Spark基本架构及原理
目标:
- Spark概述
- Spark基本概念
- Spark四大运行模式、运行流程
- spark 与 hadoop
- RDD运行流程
- Spark三大类算子
- Spark Streaming
Spark概述:
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎。
Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类 Hadoop MapRedduce的通用并行框架,Spark拥有Hadoop MapReduce所具有的优点:但不同于MapReduce 的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖据与机器学习等需要迭代的MapRedduce的算法。
Spark是一种与Hadoop相似的开源集群计算环境,但是两者之间有不间还存在一些不同之处,这些有用的不同之处使Spark 在某些工作负载方面表现得更加优越,换句话说,Spark启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark是在Scala语言中实现的,它将Scala 用作其应用程序框架。与Hadoop不同,Spark和Scala能够紧密集成,其中的Scala 可以像操作本地集合对象一样轻松地操作分布数据集。
尽管创建Spark是为了支持分布式数据集上的选代作业,但是实际上它是对Hadoop的补充,可以在Hadoop文件系统中进行并行运行。通过名为Mesos 的第三方集群框架可以支持此行为。Spark由加州大学伯克利分校AMP安验室(Algrihms, Machines and
People Lab)开发,可用来构建大型的、低延迟的数据分析应用程序。
Spark基本概念:
1、Spark特性
高可伸缩性
高容错
内存计算
2、Spark的生态体系
Spark属于BDAS(DBAS,伯利克分析栈)生态体系。
MapReduce属于Hadoop生态体系之一,Spark则属于BDAS生态体系之一。
Hadoop包含了MapReduce、HDFS、HBase、Hive、Zookeeper、Pig、Sqoop等。
BDAS包含了Spark、Shark(相当于Hive)、BlinkDB、Spark Streaming(消息实时处理框架,类似Storm)。
3、Spark的数据读取和存储
Spark可以从以下系统访问数据
Hadoop HDFS 以及HIVE, HBASE 等生态圈部件
Amazon S3
Cassandra, Mongodb
其他流工具如 Flume, Kafka所支持的各协议如 AVRO
另外Spark可以支持一下文件格式: Text (包括CSV JSON 等)
SequenceFiles
AVRO
Parquet
*Spark可以独立于HADOOP单独运行
4、Spark部件和应用平台
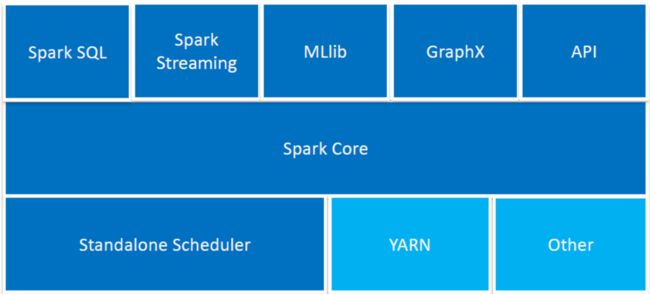
Spark 的主要部件
SPARK CORE:包含spark的主要基本功能。所有跟RDD有关的API都出自于SPARKCORE。
Spark SQL: Spark 中用于结构化数据处理的软件包。用户用户可以在Spark环境下用SQL语言处理数据。
Spark Streaming:Spark 中用来处理流数据的部件
MLlib:Spark 中用来进行机器学习和数学建模的软件包
GraphX:Spark 中用来进行图计算(如社交媒体关系) 的库函数
Cluster Managers:Spark 中用来管理机群或节点的软件平台.这包括Hadoop YARN, Apache Mesos, 和 Standalone Scheduler (Spark 自带的用于单机系统)
SPARK CORE
Spark生态圈的核心:
负责从HDFS、Amazon S3和HBase等持久层读取数据
在、YARN和Standalone为资源管理器调度Job完成分布式计算
包括两个重要部件
有向无环图(DAG)的分布式并行计算框架
容错分布式数据RDD (Resilient Distributed Dataset)
总结SPARK CORE
总体来说SPARK CORE 就是 SPARK 功能调度中心,其中包括任务调动, 内存管理,容错管理及存储管理。同时也是一些 列应用程序的集中地。
这些应用程序用来定义和管理RDD (Resilient DistributedDataset).
