Python 使用itchat 获取微信好友信息并解析(性别 区域 头像 签名等)
目录
- Itchat简介
- 1. 登录 获取好友信息
- 2. 好友性别统计
- 3. 好友省份统计
- 4. 好友城市统计
- 5. 好友头像获取
- 6. 好友签名分析
- 总结
Itchat简介
itchat官网:https://itchat.readthedocs.io/zh/latest/
itchat是一个开源的微信个人号接口
使用这个接口可以完成获取微信好友信息,发送信息,接收信息等操作
借此可以开发个人的微信机器人。
(目前发送信息等功能好像已被官方禁止)
现在我们只是用最基本的获取好友信息功能 来得到微信好友信息 并进行初步的分析统计
1. 登录 获取好友信息
首先当然是要安装这个开源包
pip install itchat
只需要一条命令就可以进行微信的扫码登录
import itchat
itchat.auto_login()
扫码后便会提示登陆了网页版微信 (ps: 新的微信账号貌似已经不支持网页版登陆了。。。)
登录之后便可以通过下面这条命令获取最新的好友信息
itchat.get_friends(update=True)
这里的update参数是代表是否重新获取最新信息 如果是False那么就会使用缓存信息
为了清楚地了解其内部数据结构 我们这里会将好友信息保存在本地 (效果同update=False一样)
代码如下:
if os.path.exists('friends.json') is False:
with open("friends.json",'w') as f:
itchat.auto_login()
friends = itchat.get_friends(update=True)
json.dump(friends,f)
print("save friends info.")
else:
with open('friends.json','r') as lf:
friends = json.load(lf)
print('load friends info.')
此时我们将好友信息保存到了friends.json
我们可以查看一下里面的信息存储结构:
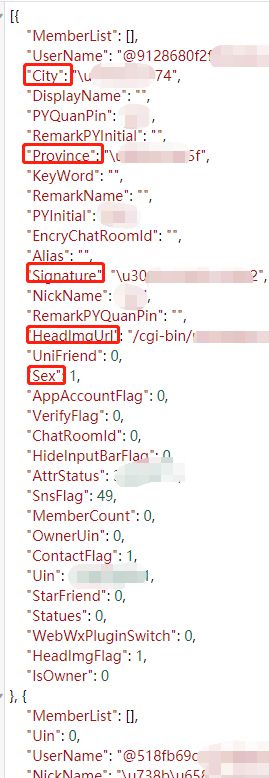
根据上图我们可以对好友的城市、省份、签名、性别、头像等进行统计分析
2. 好友性别统计
sex 代表着好友的性别 1:男 2:女 当然不能排除其它情况。。。0.0
def sex_analysis(friends):
labels = ['男', '女', '其他']
data = [0, 0, 0]
# friends[0] 是自己的信息
for friend in friends[1:]:
sex = friend["Sex"]
if sex == 1:
data[0] += 1
elif sex == 2:
data[1] += 1
else:
data[2] += 1
labels = [labels[i]+':'+str(data[i]) for i in range(len(labels))]
plt.title("微信好友性别比例")
plt.pie(data, labels=labels,autopct="%.2f%%")
plt.savefig("sex.jpg")
plt.show()
我们可以使用matplotlib根据这个统计结果生成一个饼状图

3. 好友省份统计
我们将各省拥有的好友个数进行统计 并排序 取top10
这里会有特殊的空(’’)省份需要去除
def prov_analysis(friends):
prov_dict = defaultdict(int)
for friend in friends[1:]:
prov = friend['Province']
prov_dict[prov] +=1
prov_dict.pop('')
prov_top10 = sorted(prov_dict.items(),key=lambda x:x[1],reverse=True)[:10]
prov_name = [x[0] for x in prov_top10]
prov_num = [x[1] for x in prov_top10]
plt.bar(prov_name,prov_num,width=0.5,align='center',color='#87CEFA')
for i in range(len(prov_num)):
x = prov_name[i]
y = prov_num[i]
plt.text(x,y+1,'%s'%y,fontsize=10,ha='center')
plt.ylabel("好友数量")
plt.xlabel("省")
plt.title("各省好友分布 TOP10")
plt.savefig("province.jpg")
plt.show()
同样将结果使用plt呈现
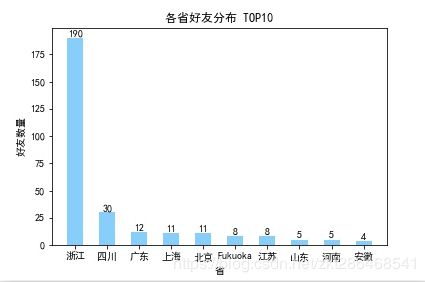
根据这个明显的省份分布 几乎可以断定。。该微信号是个浙江人
4. 好友城市统计
这个和省份统计基本一致
def city_analysis(friends):
city_dict = defaultdict(int)
for friend in friends[1:]:
city = friend['City']
city_dict[city] +=1
city_dict.pop('')
city_top10 = sorted(city_dict.items(),key=lambda x:x[1],reverse=True)[:10]
city_name = [x[0] for x in city_top10]
city_num = [x[1] for x in city_top10]
plt.bar(city_name,city_num,width=0.5,align='center',color='#87CEFA')
for i in range(len(city_num)):
x = city_name[i]
y = city_num[i]
plt.text(x,y+1,'%s'%y,fontsize=10,ha='center')
plt.ylabel("好友数量")
plt.xlabel("城市")
plt.title("各城市好友分布 TOP10")
plt.savefig("city.jpg")
plt.show()

