs-site.xml,它主要用来配置hdfs分布式文件系统的namenode即datanode数据的存储路径,及数据区块的冗余数。
dfs.namenode.name.dir
file:/usr/local/hadoop2.7/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop2.7/dfs/data
dfs.webhdfs.enabled
true
dfs.replication
2
dfs.permissions.enabled
false
mapred-env.sh和mapred-site.xml这两个配置文件是对mapreduce计算框架的运行环境参数及网络的配置文件,因为我们不会用到mapreduce,因为它的计算性能不如spark。
mapred-site.xml配置
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop-maste:10020
mapreduce.map.memory.mb
4096
mapreduce.reduce.memory.mb
8192
yarn.app.mapreduce.am.staging-dir
/stage
mapreduce.jobhistory.done-dir
/mr-history/done
mapreduce.jobhistory.intermediate-done-dir
/mr-history/tmp
对于Yarn的配置有yarn-env.sh和0yarn-site.xml两个配置文件,yarn是hadoop的任务调度系统,从配置文件的名字可以看出,他们分别用于yarn运行环境的配置及网络的配置。yarn-env.sh中会读取JAVA_HOME环境变量,还会设置一些默认的jdk参数,因此通常情况下我们都不用修改yarn-env.sh这个配置文件。
yarn-site.xml配置
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce_shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.hostname
hadoop-maste
yarn.resourcemanager.address
hadoop-maste:8032
yarn.resourcemanager.scheduler.address
hadoop-maste:8030
yarn.resourcemanager.resource-tracker.address
hadoop-maste:8035
yarn.resourcemanager.admin.address
hadoop-maste:8033
yarn.resourcemanager.webapp.address
hadoop-maste:8088
yarn.log-aggregation-enable
true
yarn.nodemanager.vmem-pmem-ratio
5
yarn.nodemanager.resource.memory-mb
22528
每个节点可用内存,单位MB
yarn.scheduler.minimum-allocation-mb
4096
单个任务可申请最少内存,默认1024MB
yarn.scheduler.maximum-allocation-mb
16384
单个任务可申请最大内存,默认8192MB
最后是master和slaves两个配置文件。hadoop是一个master-slave结构的分布式系统,制定哪个节点为master节点,哪些节点为slave节点的方案是通过master和slaves两个配置文件决定的。
master配置文件:
hadoop-maste
即指定master主节点运行在网络规划中的hadoop-maste这个hostname对应的容器中。
slaves配置文件:
hadoop-node1
hadoop-node2
即指定slaves节点分别为hadoop-node1和hadoop-node2,在这两个容器中将会启动Hdfs对应的DataNode进程及YARN资源管理系统启动的NodeManager进程。
7. Spark配置文件
主要有masters slaves spark-defaults.conf spark-env.sh
masters配置
hadoop-maste
slaves配置
hadoop-node1
hadoop-node2
spark-defaults.conf配置
spark.executor.memory=2G
spark.driver.memory=2G
spark.executor.cores=2
#spark.sql.codegen.wholeStage=false
#spark.memory.offHeap.enabled=true
#spark.memory.offHeap.size=4G
#spark.memory.fraction=0.9
#spark.memory.storageFraction=0.01
#spark.kryoserializer.buffer.max=64m
#spark.shuffle.manager=sort
#spark.sql.shuffle.partitions=600
spark.speculation=true
spark.speculation.interval=5000
spark.speculation.quantile=0.9
spark.speculation.multiplier=2
spark.default.parallelism=1000
spark.driver.maxResultSize=1g
#spark.rdd.compress=false
spark.task.maxFailures=8
spark.network.timeout=300
spark.yarn.max.executor.failures=200
spark.shuffle.service.enabled=true
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.minExecutors=4
spark.dynamicAllocation.maxExecutors=8
spark.dynamicAllocation.executorIdleTimeout=60
#spark.serializer=org.apache.spark.serializer.JavaSerializer
#spark.sql.adaptive.enabled=true
#spark.sql.adaptive.shuffle.targetPostShuffleInputSize=100000000
#spark.sql.adaptive.minNumPostShufflePartitions=1
##for spark2.0
#spark.sql.hive.verifyPartitionPath=true
#spark.sql.warehouse.dir
spark.sql.warehouse.dir=/spark/warehouse
spark-env.sh配置
#!/usr/bin/env bash
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# This file is sourced when running various Spark programs.
