Python数据挖掘实战——KNN算法(K最近邻节点算法,k-NearestNeighbor)
一、分类
分类是用来预测类别数据的一种方法,可以用来预测未来一段时间内用户是否会流失,预测用户是否会响应你的促销活动,能够评估用户的信用度是好还是差的一系列分类预测问题。
二、概念
2.1监督学习(Supervised Learning)
从给定标注的训练数据集中学习出一个函数,根据这个函数为新数据进行标注。(有因变量y)回归分类、分类、时间序列等。
2.2无监督学习(Unsupervised Learning)
从给定五标注的训练数据中学习出一个函数,根据这个函数为所有数据标注。(聚类、因子、关联等)
2.3分类(Classification)
分类算法通过对已知类别训练数据集的分析,从中发现分类规格,以此预测新数据的类别,分类算法属于监督学习。
三、KNN算法(k-NearestNeighbor)

1.找一个距离,例如最小的圆圈,圈内的训练样本数为3个,其中一个为矩形、两个三角形,待分类的数据从距离上看很可能是三角形。但是把虚线放大,放大到虚线的圆圈,其中有3个蓝色的矩形,2个红色的三角形,如果用这个距离绿色的圆很可能是蓝色矩形的分类。
四、分类算法的验证方法——交叉验证(Cross Validation)
4.1训练集(Train Set)
用来训练模型或确定模型参数的数据。
用来验证模型的准确性的数据。
4.3K折交叉验证(K-Fold Cross Validation)
设置k=10,那么我们把原来的数据集随机分为10份,分别为{D1,D2,...,D10},
接着,使用D1作为测试集,{D2,D3,...,D10}作为训练集,计算得分S1
继续,使用D2作为测试集,{D1,D3,...,D10}作为训练集,计算得分S2
……
最后,使用D10作为测试集,{D1,D2,...,D9}作为训练集,计算得分S10
计算这组得分{S1,S2,...,S10}的平均值,作为模型的总和得分 :
综合得分= ![]()
五、IRIS数据集
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
六、案例实战
import numpy
from sklearn import datasets #sklearn 内置了iris数据集
#引入数据集
iris = datasets.load_iris() #控制台可看到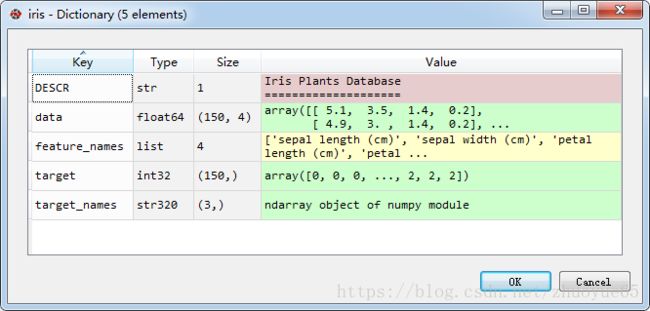
点击data进入可以看到尾150行,4列数据
#查看数据的规模
iris.data.shape
接着,去重分类目标,保留唯一值。
#查看训练目标的总类,一共就3个分类
numpy.unique(iris.target)
#Out[4]: array([0, 1, 2])Sklearn中切分数据集的方法(train_test_split):训练集、测试集切割方法
把特征数据(iris.data)、目标数据(iris.target)作为前面两个方法传入,
from sklearn.model_selection import train_test_split
data_train, data_test, target_train, target_test = train_test_split(
iris.data, #特征数据
iris.target, #目标数据
test_size=0.3#训练占比,一般37分,训练集占比70%,测试集30%
)执行方法会返回4个参数
data_train.shape #特征集的训练集
data_test.shape #特征集的测试集
target_train.shape #目标变量的训练集
target_test.shape #目标变量的测试集
#可以用shap看看这几个数据集的规模,验证切割是否合理

进行KNN分类,KNN分类需要一个参数,建模的个数。
从前面的代码:numpy.unique(iris.target)执行结果看到是3个分类,所以此处:(n_neighbors)我们填3
#调用KNN的建模类k-neighbors
from sklearn import neighbors
#从前面的代码:numpy.unique(iris.target)执行结果看到是3个分类,所以此处:(n_neighbors)我们填3
knnModel = neighbors.KNeighborsClassifier(n_neighbors=3)
#用fit方法训练模型,传入特征集和训练集的数据
knnModel.fit(data_train, target_train)
#把测试集的数据传入即可得到模型的评分
knnModel.score(data_test, target_test)
#Out[9]: 0.93333333333333335
"""以上就是1折交叉验证的得分"""
"""如果要做5折交叉验证,直接调用方法即可。"""
from sklearn.model_selection import cross_val_score
#cross_val_score,接受2个方法:
#一个knn模型,一个特征数据集,一个目标变量的数据集,一个K值
cross_val_score(
knnModel,
iris.data, iris.target, cv=5 #K折交叉验证的值,因为需要5折所以输入5
)
#执行代码返回如下:
#Out[10]: array([ 0.96666667, 0.96666667, 0.93333333, 0.96666667, 1. ])
#使用模型进行预测
knnModel.predict([[0.1, 0.2, 0.3, 0.4]])#传入特征值,即data_test、data_train等数据7.1neighbors.KNeighborsClassifier KNN模型
knnModel = neighbors.KNeighborsClassifier(n_neighbors = 5)
√ n_neighbors 分类的个数
√ 返回 KNN模型,用他来训练和评估模型
7.2knnModel.fit(tData,tTarget) KNN训练方法
√tData 特征集的训练数据
√tTarget 目标集的训练数据
7.3knnModel.score(sData,sTarget) KNN评分方法
√sData 测试数据的属性数据
√sTarget 测试数据的目标数据
7.4knnModel.predict(pData) KNN预测方法
√pData 需要预测的属性数据
√返回 模型预测的结果