流量控制
目录
一、静态流控
二、动态流控
三、并发控制
四、链接控制
五、并发和连接控制算法
流量控制: 当资源成为瓶颈时,服务框架需要对消费者进行限流,启动流控保护机制。流量控制有多种策略,比较常用的有:针对访问速率的静态流控、针对资源占用的动态流控、针对消费者并发连接数的连接控制和针对并行访问数的并发控制。
在实践中,各种流量控制策略需要综合使用才能起到较好的效果。本篇将对分布式服务框架的流量控制设计原则和实践进行分析。
一、静态流控
静态流控主要针对客户端访问速率进行控制,它通常根据服务质量等级协议(SLA)中约定的 QPS(每秒查询速率)做全局流量控制,如订单服务的静态流控制阈值为 100QPS,则无论集群有多少个订单服务实例,它们总的处理速率之和不超过100QPS。
【1】传统静态流控制设计方案:传统的静态流控设计采用安装预分配方案,在软件安装时,根据集群服务节点个数和静态流控阈值,计算每个服务节点分摊的 QPS阈值,系统运行时,各个服务节点按照自己分配的阈值进行流控,对于超出流控阈值的请求则拒绝访问。静态预分配方案原理如图1.1所示:

图1.1:静态预分配方案原理图
服务框架启动时,将本节点的静态流控阈值加载到内存中,服务框架通过 Handler拦截器在服务调用前做拦截计数,当计数器在指定的周期 T到达 QPS上限时,启动流控,拒绝新的请求消息接入。有两点需要注意:
1)、服务实例通常由多线程执行,因此计数时需要考虑线程并发安全,可以使用 Atomic原子类进行原子操作。
2)、到达流控制阈值之后拒绝新的请求消息接入,不能拒绝后续的应答消息,否则就会导致客户端超时或者触发 Failover,增加服务端的负载。
【2】传统方案的缺点: 静态分配方案最大的缺点就是忽略了服务实例的动态变化:
1)、云服务的弹性伸缩特性是服务的节点动态数处于动态的变化过程中,预分配方案行不通。
2)、服务节点数宕机,或者有新的节点加入,导致服务节点数发生变化,静态分配的 QPS需要实时动态调整,否则会导致流控不准。
分布式服务框架的一个特点就是服务动态上下线和自动发现机制,这就决定了在运行期服务节点数会随着业务量的变化而频繁变化,在这种场景下静态分配方案显然无法满足需求。
当服务和应用迁移到云上之后,Paas 平台的一个重要特性就是支持应用和服务的弹性伸缩,在云上,资源都是动态分配和调整的,静态分配阈值分案无法使用服务迁移到云上。
【3】动态配额分配制:为解决静态分配的缺陷,在实践中通常会采用动态配额分配制。它的工作原理:有服务注册中心以流控周期T为单位,动态推送每个服务节点的流控阈值 QPS。当服务节点发生变更时,会触发服务注册中心重新计算每个节点的配额,然后进行推送,这样无论是新增还是减少服务节点数,都能够在下一个流控周期内被识别和处理,这就解决了静态分配方案无法适应节点数动态变化的问题。动态配额分配制的工作流程如图1-2所示:
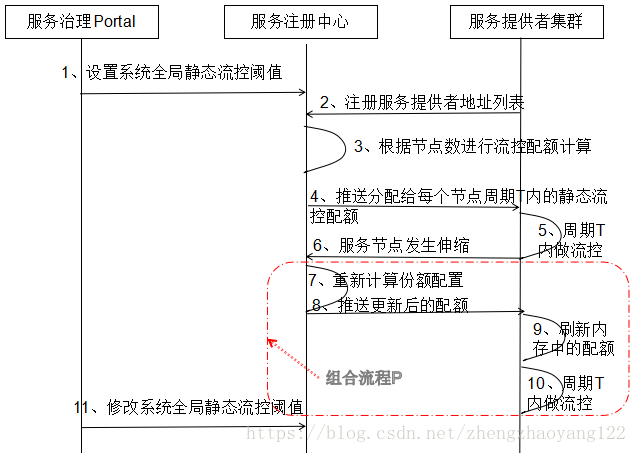
如图1-2:动态配额分配制的工作流程
在生产环境中,每台机器 VM的配置可能不同,如果每个服务节点采用流控总阈值/服务节点数这种平局主义,可能会发生性能高、处理快的节点配额很快用完,但是性能差的节点配额还有剩余的情况,这会导致总的配额没有用完,但是系统却发生了静态流控的问题。一种解决方案就是服务注册中心进行配额计算时,根据各个节点的性能 KPI数据(例如服务调用平均时延)做加权,处理能力差的服务节点分配的指标少些,性能高的分配的指标多些,这样就能够尽可能低地降低流控偏差。
还有另一种解决方案就是配额指标返还和重新申请,每个服务节点根据自身分配的指标值、处理速率做预测,如果计算结果表明指标会有剩余,则把剩余的返还给服务注册中心;对于配额已经使用完的节点,重新主动去服务注册中心申请配额,如果连续N次都申请不到新的配额指标,则对于新接入的请求消息做流控。
最后一点就是结合负载均衡进行静态流控,才能够实现更精确的调度和控制。消费者根据各种服务节点的负载均衡情况做加权路由,性能差的节点路由到的消息更少,由于配额计算也是根据负载做了加权调整,最终分配制性能差的节点配额指标也较少,这样既保证了系统的负载均衡,又实现了配额的更合理分配。