# Copy it as spark-env.sh and edit that to configure Spark for your site.
# Options read when launching programs locally with
# ./bin/run-example or ./bin/spark-submit
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public dns name of the driver program
# Options read by executors and drivers running inside the cluster
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public DNS name of the driver program
# - SPARK_LOCAL_DIRS, storage directories to use on this node for shuffle and RDD data
# - MESOS_NATIVE_JAVA_LIBRARY, to point to your libmesos.so if you use Mesos
# Options read in YARN client mode
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - SPARK_EXECUTOR_CORES, Number of cores for the executors (Default: 1).
# - SPARK_EXECUTOR_MEMORY, Memory per Executor (e.g. 1000M, 2G) (Default: 1G)
# - SPARK_DRIVER_MEMORY, Memory for Driver (e.g. 1000M, 2G) (Default: 1G)
# Options for the daemons used in the standalone deploy mode
# - SPARK_MASTER_HOST, to bind the master to a different IP address or hostname
# - SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, to use non-default ports for the master
# - SPARK_MASTER_OPTS, to set config properties only for the master (e.g. "-Dx=y")
# - SPARK_WORKER_CORES, to set the number of cores to use on this machine
# - SPARK_WORKER_MEMORY, to set how much total memory workers have to give executors (e.g. 1000m, 2g)
# - SPARK_WORKER_PORT / SPARK_WORKER_WEBUI_PORT, to use non-default ports for the worker
# - SPARK_WORKER_DIR, to set the working directory of worker processes
# - SPARK_WORKER_OPTS, to set config properties only for the worker (e.g. "-Dx=y")
# - SPARK_DAEMON_MEMORY, to allocate to the master, worker and history server themselves (default: 1g).
# - SPARK_HISTORY_OPTS, to set config properties only for the history server (e.g. "-Dx=y")
# - SPARK_SHUFFLE_OPTS, to set config properties only for the external shuffle service (e.g. "-Dx=y")
# - SPARK_DAEMON_JAVA_OPTS, to set config properties for all daemons (e.g. "-Dx=y")
# - SPARK_PUBLIC_DNS, to set the public dns name of the master or workers
# Generic options for the daemons used in the standalone deploy mode
# - SPARK_CONF_DIR Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - SPARK_LOG_DIR Where log files are stored. (Default: ${SPARK_HOME}/logs)
# - SPARK_PID_DIR Where the pid file is stored. (Default: /tmp)
# - SPARK_IDENT_STRING A string representing this instance of spark. (Default: $USER)
# - SPARK_NICENESS The scheduling priority for daemons. (Default: 0)
# - SPARK_NO_DAEMONIZE Run the proposed command in the foreground. It will not output a PID file.
SPARK_MASTER_WEBUI_PORT=8888
export SPARK_HOME=$SPARK_HOME
export HADOOP_HOME=$HADOOP_HOME
export MASTER=spark://hadoop-maste:7077
export SCALA_HOME=$SCALA_HOME
export SPARK_MASTER_HOST=hadoop-maste
export JAVA_HOME=/usr/local/jdk1.8.0_101
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
#SPARK_LOCAL_DIRS=/home/spark/softwares/spark/local_dir
8.Hive配置文件
Hive是一个支持SQL语句的数据仓库,SparkSQL之前的版本曾经使用过Hive底层的SQL解释器及优化器,因此Spark自然也是支持读写Hive表格的,前提条件是在Spark中使用enableHiveSupport指令。
需要注意,Hive的配置文件hive-site.xml需要放到$SPARK_HOME/conf目录下,这样Spark在操作Hive的时候才能找到相应的Hive的通信地址。Hive中重要的配置文件包括hive-site.xml和hive-env.sh两个配置文件。
hive-site.xml配置:
hive.metastore.warehouse.dir
/home/hive/warehouse
hive.exec.scratchdir
/tmp/hive
hive.metastore.uris
thrift://hadoop-hive:9083
Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.
