Spring Boot Redis 入门
本文,我们基于 Spring Boot 2.X 版本。
1. 概述
在快速入门 Spring Boot 整合 Redis 之前,我们先来做个简单的了解。在 Spring 的生态中,我们使用 Spring Data Redis 来实现对 Redis 的数据访问。
可能这个时候,会有胖友会有疑惑,市面上已经有 Jedis、Redisson、Lettuce 等优秀的 Java Redis 工具库,为什么还要有 Spring Data Redis 呢?学不动了,头都要秃了!不要慌,我们先来看一张图: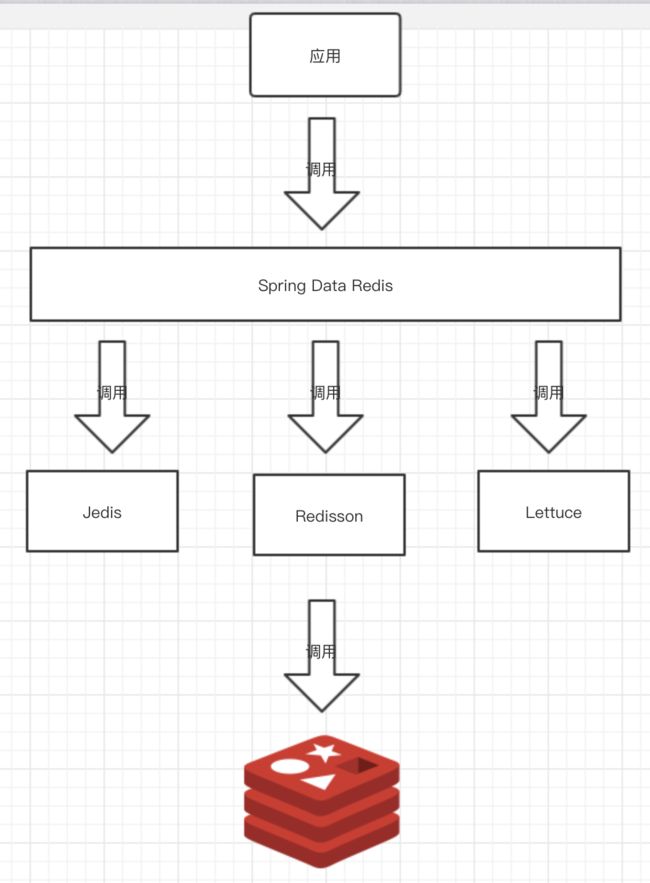
- 对于下层,Spring Data Redis 提供了统一的操作模板(后文中,我们会看到是 RedisTemplate 类),封装了 Jedis、Lettuce 的 API 操作,访问 Redis 数据。所以,实际上,Spring Data Redis 内置真正访问的实际是 Jedis、Lettuce 等 API 操作。
- 对于上层,开发者学习如何使用 Spring Data Redis 即可,而无需关心 Jedis、Lettuce 的 API 操作。甚至,未来如果我们想将 Redis 访问从 Jedis 迁移成 Lettuce 来,无需做任何的变动。? 相信很多胖友,在选择 Java Redis 工具库,也是有过烦恼的。
- 目前,Spring Data Redis 暂时只支持 Jedis、Lettuce 的内部封装,而 Redisson 是由 redisson-spring-data 来提供。
OK ,哔哔结束,我们先来快速上手下 Spring Data Redis 的使用。
2. 快速入门
示例代码对应仓库:spring-data-redis-with-jedis 。
感兴趣的胖友可以看看 https://mvnrepository.com/artifact/redis.clients/jedis 地址,会发现 2016 年到 2018 年的 Jedis 更新频率。所幸,2018 年底又突然复活了。
同时,艿艿目前使用的 SkyWalking 中间件,暂时只支持 Jedis 的自动化的追踪,那么更加考虑使用 Jedis 啦。
这里在分享一个 Jedis 和 Lettuce 的对比讨论。
2.1 引入依赖
在 pom.xml 文件中,引入相关依赖。
org.springframework.boot
spring-boot-starter-parent
2.1.3.RELEASE
org.springframework.boot
spring-boot-starter-data-redis
io.lettuce
lettuce-core
redis.clients
jedis
org.springframework.boot
spring-boot-starter-test
test
com.alibaba
fastjson
1.2.61
com.fasterxml.jackson.core
jackson-databind
具体每个依赖的作用,胖友自己认真看下艿艿添加的所有注释噢。
2.2 配置文件
在 application.yml 中,添加 Redis 配置,如下:
spring:
# 对应 RedisProperties 类
redis:
host: 127.0.0.1
port: 6379
password: # Redis 服务器密码,默认为空。生产中,一定要设置 Redis 密码!
