海量数据判重——布隆过滤器(Bloom filter)与Bitmap对比
布隆过滤器
关于布隆过滤器(Bloom filter)的介绍部分,大多翻译自Wikipedia
简介
布隆过滤器(Bloom filter)是一个高空间利用率的概率性数据结构,由Burton Bloom于1970年提出。被用于测试一个元素是否在集合中(由于集合无重复元素的性质,可用来判重)。
可在数据量大到传统无错误散列(hash)方法需要使用的内存量是不可满足时使用,传统无错散列方法可以消除所有无用的磁盘访问,同时需要使用的内存量也非常大,而布隆过滤器在有限的内存使用量下依旧可以排除大部分无用的磁盘访问。
特性
存在假阳性(将不在集合中的元素误判为在集合中),不存在假阴性(将在集合中的元素误判为不在集合中)。过滤器中的元素个数越多,假阳性的可能性越大,总的来说,当不考虑集合中元素个数的情况下,每个元素由10个以下的bit来表示就可以保证1%以内的假阳性概率。
元素可以被加入过滤器,但不可从过滤器中删除(因为删除的时候有可能会影响到其他元素,之后会细说)。
空间和时间优势
布隆过滤器不需要存储数据项,但是同时它需要在其他地方单独存储真正的数据项。对于一个拥有最优k值且误判率在1%的布隆过滤器,每个元素只需要9.6bits(与元素的大小无关)。这个优点一部分继承自数组的紧凑性,另一方面由它本身的概率性决定。若给每个元素增加4.8bits左右,误判率将会减少十倍。
布隆过滤器在添加和查找元素时,所需要的时间时一个常数,O(k),完全与集合中元素个数无关。没有其他固定空间的集合数据结构有这样的效率,但是对于稀疏散列表来说,平均访问时长在实际使用中比一些布隆过滤器要短。在硬件实现方式中,布隆过滤器的优势在于他的k个查询之间不相关,因此可以并行处理。
算法描述
一个空的布隆过滤器是一串被置为0的bit数组(假设由m位)。同时,应该声明k个不同的散列函数生成一个统一随机分布,每一个散列函数都将元素映射到m个bit中的一个(k是一个小于m的常数,与加入过滤器中的元素个数成比例)。k与相应的m的选择由误判率决定。
向过滤器中添加元素时,通过k个散列函数得到该元素对应的k个位置,并将这些位置置为1.
查询某个元素/测试是否与已有元素重复时,依旧通过k个散列函数得到对应的k个位置,判断这些位置是否为1(若全为1则在集合内/重复)
可以看如下图所示的一个例子,其中,{x,y,z}为集合,w为进行比对的元素,m=18,k=3,不同颜色的箭头表示散列映射关系。可以看出,w并不在{x,y,z}这个集合中。

注意
①、当k比较大时,设计k个不同且无相关的散列函数是不现实的。对于一些输出的位数较多的优秀的散列函数(优秀指不同bit区间之间联系很小),我们可以将其切割成多个bit区域来代替多个散列函数。或者我们可以传递k个不同的值(例如:0,1,2,…,k-1)到一个散列函数中对其进行初始化;或者将这k个值整合到待计算元素中,再进行计算。对于较大的m,k,无相关性的散列函数可以使误判率的增加量减少。
②、从过滤器中删除元素是不可能的,因为有可能删除的当前元素与其他元素共享了某一个bit。当置该bit为0时,就会产生假阴性,这是绝对不允许的。
③、想要保持误判率低,过滤器的空间使用率(bit数组中置为1的概率)应为50%左右

Bitmap
Bitmap在海量无重复整数排序时的应用
bitmap就是用一个bit位来标记某个元素对应的value的存在,而key即是这个元素。由于采用bit为单位来存储数据,因此在可以大大的节省空间开销
这里的海量数据以整数为例,整数为4字节,也就是32bit,假设数据量N(N为最大值)=100000000,由于bitmap是用一个bit来标识元素的存在,那么我们只需⌈N/8⌉个字节就可以把数据表示出来也就是12500000字节,约为13MB,比原先的N*8的存储方式少到不知道哪里去了。
对于bitmap中存储的数据进行排序:其实在存储的过程中已经完成了排序
正文
(为了方便,下文将存储bitmap的整数成为bitmap整数)
海量数据的存储
假设该数字为num,则它所对应的bit索引为:第 ⌊num/32⌋ 个bitmap整数中的第 num%32 位
排序
通过每个数字的映射,我们可以得到所需要的bitmap整数个数,我们只需对每个bitmap整数的每一位遍历,当某位为1时,就证明该位所对应的整数存在与原始数据中(其实在存储的过程中,我们通过不断插入数字标识,已经完成了排序),当我们从最低位向最高位遍历时,通过整数与bit索引的逆过程就可以的到原整数,将其一个个输出,我们就能得到原始数据的从小到大排序后的结果,具体实现可以看伪代码
//排序及还原伪代码
//max为bitmap整数个数
for(int i=0;i
if(1&bitmap[i]>>j){
print i*32+j;
}
}
}
注意
① 限于每位只有0,1两个状态,我们无法对有重复数字的海量整数如此排序