hive.server2.transport.mode
http
hive.server2.thrift.http.port
10001
javax.jdo.option.ConnectionURL
jdbc:mysql://hadoop-mysql:3306/hive?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
root
hive.metastore.schema.verification
false
hive.server2.authentication
NONE
在配置文件中,通过javax.jdo.option.ConnectionURL配置选项指定了Hive元数据存放的关系型数据库mysql的存储地址。通过javax.jdo.option.ConnectionDriverName指定驱动,通过hive.metastore.warehouse.dir指定仓库在HDFS中的存放位置。hive.matastore.uris指定Hive元数据访问的通信地址,使用的是thrift协议。javax.jdo.option.ConnectionUserName指定连接数据库的用户名,javax.jdo.option.ConnectionPassword指定数据库的密码。
关于hive-env.sh配置文件,因为Hive的数据要存储在HDFS中,那Hive怎么和Hadoop通信呢 ?Hive的解决方案是在hive-env.sh中加入Hadoop的路径,这样Hive就会从Hadoop的路径下去寻找配置文件呢,就剋找到和Hadoop中HDFS通信的信息,从而完成Hive和Hadoop的通信。
hive-env.sh配置:
HADOOP_HOME=/usr/local/hadoop-2.7.3
9.其他配置
豆瓣pip源配置
这个配置用于为国内节点pip加速。
新建pip.conf文件,添加:
[global]
index-url = http://pypi.douban.com/simple
trusted-host = pypi.douban.com
将pip.conf文件放到 /.pip/pip.conf文件夹中,制作镜像时先新建/.pip文件夹,然后把config目录中已经配置好的pip.conf mv到~/.pip文件夹中。
profile
这个配置用于配置系统环境变量。profile配置文件位于/etc/profile,我们需要把hadoop,spark,hive,jdk,scala,mysql的环境变量配hi在这里
# /etc/profile: system-wide .profile file for the Bourne shell (sh(1))
# and Bourne compatible shells (bash(1), ksh(1), ash(1), ...).
if [ "$PS1" ]; then
if [ "$BASH" ] && [ "$BASH" != "/bin/sh" ]; then
# The file bash.bashrc already sets the default PS1.
# PS1='\h:\w\$ '
if [ -f /etc/bash.bashrc ]; then
. /etc/bash.bashrc
fi
else
if [ "`id -u`" -eq 0 ]; then
PS1='# '
else
PS1='$ '
fi
fi
fi
if [ -d /etc/profile.d ]; then
for i in /etc/profile.d/*.sh; do
if [ -r $i ]; then
. $i
fi
done
unset i
fi
export JAVA_HOME=/usr/local/jdk1.8.0_101
export SCALA_HOME=/usr/local/scala-2.11.8
export HADOOP_HOME=/usr/local/hadoop-2.7.3
export SPARK_HOME=/usr/local/spark-2.3.0-bin-hadoop2.7
export HIVE_HOME=/usr/local/apache-hive-2.3.2-bin
export MYSQL_HOME=/usr/local/mysql
export PATH=$HIVE_HOME/bin:$MYSQL_HOME/bin:$JAVA_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$SPARK_HOME/bin:$PATH
分别将JAVA_HOME,SCALA_HOME,HADOOP_HOME,SPARK_HOME,HIVE_HOME,MYSQL_HOME添加到PATH中,在制作镜像时,需要把profile文件COPY到/etc/profile。profile的目的时防止Dockerfile中通过ENV命令设置环境变量不成功。
restart_containers.sh, start_containers.sh, stop_containers.sh
这几个脚本用来启动、重启、停止容器。也是一键启动,重启,关闭容器集群的脚本。
Dockerfile制作镜像的核心文件
FROM ubuntu
MAINTAINER reganzm [email protected]
ENV BUILD_ON 2018-03-04
COPY config /tmp
#RUN mv /tmp/apt.conf /etc/apt/
RUN mkdir -p ~/.pip/
RUN mv /tmp/pip.conf ~/.pip/pip.conf
RUN apt-get update -qqy
RUN apt-get -qqy install netcat-traditional vim wget net-tools iputils-ping openssh-server python-pip libaio-dev apt-utils
RUN pip install pandas numpy matplotlib sklearn seaborn scipy tensorflow gensim
#添加JDK
ADD ./jdk-8u101-linux-x64.tar.gz /usr/local/
#添加hadoop