database: 0 # Redis 数据库号,默认为 0 。
timeout: 0 # Redis 连接超时时间,单位:毫秒。
# 对应 RedisProperties.Jedis 内部类
jedis:
pool:
max-active: 8 # 连接池最大连接数,默认为 8 。使用负数表示没有限制。
max-idle: 8 # 默认连接数最小空闲的连接数,默认为 8 。使用负数表示没有限制。
min-idle: 0 # 默认连接池最小空闲的连接数,默认为 0 。允许设置 0 和 正数。
max-wait: -1 # 连接池最大阻塞等待时间,单位:毫秒。默认为 -1 ,表示不限制。具体每个参数的作用,胖友自己认真看下艿艿添加的所有注释噢。
2.3 简单测试
创建 Test01 测试类,我们来测试一下简单的 SET 指令。代码如下:
@RunWith(SpringRunner.class)
@SpringBootTest
public class Test01 {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
public void testStringSetKey() {
stringRedisTemplate.opsForValue().set("yunai", "shuai");
}
}通过 StringRedisTemplate 类,我们进行了一次 Redis SET 指令的执行。关于 StringRedisTemplate 是什么,我们先卖个关子,在 「2.4 RedisTemplate」 中来介绍。
我们先来执行下 #testStringSetKey() 方法这个测试方法。执行完成后,我们在控制台查询,看看是否真的执行成功了。
$ redis-cli get yunai
"shuai"- 请大声的告诉我,Redis 是怎么夸奖
"yunai"的,哈哈哈哈。
2.4 RedisTemplate
org.springframework.data.redis.core.RedisTemplate 类,从类名上,我们就明明白白知道,提供 Redis 操作模板 API 。核心属性如下:
// RedisTemplate.java
// 艿艿省略了一些不重要的属性。
// <1> 序列化相关属性
@SuppressWarnings("rawtypes") private @Nullable RedisSerializer keySerializer = null;
@SuppressWarnings("rawtypes") private @Nullable RedisSerializer valueSerializer = null;
@SuppressWarnings("rawtypes") private @Nullable RedisSerializer hashKeySerializer = null;
@SuppressWarnings("rawtypes") private @Nullable RedisSerializer hashValueSerializer = null;
private RedisSerializer stringSerializer = RedisSerializer.string();
// <2> Lua 脚本执行器
private @Nullable ScriptExecutor scriptExecutor;
// <3> 常见数据结构操作类
// cache singleton objects (where possible)
private @Nullable ValueOperations valueOps;
private @Nullable ListOperations listOps;
private @Nullable SetOperations setOps;
private @Nullable ZSetOperations zSetOps;
private @Nullable GeoOperations geoOps;
private @Nullable HyperLogLogOperations hllOps; <1>处,看到了四个序列化相关的属性,用于 KEY 和 VALUE 的序列化。- 例如说,我们在使用 POJO 对象存储到 Redis 中,一般情况下,会使用 JSON 方式序列化成字符串,存储到 Redis 中。详细的,我们在 「3. 序列化」 小节中来说明。
- 在上文中,我们看到了
org.springframework.data.redis.core.StringRedisTemplate类,它继承 RedisTemplate 类,使用org.springframework.data.redis.serializer.StringRedisSerializer字符串序列化方式。直接点开 StringRedisSerializer 源码,看下它的构造方法,瞬间明明白白。
<2>处,Lua 脚本执行器,提供 Redis scripting API 操作。<3>处,Redis 常见数据结构操作类。- ValueOperations 类,提供 Redis String API 操作。
- ListOperations 类,提供 Redis List API 操作。
- SetOperations 类,提供 Redis Set API 操作。
- ZSetOperations 类,提供 Redis ZSet(Sorted Set) API 操作。
- GeoOperations 类,提供 Redis Geo API 操作。
- HyperLogLogOperations 类,提供 Redis HyperLogLog API 操作。
那么 Pub/Sub、Transaction、Pipeline、Keys、Cluster、Connection 等相关的 API 操作呢?它在 RedisTemplate 自身提供,因为它们不属于具体每一种数据结构,所以没有封装在对应的 Operations 类中。哈哈哈,胖友打开 RedisTemplate 类,去瞅瞅,妥妥的明白。
3. 序列化
艿艿:为了尽量把序列化说的清楚一些,所以本小节内容会略长。
因为有些地方,直接撸源码,比吓哔哔一段话更易懂,所以会有一些源码,保持淡定。
3.1 RedisSerializer
org.springframework.data.redis.serializer.RedisSerializer 接口,Redis 序列化接口,用于 Redis KEY 和 VALUE 的序列化。简化代码如下:
// RedisSerializer.java
public interface RedisSerializer {
@Nullable
byte[] serialize(@Nullable T t) throws SerializationException;
@Nullable
T deserialize(@Nullable byte[] bytes) throws SerializationException;
} - 定义了对象
- 啊,可能有胖友会有疑惑了:我们在
redis-cli终端,看到的不都是字符串么,怎么这里是序列化成二进制数组呢?实际上,Redis Client 传递给 Redis Server 是传递的 KEY 和 VALUE 都是二进制值数组。好奇的胖友,可以打开 JedisConnection#sendCommand(final Command cmd, final byte[]... args)方法,传入的参数就是二进制数组,而cmd命令也会被序列化成二进制数组。
RedisSerializer 的实现类,如下图: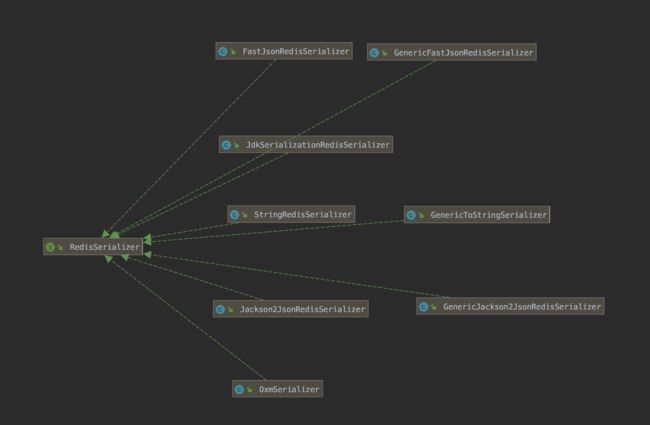
主要分成四类:
- JDK 序列化方式
- String 序列化方式
- JSON 序列化方式
- XML 序列化方式
3.1.1 JDK 序列化方式
org.springframework.data.redis.serializer.JdkSerializationRedisSerializer ,默认情况下,RedisTemplate 使用该数据列化方式。具体的,可以看看 RedisTemplate#afterPropertiesSet() 方法,在 RedisTemplate 未设置序列化的情况下,使用 JdkSerializationRedisSerializer 作为序列化实现。在 Spring Boot 自动化配置 RedisTemplate Bean 对象时,就未设置。
绝大多数情况下,可能 99.9999% ,我们不会使用 JdkSerializationRedisSerializer 进行序列化。为什么呢?我们来看一个示例,代码如下:
// Test01.java
@RunWith(SpringRunner.class)
@SpringBootTest
public class Test01 {
@Autowired
private RedisTemplate redisTemplate;
@Test
public void testStringSetKey02() {
redisTemplate.opsForValue().set("yunai", "shuai");
}
}我们先来执行下 #testStringSetKey02() 方法这个测试方法。注意,此处我们使用的是 RedisTemplate 而不是 StringRedisTemplate 。执行完成后,我们在控制台查询,看看是否真的执行成功了。
# 在 `redis-cli` 终端中
127.0.0.1:6379> scan 0
1) "0"
