- 《经年驯养》黎栀傅谨臣(高分女频)全章节在线阅读
云轩书阁
《经年驯养》黎栀傅谨臣(高分女频)全章节在线阅读主角:黎栀傅谨臣简介:傅谨臣养大黎栀,对她有求必应,黎栀以为那是爱。结婚两年才发现,她不过他豢养最好的一只宠物,可她拿他当全世界。关注微信公众号【看精灵】去回个书號【9328】,即可阅读【经年驯养】小说全文!第10章温柔的眼神,宠溺的动作,留恋的话近乎情人低语。是黎栀做梦都想要的一切……她口干舌燥,紧张难言。一颗心似被浸泡在温水里,酥麻舒适,无可抗拒
- 《前夫如龙》王昊江琼(独家小说)精彩TXT阅读
海边书楼
《前夫如龙》王昊江琼(独家小说)精彩TXT阅读主角:王昊江琼简介:离婚那天,她视他如泥土。谁曾想,消息一出,天下震动!可关注微信公众号【风车文楼】去回个书号【203】,即可免费阅读【前夫如龙】全文!江芸并未听出华少龙声音里的冷漠,依旧一脸笑容道:“是啊,那个废物哪儿配得上我姐?这些年,我姐对他仁至义尽了。以后,华少爷可以多跟我姐接触接触,只有华少爷这样的人,才配得上我姐啊!”江琼低着头,微微有些娇
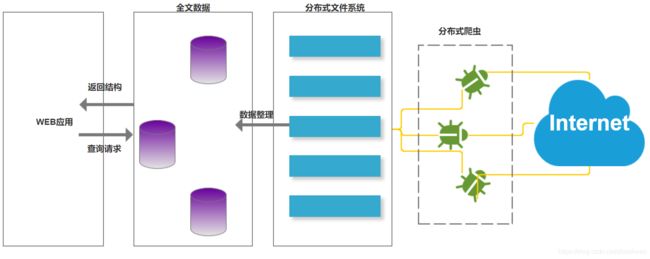
- Java爬虫框架(一)--架构设计
狼图腾-狼之传说
java框架java任务html解析器存储电子商务
一、架构图那里搜网络爬虫框架主要针对电子商务网站进行数据爬取,分析,存储,索引。爬虫:爬虫负责爬取,解析,处理电子商务网站的网页的内容数据库:存储商品信息索引:商品的全文搜索索引Task队列:需要爬取的网页列表Visited表:已经爬取过的网页列表爬虫监控平台:web平台可以启动,停止爬虫,管理爬虫,task队列,visited表。二、爬虫1.流程1)Scheduler启动爬虫器,TaskMast
- Java:爬虫框架
dingcho
Javajava爬虫
一、ApacheNutch2【参考地址】Nutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。Nutch致力于让每个人能很容易,同时花费很少就可以配置世界一流的Web搜索引擎.为了完成这一宏伟的目标,Nutch必须能够做到:每个月取几十亿网页为这些网页维护一个索引对索引文件进行每秒上千次的搜索提供高质量的搜索结果简单来说Nutch支持分
- 《错嫁傻王:王妃她又黑化了》南君宥乔洛染(独家小说)精彩TXT阅读
海边书楼
《错嫁傻王:王妃她又黑化了》南君宥乔洛染(独家小说)精彩TXT阅读主角:南君宥乔洛染简介:堂堂21世纪金牌特种兵乔洛染,穿来的第一天,就被人诬陷私通被逼投江。而前来解救她的,正是她的夫婿——智力受损的痴傻王爷南君宥。傻子娶了一个不贞女,全京城都在等着看他们的笑话。殊不知,乔洛染一手医术济天下,一手制毒退万敌。关注微信公众号【花车文学】去回个书號【36】,即可阅读【错嫁傻王:王妃她又黑化了】小说全文
- 《花都狂少》章小贝小说免费阅读【花都狂少TXT】完整版
九月文楼
《花都狂少》章小贝小说免费阅读【花都狂少TXT】完整版主角:章小贝简介:开光师,是一种专门给新娘破瓜的职业。在我们那里,我被逼着做了一名开光师,专门做那些新郎官不敢做的事。一开始我很抵触,更怕早死。可是当我真的做了一次以后,就开始欲罢不能起来。小姐姐,别走,今晚,破瓜!关注微信公众号【风车文楼】去回个书号【267】,即可阅读【花都狂少】小说全文!“你怎么流鼻血了?”灵琴清惊讶的问。咳咳,我尴尬的咳