② 此种方法适用于数字之间差值比较小的情况(无限趋近于连续数据),若数字之间差值比较大(举个极端的例子:每个bitmap整数中只有一个位为1,其余全为0的情况)时,博主暂时没有想到可行解法……
这里我不再赘述Bitmap的用法以及其他信息了,大家可以参考我的另一篇博文:
Bitmap在海量无重复整数排序时的应用
对比
可能有人会想,Bitmap在处理海量数据时,有着得天独厚的优势,占用内存非常小(每一个数据只占1个bit),即使在处理url、邮件地址等其他类型的数据时,要把字符串变换为整数,也有各式各样的方法。那么我们为什么不用Bitmap来判重而要用布隆过滤器呢?
首先,我们来看,Bitmap的存储空间计算方式是:找到所有元素里面最大的(假设为N),Bitmap所需空间S为: 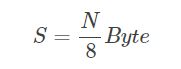
当N为64位整数时,最大的N为2^64,此时S为 2^61 Byte,也就是 2^41 MB,可以说是一个天文数字了……Bitmap的长处非常令人愉悦:空间不随集合内元素个数的增加而增加。但是不足之处也同样明显:空间随集合内最大元素的增大而增大。
比如:在爬虫避免重复下载处理时,若网站数量很多的情况下,用一个64位,甚至是128位的整数来标识URL是家常便饭。此时如果使用bitmap的话,无疑是不明智的。而选择布隆过滤器,由于其可能一个bit为多个元素做标识,这就保证了它的空间利用率。
题目
5TB的硬盘上放满了数据,请写一个算法将这些数据进行排重。如果这些数据是一些32bit大小的数据该如何解决?如果是64bit的呢?
在面试时遇到的问题,问题的解决方案十分典型,但对于海量数据处理接触少的同学可能一时也想不到什么好方案。介绍两个算法,对于空间的利用到达了一种极致,那就是Bitmap和布隆过滤器(Bloom Filter)。
Bitmap算法
在网上并没有找到Bitmap算法的中文翻译,在《编程珠玑》中有提及。与其说是算法,不如说是一种紧凑的数据存储结构。其实如果并非如此大量的数据,有很多排重方案可以使用,典型的就是哈希表。
public int[] removeDuplicates(int[] array) {
int index = 0;
Map
for(int num : array) {
if(!maps.contains(num)) {
array[index] = num;
index++;
maps.put(num, true);
}
}
return newArray;
}
实际上,哈希表实际上为每一个可能出现的数字提供了一个一一映射的关系,每个元素都相当于有了自己的独享的一份空间,这个映射由散列函数来提供(这里我们先不考虑碰撞)。实际上哈希表甚至还能记录每个元素出现的次数,这样的数据结构完成这个任务有点“大材小用”了。
我们拆解一下我们的需求:
集合中每个元素(示例中是int)有一个独享的空间
找到一个到这个空间的映射方法
这个空间要多大?对于我们的问题来说,一个boolean就够了,或者说,1个bit就够了,我们只想知道某个元素出现过没有。如果为每个所有可能的值分配1个bit,32bit的int所有可能取值需要内存空间为:
232bit=229Byte=512MB
232bit=229Byte=512MB
那怎么样完成这个映射呢?其实就是Bitmap所要完成的工作了。如果我们把整型0x01、0x02、…、0x08的空间依次映射到一个Byte上,每个bit就代表这个int值是否出现过,初值为0(false)。
若扩展到整个int取值域,申请一个byte[]即可,示例代码如下:
public static final int _1MB = 1024 * 1024;
//每个byte记录8bit信息,也就是8个数是否存在于数组中
public static byte[] flags = new byte[ 512 * _1MB ];
public static void main(String[] args) {
//待判重数据
int[] array = {255, 1024, 0, 65536, 255};
int index = 0;
for(int num : array) {
if(!getFlags(num)) {
//未出现的元素
array[index] = num;
index = index + 1;
//设置标志位
setFlags(num);
System.out.println("set " + num);
} else {
System.out.println(num + " already exist");
}
}
}
public static void setFlags(int num) {
//使用每个数的低三位作为byte内的映射
//例如: 255 = 0x11111111
//低三位(也就是num & (0x07))为0x111 = 7, 则byte的第7位为1, 表示255已存在