2) 1) "\xac\xed\x00\x05t\x00\x05yunai"
127.0.0.1:6379> get "\xac\xed\x00\x05t\x00\x05yunai"
"\xac\xed\x00\x05t\x00\x05shuai"-
具体为什么是这样一串奇怪的 16 进制,胖友可以看看
ObjectOutputStream#writeString(String str, boolean unshared)的代码,实际就是标志位 + 字符串长度 + 字符串内容。
对于 KEY 被序列化成这样,我们线上通过 KEY 去查询对应的 VALUE 势必会非常不方便,所以 KEY 肯定是不能被这样序列化的。
对于 VALUE 被序列化成这样,除了阅读可能困难一点,不支持跨语言外,实际上也没啥问题。不过,实际线上场景,还是使用 JSON 序列化居多。
3.1.2 String 序列化方式
① org.springframework.data.redis.serializer.StringRedisSerializer ,字符串和二进制数组的直接转换。代码如下:
// StringRedisSerializer.java
private final Charset charset;
@Override
public String deserialize(@Nullable byte[] bytes) {
return (bytes == null ? null : new String(bytes, charset));
}
@Override
public byte[] serialize(@Nullable String string) {
return (string == null ? null : string.getBytes(charset));
}- 是不是很直接简单。
绝大多数情况下,我们 KEY 和 VALUE 都会使用这种序列化方案。而 VALUE 的序列化和反序列化,自己在逻辑调用 JSON 方法去序列化。为什么呢?继续往下看。
② org.springframework.data.redis.serializer.GenericToStringSerializer ,使用 Spring ConversionService 实现
例如说,序列化的过程,首先
当然,GenericToStringSerializer 貌似基本不会去使用,所以不用去了解也问题不大,哈哈哈。
3.1.3 JSON 序列化方式
① org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer ,使用 Jackson 实现 JSON 的序列化方式,并且从 Generic 单词可以看出,是支持所有类。怎么体现呢?参见构造方法的代码:
// GenericJackson2JsonRedisSerializer.java
public GenericJackson2JsonRedisSerializer(@Nullable String classPropertyTypeName) {
this(new ObjectMapper());
// simply setting {@code mapper.disable(SerializationFeature.FAIL_ON_EMPTY_BEANS)} does not help here since we need
// the type hint embedded for deserialization using the default typing feature.
mapper.registerModule(new SimpleModule().addSerializer(new NullValueSerializer(classPropertyTypeName)));
// <1>
if (StringUtils.hasText(classPropertyTypeName)) {
mapper.enableDefaultTypingAsProperty(DefaultTyping.NON_FINAL, classPropertyTypeName);
// <2>
} else {
mapper.enableDefaultTyping(DefaultTyping.NON_FINAL, As.PROPERTY);
}
}<1>处,如果传入了classPropertyTypeName属性,就是使用使用传入对象的classPropertyTypeName属性对应的值,作为默认类型(Default Typing)。<2>处,如果未传入classPropertyTypeName属性,则使用传入对象的类全名,作为默认类型(Default Typing)。
那么,胖友可能会问题,什么是**默认类型(Default Typing)**呢?我们来思考下,在将一个对象序列化成一个字符串,怎么保证字符串反序列化成对象的类型呢?Jackson 通过 Default Typing ,会在字符串多冗余一个类型,这样反序列化就知道具体的类型了。来举个例子,使用我们等会示例会用到的 UserCacheObject 类。
-
标准序列化的结果,如下:
{ "id": 1, "name": "芋道源码", "gender": 1 } -
使用 Jackson Default Typing 机制序列化的结果,如下:
{ "@class": "cn.iocoder.springboot.labs.lab10.springdatarediswithjedis.cacheobject.UserCacheObject", "id": 1, "name": "芋道源码", "gender": 1 }- 看
@class属性,反序列化的对象的类型不就有了么?
- 看
下面我们来看一个 GenericJackson2JsonRedisSerializer 的示例。在看之前,胖友先跳到 「3.2 配置序列化方式」 小节,来看看如何配置 GenericJackson2JsonRedisSerializer 作为 VALUE 的序列化方式。然后,马上调回到此处。
示例代码如下:
// Test01.java
@Autowired
private RedisTemplate redisTemplate;
@Test
public void testStringSetKeyUserCache() {
UserCacheObject object = new UserCacheObject()
.setId(1)
.setName("芋道源码")
.setGender(1); // 男
String key = String.format("user:%d", object.getId());
redisTemplate.opsForValue().set(key, object);
}
@Test
public void testStringGetKeyUserCache() {
String key = String.format("user:%d", 1);
Object value = redisTemplate.opsForValue().get(key);
System.out.println(value);
}胖友分别执行 #testStringSetKeyUserCache() 和 #testStringGetKeyUserCache() 方法,然后对着 Redis 的结果看看,比较简单,就不多哔哔了。
我们在回过头来看看 @class 属性,它看似完美解决了反序列化后的对象类型,但是带来 JSON 字符串占用变大,所以实际项目中,我们也并不会采用 Jackson2JsonRedisSerializer 类。
② org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer ,使用 Jackson 实现 JSON 的序列化方式,并且显示指定
// Jackson2JsonRedisSerializer.java
public class Jackson2JsonRedisSerializer implements RedisSerializer {
// ... 省略不重要的代码
public static final Charset DEFAULT_CHARSET = StandardCharsets.UTF_8;
/**
* 指定类型,和 要一致。
*/
private final JavaType javaType;
private ObjectMapper objectMapper = new ObjectMapper();
} 因为 Jackson2JsonRedisSerializer 序列化类里已经声明了类型,所以序列化的 JSON 字符串,无需在存储一个 @class 属性,用于存储类型。
但是,我们抠脚一想,如果使用 Jackson2JsonRedisSerializer 作为序列化实现类,那么如果我们类型比较多,岂不是每个类型都要定义一个 RedisTemplate Bean 了?!所以实际场景下,我们也并不会使用 Jackson2JsonRedisSerializer 类。?
注意,GenericFastJsonRedisSerializer 不是 Spring Data Redis 内置实现,而是由 FastJSON 自己实现。
3.1.4 XML 序列化方式
org.springframework.data.redis.serializer.OxmSerializer ,使用 Spring OXM 实现将对象和 String 的转换,从而 String 和二进制数组的转换。
因为 XML 序列化方式,暂时没有这么干过,我自己也没有,所以就直接忽略它吧。?