- 浅评《记忆像铁轨一样长》中的修辞手法
后会定无期
《记忆像铁轨一样长》是已逝世的余光中先生在一九八四年创作的一篇散文,后成为其代表作之一。余光中先生作为著名的作家、诗人和翻译家,素有文坛“璀璨五彩笔”、“诗文双绝”和“诗坛最后的守夜人”等美誉。《记忆像铁轨一样长》这篇散文也继承了作者一贯的风格,全文语言优美隽永,结构清晰紧凑,节奏张弛有度,想象天马行空,感情细腻真挚。其中运用了大量的修辞手法,或新颖巧妙,或生动有趣,用词准确灵活,给读者留下了深刻
- app推广一手资源在哪里找?盘点2024年必备的八大app拉新渠道
U客直谈APP
在2024年即将来临之际,还是有许多小伙伴表示不知道app推广一手资源在哪里找,又要从哪里去了解各个资源渠道的不同特性。好消息来啦,本篇文章就将带大家盘点24年必备的八大app拉新渠道,全文干货,拆解分析点评一步到位,还不快快收藏起来~1.app推广一手资源来源:U客直谈U客直谈是一个资源对接平台,专注于为推广人员提供海量丰富的app拉新任务。其具有数量丰富且类型多样的app拉新任务,使得U客直谈
- (已完结小说)--《我的美女上司》王鹏--(全文免费阅读)
小说推书
(已完结小说)--《我的美女上司》王鹏--(全文免费阅读)主角:王鹏简介:王鹏,第一天上班,发现他竟然成为了自己公司董事长的男人!!关注微信公众号【小北文楼】去回个书号【47】,即可阅读【我的美女上司】小说全文!“九亿元,确实有资本炫耀……”白蒹葭张开杏目,笑脸盈盈的看向王鹏,岂料,王鹏却开口纠正她说:“不是九亿元,是二十七亿元。”王鹏此言一出,全场再度哗然,二十七亿元的销售额,这是多么大一笔业绩
- (已完结小说)--《完美盛宴/无缺盛宴》刘洋姜海燕--(全文免费阅读)
九月文楼
(已完结小说)--《完美盛宴/无缺盛宴》刘洋姜海燕--(全文免费阅读)主角:刘洋姜海燕简介:女朋友背叛,倒霉男人刘洋又得罪了美女上司,看他如何拯救自己的事业,创造一段传奇……关注微信公众号【寒风书楼】去回个书号【263】,即可阅读【完美盛宴】小说全文!第6章:就这样走了?刘洋心里微微一动,也起身说道:“姐,咱们要是在一起时间长了,你就会发现我不是有两下子,而是还有好几下子呢……”“咯咯,说你胖你还
- 最新小说《美女老婆种回家》吴敏霍小燕&全文阅读无删减
小说推书
最新小说《美女老婆种回家》吴敏霍小燕&全文阅读无删减主角:吴敏霍小燕简介:在我的老家农村倒是经常听到老人们说起这种事情,或是某人没生育能力,然后找个族亲的同辈来传宗接代。可以关注微信公众号【小北文楼】去回个书号【53】,即可免费阅读【美女老婆种回家】小说全文!晚上,我熬了半个通宵,做出了一个自我感觉很是完美的企划案,第二天我兴冲冲的来到公司打算交给经理请功,没想到刚到经理办公室门口,就听到了秘书小
- 《大小姐她疯批又娇惹,侍卫动心了》虞洛厉骁全文免费阅读完整版
云轩书阁
