网易云音乐基于用户的推荐系统
网易云音乐核心功能是其推荐算法,据观察,日推主要采用itemCF方法。网易云音乐根据每日获取到的听歌列表,优先推荐跟该歌曲相似的歌曲。如今,网易云音乐着重社交功能,因此,本文尝试构建基于用户的推荐系统。
摘要:本文思路是根据用户所有时间听歌排行计算相似度,推荐用户最近一周听歌次数大于2次的歌曲。采用jaccard距离和向量余弦计算相似度。本文目录为数据集获取、数据预处理、数据分析、算法实现和结果输出
一、数据集获取
分析网易云音乐听歌排行页面发现最近一周数据和所有时间数据是动态加载,因此使用requests+beautifulsoup很难获得完整的数据。

进一步分析网页源代码,点击network,选择XHR,重新加载网页,我们在最后一个文件中找到我们要的数据,下图的preview为json文件,点击headers可以看到,浏览器是使用post方法请求json数据,因此我们的爬虫也使用post方法
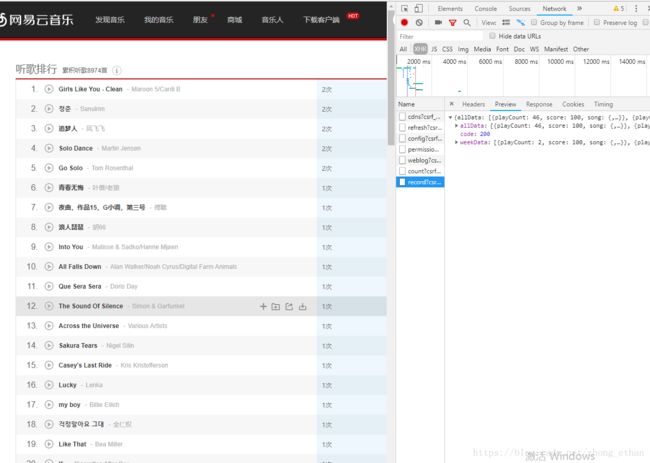
上代码
import json
from urllib import request, parse
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
#从network-XHR-Headers-FromData中获取data和url
data = { 'params':'bMCucP9w4r9XUMWjHedB1PBdNzcVLrZMbv+3QwlZu0RyNBYCiVYdQr/guQblmlxWuDeQIxQ86HP84U2tADFvAlVUQfZqzEErQpPoAzKgfNmr596MQUW/t+MFuQroJ1OpLYcf2VsSuWGWBZym4/mds70oCqij+kJGsjl1XIXzh6YLF36Nqr2bHWe25RENZ9oZox2mFwmbbBL6v5mQTuk9WgyzShZPJ8V0rmyKuUM='
'encSecKey': '31ab03c7f70469fdb89ea8184ee58501106acda3baa831a5e8e89c2950193d6ccff4ac086e089ff6712b9fe90773a042b735cb18c0e87a217baf8ffc40b59de1624527ea1899227be0e435b927346090abac1314b5f7c1da78cb4fdc8399bc1dc8195bb57db64948299c825ae47e9614508197f67fa141429bce875b3'
}
# 这个URL从网页源码中查找,为requestURL对应的
url = 'https://music.163.com/weapi/v1/play/record?csrf_token=74f92d802fc66dade9d176e77480ac'
data =parse.urlencode(data).encode('utf-8')
request1 = request.Request(url, data, headers = headers)
response = request.urlopen(request1)
html = response.read().decode('utf-8')
results = json.loads(html)
#这里获取到的result包括alldata 和 weekdata从result结果中提取歌名,歌手以及score,最后将我们获取到的数据存储为json文件,这里的score对应的分数为(次数/max次数)转为百分比
二、数据预处理
对歌曲名称的预处理包括:去除歌名中括号,方括号的内容,去除歌名中非字母数字,去除歌名中空格,将大写字母转换为小写
对歌曲作者的预处理包括:去除所有非字母数字,去除空格,将大写转换为小写
这个步骤的作用是格式化字符串,提高算法速度
三、数据分析
常见的相似性度量方法有欧氏距离、皮尔逊相关度、jaccard距离、余弦相似度。本文使用jaccard距离衡量用户喜欢歌曲的相似性,用余弦相似度衡量用户对喜欢的歌曲的喜欢程度的相似性。根据用户所有时间听歌排行评价用户相似性时,歌单里的每一首歌都是用户喜欢的歌,系数score代表用户喜欢的程度。用A 代表用户A喜欢的歌曲集合,用B 代表用户B 喜欢的歌曲集合,则jaccard距离为:A∩B代表两用户同时喜欢的歌曲
![]()
考虑到用户喜欢同一个歌手也具有相似性,因此此处的交集应包括两用户同时喜欢的歌手。
用C表示用户A与B同时喜欢的歌曲中A集合对应的分数,D表示用户A与B同时喜欢的歌曲中B集合对应的分数,则相似性为:
![]()
本文在最终处理数据时,使用了jaccard与cossimi的乘积代表其相似度,迭代计算用户A与其他用户之间的相似性,选择值最大的用户,推荐其最近一周听歌次数大于一次的歌曲。
四、算法实现
import json
import re
import numpy as np
# 打开爬取到的数据集
with open('NeteaseMusicData.json', 'r') as f:
data = json.load(f)
users = data['username']
pattern1 = '\(.*\)' # 匹配圆括号中的内容
pattern2 = '\[.*\]' # 匹配中括号中的内容
pattern3 = '\W' # 匹配非字符内容
patterns = [pattern1, pattern2, pattern3]
# 清理数据,去除空格,符号,并将大写转为小写
def remove(string, pat):
obj = re.compile(pat)
delstring = obj.findall(string)
if delstring:
for dels in delstring:
string = string.replace(dels, '')
return string.lower()
# 处理title列表,得到
def handletitle(user):
title = [each[0] for each in data[user]['alldata']]
titled = []
for each in title:
for pattern in patterns:
each = remove(each, pattern)
titled.append(each)
return titled
# 处理singer列表数据,去除列表中的非字母数字符号,并将大写转换为小写
def handlesinger(user):
singers = [each[1] for each in data[user]['alldata']]
singered = []
for singer in singers:
