数据库篇之可视化工具+数据基础理论
//工具部分
mysql-sqlyog
>创建存储过程时需要注意
1 无参数
[DELIMITER //]在这句之后写语句,另外需要在 end之后加上 [//]
2 in/out/inout
在[DELIMITER //]之间写语句,另外需要在 end之后加上 [//]
2.1
模式写在参数前
eg: in XX XXType ,out YY YYType
>一次执行多个sql语句

查询之间使用“;”分隔
使用场景:
1
写查询
编写复杂查询时,可以通过该方法可以看到全部字段,进而可以选取显示字段
2
查数据
将复杂查询拆开,进而可以看到各个字段数据的来源
>格式化查询
格式化查询:
快捷键:f12
>刷新
1
数据库全部刷新:
右键->刷新数据库对象
单个库刷新:
选择要刷新的库,f5
2
通过alter命令对表进行修改后,操作成功之后,先刷新库,然后右键->打开表,即可看到新增的字段
>导出
1
导出sql文件

选择导出类型

设置相关选项进行数据导出
2同步数据
2.1
![]()
2.2
2.2 主页面找图标

2.3

3
导出多张表
找到要导出表的数据库,右键->备份/导出-->备份数据库,转储到sql
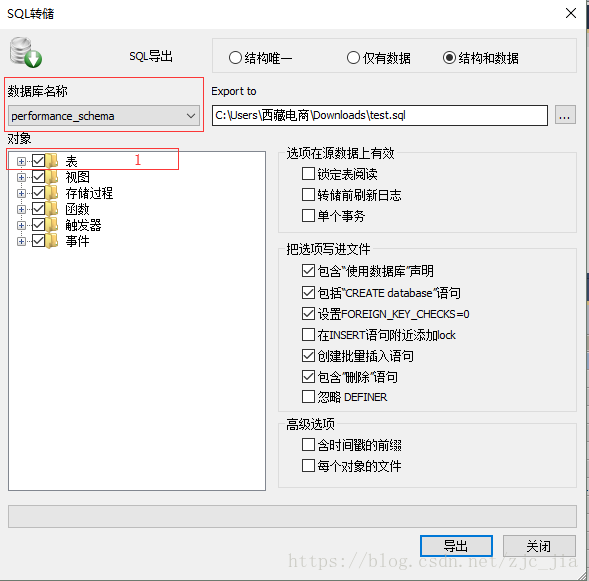
备注:可以通过点击“1”来获取更多的表信息
选择导出的sql
选择导出的数据库
选择导出的路经
选择导出的表
点击导出。
datagrip
日期:2019-6-10
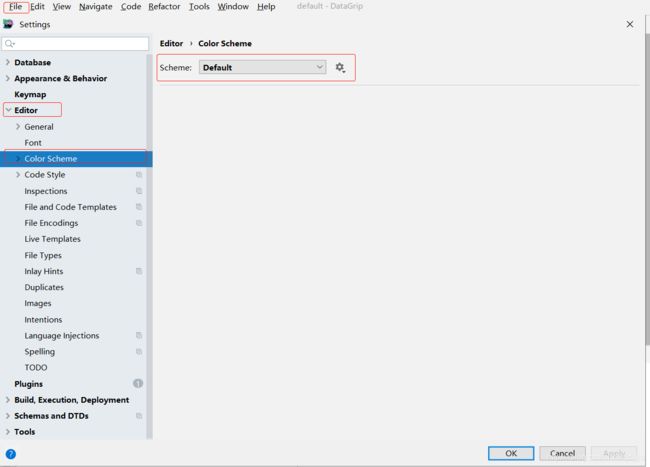
>>datagrip查看连接配置:
如图所示:图中标红部分
>>datagrip连接到库之后,显示的schema
1>如下图:则没有显示任何schema
2>显示的schema
2.1>页面调出
参考:datagrip查看连接配置
2.2>修改方式
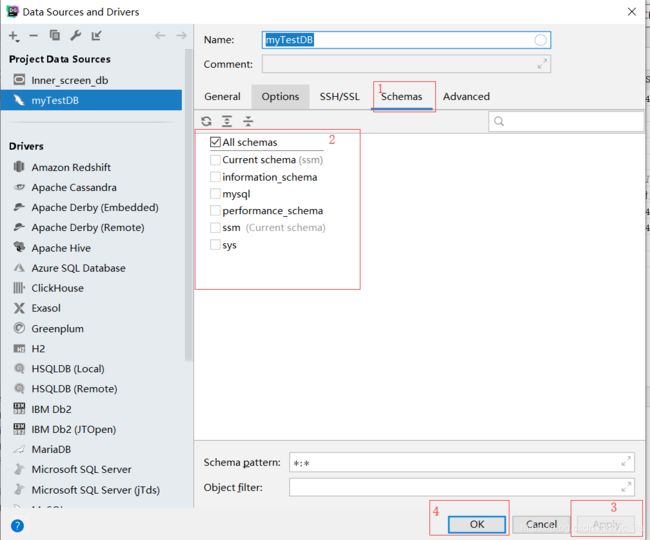
说明:
在2中,勾选需要显示的schema。
在依次点击3,4即可。
>>datagrip连接数据库是提示:
Connection to localhost failed. [08001] Could not create connection to database server. Attempted reconnect 3 times. Giving up
解决方式:
1>在

