强化学习(三):Deep Q Network(DQN)算法
强化学习(一):基础知识
强化学习(二):Q learning算法
强化学习(三):Deep Q Network(DQN)算法
在上一节中介绍的Q learnig算法利用Q table来记录和检索 Q value,在状态空间较小的情况下可以适用,但是当状态空间很大的时候,利用Q table来维护数据就不太可行了,所以就诞生了deep Q network(DQN)算法,也叫deep Q learning,它用神经网络代替了Q table的作用。将输入数据输入神经网络,神经网络会输出对应的Q value。
下图是DQN算法的结构图,输入数据仅仅只是当前的state,如一张游戏的画面截图,经过deep NN之后,输出是Q value。在很多时候,action的个数是固定的,所以神经网络的输出个数也是固定的,它的输出是n个数字,n表示的是action的维度,每个输出表示的是action对应的Q value。
如果我们想获取在给定state下的一个动作,我们只需要将state喂给神经网络,然后它返回给我们所有的Q values。我们选择最大的Q value,然后选择和最大Q value关联的动作。
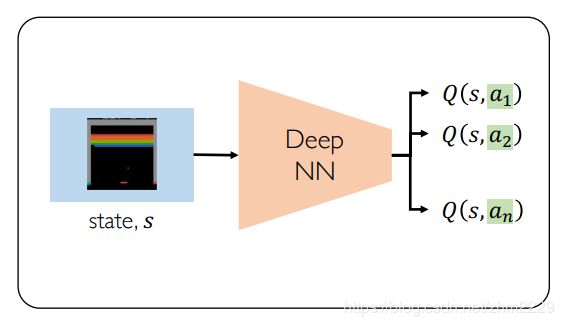 DQN 结构图
DQN 结构图
下面是DQN 的损失函数,使用的是mean squared error(MSE) 平方均值法。损失函数是要最小化predicted Q value和target Q value之间的error。
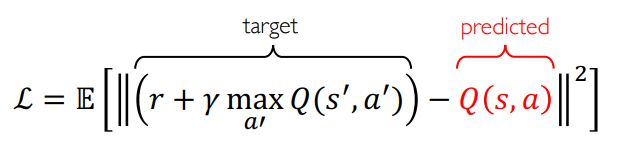
右边是predicted Q value,它就是神经网络的输出,表示的是状态为s,动作为a的时候神经网络的预测值。
左边是target Q value,它是指当选择动作a时实际观测到的值。当agent选择一个动作,它会得到一个reward,然后我们可以它存下来,我们同样可以把every action after that的discounted reward存下来。它们两的和就是target Q value,是给一个动作实际获得的所有reward。
我们可以用predicted Q value去做回归问题,然后用和普通神经网络里一样的反向传播去训练损失函数,然后根据损失函数去训练神经网络使得predicted Q value尽量接近target Q value。
下面是deep mind 用DQN去玩Atari游戏
左边的输入是游戏的状态state,经过一系列卷积层和RuLU函数,然后经过全连接层,最后在输出层得到一列Q值。每一个Q值对应一个agent可能采取的动作。
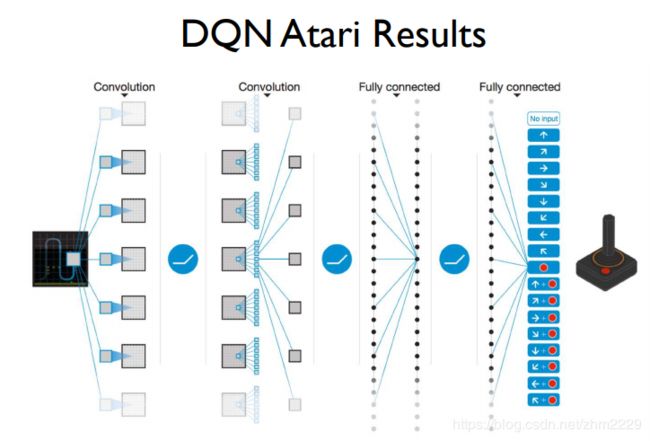 用DQN玩atari游戏的神经网络结构
用DQN玩atari游戏的神经网络结构
这个算法不需要改变任何参数,就可以将它应用于不同的游戏中(因为所有atari游戏的可能动动作集是一样的),然后就可以让这个神经网络在很多不同的atari游戏上达到高于人类的水平。
atari是一系列的游戏(类似国内的小霸王游戏机),下图X轴显示的一些不同的atari游戏,左边的一些DQN超过人类水平的游戏,右边是一些DQN达不到人类水平的游戏。
 DQN 玩atari游戏结果
DQN 玩atari游戏结果
在一些游戏中或者状态下我们没有一个perfectly observable world(完全可观测的世界),它是指给定一个state,我们可以最优观测到在那个状态下应该采取的正确的动作。但是不是所有的游戏都有这个属性。
在一些游戏中,它有比较稀疏的rewards,比如最右边的Montezuma`s Revenge,它会得到比较稀疏的reward,它会让agent 爬上梯子,到另一个房间,拿到一个钥匙,用钥匙打开锁。在这些过程中,agent没有得到Q value,然后它就学不到哪个是应该采取的好的action。如果它只是随机地在环境中探索,它很难看到应该选的动作,它就用永远不可能得到一些选择最优动作的上下文。
而在打砖块游戏breakout中,我们能看到球拍击中球,然后球反弹去打方块,这个是一个有perfect information的游戏。所以如果我们知道球的方向和球拍的位置以及空间中的点,我们能得到在一个state下的最优解,然后知道怎么去移动球拍。
DQN算法虽然可以在多个不同的atari游戏中表现不错,但是它也有自己的缺点
在复杂性方面,它能解决动作空间是较少且离散的问题,它不能解决连续动作空间的问题。
比如在自动驾驶时,方向盘的转动角度是连续的,这时候就不能用DQN,因为它的输出是有限的个数。当然也可以把连续的空间分割成很小的bins,然后学习这些bins的Q value,但是也存在一些问题,如将bin划分为多小,bin越小,计算越复杂等。
在灵活性方面,它不能学习随机的policy,因为在DQN中policy都是由Q 函数很确定地计算出来的。
因为在DQN中,action都是由Q value决定,选择最大Q value对应的action。
关于这两个问题,可以用Policy Gradient(PG)算法来解决。

参考:
1. 深度强化学习:https://www.youtube.com/watch?v=i6Mi2_QM3rA&list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI&index=1