singer = remove(singer, pattern3)
singer = singer.replace(' ', '').lower()
singered.append(singer)
return singered
# 计算两个列表的重复元素
def repeatlist(list1, list2):
relist = list()
for each in list1:
if each in list2:
relist.append(each)
return relist
# 计算jaccard相似度
def jaccardsimi(user1, user2):
titled1 = handletitle(user1)
titled2 = handletitle(user2)
singered1 = handlesinger(user1)
singered2 = handlesinger(user2)
count1 = len(titled1)
count2 = len(titled2)
repeattitle = repeatlist(titled1, titled2)
repeatsinger = repeatlist(singered1, singered2)
if not repeattitle:
return 0
for each in repeattitle:
index = titled1.index(each)
dual = 0
if singered1[index] in repeatsinger:
dual += 1
num = len(repeattitle) + len(repeatsinger) - dual
deno = count1 + count2 - num
jacsimi = (num / deno) * 100
return jacsimi
# 计算重复歌曲列表的余弦相似度
def cossimi(user1, user2):
titled1 = handletitle(user1)
titled2 = handletitle(user2)
repeattitle = repeatlist(titled1, titled2)
if not repeattitle:
return 0
def score(titlelist, user):
scores = list()
for each in repeattitle:
index = titlelist.index(each)
scores.append(data[user]['alldata'][index][2])
return scores
score1 = score(titled1, user1)
score2 = score(titled2, user2)
matrix1 = np.array(score1)
matrix2 = np.array(score2)
num = np.inner(matrix1, matrix2)
deno = np.sqrt(matrix1.dot(matrix1)) * np.sqrt(matrix2.dot(matrix2))
cosimi = (num / deno) * 100
return cosimi
def main(username):
if username not in users:
print('该用户不存在')
return
maxsimi = 0
for eve in users:
if username != eve:
jacsimi = jaccardsimi(username, eve)
cosimi = cossimi(username, eve)
print('%s与%s的jaccard相似度是:%f%%' % (username, eve, jacsimi))
print('%s与%s的余弦相似度是:%f%%' % (username, eve, cosimi))
if maxsimi < jacsimi * cosimi:
maxsimi = jacsimi * cosimi
maxuser = eve
weekdata = data[maxuser]['weekdata']
def minscore(weekdatalist):
mins = 100
for each in weekdatalist:
if mins > each[2]:
mins = each[2]
return mins
minsco = minscore(weekdata)
recommendlist = [each for each in weekdata if each[2] > minsco]
print('%s和%s的相似度最高,推荐的歌单列表为:' % (username, maxuser))
print(recommendlist)
if __name__ == '__main__':
main('yuzhong_沐阳')
五、结果输出
yuzhong_沐阳与Tanya方良的jaccard相似度是:6.382979%
yuzhong_沐阳与Tanya方良的余弦相似度是:90.803806%
yuzhong_沐阳与HarkerLee的jaccard相似度是:6.382979%
yuzhong_沐阳与HarkerLee的余弦相似度是:90.968774%
yuzhong_沐阳与hyhsky0825的jaccard相似度是:6.382979%
yuzhong_沐阳与hyhsky0825的余弦相似度是:94.077937%
yuzhong_沐阳与hi-M3U_玻色子的泛的jaccard相似度是:0.000000%
yuzhong_沐阳与hi-M3U_玻色子的泛的余弦相似度是:0.000000%
yuzhong_沐阳和hyhsky0825的相似度最高,推荐的歌单列表为:
[['바람에 쓰는 편지', 'July', 100], ['Free Loop', 'Daniel Powter', 100], ['那个人', '周延英(英子-effie)', 100], ['热勇', '栗先达', 100], ['Need You Now', 'Lady Antebellum', 100], ['借我一生', '水木年华', 100], ['孙大剩', '白亮', 100], ['褪变无路', '夏天播放', 100], ['被驯服的象', '蔡健雅', 100], ['丁香花', '唐磊', 100]]
不足之处:
2018/08/30
1.该算法没有进行评测。《推荐系统实践》提出三种评测方法:离线实验,用户实验,在线调查
评测指标有:用户满意度、预测准确率、覆盖率、多样性、新颖性(流行度),惊喜度
2.该算法只推荐了一位用户的歌单,歌曲覆盖率不是很高,可考虑K个用户,计算K个用户的歌单权重,排序后推荐给用户
3.改进jaccard距离算法:惩罚了共同兴趣列表中热门物品对相似度的影响