最后添加 serverTimezone=UTC
好处:该操作属于模板操作,以后的每次新增数据源都会添加上
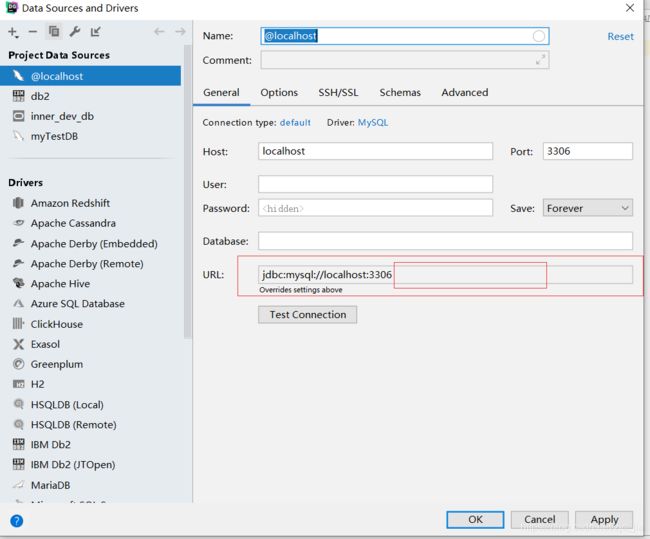
2>
在url最后添加: serverTimezone=UTC
日期:2019-06-17
>>datagrip下载的jar的位置
C:\Users\(自己电脑的用户名)\.DataGrip2019.1\config\jdbc-drivers
>>2019-06-18
datagrip修改表:找到具体的库,找到具体的表,右键选择:modify table

datagrip修改列:选择到要修改的表,找到要修改的列,右键选择:modify column
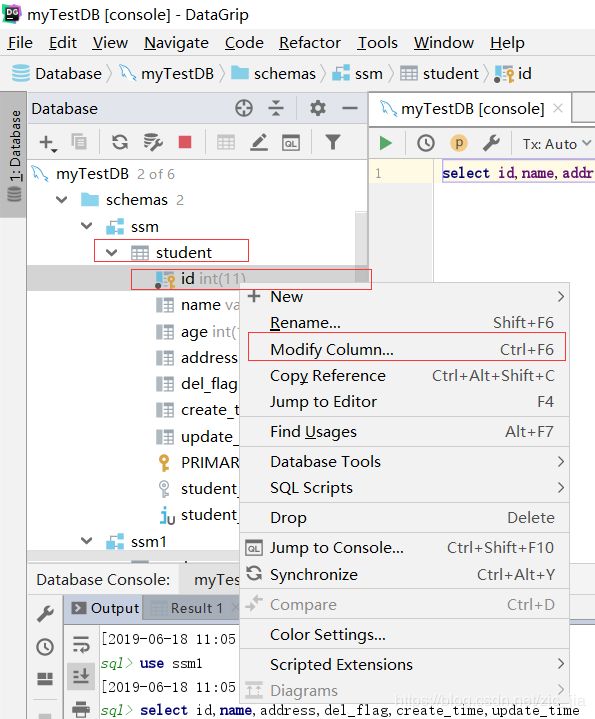
>>日期:2019-06-19
现象:当切换schema之后,无内容显示
解决方案:需要选择schema并进行刷新,
附图:刷新按钮

