30.kafka数据同步Elasticsearch深入详解(ES与Kafka同步)
1、kafka同步到Elasticsearch方式?
目前已知常用的方式有四种:
1)logstash_input_kafka插件;
缺点:不稳定(ES中文社区讨论)
2)spark stream同步;
缺点:太庞大
3)kafka connector同步;
4)自写程序读取、解析、写入 
本文主要基于kafka connector实现kafka到Elasticsearch全量、增量同步。
2、从confluenct说起
LinkedIn有个三人小组出来创业了—正是当时开发出Apache Kafka实时信息列队技术的团队成员,基于这项技术Jay Kreps带头创立了新公司Confluent。Confluent的产品围绕着Kafka做的。
Confluent Platform简化了连接数据源到Kafka,用Kafka构建应用程序,以及安全,监控和管理您的Kafka的基础设施。
confluent组成如下所示: 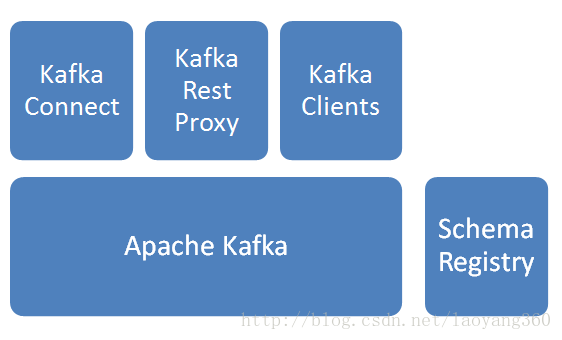
1)Apache Kafka
消息分发组件,数据采集后先入Kafka。
2)Schema Registry
Schema管理服务,消息出入kafka、入hdfs时,给数据做序列化/反序列化处理。
3)Kafka Connect
提供kafka到其他存储的管道服务,此次焦点是从kafka到hdfs,并建立相关HIVE表。
4)Kafka Rest Proxy
提供kafka的Rest API服务。
5)Kafka Clients
提供Client编程所需SDK。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
默认端口对应表:
组件 | 端口
Apache Kafka brokers (plain text):9092
Confluent Control Center:9021
Kafka Connect REST API:8083
REST Proxy:8082
Schema Registry REST API:8081
ZooKeeper:2181
3、kafka connector介绍。
Kafka 0.9+增加了一个新的特性 Kafka Connect,可以更方便的创建和管理数据流管道。它为Kafka和其它系统创建规模可扩展的、可信赖的流数据提供了一个简单的模型。
通过 connectors可以将大数据从其它系统导入到Kafka中,也可以从Kafka中导出到其它系统。
Kafka Connect可以将完整的数据库注入到Kafka的Topic中,或者将服务器的系统监控指标注入到Kafka,然后像正常的Kafka流处理机制一样进行数据流处理。
而导出工作则是将数据从Kafka Topic中导出到其它数据存储系统、查询系统或者离线分析系统等,比如数据库、 Elastic Search、 Apache Ignite等。
KafkaConnect有两个核心概念:Source和Sink。 Source负责导入数据到Kafka,Sink负责从Kafka导出数据,它们都被称为Connector。
kafkaConnect通过Jest实现Kafka对接Elasticsearch。
4、kafka connector安装
实操非研究性的目的,不建议源码安装。
直接从官网down confluent安装即可。地址:https://www.confluent.io/download/
如下,解压后既可以使用。
[root@kafka_no1 confluent-3.3.0]# pwd
/home/confluent/confluent-3.3.0
[root@kafka_no1 confluent-3.3.0]# ls -al
total 32
drwxrwxr-x. 7 root root 4096 Dec 16 10:08 .
drwxr-xr-x. 3 root root 4096 Dec 20 15:34 ..
