免费使用谷歌GPU,深度学习最好用的jupyter工具 colab
原英文链接https://medium.com/deep-learning-turkey/google-colab-free-gpu-tutorial-e113627b9f5d
转翻译http://www.bubuko.com/infodetail-2524001.html
数据分析神器Colab的初探

为什么要使用Colab
使用过Jupyter(参看《「极客时间」带来的社区价值思考》章节:社区交流的基建设施)的朋友,一定会醉心于它干净简洁的设计,以及在“摆脱Python命令行运行”上提供的优质服务。某种意义上讲,Jupyter的简洁设计,非常适合于初学编程的朋友。因为从整体看,整个Jupyter所提供的界面像是学生时代老师提供的PPT演讲大纲。而唯一不同的是,在Jupyter里面,那些作为示例文档的代码,可以被真实运行起来。对于真正从事过教学和喜欢探索的人来讲,这个优雅的小功能,有着难以言说的奇妙和舒适感。
但这远远不够。对于一般的“门外汉”来讲,或者对于那些仅仅想要随手做一个轻便小实验的研究者来讲,Jupyter还是过重了。为什么呢?因为Jupyter提供的是一套组装工具,类似于宜家售卖的拼接家具。你可以通过Jupyter提供的这套基建设施组合出一副精致的“家具”,但必须经历拼接的繁琐:例如Jupyter软件的安装、各种Machine Learning代码库的“先下载后安装”,以及最为反人性的:你必须在本地占用一个端口启动一个server,还得保持这个server的运行。
从程序角度讲,它的这套逻辑毫无问题。可从用户角度讲,这些繁琐的基础设施消耗,会大大磨灭探索者前进的欲望。还没开始真正的数据分析,就已经准备放弃了。
一个相对折中的办法,是购买一台虚拟机,在它上面开辟出一个端口来长时间运行Jupyter。但这也需要不怎么省力的一番折腾。
那有没有什么更为优质的解决方案呢?!答案是,yes。
那就是Google提供的Colab(https://colab.research.google.com 看不到的同学,请自行搭建梯子),以及Kaggle社区提供的Kernel环境。
事实上,最先让我注意到的,是Kaggle社区的Kernel。我想,这个功能的提供,必定引发了很多数据科学研究者加入Kaggle社区。但数据竞赛,又是Kaggle的一个包袱。这套Kernel,几乎是完全根植在Kaggle竞赛里的。为了使用它,你不得不拥有一个Kaggle账号(典型的Growth Hacker套路),进而再在Kaggle复杂的界面中,找到Kernels 按钮,默默新建一个工作界面。
在最初使用Kernel的惊喜之余,我直接想到的便是:Kaggle应该将这个东西单独拿出来做,而不是被数据竞赛限制住自己的脚步。
可毕竟是创业公司,资源稀少,不敢随意胡乱使用。等到Google将Kaggle收购后,这位从来喜好有趣的大老爹,便毫不留情地将这个部分给吃掉,发布了Colab。
更让人惊喜的是,这位有钱的大老爹,还提供了GPU这个让我等平民无法仰视的重要资源:免费使用 Nvidia Tesla K80 GPU !!!

虽然有很多吐槽的声音认为:便宜无好货,这个鸡肋的资源在某些情形下还不如CPU跑得快。
但我想说的是,如果你知道GPU是未来,也相信摩尔定律会让你在不久的将来也能用上GPU,你难道不应该更加去在意如何快速、先人一步掌握这块技术魔法石,而不是关注它在不久后便会有重大提升的效率么?比起机器提升的效率来讲,自己的学习速率不才是瓶颈吗?