>>datagrip通过表来筛选数据
1>双击打开对应的表
2>在查找处数据,输入条件:
![]()
3>输入:筛选条件与筛选值
示例:
id='idValue'
4>回车键执行
日期:2019-6-5
可视化工具sqldeveloper ,不显示左边已经连接的窗口
解决:
日期:2019-07-05
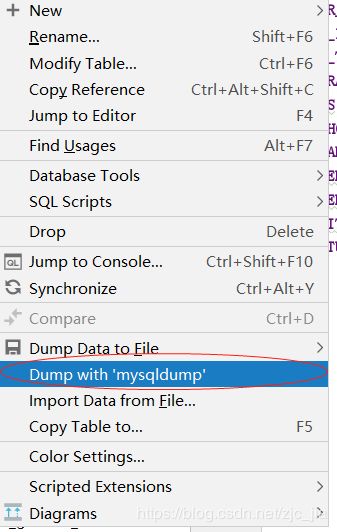
连接mysql数据库只导出表结构操作
选择要导出的表,右键选择操作项-附图:

说明:path to mysqldump ,该项的值指向:mysqldump.exe的具体路径
当进行值导入表结构时,需要加上-d(后面需要空格),形如:
-d ssm --result-file=""
日期:2019-08-19
在连接oracle数据库情况下,设置事务自动提交
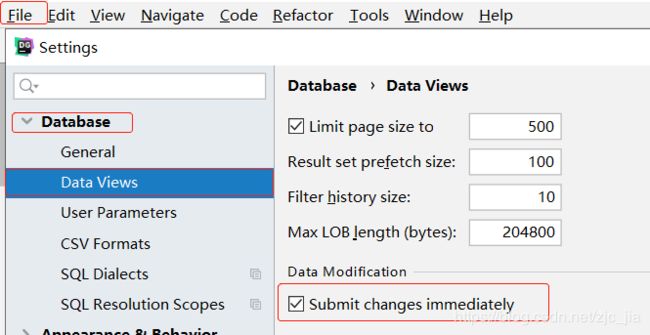
调整datagrip调整背景颜色
navicat for mysql
2020-3-26
//查看表备注
(1)选择查看的表右键选择[对象信息]