《大小姐她疯批又娇惹,侍卫动心了》虞洛厉骁全文免费阅读完整版主角:虞洛厉骁简介:“我这是,穿书了?”救命!穿书就穿书吧,怎么还穿成了虐男主千百遍的疯批女配?关注微信公众号【旺精灵】去回个书號【7733】,即可阅读【大小姐她疯批又娇惹,侍卫动心了】小说全文!第10章:虞洛差不多有些困了,在书中的生活比她在现实生活中难熬多了。她现在只想爬上床睡一觉。说不定睁开眼睛之后,会发现这里的一切只是一场梦。把所
- 《弃妃要和离,矜持王爷失控了》花芊芊离渊全文免费阅读
海边书楼
《弃妃要和离,矜持王爷失控了》花芊芊离渊全文免费阅读主角:花芊芊离渊简介:前世,她为家人付出一切,却被人弃之敝履。重生后,她果断与眼盲心瞎的丈夫和离,与相府断绝关系。斗婊虐渣,从一个弃妇摇身一变成了各个大佬争相宠爱的国宠。带着疼爱她的外祖一家青云直上。曾经对她弃之敝履的哥哥和前夫们纷纷后悔了,排队求原谅。当发现前一世一直救她护她的人,竟然是她的“大表哥”时,她红了眼,紧紧搂着那人不撒手。欲拒还迎的
- 《撩太子虐白莲重生皇妃太野》苏卿月(完结小说)&全文在线阅读【无弹窗】
寒风书楼
《撩太子虐白莲重生皇妃太野》苏卿月(完结小说)&全文在线阅读【无弹窗】主角:苏卿月简介:前世她信了苏筱芸的伪善,落得个声名扫地、清誉全毁、家人遗弃、万人嫌恶的下场!关注微信公众号【海边书楼】去回个书号【158】,即可阅读【撩太子虐白莲重生皇妃太野】小说全文!不过片刻,前厅便只母女三人。思及苏卿月刚回来,姐妹二人正是联络感情的好时机,柳兰烟笑道:“芸儿,晚儿刚回来,对府里还不熟悉,不如你带她去逛逛,
- 《傲世龙帝》陆离柳诗雨(独家小说)精彩章节TXT阅读
寒风书楼
《傲世龙帝》陆离柳诗雨(独家小说)精彩章节TXT阅读主角:陆离柳诗雨简介:他奉师命从神农架下山,遇到清纯可人的大小姐,冷傲的女总裁,医术、毒经、加上至尊实力,让他龙腾宇内,一手针法可救苍生,一手毒术可灭万敌,这天下,他一人可睥睨!可以关注微信公众号【九月文楼】去回个书號【167】,即可免费阅读【傲世龙帝】小说全文!陆离脸色越来越阴沉,他倒不是多喜欢这个慕容晚晴,毕竟,他只是听师傅说有这么一个未婚妻
- 言情小说《恶毒原配不作了,冷面军爷宠上天》孟晚棠&全文阅读笔趣阁
寒风书楼
言情小说《恶毒原配不作了,冷面军爷宠上天》孟晚棠&全文阅读笔趣阁主角:孟晚棠简介:孟晚棠穿到一本三观炸裂的书里,成了里面恶毒愚蠢,虐待崽崽,冷暴力丈夫的坏女人。上辈子笑话人家亲戚都是极品,这下好了,她成了那个极品。没关系,反正白捡一条命,从头开始就是。婆媳关系恶劣?妯娌之间更是水火不容?母子关系岌岌可危?慢慢来。至于退伍回来,没工作冷面丈夫,自然不能赶出去,那就养好伤再一起赚钱养家呗。谁知道这家伙
- 拆解罗振宇跨年演讲2019《时间的朋友》
筝小钱
写在前面:演讲稿未删减版4万字,建议阅读时分章节阅读,一次一节。随时记录自己读完想到了哪些,对读不懂的暂时跳过。全文读完仅有1个收获,就不枉费阅读时间。拆解:关于做事和不做事原文:我们不操心行业和公司层面的事,就想想咱们自己。做事的人无所谓悲观还是乐观,我们只关心如何把事做好。我们做事的人都知道:2018年难,哪一年不难?难就不干了吗?最聪明的做法,就是做一个理性乐观派。我们可以了解和关注,作为资
- 《志在千里》陈冰老张全文免费阅读【完结小说无弹窗】
海边书楼
