【Python3网络爬虫】 抓取猫眼电影排行榜
#抓取猫眼电影排行榜前100
#目标: 提取出猫眼电影TOP100的电影名称、时间、评分、图片等信息
#提取站点 :http://maoyan.com/board/4 提取的结果以文件形式保存
#使用知识: 网页基础 、网络基础 、urllib、requests、正则表达式
.*?board-index.*?>(.*) 发现可以一对标记只需要写一个就可以
.*?board-index.*?>(.*).*?data-src = "(.*?)"
.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?)
.*board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*) .*?star.*?>(.*?).*?releasetime.*?>(.*?).*?integer.*?>(.*?)(.*?).*?fraction.*?>(.*).*?
#目标: 提取出猫眼电影TOP100的电影名称、时间、评分、图片等信息
#提取站点 :http://maoyan.com/board/4 提取的结果以文件形式保存
#使用知识: 网页基础 、网络基础 、urllib、requests、正则表达式
1.抓取分析:
1.网站页面 有效信息:影片名称 主演 上映时间 上映地区 评分 图片 一页10条
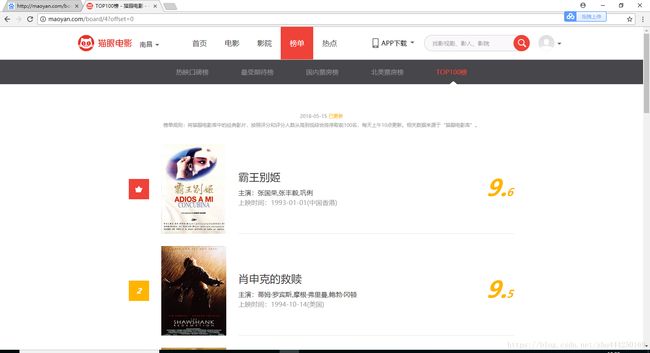
2.点击 第二页 发现上方的URL http://maoyan.com/board/4?offset=10
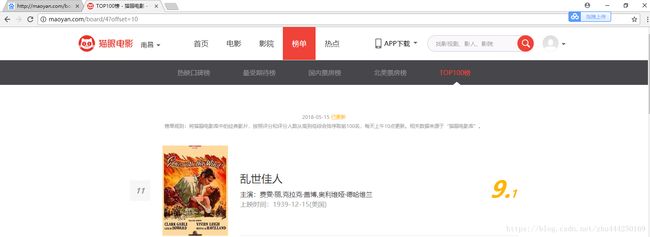
由此可见 offset代表偏移值
2.抓取首页
import requests
def get_one_page(url):
headers ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.170 Safari/537.36',
}
response = requests.get(url,headers = headers)
if response.status_code ==200:
return response.text
return None
def main():
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
print(html)
main()3.正则提取
先观察一个条目的源码:

1.提取排名信息:
![]()
这里可以写成的正则表达式:
2.提取电影图片
![]()
可以看到有两个图片链接,简单的测试之后,就可以得到 data-src是电影图片。
正则表达式可以写为:
3.提取电影名称
![]()
正则表达式 :
4.提取主演、发布时间评分等内容 :

第四个就是完整的正则表达式了,里面匹配了七个信息。接下来调用findall方法提取所有内容。
def parse_one_page(html):
pattern = re.compile('.*board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>
+(.*).*?star.*?>(.*?).*?releasetime.*?>(.*?).*?integer.*?>(.*?)(.*?).*?fraction.*?>(.*).*?','re.S')
items = re.findall(pattern,html)
print(items)
for item in items:
yield{
'index':'item[0]',
'image':'item[1]',
'title':item[2]strip()
'actor':item[3]strip()[3:] if len(item[3]) >3 else'',
'time':item[4]strip()[5:] if len(item[4])>5 else '',
'score':item[5].strip()+item[6].strip()
}
这样就可以成功提取 电影的排名 图片 标题 演员 时间 评分 等内容 并把它赋值为一个字典 形成结构化数据
4.写入文件
这里直接写入一个文本文件中。这里通过JSON库的dumps()方法实现字典的序列化,并指定ensure_ascii参数为False,这样就可以保证输出结果是中文形式而不是Unicode编码。
def write_to_file(content):
with open('result.txt','a',encoding='utf-8') as f:
print(type(json.dumps(content)))
f.write(json.dumps(content,ensure_ascii=False)+'\n')
5.整合代码
最后,实现main()方法调用前面实现的方法,将单页的电影结果写入到文件。相关代码如下:
def main()
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
for item in parse_one_page(html)
write_to_file(item)
6.分页爬取
因为需要抓取的是top100的电影,所以还需要遍历一下,给这个链接传入offset参数,实现其他90部电影的爬取,此时添加如下调用 即可:
if __name__=='__main__':
for i in range(10):
main(offset=i*10)
这里还需要将main()方法修改一下,接收一个offset值作为偏移量,然后构造URL进行爬取。实现代码如下:
def main(offset):
url = 'http://maoyan.com/board/4?offset='+str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
7.完整代码:
import json
import requests
from requests.exceptions import RequestException
import re
import time
def get_one_page(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('.*?board-index.*?>(\d+).*?data-src="(.*?)".*?name">(.*?).*?star">(.*?).*?releasetime">(.*?)'
+ '.*?integer">(.*?).*?fraction">(.*?).*? ', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
for i in range(10):
main(offset=i * 10)
time.sleep(1)
这个爬虫是看着崔老师的书写的,决定自己重新写一遍,之后换一个网站爬一下。
