DSSD(Deconvolutional Single Shot Detector)算法理解
论文地址:https://arxiv.org/abs/1701.06659
Github 源码(caffe版):https://github.com/chengyangfu/caffe/tree/dssd
1、文章概述
DSSD(Deconvolutional Single Shot Detector)是SSD算法改进分支中最为著名的一个,SSD的其他改进还包括RSSD(https://arxiv.org/abs/1705.09587)、FSSD(https://arxiv.org/abs/1512.02325)等。在VOC2007数据集上,513*513的输入图片上,DSSD的mAP值达到81.5%,但是fps只有6fps左右。
DSSD将SSD的VGG网络用Resnet-101进行了替换,在分类回归之前引入了残差模块,在SSD添加的辅助卷积层后又添加了反卷积层形成“宽 - 窄 - 宽”的“沙漏”结构。DSSD相比SSD的一个最大的提升在于对小目标的检测度上DSSD有了很大的提升,文章的最后部分也展示了小目标的检测效果。即便如此,DSSD的检测速度相比SSD慢了很多,其中很大一部分原因在于引入的Resnet-101太深。
DSSD的网络模型如下图所示:

图中的蓝色部分是SSD在基础网络的基础上添加的辅助层,红色部分是DSSD在SSD的后面添加的反卷积层,红色的反卷积层和蓝色的卷积层对应尺度相同,融合后再送入上面的蓝色框框的Prediction Module模块进行分类回归。
2、Resnet-101替换VGG网络
这么做的目的是提高精度,毕竟Resnet-101比VGG的网络更深,提取的特征就有更高的语义信息,而且Resnet-101的分类精度确实比VGG的高。需要注意的是,在300*300的输入图像下,直接将VGG用Resnet-101替换,精度不升反降;在512*512的输入图像下测试,精度才有略微提升。再加入了Prediction模块和反卷积模块后,精度才有稳定提升。还需注意的是,在300*300的图像上测试,用VGG的SSD有59的FPS,而用Resnet-101的DSSD的fps只有15,Resnet-101更深的网络结构是fps显著降低的原因。
3、PM(Prediction Module)模块
PM模块如下图所示(图片来自博客:https://blog.csdn.net/jesse_mx/article/details/55212179?utm_source=itdadao&utm_medium=referral):
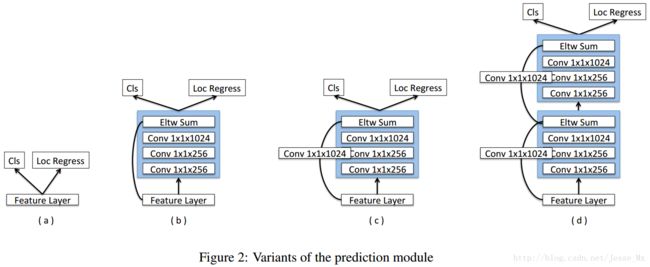
左图(a)是SSD中用于分类和回归用的结构,即在特征图上直接连接1*1的卷积,一个用来分类,一个用于回归。图(c)是文中用于分类和回归的最优结构。图(b)、图(c)、图(d)均是在SSD的基础上将原有的结构改成Resnet模块(不清楚的可以查一下Resnet那篇文章)。这么做的目的是提取更深维度的特征用于分类和回归。添加的位置在反卷积结构之后,分类和回归之前。Eltw sum有两种,一种点和、一种点积,最后实验证明点积的效果最好。
4、DM(Deconvolutional Module)模块
文章最具特色的部分,结构如下图所示(图片来自博客:https://blog.csdn.net/jesse_mx/article/details/55212179?utm_source=itdadao&utm_medium=referral):


DM模块里的要反卷积的高层特征图(图中以A表示)和SSD的卷积的低层特征图(图中以B表示)和最后得到的融合后的卷积图(图中以C表示)与DSSD的沙漏结构中的对应位置如图所示。融合后的特征图C送入Prediction Module模块里,特征图C就对应PM残差结构中的“feature map”。需要注意的是这时的融合特征图C作为下一级DM模块的要反卷积的特征图再进行下一级的DM模块操作。至于2H和2W经过一系列的3*3卷积后仍保持2H*2W的特征图尺寸,个人认为是3*3卷积层中,padding=1,stride=1。
DM模块放在SSD添加的辅助卷积层后面,与SSD中的卷积层网络构成了不对称的“沙漏”结构,也叫“encorder-decorder”结构。为什么设计成不对称的结构作者也在文中很清楚的说明了,可以查看原文。DM模块与整个沙漏结构,更充分利用了上下文信息(context),更充分利用了浅层的特征,从而与SSD相比在小目标和密集目标的检测率上有很大的提高。需要注意的是在融合Conv3_x时,要先加一步Normalization操作,否则不容易训练,因为这一层的梯度过大。
5、反卷积+“宽 - 窄 - 宽”的不对称“沙漏”结构
DSSD的整体网络就是“宽 - 窄 - 宽”的不对称“沙漏”结构,具体结构在前面已经说了,这里主要从理论上分析一下为什么要这么设计,参考了这篇知乎上的文章:https://zhuanlan.zhihu.com/p/33036037?edition=yidianzixun&utm_source=yidianzixun&yidian_docid=0IA1dq0Q&yidian_s=&yidian_appid=
卷积神经网络在结构上存在固有的问题:高层网络的感受野比较大,语义信息表征能力强,但是特征图的resolution低,几何信息的表征能力弱;低层网络的感受野比较小,几何细节信息表征能力强,虽然分辨率高,但是语义信息表征能力弱。SSD采用多尺度的特征图来预测目标,使用具有较大感受野的高层特征信息预测大的物体,具有较小感受野的低层特征信息预测小目标。这样就带来一个问题:使用的低层网络的特征信息预测小目标时,由于缺乏高层语义特征,导致SSD对于小目标的分类结果较差,即SSD没有充分利用低层的特征。而解决这个问题的思路就是对高层语义信息和低层语义信息进行融合,丰富预测回归位置框和分类任务输入的多尺度特征图,以此提高精度。基于此,作者提出了反卷积+“宽 - 窄 - 宽”的不对称“沙漏”结构。
6、DSSD关于default box的改进
针对PASCAL VOC2007和2012里trainval的图片,用k-means对长宽比例做了一个聚类分析,最终确定default box的长宽比例的阿尔法为1、1.6、2和3;SSD的阿尔法为1、2、3、1/2、1/3。
7、DSSD的训练方法
先预训练好一个SSD的模型,然后用训练好的SSD模型来初始化DSSD网络。具体地,训练分为两个阶段,先冻结DSSD网络中SSD网络层的参数,只用预训练好的SSD模型去微调DSSD层的权重(DSSD层的权重的初始化方式为Xavier);第二阶段解冻第一阶段的所有层参数,放开了微调。
但是知乎上那篇文章复现DSSD时说这样训练精度并没有提高,而且特别耗时,反而直接放开所有层微调效果会更好,收敛速度会更快。
具体的实验结果和测试时的新的操作请看原文。
参考博客:
https://blog.csdn.net/jesse_mx/article/details/55212179?utm_source=itdadao&utm_medium=referral
https://zhuanlan.zhihu.com/p/33036037?edition=yidianzixun&utm_source=yidianzixun&yidian_docid=0IA1dq0Q&yidian_s=&yidian_appid=
https://blog.csdn.net/u010725283/article/details/79115477