flags[num >> 3] |= 0x01 << (num & (0x07));
}
public static boolean getFlags(int num) {
return (flags[num >> 3] >> (num & (0x07)) & 0x01) == 0x01;
}
其实,就是按int从小到大的顺序依次摆放到byte[]中,仅涉及到一些除以2的整次幂和对2的整次幂取余的位操作小技巧。很显然,对于小数据量、数据取值很稀疏,上面的方法并没有什么优势,但对于海量的、取值分布很均匀的集合进行去重,Bitmap极大地压缩了所需要的内存空间。于此同时,还额外地完成了对原始数组的排序工作。缺点是,Bitmap对于每个元素只能记录1bit信息,如果还想完成额外的功能,恐怕只能靠牺牲更多的空间、时间来完成了。
布隆过滤器(Bloom Filter)
然而Bitmap不是万能的,如果数据量大到一定程度,如开头写的64bit类型的数据,还能不能用Bitmap?我们来算一算:
264bit=261Byte=2048PB=2EB
264bit=261Byte=2048PB=2EB
EB(Exabyte,艾字节)这个计算机科学中统计数据量的单位有多大,有兴趣的小伙伴可以查阅下资料。这个量级的Bitmap,已经不是人类硬件所能承担的了。我相信谁也不会想用集群去计算这么一个问题吧?所以Bitmap的好处在于空间复杂度不随原始集合内元素的个数增加而增加,而它的坏处也源于这一点——空间复杂度随集合内最大元素增大而线性增大。
所以接下来,我们要引入另一个著名的工业实现——布隆过滤器(Bloom Filter)。如果说Bitmap对于每一个可能的整型值,通过直接寻址的方式进行映射,相当于使用了一个哈希函数,那布隆过滤器就是引入了k(k>1)k(k>1)个相互独立的哈希函数,保证在给定的空间、误判率下,完成元素判重的过程。下图中是k=3k=3时的布隆过滤器。
x,y,zx,y,z经由哈希函数映射将各自在Bitmap中的3个位置置为1,当ww出现时,仅当3个标志位都为1时,才表示ww在集合中。图中所示的情况,布隆过滤器将判定ww不在集合中。
那么布隆过滤器的误差有多少?我们假设所有哈希函数散列足够均匀,散列后落到Bitmap每个位置的概率均等。Bitmap的大小为mm、原始数集大小为nn、哈希函数个数为kk:
1个散列函数时,接收一个元素时Bitmap中某一位置为0的概率为:
1−1m
1−1m
kk个相互独立的散列函数,接收一个元素时Bitmap中某一位置为0的概率为:
(1−1m)k
(1−1m)k
假设原始集合中,所有元素都不相等(最严格的情况),将所有元素都输入布隆过滤器,此时某一位置仍为0的概率为:
(1−1m)nk
(1−1m)nk
某一位置为1的概率为:
1−(1−1m)nk
1−(1−1m)nk
当我们对某个元素进行判重时,误判即这个元素对应的kk个标志位不全为1,但所有kk个标志位都被置为1,误判率εε约为:
ε≈[1−(1−1m)nk]k
ε≈[1−(1−1m)nk]k
这个误判率应当比实际值大,因为将判断正确的情况也算进去了。根据著名极限limn→∞(1+1n)n=elimn→∞(1+1n)n=e可以得到:
ε≈[1−e−nkm]k
ε≈[1−e−nkm]k
εε得到最优解1,当且仅当:
k=mnln2≈0.7mn
k=mnln2≈0.7mn
此时,误判率εε与数集大小和
ε≈(1−e−ln2)ln2mn=0.5ln2mn=0.5k
ε≈(1−e−ln2)ln2mn=0.5ln2mn=0.5k
回到我们的问题中,有趣的是由于硬盘空间是限制死的,集合元素个数nn的大小反而与单个数据的比特数成反比,数据长度为64bit时,
n=5TB64bit=5×240Byte8Byte≈234
n=5TB64bit=5×240Byte8Byte≈234
若以m=16nm=16n计算,Bitmap集合的大小为238bit=235Byte=32GB238bit=235Byte=32GB,此时的ε≈0.0005ε≈0.0005。并且要知道,以上计算的都是误差的上限。
布隆过滤器通过引入一定错误率,使得海量数据判重在可以接受的内存代价中得以实现。从上面的公式可以看出,随着集合中的元素不断输入过滤器中(nn增大),误差将越来越大。但是,当Bitmap的大小mm(指bit数)足够大时,比如比所有可能出现的不重复元素个数还要大10倍以上时,错误概率是可以接受的。
最后我们所要做的,就是实现一个布隆过滤器,然后利用它对硬盘上的5TB数据一一判重,并写回硬盘中。这其中可能涉及到利用读写的buffer,待有时间补上。
附录
这里有一个google实现的布隆过滤器,我们来看看它的误判率:
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.util.HashSet;
import java.util.Random;
public class testBloomFilter {