【4】动态配额申请制:尽管动态配额分配制可以解决节点变化引起的流控不准的问题,也能够改善平均主义配额分配导致的贫富不均,但是它并不是最有的方案,它的缺点总结如下:
1)、如果流控周期T比较大,各服务节点的负载情况变化比较快,服务节点的负载反馈到注册中心,有注册中心统一计算后再做配额均衡,误差会比较大。
2)、如果流控周期T比较小,服务注册中心需要实时获取各服务节点的性能 KPI数据并计算负载情况,经过性能数据采集、上报、汇总和计算之后,会有一定的时延,这会导致流控滞后产生误差。
3)、如果采用配额返还和重新申请的方式,会增加交互次数,同时也会存在时序误差,效果有限。
4)、扩展性差,负载的汇总、计算和配额分配、下发都有服务注册中心完成,如果服务注册中心管理的节点数非常多,则服务注册中心计算压力非常大,随着服务节点不断增加服务注册中心的配额分配效率会急速下降,系统不具备平滑扩展能力。
要解决上述问题,可以采用动态配额申请制,它的工作原理如下:
1)、系统部署的时候,根据服务节点数和静态流控 QPS阈值,拿出一定比例的配额做初始分配,剩余的配额放在配额资源池中。
2)、那个服务节点使用完了配额,就主动向服务注册中心申请配额。配额的申请策略是,如果流控周期为T,则将周期T分成更小的周日T/N(N为经验值,默认值为10),当前的服务节点数为M个,则申请的配额为(总QPS配额 - 已经分配的QPS配额)/M * T/N。
3)、总的配额如果被分配完,则返回 0个配额给各个申请额度的服务节点,服务节点对新接入的请求消息进行流控。
动态配额申请制的优点:
1)、各个服务节点最清楚自己的负载情况,性能 KPI在本地内存中计算获得,实时性高。
2)、由各个服务节点根据自身负载情况去申请配额,保证性能高的节点有更高的额度,性能差的自然配额就少,这样能够更合理地调配资源,实现流控的精确性。
实践经验表明,采用动态配额申请制的静态流控更精确,在实战中效果也更好。
二、动态流控
动态流控:动态流控的最终目标是为了保命,并不是对流量或者访问速度做精确控制。当系统负载压力非常大时,系统进入过负载状态,可能是CPU、内存资源已经过载,也可能是应用进行内部的资源几乎耗尽,如果继续全量处理业务,可能会导致长时间的 Full GC、消息积压或者应用进程宕机,最总将压力转移到其他的节点,引起级联故障。
出发动态流控的因子是资源,资源又分为系统资源和应用资源两大类,根据不同的资源负载情况,动态流控有分布多个级别,每个级别流控系数都不同,也就是被拒绝掉的消息比例不同。每个级别都有相应的流控阈值,这个阈值通常支持在线动态调整。
【1】动态流控因子: 动态流控因子包括系统资源和应用资源两大类,常用的系统资源包括:
1)、应用进程所在主机 VM的 CPU使用率。
2)、应用进行所在主机 VM的内存使用率。
主机CPU、内存使用率采集算法非常多,例如使用 java.lang.Process 执行 top、sar 等外部命令获取系统资源使用情况,然后解析后计算获得资源使用率。也可以直接读取操作系统的系统文件获取香瓜数据,需要注意的是,无论是执行操作系统的本地命令,还是读取操作系统的资源使用率文件,都是操作系统本地相关的,不同的操作系统和服务器,命令和格式可能存在很大差异。在计算时首先判断操作系统类型,然后调用相关操作系统的资源采集接口实现类,通过这种方法就可以实现跨平台。
常用的应用资源包括:
1)、JVM 堆内存使用率。
2)、消息队列积压率。
3)、会话积压率(可选)
具体实现策略是系统启动时拉起一个管理线程,定时采集应用资源的使用率,并刷新动态流控的应用资源阈值。
【2】分机流控:通常,动态流控是分级别的,不同级别的流控拒绝的消息比例是不同的,这取决于资源的负载使用情况,例如发生一级级别,拒绝掉1/8的消息,发生二级级别的流控时,拒绝1/4的消息等。
不同的级别有不同的流控阈值,系统上线后会提供默认的流控阈值,不同流控因子的流控阈值不同,业务上线后通常会根据现场的实际情况做阈值调优,因此流控阈值需要支持在线修改和动态生效。
需要指出的是为了防止系统波动导致的偶发性流控,无论是进入流控状态还是从流控状态恢复,都需要连续采集N次并计算平均值,如果连续N此平均值大于流控阈值,则进入流控状态;同理,只有联系N此资源使用率的平均值低于流控阈值,才能脱离流控状态恢复正常。根据资源使用率的变化,流控会发生升级或者降级,在同一个流控周期内,不会发生流控级别的跳变。