《志在千里》陈冰老张全文免费阅读【完结小说无弹窗】主角:陈冰老张简介:陈冰身材高挑,脸蛋俊俏,气质高雅,一双水灵灵的媚眼性感至极。可关注微信公众号【寒风书楼】去回个书号【285】,即可免费阅读【志在千里】全文!电工老张今年五十出头,最近一直很欣赏雇主少-妇陈冰。陈冰身材高挑,脸蛋俊俏,气质高雅,一双水灵灵的媚眼。这天,陈冰穿着一件吊带丝绸睡衣,她从卧室里走出来,发现丈夫李凯与邻居电工老张并肩坐在沙
- 《快穿: 大佬心尖宠又要作妖了》梨初许言全文在线阅读(完整版)
云轩书阁
《快穿:大佬心尖宠又要作妖了》梨初许言全文在线阅读(完整版)主角:梨初许言简介:我穿越了,但是我给人当了四年舔狗才想起这事。一朝恢复记忆,我一心只想搞钱,至于太子?我可去你的吧!关注微信公众号【旺精灵】去回个书號【9524】,即可阅读【快穿大佬心尖宠又要作妖了】小说全文!第18章:梨初心道不好,抬头望向江星竹,果然对方脸色阴沉,又难过,手不安的捏着她衣裙。目光可怜。梨初安抚的摸摸他脑袋,对着玉佩回
- 麦克白读后感
学号叁拾
最光明的天使也会堕落,可是天使总是光明的;虽然小人全都貌似忠良,可是忠良的一定仍然不失他的本色。倏落秋零之际,黄叶正自凋残。看了辜正坤翻译的麦克白,全文采用了诗歌的形式,文字优美,语句漂亮,只是脑海中一边想着舞台剧一边读这种词总感觉别扭。麦克白作为苏格兰的骁勇大将,在战争大获全胜之后偶遇了三个女巫,女巫预言他会成为韦尔多王爵,又会成为国王。麦克白应该是很开心的吧,在封爵成功之后就告诉了自己的夫人这
- 未来网络体系结构和SDN的研究进展-毕军
拟声的主扬
专题sdn网络结构互联网软件
未来网络体系结构和SDN的研究进展-毕军在讨论互联网体系结构的基础上,毕军介绍未来网络体系结构的主要国际学术研究进展。介绍了软件定义网(SDN)的发展现状,讨论SDN的体系结构,提出一种SDN体系结构的抽象模型。最后,介绍一种未来网络体系结构创新环境(FINE)体系结构。阅读全文和小伙伴们一起来吐槽
- 《替嫁医妃狠翻天》温思语秦砚小说完整版(结局已上线)
云轩书阁
《替嫁医妃狠翻天》温思语秦砚小说完整版(结局已上线)主角:温思语,秦砚简介:一朝穿越,为了保命,温思语无奈替嫁给了被称为煞神的应王——秦砚。可关注微信公众号【才精灵】去回个书號【2864】,即可免费阅读【替嫁医妃狠翻天】小说全文!李管事这笑里藏刀的说话方式,简直让温思语都忍不住在心里竖起大拇指,明明是和和气气的模样,说的话却威胁十足,令人忍不住后背发毛。不愧是煞神身边的人,还真是阎王身边无小鬼啊。
- 《官场之手眼通天》秦峰胡佳芸(完结篇)全文免费阅读【笔趣阁】
海边书楼
《官场之手眼通天》秦峰胡佳芸(完结篇)全文免费阅读【笔趣阁】主角:秦峰胡佳芸简介:做官要有两颗心,一颗是责任心,一颗是良心。且看秦峰一个最偏远乡镇的基层公务员,带着这两颗心怎么在尔虞我诈的权力游戏里一步步走向权力的巅峰。可关注微信公众号【寒风书楼】去回个书号【283】,即可免费阅读【官场之手眼通天】全文!第9章你在等我吗?“听说过,那天我正好路过。”“你看到了没有去救人?”“没有。”秦峰不是个喜欢
- 言情小说《相亲领证后,豪门老公抢着帮我虐渣》沈均衡顾柠(全文免费阅读)
九月文楼