3.2 配置序列化方式
创建 RedisConfiguration 配置类,代码如下:
@Configuration
public class RedisConfiguration {
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory factory) {
// 创建 RedisTemplate 对象
RedisTemplate template = new RedisTemplate<>();
// 设置 RedisConnection 工厂。? 它就是实现多种 Java Redis 客户端接入的秘密工厂。感兴趣的胖友,可以自己去撸下。
template.setConnectionFactory(factory);
// 使用 String 序列化方式,序列化 KEY 。
template.setKeySerializer(RedisSerializer.string());
// 使用 JSON 序列化方式(库是 Jackson ),序列化 VALUE 。
template.setValueSerializer(RedisSerializer.json());
return template;
}
} -
RedisSerializer#string()静态方法,返回的就是使用 UTF-8 编码的 StringRedisSerializer 对象。代码如下:// RedisSerializer.java static RedisSerializerstring() { return StringRedisSerializer.UTF_8; } // StringRedisSerializer.java public static final StringRedisSerializer ISO_8859_1 = new StringRedisSerializer(StandardCharsets.ISO_8859_1); -
RedisSerializer#json()静态方法,返回 GenericJackson2JsonRedisSerializer 对象。代码如下:// RedisSerializer.java static RedisSerializer
3.3 自定义 RedisSerializer 实现类
我们直接以 GenericFastJsonRedisSerializer 举例子,直接莽源码。代码如下:
// GenericFastJsonRedisSerializer.java
public class GenericFastJsonRedisSerializer implements RedisSerializer完成自定义 RedisSerializer 配置类后,我们就可以参照 「3.2 配置序列化方式」 小节,将 VALUE 序列化的修改成我们的,哈哈哈。
4. 项目实践
本小节,我们来分享我们在生产中的一些实践。关于这块,希望大家可以一起讨论,能够让我们的代码更加优雅干净。
4.1 Cache Object
在我们使用数据库时,我们会创建 dataobject 包,存放 DO(Data Object)数据库实体对象。
那么同理,我们缓存对象,怎么进行对应呢?对于复杂的缓存对象,我们创建了 cacheobject 包,和 dataobject 包同层。如:
service # 业务逻辑层
dao # 数据库访问层
dataobject # DO
cacheobject # 缓存对象并且所有的 Cache Object 对象使用 CacheObject 结尾,例如说 UserCacheObject、ProductCacheObject 。
4.2 数据访问层
在我们访问数据库时,我们会创建 dao 包,存放每个 DO 对应的 Dao 类。那么对于每一个 CacheObject 类,我们也会创建一个其对应的 Dao 类。例如说,UserCacheObject 对应 UserCacheObjectDao 类。示例代码如下:
@Repository
public class UserCacheDao {
private static final String KEY_PATTERN = "user:%d"; // user:用户编号 <1>
@Resource(name = "redisTemplate")
@SuppressWarnings("SpringJavaInjectionPointsAutowiringInspection")
private ValueOperations operations; // <2>
private static String buildKey(Integer id) { // <3>
return String.format(KEY_PATTERN, id);
}
public UserCacheObject get(Integer id) {
String key = buildKey(id);
String value = operations.get(key);
return JSONUtil.parseObject(value, UserCacheObject.class);
}
public void set(Integer id, UserCacheObject object) {
String key = buildKey(id);
String value = JSONUtil.toJSONString(object);
operations.set(key, value);
}
} <1>处,通过静态变量,声明 KEY 的前缀,并且使用冒号作为间隔<3>处,声明KEY_PATTERN对应的 KEY 拼接方法,避免散落在每个方法中。<2>处,通过@Resource注入指定名字的 RedisTemplate 对应的 Operations 对象,这样明确每个 KEY 的类型。- 剩余的,就是每个方法封装对应的操作。
可能会有胖友问,为什么不支持将 RedisTemplate 直接在 Service 业务层调用呢?如果这样,我们业务代码里,就容易混杂着很多 Redis 访问代码的细节,导致很脏乱。我们试着把 RedisTemplate 想象成 Spring JDBCTemplate ,我们一定会声明对应的 Dao 类,访问数据库。所以,同理咯。
那么还有一个问题,UserCacheDao 放在哪个包下?目前的想法是,将 dao 包下拆成 mysql、redis 包。这样,MySQL 相关的 Dao 放在 mysql 包下,Redis 相关的 Dao 放在 redis 。
4.3 序列化
在 「3. 序列化」 小节中,我们仔细翻看了每个序列化方式,暂时没有一个能够完美的契合我们的需求,所以我们直接使用最简单的 StringRedisSerializer 作为序列化实现类。而真正的序列化,我们在各个 Dao 类里,自己手动来调用。
例如说,在 UserCacheDao 示例中,已经看到了这么做了。这里还有一个细化点,虽然我们是自己手动序列化,可以自己简单封装一个 JSONUtil 类,未来如果我们想换 JSON 库,就比较方便了。其实,这个和 Spring Data Redis 所做的封装是一个思路。
5. 示例补充
像 String、List、Set、ZSet、Geo、HyperLogLog 等等数据结构的操作,胖友自己去用用对应的 Operations 操作类的 API 方法,就非常容易懂了,我们更多的,补充 Pipeline、Transaction、Pub/Sub、Script 等等功能的示例。
5.1 Pipeline
如果胖友没有了解过 Redis 的 Pipeline 机制,可以看看 《Redis 文档 —— Pipeline》 文章,批量操作,提升性能必备神器。
在 RedisTemplate 类中,提供了 2 组四个方法,用于执行 Redis Pipeline 操作。代码如下:
// <1> 基于 Session 执行 Pipeline
@Override
public List- 两组方法的差异,在于是否是 Session 中执行。那么 Session 是什么呢?卖个关子,在 「5.3 Session」 中来详细解析。本小节,我们只讲 Pipeline + RedisCallback 的组合的方法。
- 每组方法里,差别在于是否传入 RedisSerializer 参数。如果不传,则使用 RedisTemplate 自己的序列化相关的属性。
5.1.1 源码解读
在看具体的 #executePipelined(RedisCallback action, ...) 方法的示例之前,我们先来看一波源码,这样我们才能更好的理解具体的使用方法。代码如下:
// RedisTemplate.java
@Override
public List<1>处,调用#execute(RedisCallback方法,执行 Redis 方法。注意,此处传入的action) action参数,不是我们传入的 RedisCallback 参数。我们的会在该action中被执行。<2>处,调用RedisConnection#openPipeline()方法,自动打开 Pipeline 模式。这样,我们就不需要手动去打开了。<3>处,调用我们传入的实现的RedisCallback#doInRedis(RedisConnection connection)方法,执行在 Pipeline 中,想要执行的 Redis 操作。<4>处,不要返回结果。因为 RedisCallback 是统一定义的接口,所以可以返回一个结果。但是在 Pipeline 中,未提交执行时,显然是没有结果,返回也没有意思。简单来说,就是我们在实现RedisCallback#doInRedis(RedisConnection connection)方法时,返回null即可。<5>处,调用RedisConnection#closePipeline()方法,自动提交 Pipeline 执行,并返回执行结果。<6>处,反序列化结果,并返回 Pipeline 结果。
至此,Spring Data Redis 对 Pipeline 的封装,我们已经做了一个简单的了解,实际就是经典的“模板方法”设计模式化的应用。下面,在让我们来看看 org.springframework.data.redis.core.RedisCallback 接口,Redis 回调接口。代码如下:
// RedisCallback.java
public interface RedisCallback {
/**
* Gets called by {@link RedisTemplate} with an active Redis connection. Does not need to care about activating or
* closing the connection or handling exceptions.