选项ddl会有表的详细信息
//理论部分
//mysql数据库
# 0:区分大小写,1:不区分大小写
lower_case_table_names = 1
>mysql与oracle的区别
1
mysql/oracle 的区别
1.1 项目中遇到学习的
使用:
mysql 中小型项目
oracle 大型项目
主键自增
MySql auto increment
Oracle中没有自动增长,主键一般使用序列
字段
mysql varchar/data,time/limit
oracle varchar2/data/rounum
提交方式
oracle默认不自动提交,需要用户手动提交。
mysql默认是自动提交。
1.2 自学,了解到的
并发性
mysql以表级锁为主,对资源锁定的粒度很大
oracle使用行级锁,对资源锁定的粒度要小很多
一致性
oracle支持serializable的隔离级别
mysql没有类似oracle的构造多版本数据块的机制,只支持read commited的隔离级别
逻辑备份
oracle逻辑备份时不锁定数据,且备份的数据是一致的。
mysql逻辑备份时要锁定数据,才能保证备份的数据是一致的,影响业务正常的dml使用。
>like的使用
sql语句like查询,当条件值为多个时,中间使用:“||”分隔
>>Mysql数据库安装包方式安装:(版本8)
1>下载并解压并准备初始化文件
初始化配置文件:
a:新建 ini文件
b:命名 my.ini
c:基本配置
[
[mysqld]
# 设置3306端口
port=3306
# 设置mysql的安装目录
basedir=
# 设置mysql数据库的数据的存放目录
datadir=
# 允许最大连接数
max_connections=200
# 允许连接失败的次数。这是为了防止有人从该主机试图攻击数据库系统
max_connect_errors=10
# 服务端使用的字符集默认为UTF8
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
# 默认使用“mysql_native_password”插件认证
default_authentication_plugin=mysql_native_password
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[client]
# 设置mysql客户端连接服务端时默认使用的端口
port=3306
default-character-set=utf8
]
2>在MySQL安装目录的 bin 目录下操作
2.1>初始化数据库
mysqld --initialize --console
执行完成后,会打印 root 用户的初始默认密码
a:如果没有记住,删除data文件夹,重新执行
2.2>安装服务
mysqld --install
3>启动数据库
net start mysql
4>修改用户密码:
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '新密码';
>Mysql数据库安装包方式安装:(版本8之前)
1安装包下载
2安装包解压
3修改.int文件
3.1 点击解压好的文件可以看到.int文件:
修改int文件名称:.ini文件的名字修改为:my.int
3.2新增如下内容:
#安装目录
basedir =
# 数据库存放目录
datadir =
#端口
port = 3306
说明:
1
在datadir的路径最后面添加\\data
data文件夹必须是新建的,必须为空
Basedir/datadir 路径指向mysql安装包的解压路径
拓展:
除这些之外,还可以添加存储引擎/字符集等
4配置环境变量。
5以管理员身份进入mysql路径下的bin文件夹
6安装
方式一:执行如下命令
1
mysqld --initialize-insecure --user=mysql
2
mysqld --install mysql --defaults-file=[指 .int 文件路径]
注意点:
1
my.ini文件的编码必须是英文编码(如windows中的ANSI),不能是UTF-8或GBK等。
2
该路径需要写在: "" 双引号中
示例:
"d:\\mysql\\mysql-5.7.17-winx64\\my.int"
上述两个命令执行结束:提示:Service successfully installed,表示操作成功。
方式二:执行如下命令
mysqld install
该命令执行结束:提示:Service successfully installed.表示操作成功
7测试安装结果
方式一:
继续在窗口执行命令:net start mysql
该命令执行结束,提示:
MySQL 服务正在启动 .
MySQL 服务已经启动成功。
表示:操作成功
方式二:
通过win+r输入 services.msc 命令,进入服务,找到mysql启动即可
>临时表
使用关键字 :TEMPORARY
类别:
1
内部临时表[/ 轻量级/性能优化]
分类
1.1
heapi 内存
1.2
ondisk 磁盘
2
外部临时表 [关键的时候需要使用:TEMPORARY ;归属:当前用户 ; 销毁:回话结束,表自动关闭]
日期:2018-4-24
concat
1、功能:将多个字符串连接成一个字符串。
2、语法:concat(str1, str2,...)
返回结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null
>添加列
mysql数据库中,表添加一列
ALTER TABLE talbe_name
ADD COLUMN column_name column_type NULL COMMENT 'column_comment' AFTER `table_old_column`,
说明:
table_name 要新增的表名称