drwxr-xr-x. 3 root root 4096 Jul 28 08:30 bin
drwxr-xr-x. 18 root root 4096 Jul 28 08:30 etc
drwxr-xr-x. 2 root root 4096 Dec 21 15:34 logs
-rw-rw-r--. 1 root root 871 Jul 28 08:45 README
drwxr-xr-x. 10 root root 4096 Jul 28 08:30 share
drwxrwxr-x. 2 root root 4096 Jul 28 08:45 src- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
5、kafka connector模式
Kafka connect 有两种工作模式
1)standalone:在standalone模式中,所有的worker都在一个独立的进程中完成。
2)distributed:distributed模式具有高扩展性,以及提供自动容错机制。你可以使用一个group.ip来启动很多worker进程,在有效的worker进程中它们会自动的去协调执行connector和task,如果你新加了一个worker或者挂了一个worker,其他的worker会检测到然后在重新分配connector和task。
6、kafka connector同步步骤
前提:
$ confluent start- 1
如下的服务都需要启动:
Starting zookeeper
zookeeper is [UP] ——对应端口:2181
Starting kafka
kafka is [UP]——对应端口:9092
Starting schema-registry
schema-registry is [UP]——对应端口:8081
Starting kafka-rest
kafka-rest is [UP]
Starting connect
connect is [UP]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
可以,netstat -natpl 查看端口是否监听ok。
步骤1:创建topic
./kafka-topics.sh --create --zookeeper 110.118.7.11 :2181 --replication-factor 3 --partitions 1 --topic test-elasticsearch-sink- 1
步骤2:生产者发布消息
假定avrotest topic已经创建。
./kafka-avro-console-producer --broker-list 110.118.7.11:9092 --topic test-elasticsearch-sink \
--property value.schema='{"type":"record","name":"myrecord","fields":[{"name":"f1","type":"string"}]}'
{"f1": "value1"}
{"f1": "value2"}
{"f1": "value3"}- 1
- 2
- 3
- 4
- 5
- 6
步骤3:消费者订阅消息测试(验证生产者消息可以接收到)
./kafka-avro-console-consumer --bootstrap-server 110.118.7.11:9092 :9092 --topic test-elasticsearch-sink --from-beginning- 1
步骤4:connector传输数据操作到ES
./connect-standalone ../etc/schema-registry/connect-avro-standalone.properties \
../etc/kafka-connect-elasticsearch/quickstart-elasticsearch.properties- 1
- 2
注意此处: connect-standalone模式,对应 connect-avro-standalone.properties要修改;
如果使用connect-distribute模式,对应的connect-avro-distribute.properties要修改。
这里 quickstart-elasticsearch.properties :启动到目的Elasticsearch配置。
quickstart-elasticsearch.properties**设置**:
name=elasticsearch-sink
connector.class=io.confluent.connect.elasticsearch.ElasticsearchSinkConnector
tasks.max=1
#kafka主题名称,也是对应Elasticsearch索引名称
topics= test-elasticsearch-sink
key.ignore=true
#ES url信息
connection.url=http://110.18.6.20:9200
#ES type.name固定
type.name=kafka-connect- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
7、同步效果。

curl -XGET 'http:// 110.18.6.20 :9200/test-elasticsearch-sink/_search?pretty'
8、连接信息查询REST API
- -
GET /connectors – 返回所有正在运行的connector名。
- POST /connectors – 新建一个connector; 请求体必须是json格式并且需要包含name字段和config字段,name是connector的名字,config是json格式,必须包含你的connector的配置信息。
- GET /connectors/{name} – 获取指定connetor的信息。
- GET /connectors/{name}/config – 获取指定connector的配置信息。
- PUT /connectors/{name}/config – 更新指定connector的配置信息。
- GET /connectors/{name}/status – 获取指定connector的状态,包括它是否在运行、停止、或者失败,如果发生错误,还会列出错误的具体信息。
- GET /connectors/{name}/tasks – 获取指定connector正在运行的task。
- GET /connectors/{name}/tasks/{taskid}/status – 获取指定connector的task的状态信息。
- PUT /connectors/{name}/pause – 暂停connector和它的task,停止数据处理知道它被恢复。
- PUT /connectors/{name}/resume – 恢复一个被暂停的connector。
- POST /connectors/{name}/restart – 重启一个connector,尤其是在一个connector运行失败的情况下比较常用
- POST /connectors/{name}/tasks/{taskId}/restart – 重启一个task,一般是因为它运行失败才这样做。
- DELETE /connectors/{name} – 删除一个connector,停止它的所有task并删除配置。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
9、小结。
他山之石,可以攻玉。
kafka上的小学生,继续加油!
参考:
[1]kafka-connect部署及简介:http://t.cn/RiUCaWx
[2]connector介绍:http://orchome.com/344
[3]英文-同步介绍http://t.cn/RYeZm7P
[4]部署&开发http://t.cn/RTeyOEl
[5]confluent生态链http://t.cn/RTebVyL
[6]快速启动参考:https://docs.confluent.io/3.3.0/quickstart.html
[7]ES-connector:http://t.cn/RTecXmc