*
* @param connection active Redis connection
* @return a result object or {@code null} if none
* @throws DataAccessException
*/
@Nullable
T doInRedis(RedisConnection connection) throws DataAccessException;
} -
虽然接口名是以 Callback 结尾,但是通过
#doInRedis(RedisConnection connection)方法可以很容易知道,实际可以理解是 Redis Action ,想要执行的 Redis 操作。 -
有一点要注意,传入的
connection参数是 RedisConnection 对象,它提供的'low level'更底层的 Redis API 操作。例如说:// RedisStringCommands.java // RedisConnection 实现 RedisStringCommands 接口 byte[] get(byte[] key); Boolean set(byte[] key, byte[] value);- 传入和返回的是二进制数组,实际就是 RedisTemplate 已经序列化的入参和会被反序列化的出参。
5.1.2 具体示例
示例代码对应测试类:PipelineTest 。
创建 PipelineTest 单元测试类,编写代码如下:
// PipelineTest.java
@RunWith(SpringRunner.class)
@SpringBootTest
public class PipelineTest {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
public void test01() {
List执行 #test01() 方法,结果如下:
[true, true, true, shuai, shuai, shuai]- 因为我们使用 StringRedisTemplate 自己的序列化相关属性,所以 Redis GET 命令返回的二进制,被反序列化成了字符串。
5.2 Transaction
基情提示:实际项目实战中,Redis Transaction 事务基本不用,至少问了一些胖友,包括自己,都没有再用。所以呢,本小节可以选择性看看。或者,就不看,哈哈哈哈。
在看 Redis Transaction 事务之前,我们先回想下 Spring 是如何管理数据库 Transaction 的。在应用程序中处理一个请求时,如果我们的方法开启Trasaction 功能,Spring 会把数据库的 Connection 连接和当前线程进行绑定,从而实现 Connection 打开一个 Transaction 后,所有当前线程的数据库操作都在该 Connection 上执行,达到所有操作在这个 Transaction 中,最终提交或回滚。
在 Spring Data Redis 中,实现 Redis Transaction 也是这个思路。通过 SessionCallback 操作 Redis 时,会从当前线程获得 Redis Connection ,如果获取不到,则会去“创建”一个 Redis Connection 并绑定到当前线程中。这样,我们在该 Redis Connection 开启 Redis Transaction 后,在该线程的所有操作,都可以在这个 Transaction 中,最后交由 Spring 事务管理器统一提供或回滚 Transaction 。
如果想要使用 Redis Transaction 功能,需要创建 RedisTemplate Bean 时,设置其 enableTransactionSupport 属性为 true ,默认为 false 不开启。示例如下:
@Configuration
public class RedisConfiguration {
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory factory) {
// 创建 RedisTemplate 对象
RedisTemplate template = new RedisTemplate<>();
// 【重要】设置开启事务支持
template.setEnableTransactionSupport(true);
// 设置 RedisConnection 工厂。? 它就是实现多种 Java Redis 客户端接入的秘密工厂。感兴趣的胖友,可以自己去撸下。
template.setConnectionFactory(factory);
// 使用 String 序列化方式,序列化 KEY 。
template.setKeySerializer(RedisSerializer.string());
// 使用 JSON 序列化方式(库是 Jackson ),序列化 VALUE 。
template.setValueSerializer(RedisSerializer.json());
return template;
}
} 5.2.1 源码解析
概念和原理层面的东西,一旦复杂,就会特别抽象,那么还是老规矩,让我们一起撸下源码,让原理具象化。很多时候,这就是为什么我们要去撸源码的意义。
我们先来看看,配置下 enableTransactionSupport 属性,Redis 在执行命令,是如何获得 Connection 连接的。代码如下:
// RedisTemplate.java
public T execute(RedisCallback action, boolean exposeConnection, boolean pipeline) {
Assert.isTrue(initialized, "template not initialized; call afterPropertiesSet() before using it");
Assert.notNull(action, "Callback object must not be null");
RedisConnectionFactory factory = getRequiredConnectionFactory();
RedisConnection conn = null;
try {
// <1.1>
if (enableTransactionSupport) {
// only bind resources in case of potential transaction synchronization
conn = RedisConnectionUtils.bindConnection(factory, enableTransactionSupport);
} else {
// <1.2>
conn = RedisConnectionUtils.getConnection(factory);
}
// ... 省略中间,执行 Redis 命令的代码。
} finally {
// <2>
RedisConnectionUtils.releaseConnection(conn, factory);
}
} - 考虑到尽量让内容简单一些,我们不会对每一行代码做特别的深究,主要是保证胖友对 Spring Data Redis 对 Transaction 的封装,有个总体了解。
<1.2>处,当我们未开启enableTransactionSupport事务时,调用RedisConnectionUtils#getConnection(factory)方法,获得 Redis Connection 。如果获取不到,则进行创建。<1.1>处,当我们有开启enableTransactionSupport事务时,调用RedisConnectionUtils#bindConnection(RedisConnectionFactory factory, boolean enableTranactionSupport)方法,在RedisConnectionUtils#getConnection(factory)的基础上,如果是创建的 Redis Connection ,会绑定到当前线程中。因为 Transaction 是需要在 Connection 打开,然后后续的 Redis 的操作,都需要在其上。并且,还有一个非常重要的操作,打开 Redis Transaction ,会在该方法中,通过调用RedisConnectionUtils#potentiallyRegisterTransactionSynchronisation(RedisConnectionHolder connHolder, final RedisConnectionFactory factory)。<2>处,调用RedisConnectionUtils#releaseConnection(RedisConnection conn, RedisConnectionFactory factory)方法,释放 Redis Connection 。当然,这是有一个前提,整个 Transaction 已经完成。如果未完成,实际 Redis Connection 不会释放。