column_name 新增列名称
column_type 新增列类型
column_comment 新增列描述
table_old_column:表中原始列/[建议:新增列位于原始表中最后一列之后]
2
表,修改一个列[demo说明:修改表中一个字段的comment]
ALTER TABLE table_name
MODIFY COLUMN update_column_name VARCHAR(64) NULL COMMENT 'update_comment' AFTER `table_old_column` ;
说明:
table_name: 表名称
update_column_name :要修改的列名称
VARCHAR(64) 为原始字段的原始类型,如果需要,则可以修改为自身需要的字段类型
update_commenet: 新修改的comment
>mysql存储引擎:
MyISAM存储引擎:不支持事务、也不支持外键,优势是访问速度快
该存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全
Memory存储引擎使用存在于内存中的内容来创建表
Merge存储引擎是一组MyISAM表的组合
>mysql主从复制:
MySQL Replication:
Replication可以实现将数据从一台数据库服务器(master)复制到一或多台数据库服务器(slave)
默认情况下属于异步复制,无需维持长连接 通过配置,可以复制所有的库或者几个库,甚至库中的一些表 是MySQL内建的,本身自带的
Replication的原理 :
简单的说就是master将数据库的改变写入二进制日志,slave同步这些二进制日志,并根据这些二进制日志进行数据操作
日期:2018-11-19
1>mysql索引
索引我们分为四类来讲 单列索引(普通索引,唯一索引,主键索引)、组合索引、全文索引、空间索引
日期:2019-3-19
1>mysql-sql-优化
explain-查看sql执行计划;type=range
sql中in不应该包含过多的值
select指定具体字段
当需要一条数据的时候,可以使用limit 1
如果排序字段没有用到索引就尽量少排序
尽量少用or
union all 替换 union
不适用 order by rand()
分页;分段
在where子句中避免对字段进行null值判断
不建议%前缀模糊查询
避免在where子句中进行字段表达式操作
日期:2019-06-20
>mysql数据库实例删除
sc delete mysql
//oracle
>开窗函数
分析函数是Oracle专门用于解决复杂报表统计需求的功能强大的函数,它可以在数据中进行分组然后计算基于组的某种统计值,并且每一组的每一行都可以返回一个统计值
分析函数带有一个开窗函数over(),包含三个分析子句:分组(partition by), 排序(order by), 窗口(rows) ,他们的使用形式如下:over(partition by xxx order by yyy rows between zzz)
日期:2019-4-23
>>数据类型及其大小
char|n=1 to 2000字节 ;
NVARCHAR2|varchar2(n) n=1 to 4000字节
DATE|一般占用7个字节的存储空间
TIMESTAMP|7字节或12字节的定宽日期/时间数据类型
日期:2019-6-6
序列
创建语法:
create SEQUENCE SEQUENCE_name
属性:
increment by n 步长
start with n 起始
no|maxvalue/no|minvalue 是否有最大/小值
no|cycle 是否循环
no|cache 是否缓存
伪列
nextval : 返回下一个可用的序列值
currval :获取序列当前的值
日期:2019-08-06
业务场景:数据存在做修改;数据不存在做新增
知识点:MERGE INTO
语句格式与说明:
MERGE INTO tableName
USING ( select column_1, column_2 from tableName) T2
ON ( tableName.column_1=T2.column_1 and tableName.column_2 = t2.column_2 )
WHEN MATCHED THEN
后面跟update语句,注意点:update 语句不需要on条件中的列,不需要跟表名
[
update set
tableName.column_x=value,
tableName.column_Y=value,
tableName.column_Z=value,
]
WHEN NOT MATCHED THEN
后面跟insert语句,注意点:insert 语句不需要添加表名
与mybatis结合使用时,需要使用update标签
日期:2019-08-27
现象: 查询中使用了distinct关键字,且sql中同时使用了order by
运行结果:ORA-01791: 不是 SELECTed 表达式
解决方案:将出现在order by 中的查询字段,一一在sql语句中体现出现
//db2
日期:2019-06-21
db2指定schema
在配置文件,数据库连接配置,url属性最后加入下面的内容:
:currentSchema=Schema_name;说明:前面的冒号是必需的;后面的分号是必须的
日期:2019-07-08
场景:连接db2数据库之后,schema分配的不一定是需要使用的
每次进行sql编写时需要:schema_name.table_name
解决方式
1>db2获取当前的schema
values current schema;
2>修改schema
set current schema ='schema_name'
日期:2019-07-21
查看数据库版本
select * from product_component_version;