为什么「顶级量化对冲基金们」要自建人工智能平台?
来源 : AI金融评论| aijinrongpinglun 作者:袁峻峰 蚂蚁金服人工智能部,复旦金融学硕士,FRM金融风险管理师。

近日对冲基金公司「幻方」自建超级计算机,在业界引起热议。
近日,国内领先的对冲基金公司「幻方」宣布,其新一代AI超级计算机“萤火一号”,已于2020年3月正式投入运行。
该服务器是由一个存储集群和一个计算集群组成。存储集群提供4.1Tbps读写带宽以及1.2PB容量。计算集群搭载1100张高端显卡,每秒可以进行1.84亿亿次浮点运算,相当于4万台个人电脑算力。
在全球著名对冲基金Two Sigma的主页上,公司介绍中写到,只有基于数据的、不断优化迭代的科学方法才是最好投资方式。他们使用42 PB(1PB=1000TB,1TB=1000GB)数据用于投资模型,涵盖了10000个以上的数据源,并使用33万个CPU以上的集群处理数据。
数字化时代
数字化时代,基于传统统计、计量的方法已无法处理如此大的数据量。而机器学习、深度学习的优势随着大数据、计算机处理能力的飞速发展逐渐展现出来。
数据驱动的量化策略,是指通过相关数据,直接识别金融市场的模式或规律,寻找投资机会,这一直是对冲基金主流的策略模式之一。在数字化时代,这类策略将越来越得到重视,而机器学习自然是这类策略主要的技术与方法之一。
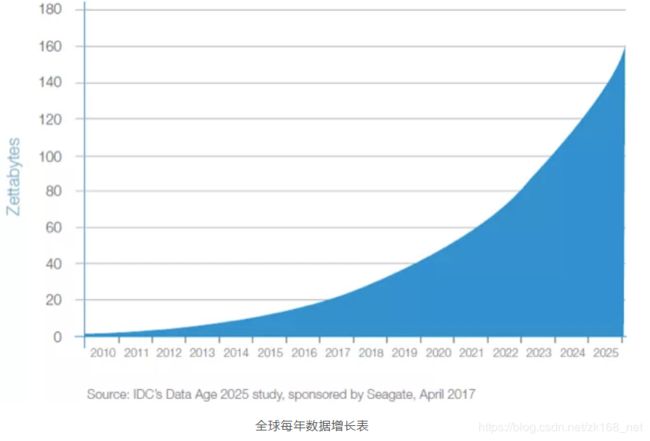
数据近几十年都一直在指数级增长, 当5G全面普及,物联网中各样设备接入互联网,每年产生的数据还将几何式爆炸增长。
IDC预计,到2025年全球数据每年将达到163ZB。
随着石油的价格一降再降,将数据比作世界上最有价值的资源,已然没有任何疑问。
数据将使我们有机会改进我们的决策,在经济、社会中的作用将更加举足轻重。越来越多的公司使用这些数据用于企业自身决策,并为他们的客户提供更好的服务。那些能够充分利用数据为用户服务,解决问题的企业将会在新的竞争中脱颖而出。
在金融投资领域亦是如此,来自手机、社交媒体、物联网各式传感器的数据,将对金融投资机构的数据处理能力提出挑战。
能收集更大范围、更实时的数据,并有能力处理分析并发现新投资价值的机构,必将获得更强的竞争力。
数据是墙壁上的投影
信息是用来消除随机不确定性的东西。
——— 香农(Shannon)
柏拉图在《理想国》中有一个著名的比喻——洞穴之喻(Allegory of the Cave)。
设想在一个地穴中有一批囚徒,他们自小被锁链束缚,不能转头,只能看见面前洞壁上的影子。
在他们后上方有一堆火,有一条横贯洞穴的小道,沿小道筑有一堵矮墙,如同木偶戏的屏风。
人们扛着各种器具走过墙后的小道,而火光便把那些器物的影像投射到面前的洞壁上,囚徒自然地以为影子是惟一真实的事物。
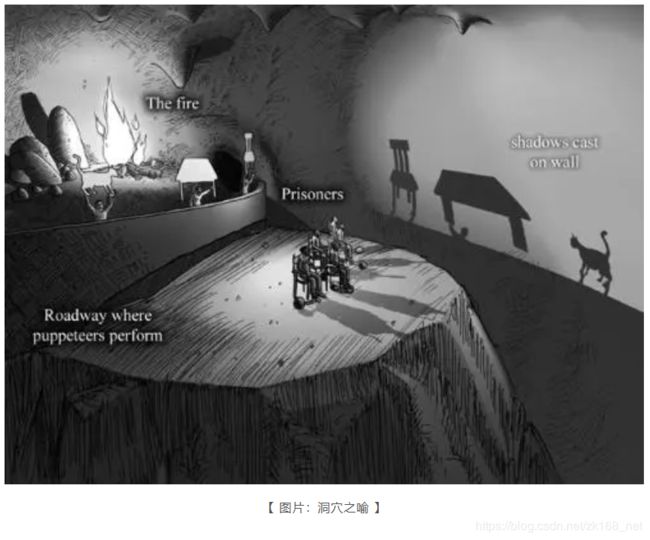
洞穴之喻简直是关于事实与数据之间关系最好的解读。
数据就像印在壁洞上的影像——人们试图利用低维的数据,去描绘一个高维的事实。这和我们认为,在数字化时代亦不存在全局性信息,大抵是一个含义。
但数字化时代,墙壁上将不再是火把的倒影,各种器具进行数据化处理,可以生成一个全息的影像,这必然能让洞穴人感知到一个更加真实的世界。
不远的未来,随着物理世界数字化不断发展,数据就不再是一个火把照出的影像,而是成为一个全息影像。更多维度、更实时的数据,将帮助我们真正理解我们的周遭环境、事物以及我们自己。
信息的基本作用是消除人们对事物的不确定性。