那么,此时会有胖友有疑问,Redis Transaction 的提交和回滚在哪呢?答案在 RedisConnectionUtils 的内部类 RedisTransactionSynchronizer 中。代码如下:
// RedisConnectionUtils.java
private static class RedisTransactionSynchronizer extends TransactionSynchronizationAdapter {
private final RedisConnectionHolder connHolder;
private final RedisConnection connection;
private final RedisConnectionFactory factory;
@Override
public void afterCompletion(int status) {
try {
switch (status) {
// 提交
case TransactionSynchronization.STATUS_COMMITTED:
connection.exec();
break;
// 回滚
case TransactionSynchronization.STATUS_ROLLED_BACK:
case TransactionSynchronization.STATUS_UNKNOWN:
default:
connection.discard();
}
} finally {
connHolder.setTransactionSyncronisationActive(false);
connection.close();
TransactionSynchronizationManager.unbindResource(factory);
}
}
}- 根据事务结果的状态,进行 Redis Transaction 提交或回滚。? 如果想进一步的深入,胖友就需要去了解 Spring Transaction 的源码。
5.2.2 具体示例
示例代码对应测试类:TransactionTest 。
创建 TransactionTest 单元测试类,编写代码如下:
// TransactionTest.java
@RunWith(SpringRunner.class)
@SpringBootTest
public class TransactionTest {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
// @Transactional
public void test01() {
// 这里是偷懒,没在 RedisConfiguration 配置类中,设置 stringRedisTemplate 开启事务。
stringRedisTemplate.setEnableTransactionSupport(true);
// 执行想要的操作
stringRedisTemplate.opsForValue().set("yunai:1", "shuai");
stringRedisTemplate.opsForValue().set("yudaoyuanma:1", "dai");
}
}目前这仅仅是一个示例。因为 Redis Transaction 实际创建事务的前提,是当前已经存在 Spring Transaction 。具体可以看看传送门处的判断的代码。? 略感神奇,不晓得为什么是这样的设定。
5.2.3 补充资料
如果觉得还是无法理解的胖友,可以在看看如下几篇文章:
- 《Spring Data Redis(Redis Transactions)》
- 《Redis 之坑:spring-data-redis 中的 Redis 事务》
- 《Spring Data Redis 事务专题》
5.2.4 闲话两句
实际场景下,如果胖友有 Redis 事务的诉求,建议把事务的、和非事务的 RedisTemplate 拆成两个连接池,相互独立。主要原因有两个:
- 1)Spring Data Redis 的事务设计,是将其融入到 Spring 整个 Transaction 当中。一般来说,Spring Transaction 中,肯定会存在数据库的 Transaction 。考虑到数据库操作相比 Redis 来说,肯定是慢得多,那么就会导致 Redis 的 Connection 一直被当前 Transaction 占用着。
- 2)How can i eliminate getting junk value through redis get command?
5.3 Session
首先,我们需要澄清下,Session 不是 Redis 的功能,而是 Spring Data Redis 封装的一个功能。一次 Session ,代表通过同一个 Redis Connection 执行一系列的 Redis 操作。
在 「5.2.1 源码解析」 中,我们可以发现,如果我们在一个 Redis Transaction 中的时候,所有 Redis 操作都使用同一个 Redis Connection ,因为我们会将获得到的 Connection 绑定到当前线程中。
但是,如果我们不在一个 Redis Transaction 中的时候,我们每一次使用 Redis Operations 执行 Redis 操作的时候,每一次都会获取一次 Redis Connection 的获取。实际项目中,我们必然会使用 Redis Connection 连接池,那么在获取的时候,会存在一定的竞争,会有资源上的消耗。那么,如果我们希望已知我们要执行一个系列的 Redis 操作,能不能使用同一个 Redis Connection ,避免重复获取它呢?答案是有,那就是 Session 。
当我们要执行在同一个 Session 里的操作时,我们通过实现 org.springframework.data.redis.core.SessionCallback 接口,其代码如下:
// SessionCallback.java
public interface SessionCallback {
@Nullable
T execute(RedisOperations operations) throws DataAccessException;
} - 相比 RedisCallback 来说,总体是比较相似的。但是比较友好的是,它的入参
operations是 org.springframework.data.redis.core.RedisOperations 接口类型,而 RedisTemplate 的各种操作,实际就是在 RedisOperations 接口中定义,由 RedisTemplate 来实现。所以使用上也会更加便利。 - 实际上,我们在实现 RedisCallback 接口,也能实现在同一个 Connection 执行一系列的 Redis 操作,因为 RedisCallback 的入参本身就是一个 Redis Connection 。
5.3.1 源码解析
在生产中,Transaction 和 Pipeline 会经常一起使用,从而提升性能。所以在 RedisTemplate#executePipelined(SessionCallback session, ...) 方法中,提供了这种的功能。而在这个方法的实现上,本质和 RedisTemplate#executePipelined(RedisCallback action, ...) 方法是基本一致的,差别在于这一行 ,替换成了调用 #executeSession(SessionCallback session) 方法。所以,我们来直接来看被调用的这个方法的实现。代码如下:
// RedisTemplate.java
@Override
public T execute(SessionCallback session) {
Assert.isTrue(initialized, "template not initialized; call afterPropertiesSet() before using it");
Assert.notNull(session, "Callback object must not be null");
RedisConnectionFactory factory = getRequiredConnectionFactory();
// bind connection
// <1> 获得并绑定 Connection 。
RedisConnectionUtils.bindConnection(factory, enableTransactionSupport);