言情小说《相亲领证后,豪门老公抢着帮我虐渣》沈均衡顾柠(全文免费阅读)主角:沈均衡顾柠简介:为了反抗家中的联姻,顾柠随便找了个人闪婚。却不曾想,被大家各种瞧不起的,即将濒临破产的老公,竟然是丰城首富!关注微信公众号【海边书楼】去回个书号【83】,即可阅读【相亲领证后,豪门老公抢着帮我虐渣】小说全文!“沈钧衡,你跑哪儿去了?还有,你怎么放着自己那辆玛莎拉帝不开,把我的小奔开走了?”沈钧衡扫了一眼副驾
- mysql添加索引的sql语句
尼采呀
mysqlsql数据库
1.添加主键索引altertable`table_name`addprimarykey(`column`);2.添加唯一索引altertable`table_name`addunique(`column`);3.添加普通索引altertable`table_name`addindexindex_name(`column`);4.添加全文索引altertable`table_name`addfull
- 在吃鸡排合集24部 半人间合12部
新年lplp
远上白云间38部半人间合12部桃千岁合集16部在吃鸡排合集24部二飞合集7部清冷美人的xx游戏by抹茶冰沙军区大院之狼烟万里1-75金玉王朝1-9部第九部到【1-125章】重生之易南淮全文+番外拍摄指南by小说制作机到最新多面人夫by大樱桃到最新
- Android面试必问的Activity,初阶,中高阶问法,你都掌握了吗?(要求熟读并背诵全文)
chuhe1989
android进阶面试Android开发android面试
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cXs1wGDx-1605843173409)(https://upload-images.jianshu.io/upload_images/24142630-84668ed4a42819ee.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)]Activity
- 《完美盛宴》刘洋姜海燕全文免费阅读【完结小说无弹窗】
小说推书
《完美盛宴》刘洋姜海燕全文免费阅读【完结小说无弹窗】主角:刘洋姜海燕简介:女朋友背叛,倒霉男人刘洋又得罪了美女上司,看他如何拯救自己的事业,创造一段传奇……关注微信公众号【寒风书楼】去回个书号【263】,即可阅读【完美盛宴】小说全文!第8章:我管你爹是谁!刘洋一侧身子躲开他,然后把那女孩子往自己的身后掩了一下,大声说道:“怎么能说没我的事儿呢?这种事情谁看着也不会不管的。人家都说了不…不想和你们在
- SQL 索引的创建和删除以及使用索引的好处
SUMMERENT
javaSQLsql数据库
目录一、创建索引1、alter方式创建索引2、create方式创建索引二、删除索引1、drop方式直接删除索引2、alter方式删除索引三、索引的使用使用索引的好处:索引主要有普通索引、唯一索引、主键索引、外键索引、全文索引、复合索引几种一、创建索引1、alter方式创建索引①普通索引:MySQL中基本索引类型,允许在定义索引的列中插入重复值和空值altertable表名addindex索引名(要
- 《兰香如梦》清欢九溟小说已完结【兰香如梦小说】全文免费阅读
云轩书阁