信息熵(Information Entropy)是对信息的量化度量,也是对不确定性的度量。关于信息熵,还有更准确的公式描述,感兴趣的读者请参考相关专业书籍。这里只需要了解,信息和不确定性是逆向关系,有效信息可以减少不确定性,增加确定性。
金融市场,如果对某个资产价格非常不确定,市场参与各方都有不同预期,资产价格就会剧烈波动。需要大量信息才能消除这不确定性,随着信息不断在市场中传播,资产价格的不确定性也不断下降逐步趋于均衡价。
我们强调经济、社会中是存在不确定性的。哈耶克有一段关于经济不确定性不能被统计有效消除的论述:”经济学家们越来越容易忘记组成整个经济体系的经常不断的小变化,其原因之一也许是他们越来越耽于统计总数,这种统计总数比具体细节的运动表现出更大的稳定性。
然而,这种统计中的相对稳定性并不能像统计学家时常想做的那样以’大数定律’即随机变化的相互补偿来解释。我们必须处理的因素,其数量并非大得足以使这些偶然力量产生稳定性。
货物和服务的不间断流动得以维持,是由于持续不断的精心调节,由于每天要根据前一天所不知的情况做出新的安排,由于一旦A不能交付就马上由B代替。”
笔者非常认同,但数字化时代,将改进原有人们基于统计的决策。
随着收集技术以及各类传感器不断优化,生产过程中哪些是由A交付,哪些是由B交付都被记录下来,再加上实时反馈系统,从而有可能实现更高效的调度。
而且,原有抽样统计中被忽略的变量也将被有效收集,大数据不同于统计样本抽样,是更大的样本集,甚至是全样本集,有效避免样本统计过程中的信息损失。
数字化时代离不开机器学习
面对大数据集时,部分统计学习算法无法处理大数据的高维、稀疏、海量等特性。
之后,随着分布式存储、计算技术、分布式机器学习平台的发展,机器学习能够有效处理更大规模的数据集,大数据的价值才更好的得到体现,才有了数据被认为是世界上最重要的资源一说。所以,大数据与机器学习是相辅相成的。
相对于大数据的兴起,机器学习、人工智能已经过半个多世纪的发展,几经兴衰,冷暖沉浮,兴时,改变世界;衰时,无法就业。虽然有人说这几年机器学习大热,可能会和之前几次人工智能浪潮一样退去。
但笔者相信,即使在热潮中,机器学习会有些被滥用,但年深月久,经过专家学者们持续不断地探索,不可逆转的数字化进程,不间断的计算能力提升,大可乐观。只有在数字化时代,机器学习、人工智能才成为一个不退去的浪潮。
目前,通常所说的大数据,数据量都达到PB级以上,必须借助于云计算才能处理。
而且在大数据上的建模已然离不开机器学习和深度学习。那些图像识别、翻译、无人驾驶等领域,都是因为有了大数据集,才发挥了深度学习的优势。
大数据将原有抽样样本集变为全量样本集,呈现出抽样样本上无法揭示的规律。并且机器学习、深度学习模型在大数据集上,能够更有效地学习之前统计模型中忽略的那些结构和关系,这也是之前所说数据中无法处理的信息中的一部分,从而可能得到更好的模型预测效果。
在数据处理、收集成本的下降的同时,机器学习、算法的成本也下降了,并且易用性也提高了。机器学习算法的实现已然不是各领域应用人工智能需要考虑的问题。
那些云计算供应商们会不断降低机器学习的应用成本并提高易用性。也就是说预测的性价比将越来越高,金融投资领域也不例外,机器学习的应用将无处不在。
另外,金融投资领域和各行各业的发展都息息相关,既然实体经济都在数字化、智能化,自然金融投资领域也必须数字化、智能化。
自建大数据、机器学习平台的好处与缺点
通常来说,对于金融投资机构,选择外部云计算服务商也是比较合适的选择。
那另一个问题来了,为什么顶级金融投资机构需要自建平台、系统呢?