RDD代表了一系列数据集合分布在机群的内存中。SPARK CORE 的任务是对这些数据进行分布式计算。
5、Spark支持的API
Spark支持的API包括Scala、Python、Java 、R。
Spark和Hadoop:
6、Spark和MapReduce
相对MapReduce,Spark具有如下优势:
MapReduce通常将中间结果放到HDFS上,Spark是基于内存并行大数据框架,中间结果存放到内存,对于迭代数据Spark效率高。
MapReduce总是消耗大量时间排序,而有些场景不需要排序,Spark可以避免不必要的排序带来的开销。
Spark 是一张有向无环图(从一个点出发最终无法回到该点的一个拓扑),并对其进行优化。
hadoop和Spark对比更多可参考知乎:
https://www.zhihu.com/question/26568496
Spark四大运行模式、流程:
7、
Spark四大运行模式
Local (用于测试、 开发):Spark单机运行,一般用于开发测试。
Standlone (独立集群模式):构建一个由Master+Slave构成的Spark集群,Spark运行在集群中。
Spark on YARN (Spark在 YARN上):Spark客户端直接连接Yarn。不需要额外构建Spark集群。
Spark on Mesos (Spark 在Mesos上):Spark客户端直接连接Mesos。不需要额外构建Spark集群。
详细启动方式可参考博客:
https://blog.csdn.net/zhangxinrun/article/details/54603585
模式分类
批处理:用于大规模的分布式数据处理
spark-submit predict.py
spark-submit --class “SparkPi” target/scala-2.10/realtime-event_2.10-1.0.jar
流方式:Spark流用于传送和处理实时数据
交互方式:常用于处理在内存中的大块数据.较低的延迟性
spark-shell
pyspark
8、Spark运行时的步骤
Driver程序启动多个Worker, Worker从文件系统加载数据并产生RDD (即数据放到RDD
中,RDD是一个数据结构),并按照不同分区Cache到内存中。
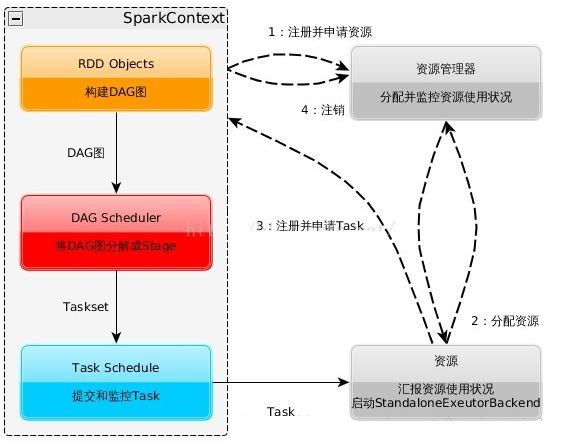
一、构建Spark Application的运行环境,启动SparkContext
二、SparkContext向资源管理器(可以是Standalone,Mesos,Yarn)申请运行Executor资源,并启动StandaloneExecutorbackend
三、Executor向SparkContext申请Task
四、SparkContext将应用程序分发给Executor
五、SparkContext构建成DAG图,将DAG图分解成Stage、将Taskset发送给Task Scheduler,最后由Task Scheduler将Task发送给Executor运行
六、Task在Executor上运行,运行完释放所有资源
Spark运行特点:
一、每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行Task。这种Application隔离机制是有优势的,无论是从调度角度看(每个Driver调度他自己的任务),还是从运行角度看(来自不同Application的Task运行在不同JVM中),当然这样意味着Spark Application不能跨应用程序共享数据,除非将数据写入外部存储系统
二、Spark与资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了
三、提交SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack里,因为Spark Application运行过程中SparkContext和Executor之间有大量的信息交换
四、Task采用了数据本地性和推测执行的优化机制
RDD:
9、RDD
RDD英文名为Resilient Distributed Dataset,中文名为弹性分布式数据集。
什么是RDD? RDD是一个只读、分区记录的集合,你可以把他理解为一个存储数据的数据结构,在Spark中一切操作基于 RDD。
RDD可以通过以下几种方式创建
一、集合转换
二、从文件系统 (本地文件、HDFS.、HBase)输入
三、从父RDD转换(为什么需要父RDD呢?容错, 下面会提及)
RDD的计算类型:
一、Transformation:延迟执行,一个RDD通过该操作产生新的RDD时不会立即执行,只有等到Action操作才会真正执行。
二、Action:提交Spark作业,当Action时,Transformation 类型的操作才会真正执行计算操作,然后产生最终结果输出
三、Hadoop提供处理的数据接口有Map和Reduce,而Spark提供的不仅仅有Map和Reduce,还有更多对数据处理的接口
10. 容错Lineage
每个RDD都会记录自己所依赖的父RDD, 一旦出现某个RDD的某些Partition丢失,可以通过并行计算迅速恢复,这就是容错。
通过并行计算迅速恢复,这就是容错
RDD的依赖又分为Narrow Dependent(窄依赖)和Wide Dependent (宽依赖)
一、窄依赖:每个Partition最多只能给一个RDD使用,由于没有多重依赖,所以在一个节点上可以一次性将Partition处理完,且一旦数据发生丢失或者损坏,可以迅速从上一个RDD恢复
二、宽依赖:每个Partition可以给多个RDD使用,由于多重依赖,只有等到所有到达节点的数据处理完毕才能进行下一步处理,
一且发生数据丢失或者损坏则完蛋了,所以在此发生之前,必须将上一次所有节点的数据进行物化(存储到磁盘上)处理,这样达到恢复。
11、宽、 窄依赖缓存策略
Spark通过useDisk、 useMemory、deserialized、 replication4个参数组成11种缓存策略。
一、useDisk:使用磁盘缓存(boolean) .
二、useMemory:使用内存缓存(boolean).
三、deserialized:反序列化(序列化是为了网络将对象进行传输,boolean: true 反序列化false序列化) .
四、replication:副本数量(int).
通过StorageL evel类的构造传参的方式进行控制,结构如下:
class StorageLevel private (useDisk : Boolean ,useMemory : Boolean , deserialized : Boolean ,replication: Ini)
12.提交的方式
spark-submit(官方推荐)
sbt run
ava -jar
提交时指定各种参数:
1.num-executors 50~100
2.executor-memory 4G~8G num-executors乘以executor-memory,就代表了你的Spark作业申请到的总内存量,这个量是不能超过队列的最大内存量的
3.executor-cores 2~4
4.spark.default.parallelism 用于设置每个stage的默认task数量,Spark作业的默认task数量为500~1000个较为合适,设置该参数为num-executors * executor-cores的2~3倍较为合适
提交示例以参数可参考博客:
https://www.cnblogs.com/gnool/p/5643595.html
https://blog.csdn.net/diannao720/article/details/73325703
Spark三大算子操作参考笔者博客:
Spark中RDD的Value型Transformation算子操作(一):Spark中RDD的Value型Transformation算子操作(一)
Spark中RDD的Key-Value型Transformation算子操作(二):Spark中RDD的Key-Value型Transformation算子操作(二)
Spark中Actionn算子操作(三):Spark中Actionn算子操作(三)