《兰香如梦》清欢九溟小说已完结【兰香如梦小说】全文免费阅读主角:清欢,九溟简介:她是他养的兰草小仙,为救他不惜一切。可他眼里从未有她······直到小兰草消失不见,上神才惊觉,他早就爱上她了。微信内放心点击【兰香如梦】直接阅读-无弹窗无广告也可以关注微信公众号【才精灵】去回个书號【2350】,即可免费阅读【兰香如梦】全文!炼化心血,需要用到神农鼎。神农鼎如今在天界的玄幽殿,她的姐姐清酒是掌事,清欢
- web前段跨域nginx代理配置
刘正强
nginxcmsWeb
nginx代理配置可参考server部分
server {
listen 80;
server_name localhost;
- spring学习笔记
caoyong
spring
一、概述
a>、核心技术 : IOC与AOP
b>、开发为什么需要面向接口而不是实现
接口降低一个组件与整个系统的藕合程度,当该组件不满足系统需求时,可以很容易的将该组件从系统中替换掉,而不会对整个系统产生大的影响
c>、面向接口编口编程的难点在于如何对接口进行初始化,(使用工厂设计模式)
- Eclipse打开workspace提示工作空间不可用
0624chenhong
eclipse
做项目的时候,难免会用到整个团队的代码,或者上一任同事创建的workspace,
1.电脑切换账号后,Eclipse打开时,会提示Eclipse对应的目录锁定,无法访问,根据提示,找到对应目录,G:\eclipse\configuration\org.eclipse.osgi\.manager,其中文件.fileTableLock提示被锁定。
解决办法,删掉.fileTableLock文件,重
- Javascript 面向对面写法的必要性?
一炮送你回车库
JavaScript
现在Javascript面向对象的方式来写页面很流行,什么纯javascript的mvc框架都出来了:ember
这是javascript层的mvc框架哦,不是j2ee的mvc框架
我想说的是,javascript本来就不是一门面向对象的语言,用它写出来的面向对象的程序,本身就有些别扭,很多人提到js的面向对象首先提的是:复用性。那么我请问你写的js里有多少是可以复用的,用fu
- js array对象的迭代方法
换个号韩国红果果
array
1.forEach 该方法接受一个函数作为参数, 对数组中的每个元素
使用该函数 return 语句失效
function square(num) {
print(num, num * num);
}
var nums = [1,2,3,4,5,6,7,8,9,10];
nums.forEach(square);
2.every 该方法接受一个返回值为布尔类型
- 对Hibernate缓存机制的理解
归来朝歌
session一级缓存对象持久化
在hibernate中session一级缓存机制中,有这么一种情况:
问题描述:我需要new一个对象,对它的几个字段赋值,但是有一些属性并没有进行赋值,然后调用
session.save()方法,在提交事务后,会出现这样的情况:
1:在数据库中有默认属性的字段的值为空
2:既然是持久化对象,为什么在最后对象拿不到默认属性的值?