try {
// <2> 执行定义的一系列 Redis 操作
return session.execute(this);
} finally {
// <3> 释放并解绑 Connection 。
RedisConnectionUtils.unbindConnection(factory);
}
} <1>处,调用RedisConnectionUtils#bindConnection(RedisConnectionFactory factory, boolean enableTranactionSupport)方法,实际和我们开启enableTranactionSupport事务时候,获取 Connection 和处理的方式,是一模一样的。也就是说:- 如果当前线程已经有一个绑定的 Connection 则直接使用(例如说,当前正在 Redis Transaction 事务中);
- 如果当前线程未绑定一个 Connection ,则进行创建并绑定到当前线程。甚至,如果此时是配置开启
enableTranactionSupport事务的,那么此处就会触发 Redis Transaction 的开启。
<2>处,调用SessionCallback#execute(RedisOperations方法,执行我们定义的一系列的 Redis 操作。看看此处传入的参数是this,是不是仿佛更加明白点什么了?<3>处,调用RedisConnectionUtils#unbindConnection(RedisConnectionFactory factory)方法,释放并解绑 Connection 。当前,前提是当前不存在激活的 Redis Transaction ,不然不就提早释放了嘛。
恩,现在胖友在回过头,好好在想一想 Pipeline、Transaction、Session 之间的关系,以及组合排列。之后,我们在使用上,会更加得心应手。
5.3.2 具体示例
示例代码对应测试类:SessionTest 。
创建 SessionTest 单元测试类,编写代码如下:
// SessionTest.java
@RunWith(SpringRunner.class)
@SpringBootTest
public class SessionTest {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
public void test01() {
String result = stringRedisTemplate.execute(new SessionCallback() {
@Override
public String execute(RedisOperations operations) throws DataAccessException {
for (int i = 0; i < 100; i++) {
operations.opsForValue().set(String.format("yunai:%d", i), "shuai02");
}
return (String) operations.opsForValue().get(String.format("yunai:%d", 0));
}
});
System.out.println("result:" + result);
}
}
执行 #test01() 方法,结果如下:
result:shuai02- 卧槽,一直被 Redis 夸奖,已经超级不好意思了。
5.4 Pub/Sub
Redis 提供了 Pub/Sub 功能,实现简单的订阅功能,不了解的胖友,可以看看 「Redis 文档 —— Pub/Sub」 。
5.4.1 源码解析
暂时不提供,感兴趣的胖友,可以自己看看最核心的 org.springframework.data.redis.listener.RedisMessageListenerContainer 类,Redis 消息监听器容器,基于 Pub/Sub 的 SUBSCRIBE、PSUBSCRIBE 命令实现,我们只需要添加相应的 org.springframework.data.redis.connection.MessageListener 即可。不算复杂,1000 多行,只要调试下核心的功能即可。
5.4.2 具体示例
示例代码对应测试类:PubSubTest 。
Spring Data Redis 实现 Pub/Sub 的示例,主要分成两部分:
- 配置 RedisMessageListenerContainer Bean 对象,并添加我们自己实现的 MessageListener 对象,用于监听处理相应的消息。
- 使用 RedisTemplate 发布消息。
下面,我们通过四个小步骤,来实现一个简单的示例。
第一步,了解 Topic
org.springframework.data.redis.listener.Topic 接口,表示 Redis 消息的 Topic 。它有两个子类实现:
- ChannelTopic :对应 SUBSCRIBE 订阅命令。
- PatternTopic :对应 PSUBSCRIBE 订阅命令。
第二步,实现 MessageListener 类
创建 TestChannelTopicMessageListener 类,编写代码如下:
public class TestPatternTopicMessageListener implements MessageListener {
@Override
public void onMessage(Message message, byte[] pattern) {
System.out.println("收到 PatternTopic 消息:");
System.out.println("线程编号:" + Thread.currentThread().getName());
System.out.println("message:" + message);
System.out.println("pattern:" + new String(pattern));
}
}message参数,可获得到具体的消息内容,不过是二进制数组,需要我们自己序列化。具体可以看下org.springframework.data.redis.connection.DefaultMessage类。pattern参数,发布的 Topic 的内容。
有一点要注意,默认的 RedisMessageListenerContainer 情况下,MessageListener 是并发消费,在线程池中执行(具体见传送门代码)。所以如果想相同 MessageListener 串行消费,可以在方法上加 synchronized 修饰,来实现同步。
第三步,创建 RedisMessageListenerContainer Bean
在 RedisConfiguration 中,配置 RedisMessageListenerContainer Bean 。代码如下:
// RedisConfiguration.java
@Bean
public RedisMessageListenerContainer listenerContainer(RedisConnectionFactory factory) {
// 创建 RedisMessageListenerContainer 对象
RedisMessageListenerContainer container = new RedisMessageListenerContainer();
// 设置 RedisConnection 工厂。? 它就是实现多种 Java Redis 客户端接入的秘密工厂。感兴趣的胖友,可以自己去撸下。
container.setConnectionFactory(factory);
// 添加监听器
container.addMessageListener(new TestChannelTopicMessageListener(), new ChannelTopic("TEST"));
// container.addMessageListener(new TestChannelTopicMessageListener(), new ChannelTopic("AOTEMAN"));
// container.addMessageListener(new TestPatternTopicMessageListener(), new PatternTopic("TEST"));
return container;
}要注意,虽然 RedisConnectionFactory 可以多次调用 #addMessageListener(MessageListener listener, Topic topic) 方法,但是一定要都是相同的 Topic 类型。例如说,添加了 ChannelTopic 类型,就不能添加 PatternTopic 类型。为什么呢?因为 RedisMessageListenerContainer 是基于一次 SUBSCRIBE 或 PSUBSCRIBE 命令,所以不支持不同类型的 Topic 。当然,如果是相同类型的 Topic ,多个 MessageListener 是支持的。
