在之前的例子中演示了来宾可执行文件、服务的编程模型,可以看到在 Service Fabric 编写服务时可以获取到资源、部署信息,以及能够完成健康和监控信息的汇报。除了无状态服务, Service Fabric 还着重介绍了有状态服务,服务部署后我们还可以对服务进行扩缩容以保证服务是处于最优的运行状态。
Service Fabric 提供了多种方法来编写和管理服务。服务可以选择使用 Service Fabric API 来充分利用平台的功能和应用程序框架。服务还可以是采用任何语言编写的任意已编译可执行程序,也可以是在 Service Fabric 群集上直接托管的容器中运行的代码。之前提到的容器部署,能够支持Docker compose和windows hyper-V,以及ASP.NET core。
Reliable Services 是一个用于编写与 Service Fabric 平台集成的服务的轻型框架,并且受益于完整的平台功能集。Reliable Services 提供最小 API 集合,该集合允许 Service Fabric 运行时管理服务的生命周期,以及允许服务与运行时进行交互。Reliable Services 可以无状态,类似于大多数服务平台,如 Web 服务器。也就是说,创建的每个服务实例都是平等的,并且状态保存在外部解决方案中,如 Azure DB 或 Azure 表存储。Reliable Services 也可以是有状态的,专门用于 Service Fabric,其状态使用 Reliable Collections 直接保存在服务中。通过复制使状态具有高可用性,以及通过分区来分布状态,所有状态由 Service Fabric 自动管理。
Reliable Actor 框架在 Reliable Services 的基础上构建,是根据执行组件设计模式实现虚拟执行组件模式的应用程序框架。Reliable Actor 框架使用称为执行组件的单线程执行的独立的计算单元和状态。Reliable Actor 为执行组件提供内置通信,以及提供预设的状态暂留和扩展配置。
服务分区
有两种服务类型:无状态服务和有状态服务。无状态服务可将持久状态存储在 Azure 存储、Azure SQL 数据库或 Azure Cosmos DB 等外部存储服务中。当服务根本没有永久性存储时,请使用无状态服务。有状态服务使用 Service Fabric 通过其 Reliable Collections 或 Reliable Actors 编程模型管理服务状态。
这里可以简单的认为有状态服务是需要使用SDK中的Reliable Collections完成工作的,下图展示了服务分区:

可以看到 Service Fabric 区分有状态和无状态的目的是服务在部署时的分区要求,也就是说将有状态的服务通过主备的方式保证其可用性的同时,提升性能,而将无状态的服务通过多实例部署的方式提升其可用性。
服务伸缩
分区并不是 Service Fabric 所独有的。一种众所周知的分区形式是数据分区,也称为分片。包含大量状态的有状态服务将跨分区拆分数据。每个分区负责服务完整状态的一部分。每个分区的副本分布在群集的节点上,以便命名服务状态进行缩放。 随着数据需求的增长,分区也会增长,Service Fabric 会在节点间重新平衡分区,以高效利用硬件资源。如果向群集添加新节点,Service Fabric 会在新增加的节点间重新平衡分区副本。
从服务分区和伸缩性的控制上,可以看到 Service Fabric 在完成服务部署的同时,还提供了基本数据的操作功能,依托提供的数据结构能够完成数据在不同节点上的分片,不需要用户引入其他技术,提供一致的使用体验,我们可以看一下如下代码:
class VotingDataService extends StatefulService implements VotingRPC {
private static final String MAP_NAME = "votesMap";
private ReliableStateManager stateManager;
public CompletableFuture addItem(String itemToAdd) {
AtomicInteger status = new AtomicInteger(-1);
try {
ReliableHashMap votesMap = stateManager
. getOrAddReliableHashMapAsync(MAP_NAME).get();
Transaction tx = stateManager.createTransaction();
votesMap.computeAsync(tx, itemToAdd, (k, v) -> {
if (v == null) {
return "1";
}
else {
int numVotes = Integer.parseInt(v);
numVotes = numVotes + 1;
return Integer.toString(numVotes);
}
}).get();
tx.commitAsync().get();
tx.close();
status.set(1);
} catch (Exception e) {
e.printStackTrace();
}
return CompletableFuture.completedFuture(new Integer(status.get()));
}
可以看到通过ReliableStateManager获取到ReliableHashMap数据结构,这个数据结构将会在多个服务节点上共享数据,用户不用关心具体的存储,可以简单的认为数据以状态的形式保存在服务实例中。服务后期的扩容缩容都会保有状态,并且通过数据的复制保证可用性。
有状态服务
前面介绍了有状态服务,有状态服务使用了Reliable Collections来保存状态,完成简单的数据存储,这个和无状态服务的区别在哪里?先看一下无状态服务的架构:

前端应用到服务应用都没有拘留状态,而是将状态维护在DB或者存储中,依靠它们存储状态,这样能够做到前端或者服务的自由扩缩容,这是我们常用的架构模式,而有状态服务的思路不一样,它是这样的:
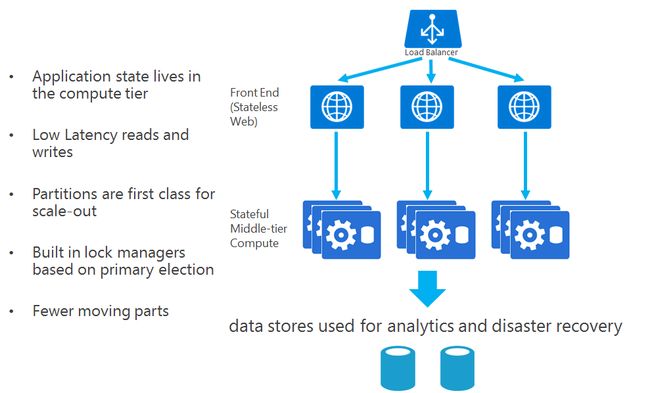
它是将数据与服务都放置在一个节点上,有状态的节点来承担服务,好处是底层数据存储不再是瓶颈,在前端负载均衡有目的的派发请求下,这种单元部署很容易完成,而且由于服务处理计算和数据天生贴近,在正常场景下性能会有优势。
而这里提到的数据不仅限于Reliable Collections,之前提到 单个 Azure SQL 数据库群集包含数百台计算机,这些计算机运行数以万计的容器,这些容器总共托管数十万个数据库。每个数据库都是一个 Service Fabric 有状态微服务。 ,通过这句话就能够理解,对于 Azure SQL,也是一种可靠的存储方式,它也会和应用一起分片部署,做到服务与数据的有状态部署,做到服务与数据的融合。