static int sizeOfNumberSet = Integer.MAX_VALUE >> 4;
static Random generator = new Random();
public static void main(String[] args) {
int error = 0;
HashSet
BloomFilter
for(int i = 0; i < sizeOfNumberSet; i++) {
int number = generator.nextInt();
if(filter.mightContain(number) != hashSet.contains(number)) {
error++;
}
filter.put(number);
hashSet.add(number);
}
System.out.println("Error count: " + error + ", error rate = " + String.format("%f", (float)error/(float)sizeOfNumberSet));
}
}
在这个实现中,Bitmap的集合mm、输入的原始数集合nn、哈希函数kk的取值都是按照上面最优的方案选取的,默认情况下保证误判率ε=0.5k<0.03≈0.55ε=0.5k<0.03≈0.55,因而此时k=5k=5。
/**
* Creates a {@link BloomFilter BloomFilter
* insertions and a default expected false positive probability of 3%.
*/
public static
return create(funnel, expectedInsertions, 0.03); // FYI, for 3%, we always get 5 hash functions
}
而还有一个很有趣的地方是,实际使用的却并不是5个哈希函数。实际进行映射时,而是分别使用了一个64bit哈希函数的高、低32bit进行循环移位。注释中包含着这个算法的论文“Less Hashing, Same Performance: Building a Better Bloom Filter”,论文中指明其对过滤器性能没有明显影响。很明显这个实现对于m>232m>232时的支持并不好,因为当大于231−1231−1的下标在算法中并不能被映射到。
enum BloomFilterStrategies implements BloomFilter.Strategy {
/**
* See "Less Hashing, Same Performance: Building a Better Bloom Filter" by Adam Kirsch and
* Michael Mitzenmacher. The paper argues that this trick doesn't significantly deteriorate the
* performance of a Bloom filter (yet only needs two 32bit hash functions).
*/
MURMUR128_MITZ_32() {
@Override public
int numHashFunctions, BitArray bits) {
long hash64 = Hashing.murmur3_128().hashObject(object, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
boolean bitsChanged = false;
for (int i = 1; i <= numHashFunctions; i++) {
int nextHash = hash1 + i * hash2;
if (nextHash < 0) {
nextHash = ~nextHash;
}
bitsChanged |= bits.set(nextHash % bits.bitSize());
}
return bitsChanged;
}
@Override public
int numHashFunctions, BitArray bits) {
long hash64 = Hashing.murmur3_128().hashObject(object, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int nextHash = hash1 + i * hash2;
if (nextHash < 0) {
nextHash = ~nextHash;
}
if (!bits.get(nextHash % bits.bitSize())) {
return false;
}
}
return true;
}
};
...
}