如何使用Colab
基于Google Drive的存储
首先,Colab的notebook是存放在你自己的Google Drive里面的。对于熟练使用Google Docs的同学来说,这是自然而然的事情。你可以自己在Google Drive里面新建一个文件夹作为notebook的存放地,也可以直接使用默认文件夹 Colab Notebooks(下图金黄色的文件夹即是):
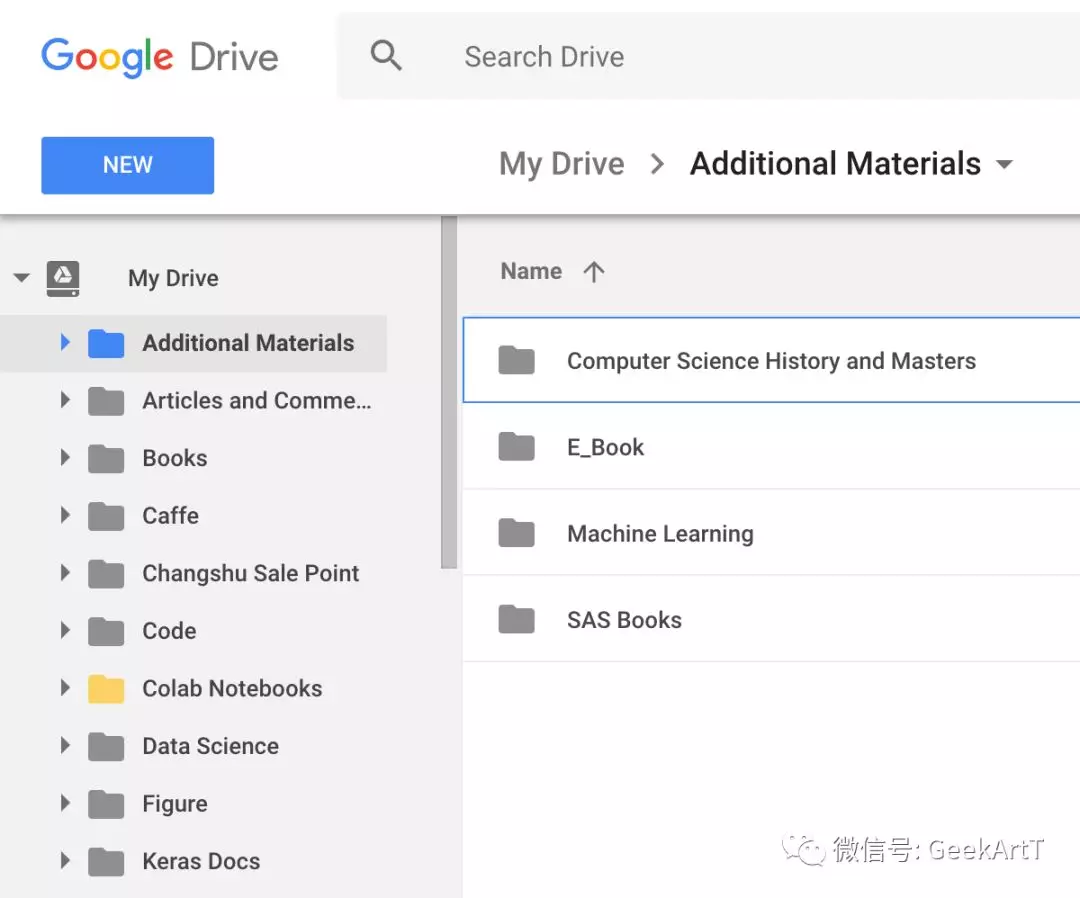
新建Colab notebook既可以在colab.research.google.com界面中,也可以直接在Google Drive里:
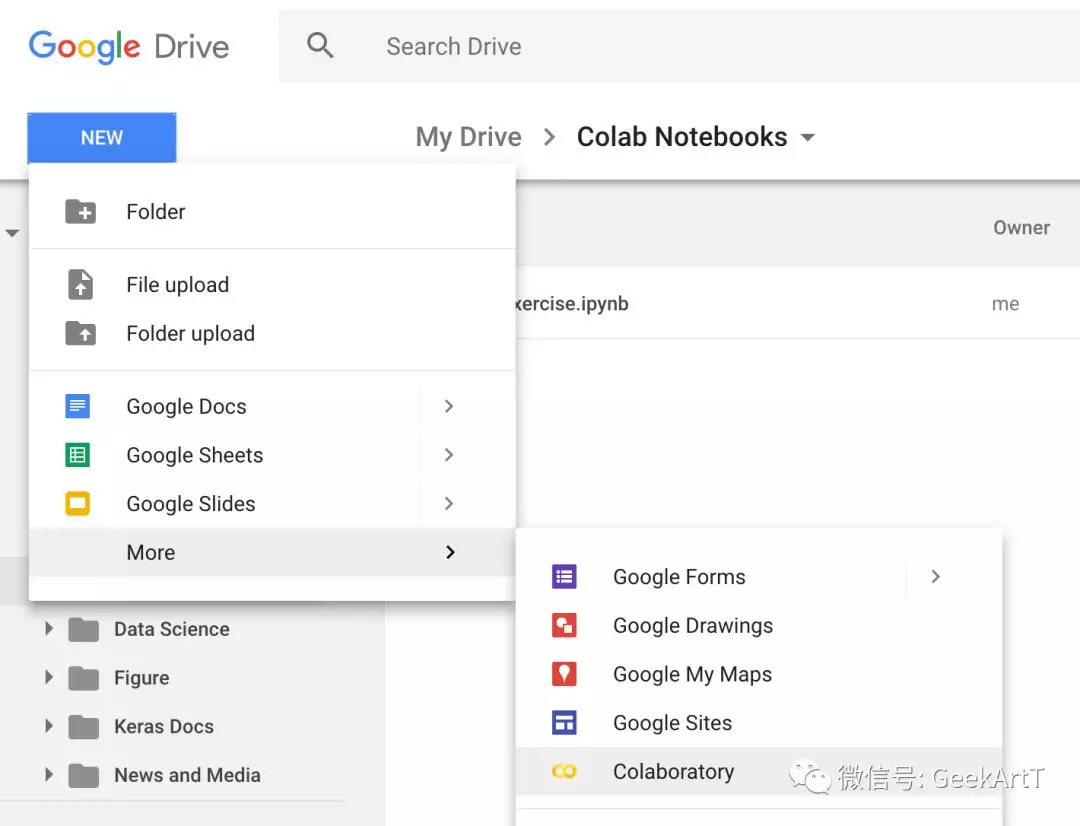
新建好了notebook,在Colab的展现出来便是这样:

整个notebook的运行方式,和Jupyter基本一致。一些细微的文档操作上,例如Cell上下移动,Google做了些自己的定制。
如何使用GPU
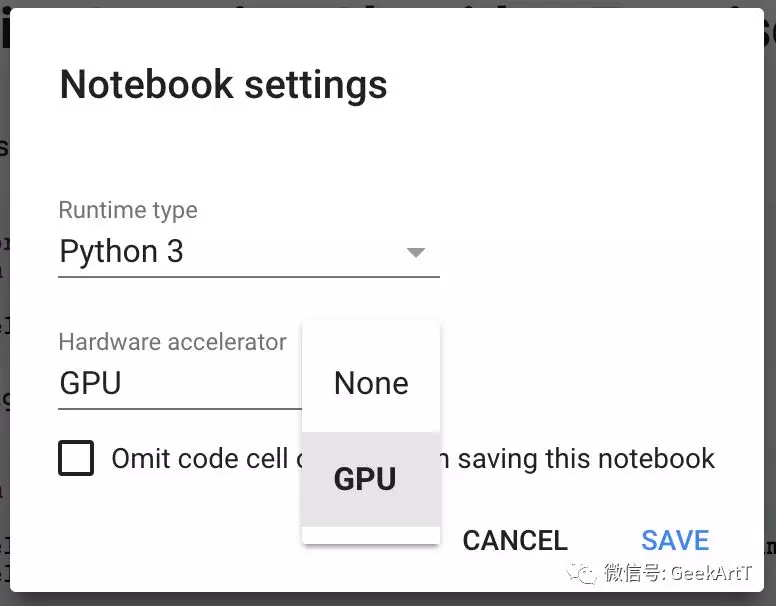
如何设置GPU的运行呢?依次点击Edit > Notebook settings 或者 Runtime > Change runtime type ,选择GPU作为Hardware accelerator。
安装程序库
对想要探索Deep Learning的同学来说,Keras已经成了一个必备的工具框架。这就涉及到安装Keras,只需一行命令:
!pip install -q keras
更一般地,为了import 不在Colab上的库,可以直接使用!pip install 或者!apt-get install 来做安装。例如,安装matplotlib:
!pip install -q matplotlib-venn
或者调整TensorFlow的版本:
# To determine which version you're using:!pip show tensorflow# For the current version:!pip install --upgrade tensorflow# For a specific version:!pip install tensorflow==1.2# For the latest nightly build:!pip install tf-nightly
又或者,查看你的当前路径和当前路径的内容:
# Check your current directory!pwd# Check contents under current directory!ls
可以推断:想在Colab中调用Linux命令,需要在命令最开始添加符号!。
如何连通Colab与Google Drive
虽然Colab的文件是存储在你的Google Drive上,但一个让人懊恼的问题是你在Colab的notebook中使用命令时,其发生作用的文件目录却不在Google Drive上,而是在Google提供的一个虚拟机(VM)中。如果你有其它数据或者文件需要在运行时使用,就没办法了。所以,你需要将运行的VM同你自己的Google Drive连接起来。这就涉及到Mount Google Drive。
这里,我们通过google-drive-ocamlfuse 去Mount自己的Google Drive。
先运行以下命令去安装必要的库,以及做相应的authorization:
!apt-get install -y -qq software-properties-common python-software-properties module-init-tools!add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null!apt-get update -qq 2>&1 > /dev/null!apt-get -y install -qq google-drive-ocamlfuse fusefrom google.colab import authauth.authenticate_user()from oauth2client.client