分析上图:
该微信号在杭绍两城市 出生/工作
并在成都生活过一段时间
5. 好友头像获取
这个功能好像没什么能分析的。。。看看好友的头像是否非主流。。
这里需要注意
从缓存的friends.json好友信息中可以获取头像地址
但是下载头像是需要重新登陆的
我们在这里继续进行缓存 将头像保存在 photos/文件夹内
get_photo:下载好友头像图片
photo_merge: 拼接好友头像 生成一张大图
def get_photo(path):
itchat.auto_login()
friends = itchat.get_friends(update=True)[0:]
num=0
for i in friends:
img = itchat.get_head_img(userName=i["UserName"])
imgpath = path+str(num)+'.jpg'
try:
with open(imgpath,'wb') as imgf:
imgf.write(img)
except Exception as e:
print("get err:",e)
num+=1
def photo_merge(friends):
path='photos/'
if os.path.exists(path) is False:
os.mkdir(path)
flist = os.listdir(path)
if len(flist)==0:
get_photo(path)
flist = os.listdir(path)
line = int(math.sqrt(len(flist)))
each_size = int(640/line)
image= Image.new('RGB',(line*each_size,int(len(flist)/line)*each_size))
x,y=0,0
poslist = list(range(len(flist)))
random.shuffle(poslist)
for i in flist:
try:
pos = poslist.pop()
img = Image.open(path+str(pos)+'.jpg')
except IOError as e:
pass
else:
img = img.resize((each_size,each_size),Image.ANTIALIAS)
image.paste(img,(x*each_size,y*each_size))
x+=1
if x==line:
x=0
y+=1
image.save("frinds_photo.jpg")
img = plt.imread("frinds_photo.jpg")
plt.imshow(img)
plt.axis('off')
plt.show()
注意: 为了让拼接的图片没有黑边 更加的好看
我们在拼接图片时会舍弃掉一些图片
假设我们有num张照片 sqrt(num) 取整 = n
我们会拼接n x n 大小的图片 整张图片大小为640x640 可以自由设定
每位好友的头像大小(640/n x 640/n)
结果如下图:
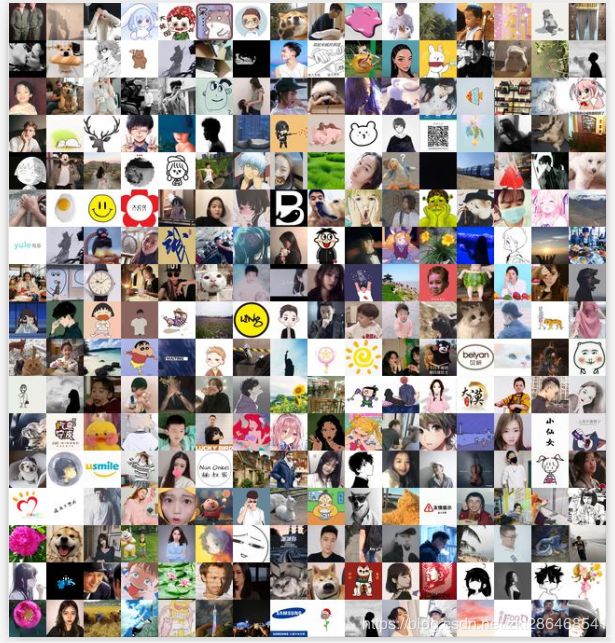
看上去挺壮观。。。。
6. 好友签名分析
这里我们会用到中文分词工具 jieba:https://github.com/fxsjy/jieba
我们将每一个好友签名 去除停用词 (这里只是初步手动去除 不全面)
拼接后 使用结巴进行分词
统计分词后词组的出现频率
使用词云(wordcloud)https://github.com/amueller/word_cloud 将这些词组展现出来
频率越高 词越大
def sig_analysis(friends):
text = ''
rule = re.compile("1fd+w*|[<>/=]")
for fri in friends:
sig = fri['Signature'].strip()
if len(sig)>0 and not sig.startswith('):
sig = sig.replace("span",'').replace("class",'').replace("emoji","").replace("\n","").replace("00","")
sig = rule.sub("",sig)
text += sig + ' '
jiebatext = list(jieba.cut(text,cut_all=True))
jiebatext = [x for x in jiebatext if len(x)>1]
wordDic = dict(Counter(jiebatext))
bgimg = plt.imread('bk.jpg')
mywordcloud = wordcloud.WordCloud(
font_path='jdxs.TTF',
background_color="white",
mask=bgimg,
width=1200,
height=1200)
mywordcloud.generate_from_frequencies(wordDic)
plt.imshow(mywordcloud)
plt.axis("off")
plt.show()
mywordcloud.to_file("sigimg.png")
结果如下图

总结
虽然只是获取了最基础的微信好友信息
但我们已经能够从这些不起眼的数据中获取到一些有用的信息
好友数量 好友性别比例 用户生活城市等等
细思极恐0.0
那些并未开放 获取不到的信息里 是否已经将我们展示地一览无余