通过调试后解决方案如下:
对于问题一,如你在数据库里设置了
- WebService调用错误合集
darkranger
webservice
Java.Lang.NoClassDefFoundError: Org/Apache/Commons/Discovery/Tools/DiscoverSingleton
调用接口出错,
一个简单的WebService
import org.apache.axis.client.Call;import org.apache.axis.client.Service;
首先必不可
- JSP和Servlet的中文乱码处理
aijuans
Java Web
JSP和Servlet的中文乱码处理
前几天学习了JSP和Servlet中有关中文乱码的一些问题,写成了博客,今天进行更新一下。应该是可以解决日常的乱码问题了。现在作以下总结希望对需要的人有所帮助。我也是刚学,所以有不足之处希望谅解。
一、表单提交时出现乱码:
在进行表单提交的时候,经常提交一些中文,自然就避免不了出现中文乱码的情况,对于表单来说有两种提交方式:get和post提交方式。所以
- 面试经典六问
atongyeye
工作面试
题记:因为我不善沟通,所以在面试中经常碰壁,看了网上太多面试宝典,基本上不太靠谱。只好自己总结,并试着根据最近工作情况完成个人答案。以备不时之需。
以下是人事了解应聘者情况的最典型的六个问题:
1 简单自我介绍
关于这个问题,主要为了弄清两件事,一是了解应聘者的背景,二是应聘者将这些背景信息组织成合适语言的能力。
我的回答:(针对技术面试回答,如果是人事面试,可以就掌
- contentResolver.query()参数详解
百合不是茶
androidquery()详解
收藏csdn的博客,介绍的比较详细,新手值得一看 1.获取联系人姓名
一个简单的例子,这个函数获取设备上所有的联系人ID和联系人NAME。
[java]
view plain
copy
public void fetchAllContacts() {
- ora-00054:resource busy and acquire with nowait specified解决方法
bijian1013
oracle数据库killnowait
当某个数据库用户在数据库中插入、更新、删除一个表的数据,或者增加一个表的主键时或者表的索引时,常常会出现ora-00054:resource busy and acquire with nowait specified这样的错误。主要是因为有事务正在执行(或者事务已经被锁),所有导致执行不成功。
1.下面的语句
- web 开发乱码
征客丶
springWeb
以下前端都是 utf-8 字符集编码
一、后台接收
1.1、 get 请求乱码
get 请求中,请求参数在请求头中;
乱码解决方法:
a、通过在web 服务器中配置编码格式:tomcat 中,在 Connector 中添加URIEncoding="UTF-8";
1.2、post 请求乱码
post 请求中,请求参数分两部份,
1.2.1、url?参数,
- 【Spark十六】: Spark SQL第二部分数据源和注册表的几种方式
bit1129
spark
Spark SQL数据源和表的Schema
case class
apply schema
parquet
json
JSON数据源 准备源数据
{"name":"Jack", "age": 12, "addr":{"city":"beijing&
- JVM学习之:调优总结 -Xms -Xmx -Xmn -Xss
BlueSkator
-Xss-Xmn-Xms-Xmx
堆大小设置JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统下,一般限制在1.5G~2G;64为操作系统对内存无限制。我在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。典型设置:
java -Xmx355
- jqGrid 各种参数 详解(转帖)
BreakingBad
jqGrid
jqGrid 各种参数 详解 分类:
源代码分享
个人随笔请勿参考
解决开发问题 2012-05-09 20:29 84282人阅读
评论(22)
收藏
举报
jquery
服务器
parameters
function
ajax
string
- 读《研磨设计模式》-代码笔记-代理模式-Proxy
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
/*
* 下面
- 应用升级iOS8中遇到的一些问题
chenhbc
ios8升级iOS8
1、很奇怪的问题,登录界面,有一个判断,如果不存在某个值,则跳转到设置界面,ios8之前的系统都可以正常跳转,iOS8中代码已经执行到下一个界面了,但界面并没有跳转过去,而且这个值如果设置过的话,也是可以正常跳转过去的,这个问题纠结了两天多,之前的判断我是在
-(void)viewWillAppear:(BOOL)animated
中写的,最终的解决办法是把判断写在
-(void
- 工作流与自组织的关系?
comsci
设计模式工作
目前的工作流系统中的节点及其相互之间的连接是事先根据管理的实际需要而绘制好的,这种固定的模式在实际的运用中会受到很多限制,特别是节点之间的依存关系是固定的,节点的处理不考虑到流程整体的运行情况,细节和整体间的关系是脱节的,那么我们提出一个新的观点,一个流程是否可以通过节点的自组织运动来自动生成呢?这种流程有什么实际意义呢?