import GoogleCredentialscreds = GoogleCredentials.get_application_default()import getpass!google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret} < /dev/null 2>&1 | grep URLvcode = getpass.getpass()!echo {vcode} | google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret}
在运行过程中,会看到相应的认证框如下图:
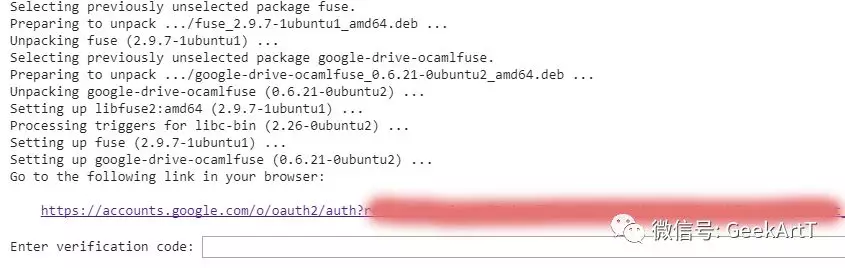
点击超链接,复制超链接关联的Google账号的Auth密钥,粘贴到输入框里面,按回车,即可通过。
下一步,Mount起自己的Google Drive:在VM中新建一个目录,再用命令将它连接到Google Drive的根目录。
!mkdir -p TerenceDrive!google-drive-ocamlfuse TerenceDrive
这里的"TerenceDrive"可修改为你想要的名称。它意味着,这个TerenceDrive 将直接指向你的Google Drive的根目录。
Mount完毕自己的Google Drive后,很多事情就变得极其方便了。
Colab中运行.py文件
先用一段Keras上的代码示例mnist_cnn.py(http://t.cn/REe2bqF)来演示如何直接运行.py文件:
'''This is [mnist_cnn.py]
'''Trains a simple convnet on the MNIST dataset.Gets to 99.25% test accuracy after 12 epochs(there is still a lot of margin for parameter tuning).16 seconds per epoch on a GRID K520 GPU.'''from __future__ import print_functionimport kerasfrom keras.datasets import mnistfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Flattenfrom keras.layers import Conv2D, MaxPooling2Dfrom keras import backend as Kbatch_size = 128num_classes = 10epochs = 12# input image dimensionsimg_rows, img_cols = 28, 28# the data, split between train and test sets(x_train, y_train), (x_test, y_test) = mnist.load_data()if K.image_data_format() == 'channels_first':x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)input_shape = (1, img_rows, img_cols)else:x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)input_shape = (img_rows, img_cols, 1)x_train = x_train.astype('float32')x_test = x_test.astype('float32')x_train /= 255x_test /= 255print('x_train shape:', x_train.shape)print(x_train.shape[0], 'train samples')print(x_test.shape[0], 'test samples')# convert class vectors