当金融投资机构的目标是在他们的公司中投资的决策各个环节嵌入大数据,进行投资全流程数字化升级,将数据的分析结果作为投资依据的重要来源。
那么外部的大数据供应商或咨询机构都无法代替公司内部的大数据团队。数据团队的工作分成两大部分,一是搭建数据存储和计算平台,二是提供数据产品和数据服务。
对数据平台有更高掌控要求的机构来说,在开源大数据技术上,构建定制化大数据存储和计算平台亦是不错的选择。数据处理团队则主要负责对各类业务数据进行清洗、加工、分类以及挖掘分析,然后把数据结果存储到数据平台,构建公司的数据中心。
在互联网行业,大数据效果非常容易体现。
采集、处理并利用数据,可以实现改善用户体验或研发新产品等作用,依托数据化运营吸引、留住用户并使之活跃是互联网公司的生存之道。
这些都有明确的相关指标量化效果,所以大数据团队的价值很容易被认可。然而在金融机构的数据处理团队并不直接参与投资,往往是作为中后台支持团队,其价值多是通过与前中台团队有效合作产生。
如果公司是一个数据驱动型投资公司,在投资决策体系依据数据支持,数据团队职能定位比较明确,并拥有较好的信息化基础和较强的数据驱动意识,那么大数据团队比较容易产生价值。
但,如果公司高层和业务团队对数据团队有着过高的期待,团队职能定位不明确,数据团队本身投资领域知识不足的话,大数据团队的价值将难以发挥。
所以,金融机构有效利用大数据团队一般需具备以下几点:
公司高层认可大数据的价值,清晰的大数据团队目标。打造一支数据科学团队是有一定成本的,建立大数据团队前,必须在高层达成一致,确认投入资源打造一支数据科学团队的必要性,并能明确团队目标和期待。
将大数据和数据分析纳入投资决策流程。数据在投资中的作用是不言而喻的,但对新的大数据集,交易团队和量化、风控等团队往往心存疑虑,需要建立合适的流程,确保大数据集经过验证后进入投资决策。鼓励交易团队、量化团队多多接触大数据集,共同探讨新数据集的价值。只有大数据能够真正应用于投资,大数据团队的价值才能显现。
寻找到合适的数据人才。对于金融机构的大数据团队,往往倾向于有金融背景的大数据和机器学习人才,但这方面人才在国内相对较少,而且互联网行业也在大力争夺相关人才。只要明确各团队职责,可适当放宽要求,不同背景的人员也是能够有效合作的。
一般来说,机器学习团队是和大数据团队划归为后台支持团队的。
由于并不直接参与投资,机器学习团队价值是通过与前中台团队有效合作体现的。
另外一种组织方案是将机器学习团队划入前、中台量化团队,这样更有利于机器学习算法直接应用于交易策略以及风险模型中,但这时就需要和后台大数据团队有效合作了。
不论如何选择组织架构,目的都是为了将大数据和机器学习纳入投资决策流程中。将大数据,机器学习融入原有金融投资机构在线交易决策、风控系统中,并支持线下策略、风控模型研究,这将涉及整体公司内IT系统的重构。
但这样的趋势已不可避免,面对数字化时代不断发展,物理世界、实体经济数字化进程加速,金融投资机构应该以更加开放的心态,将机器学习等技术有效融合到原有投资决策流程中才能获得行业竞争优势。
既然谈了自建大数据、机器学习平台的好处,那也应该说说缺点:费钱。
需要和互联网公司挣强人才。即使金融机构给的待遇更高些,但考虑到学习环境、股权激励等原因,一般大家还是更愿意选择互联网公司。当然,对于不差钱的顶级投资机构来说,自然不在考虑之列,原微软首席人工智能科学家邓力就加盟了对冲基金巨头之一Citadel公司。
最后,笔者要喊句,虽然金融投资市场不是公平的,过去不是,现在也不是,将来应该也不是。但如果,市场中的新座次取决于谁拥有最强的机器、最多的数据、最厉害的算法,那亦是违背市场机制了。更多的论述请参见即将出版的《人工智能为金融投资带来了什么》。
推荐阅读:
1.一个量化策略师的自白(好文强烈推荐)
2.股票期货经典的量化交易策略都在这里了!(源码)
3.期货/股票数据大全查询(历史/实时/Tick/财务等)
4.一个完整的量化交易系统都需要哪些功能?
5.学习Python有哪些书籍?这里有一份书单送给你
6.江湖中常说的“网格交易法”到底是什么?
7.10种经典的日内交易策略模型思路
8.干货 | 量化选股策略模型大全
9.量化金融经典理论、重要模型、发展简史大全