ADD ./hadoop-2.7.3.tar.gz /usr/local
#添加scala
ADD ./scala-2.11.8.tgz /usr/local
#添加spark
ADD ./spark-2.3.0-bin-hadoop2.7.tgz /usr/local
#添加mysql
ADD ./mysql-5.5.45-linux2.6-x86_64.tar.gz /usr/local
RUN mv /usr/local/mysql-5.5.45-linux2.6-x86_64 /usr/local/mysql
ENV MYSQL_HOME /usr/local/mysql
#添加hive
ADD ./apache-hive-2.3.2-bin.tar.gz /usr/local
ENV HIVE_HOME /usr/local/apache-hive-2.3.2-bin
RUN echo "HADOOP_HOME=/usr/local/hadoop-2.7.3" | cat >> /usr/local/apache-hive-2.3.2-bin/conf/hive-env.sh
#添加mysql-connector-java-5.1.37-bin.jar到hive的lib目录中
ADD ./mysql-connector-java-5.1.37-bin.jar /usr/local/apache-hive-2.3.2-bin/lib
RUN cp /usr/local/apache-hive-2.3.2-bin/lib/mysql-connector-java-5.1.37-bin.jar /usr/local/spark-2.3.0-bin-hadoop2.7/jars
#增加JAVA_HOME环境变量
ENV JAVA_HOME /usr/local/jdk1.8.0_101
#hadoop环境变量
ENV HADOOP_HOME /usr/local/hadoop-2.7.3
#scala环境变量
ENV SCALA_HOME /usr/local/scala-2.11.8
#spark环境变量
ENV SPARK_HOME /usr/local/spark-2.3.0-bin-hadoop2.7
#将环境变量添加到系统变量中
ENV PATH $HIVE_HOME/bin:$MYSQL_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$HADOOP_HOME/bin:$JAVA_HOME/bin:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$PATH
RUN ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' && \
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys && \
chmod 600 ~/.ssh/authorized_keys
COPY config /tmp
#将配置移动到正确的位置
RUN mv /tmp/ssh_config ~/.ssh/config && \
mv /tmp/profile /etc/profile && \
mv /tmp/masters $SPARK_HOME/conf/masters && \
cp /tmp/slaves $SPARK_HOME/conf/ && \
mv /tmp/spark-defaults.conf $SPARK_HOME/conf/spark-defaults.conf && \
mv /tmp/spark-env.sh $SPARK_HOME/conf/spark-env.sh && \
cp /tmp/hive-site.xml $SPARK_HOME/conf/hive-site.xml && \
mv /tmp/hive-site.xml $HIVE_HOME/conf/hive-site.xml && \
mv /tmp/hadoop-env.sh $HADOOP_HOME/etc/hadoop/hadoop-env.sh && \
mv /tmp/hdfs-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml && \
mv /tmp/core-site.xml $HADOOP_HOME/etc/hadoop/core-site.xml && \
mv /tmp/yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml && \
mv /tmp/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml && \
mv /tmp/master $HADOOP_HOME/etc/hadoop/master && \
mv /tmp/slaves $HADOOP_HOME/etc/hadoop/slaves && \
mv /tmp/start-hadoop.sh ~/start-hadoop.sh && \
mkdir -p /usr/local/hadoop2.7/dfs/data && \
mkdir -p /usr/local/hadoop2.7/dfs/name && \
mv /tmp/init_mysql.sh ~/init_mysql.sh && chmod 700 ~/init_mysql.sh && \
mv /tmp/init_hive.sh ~/init_hive.sh && chmod 700 ~/init_hive.sh && \
mv /tmp/restart-hadoop.sh ~/restart-hadoop.sh && chmod 700 ~/restart-hadoop.sh
RUN echo $JAVA_HOME
#设置工作目录
WORKDIR /root
#启动sshd服务
RUN /etc/init.d/ssh start
#修改start-hadoop.sh权限为700
RUN chmod 700 start-hadoop.sh
#修改root密码
RUN echo "root:111111" | chpasswd
CMD ["/bin/bash"]