to binary class matricesy_train = keras.utils.to_categorical(y_train, num_classes)y_test = keras.utils.to_categorical(y_test, num_classes)model = Sequential()model.add(Conv2D(32, kernel_size=(3, 3),activation='relu',input_shape=input_shape))model.add(Conv2D(64, (3, 3), activation='relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.25))model.add(Flatten())model.add(Dense(128, activation='relu'))model.add(Dropout(0.5))model.add(Dense(num_classes, activation='softmax'))model.compile(loss=keras.losses.categorical_crossentropy,optimizer=keras.optimizers.Adadelta(),metrics=['accuracy'])model.fit(x_train, y_train,batch_size=batch_size,epochs=epochs,verbose=1,validation_data=(x_test, y_test))score = model.evaluate(x_test, y_test, verbose=0)print('Test loss:', score[0])print('Test accuracy:', score[1])
假设这个文件mnist_cnn.py 存放在了我们的Google Drive的Colab Notebooks文件夹下,此时,它的路径便是My Drive/Colab Notebooks/mnist_cnn.py 。
知道了TerenceDrive 直接指向Google Drive的根目录,便可以直接运行命令:
!python3 'TerenceDrive/Colab Notebooks/mnist_cnn.py'
Colab中下载数据到Google Drive
例如,直接从URL上下载数据到自己Google Drive的Colab Notebooks文件夹:
!wget https://raw.githubusercontent.com/vincentarelbundock/Rdatasets/master/csv/datasets/Titanic.csv -P 'TerenceDrive/Colab Notebooks'
立马用Pandas读取一个试试:
import pandas as pdtitanic = pd.read_csv('TerenceDrive/Colab Notebooks/Titanic.csv')titanic.head(5)

简直丝滑清爽无比!
Colab中使用GitHub Repo
再来看看经常会用到的git版本控制,特别是如何使用在GitHub上现成的project。直接clone 一个项目到自己的Colab Notebooks文件夹:
!git clone https://github.com/wxs/keras-mnist-tutorial.git 'TerenceDrive/Colab Notebooks/keras-mnist-tutorial'
从Google Drive中打开notebook:
选择以Colaboratory的方式打开:

便可以将这个notebook运行了。
最后提一句,Colab自带的notebook Welcome to Colaboratory! 是一个很好的学习Colab的起点。
Enjoy your Colab journey.
近期回顾
《2018年02月写字总结》
《极端开放的头脑 | 《原则》》
《系统的演化》
如果你喜欢我的文章或分享,请长按下面的二维码关注我的微信公众号,谢谢!

26