这里有篇论文,摘要是:“针对网格中的服务
- Oracle11.2新特性之INSERT提示IGNORE_ROW_ON_DUPKEY_INDEX
daizj
oracle
insert提示IGNORE_ROW_ON_DUPKEY_INDEX
转自:http://space.itpub.net/18922393/viewspace-752123
在 insert into tablea ...select * from tableb中,如果存在唯一约束,会导致整个insert操作失败。使用IGNORE_ROW_ON_DUPKEY_INDEX提示,会忽略唯一
- 二叉树:堆
dieslrae
二叉树
这里说的堆其实是一个完全二叉树,每个节点都不小于自己的子节点,不要跟jvm的堆搞混了.由于是完全二叉树,可以用数组来构建.用数组构建树的规则很简单:
一个节点的父节点下标为: (当前下标 - 1)/2
一个节点的左节点下标为: 当前下标 * 2 + 1
&
- C语言学习八结构体
dcj3sjt126com
c
为什么需要结构体,看代码
# include <stdio.h>
struct Student //定义一个学生类型,里面有age, score, sex, 然后可以定义这个类型的变量
{
int age;
float score;
char sex;
}
int main(void)
{
struct Student st = {80, 66.6,
- centos安装golang
dcj3sjt126com
centos
#在国内镜像下载二进制包
wget -c http://www.golangtc.com/static/go/go1.4.1.linux-amd64.tar.gz
tar -C /usr/local -xzf go1.4.1.linux-amd64.tar.gz
#把golang的bin目录加入全局环境变量
cat >>/etc/profile<
- 10.性能优化-监控-MySQL慢查询
frank1234
性能优化MySQL慢查询
1.记录慢查询配置
show variables where variable_name like 'slow%' ; --查看默认日志路径
查询结果:--不用的机器可能不同
slow_query_log_file=/var/lib/mysql/centos-slow.log
修改mysqld配置文件:/usr /my.cnf[一般在/etc/my.cnf,本机在/user/my.cn
- Java父类取得子类类名
happyqing
javathis父类子类类名
在继承关系中,不管父类还是子类,这些类里面的this都代表了最终new出来的那个类的实例对象,所以在父类中你可以用this获取到子类的信息!
package com.urthinker.module.test;
import org.junit.Test;
abstract class BaseDao<T> {
public void
- Spring3.2新注解@ControllerAdvice
jinnianshilongnian
@Controller
@ControllerAdvice,是spring3.2提供的新注解,从名字上可以看出大体意思是控制器增强。让我们先看看@ControllerAdvice的实现:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
public @interface Co
- Java spring mvc多数据源配置
liuxihope
spring
转自:http://www.itpub.net/thread-1906608-1-1.html
1、首先配置两个数据库
<bean id="dataSourceA" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close&quo
- 第12章 Ajax(下)
onestopweb
Ajax
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- BW / Universe Mappings
blueoxygen
BO
BW Element
OLAP Universe Element
Cube Dimension
Class
Charateristic
A class with dimension and detail objects (Detail objects for key and desription)
Hi
- Java开发熟手该当心的11个错误
tomcat_oracle
java多线程工作单元测试
#1、不在属性文件或XML文件中外化配置属性。比如,没有把批处理使用的线程数设置成可在属性文件中配置。你的批处理程序无论在DEV环境中,还是UAT(用户验收
测试)环境中,都可以顺畅无阻地运行,但是一旦部署在PROD 上,把它作为多线程程序处理更大的数据集时,就会抛出IOException,原因可能是JDBC驱动版本不同,也可能是#2中讨论的问题。如果线程数目 可以在属性文件中配置,那么使它成为
- 推行国产操作系统的优劣
yananay
windowslinux国产操作系统
最近刮起了一股风,就是去“国外货”。从应用程序开始,到基础的系统,数据库,现在已经刮到操作系统了。原因就是“棱镜计划”,使我们终于认识到了国外货的危害,开始重视起了信息安全。操作系统是计算机的灵魂。既然是灵魂,为了信息安全,那我们就自然要使用和推行国货。可是,一味地推行,是否就一定正确呢?
先说说信息安全。其实从很早以来大家就在讨论信息安全。很多年以前,就据传某世界级的网络设备制造商生产的交