三、并发控制
并发控制主要针对线程的并发执行数进行控制,它的本质是限制对某个服务或者服务方法进行过度消费,耗用过多的资源而影响其它资源的使用。并发控制有两种形式:
1)、针对服务提供者的全局控制。
2)、针对服务提供者的局部控制。
【1】服务端全局控制:服务并行控制的配置示例代码如下:
限制 edu.yintong,EchoService接口,它的并发执行数为5,如果超过5,则抛出并行控制异常。如果要支持服务接口方法级并发控制,他的配置示例如下:分布式服务框架的服务发布 XML scheme中,service 和 method元素需要增加并行控制 executes属性。
【2】服务消费者流控:除了支持服务端全局流控之外,还需要支持针对消费者的流控,不同消费者可以配置不同的流控策略,配置如下:
显示 echoService客户端并发执行数不能超过5 与服务端类型,也支持服务方法级别控制,示例如下:
分布式服务框架的服务引用XML scheme中,reference 和method 元素需要增加并行控制 active属性。
四、链接控制
通常分布式服务框架服务提供者和消费者之间采用长连接私有协议,为了防止因为消费者连接数过多导致服务端负载压力过大,系统需要支持针对连接数进行流控。
【1】服务端连接数流控:针对分布式服务框架的某个协议,在服务端控制消费者的连接数,示例如下:限制xxx协议客户端连接数不能超过50。
【2】服务消费者连接数流控:针对某个服务消费者连接数限制,示例如下:限制接口edu.neu.EchoService的消费者,连接数最多不能超过50个。
五、并发和连接控制算法
并发控制算法原理图1-3所示:

图1-3: 并发控制算法原理图
基于服务调用 Pipeline机制,可以对请求消息接收和发送、应答消息接受和发送、异常消息等做切面拦截(类似于spring的AOP机制,但是没采用反射机制,性能更高)利用Pipeline拦截切面接口,对请求消息做服务调用的拦截和计数,根据计数做流控,服务端的算法如下:
1)、获取流控阈值。
2)、从全局RPC上下文中获取当前的并发执行数,与流控阈值对比,如果小于流控阈值,则对当前的流控阈值做原子自增。
3)、如果大于或等于流控阈值,则抛出RPC流控异常给客户端。
4)、服务调用执行完之后,获取RPC上下文中的并发执行数,做原子自减。
客户端流控算法与服务端不太一样,客户端的流控目的就是降低对服务端的冲击。因此当客户端的连接数大于流控阈值时,需要将当前的线程挂起,等待其他线程执行完后再执行,或者超时,他的算法如下:
1)、获取流控阈值。
2)、全局RPC上下文中获取当前的并发执行数,与流控阈值对比,如果小于流控阈值,则对当前的流控阈值做原子自增。
3)、如果大于或等于流控阈值,当前线程进入wait状态,wait超时时间为服务调用的超时时间。
4)、如果有其他线程服务调用完成,调用计数器自减,则并发数小于阈值,线程被notify,退出wait,继续执行。
超时示例代码如下:
int active = count.getActive();
if(active >= max){
synchronized(count){
while((active = count.getActive()) >= max)//循环判断
try{
count.wait(remain);//超时等待
}catch(Exception e){
Log.error(e);
}
long elapsed = System.currentTimeMillis() - start;
remain = timeout - elapsed;//剩余的超时时间
if(remain <= 0){//已超时
throw new RpcException("timeout"+timeout);
}
}
}总结:流控是保证服务SLA(服务等级协议)的重要措施,也是业务高峰期故障预防和恢复的有效手段,分布式服务框架需要支持不同的流控策略,还要支持流控阈值、策略的在线调整,不需要重启应用即可在线生效,提升上线服务治理的效率和敏捷性。

----关注公众号,获取更多内容----