那么,可能会有胖友会问,如果我添加了 "Test" 给 MessageListenerA ,"AOTEMAN" 给 MessageListenerB ,两个 Topic 是怎么分发(Dispatch)的呢?在 RedisMessageListenerContainer 中,有个 DispatchMessageListener 分发器,负责将不同的 Topic 分发到配置的 MessageListener 中。看到此处,有木有想到 Spring MVC 的 DispatcherServlet 分发不同的请求到对应的 @RequestMapping 方法。
第四步,使用 RedisTemplate 发布消息
创建 PubSubTest 测试类,编写代码如下:
@RunWith(SpringRunner.class)
@SpringBootTest
public class PubSubTest {
public static final String TOPIC = "TEST";
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
public void test01() throws InterruptedException {
for (int i = 0; i < 10; i++) {
stringRedisTemplate.convertAndSend(TOPIC, "yunai:" + i);
Thread.sleep(1000L);
}
}
}- 通过
RedisTemplate#convertAndSend(String channel, Object message)方法,PUBLISH 消息。
执行 #test01() 方法,运行结果如下:
收到 ChannelTopic 消息:
线程编号:listenerContainer-2
message:yunai:0
pattern:TEST
收到 ChannelTopic 消息:
线程编号:listenerContainer-3
message:yunai:1
pattern:TEST
收到 ChannelTopic 消息:
线程编号:listenerContainer-4
message:yunai:2
pattern:TEST- 整整齐齐,发送和订阅都成功了。注意,线程编号。
5.4.3 闲话两句
Redis 5.0 版本后,正式发布 Stream 功能,相信是有可能可以替代掉 Redis Pub/Sub 功能,提供可靠的消息订阅功能。
上述的场景,艿艿自己在使用 PUB/SUB 功能的时候,确实被这么坑过。当时我们的管理后台的权限,是缓存在 Java 进程当中,通过 Redis Pub/Sub 实现缓存的刷新。结果,当时某个 Java 节点网络出问题,恰好那个时候,有一条刷新权限缓存的消息 PUBLISH 出来,结果没刷新到。结果呢,运营在访问某个功能的时候,一会有权限(因为其他 Java 节点缓存刷新了),一会没有权限。
最近,艿艿又去找了几个朋友请教了下,问问他们在生产环境下,是否使用 Redis Pub/Sub 功能,他们说使用 Kafka、或者 RocketMQ 的广播消费功能,更加可靠有保障。
对了,我们有个管理系统里面有 Websocket 需要实时推送管理员消息,因为不知道管理员当前连接的是哪个 Websocket 服务节点,所以我们是通过 Redis Pub/Sub 功能,广播给所有 Websocket 节点,然后每个 Websocket 节点判断当前管理员是否连接的是它,如果是,则进行 Websocket 推送。因为之前网络偶尔出故障,会存在消息丢失,所以近期我们替换成了 RocketMQ 的广播消费,替代 Redis Pub/Sub 功能。
当然,不能说 Redis Pub/Sub 毫无使用的场景,以下艿艿来列举几个:
- 1、在使用 Redis Sentinel 做高可用时,Jedis 通过 Redis Pub/Sub 功能,实现对 Redis 主节点的故障切换,刷新 Jedis 客户端的主节点的缓存。如果出现 Redis Connection 订阅的异常断开,会重新主动去 Redis Sentinel 的最新主节点信息,从而解决 Redis Pub/Sub 可能因为网络问题,丢失消息。
- 2、Redis Sentinel 节点之间的部分信息同步,通过 Redis Pub/Sub 订阅发布。
- 3、在我们实现 Redis 分布式锁时,如果获取不到锁,可以通过 Redis 的 Pub/Sub 订阅锁释放消息,从而实现其它获得不到锁的线程,快速抢占锁。当然,Redis Client 释放锁时,需要 PUBLISH 一条释放锁的消息。在 Redisson 实现分布式锁的源码中,我们可以看到。
- 4、Dubbo 使用 Redis 作为注册中心时,使用 Redis Pub/Sub 实现注册信息的同步。
也就是说,如果想要有保障的使用 Redis Pub/Sub 功能,需要处理下发起订阅的 Redis Connection 的异常,例如说网络异常。然后,重新主动去查询最新的数据的状态。?
5.5 Script
Redis 提供 Lua 脚本,满足我们希望组合排列使用 Redis 的命令,保证串行执行的过程中,不存在并发的问题。同时,通过将多个命令组合在同一个 Lua 脚本中,一次请求,直接处理,也是一个提升性能的手段。不了解的胖友,可以看看 「Redis 文档 —— Lua 脚本」 。
示例代码对应测试类:ScriptTest 。
第一步,编写 Lua 脚本
创建 resources/compareAndSet.lua 脚本,实现 CAS 功能。代码如下:
if redis.call('GET', KEYS[1]) ~= ARGV[1] then
return 0
end
redis.call('SET', KEYS[1], ARGV[2])
return 1- 第 1 到 3 行:判断
KEYS[1]对应的 VALUE 是否为ARGV[1]值。如果不是(Lua 中不等于使用~=),则直接返回 0 表示失败。 - 第 4 到 5 行:设置
KEYS[1]对应的 VALUE 为新值ARGV[2],并返回 1 表示成功。
第二步,调用 Lua 脚本
创建 ScriptTest 测试类,编写代码如下:
@RunWith(SpringRunner.class)
@SpringBootTest
public class ScriptTest {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
public void test01() throws IOException {
// <1.1> 读取 /resources/lua/compareAndSet.lua 脚本 。注意,需要引入下 commons-io 依赖。
String scriptContents = IOUtils.toString(getClass().getResourceAsStream("/lua/compareAndSet.lua"), "UTF-8");
// <1.2> 创建 RedisScript 对象
RedisScript script = new DefaultRedisScript<>(scriptContents, Long.class);
// <2> 执行 LUA 脚本
Long result = stringRedisTemplate.execute(script, Collections.singletonList("yunai:1"), "shuai02", "shuai");
System.out.println(result);
}
} <1.1>行,读取/resources/lua/compareAndSet.lua脚本。注意,需要引入下commons-io依赖。<1.2>行,创建 DefaultRedisScript 对象。第一个参数是脚本内容(scriptSource),第二个是脚本执行返回值(resultType)。<2>处,调用RedisTemplate#execute(RedisScript方法,发送 Redis 执行 LUA 脚本。script, List keys, Object... args)
最后,我们打印下执行结果。胖友可以自己执行下试试。?
6. 尝试 Redisson
在 redisson-examples 中,Redisson 官方提供了大量的示例。
6.1 快速入门
示例代码对应仓库:spring-data-redis-with-redisson 。
6.1.1 引入依赖
在 pom.xml 中,引入相关依赖。
org.springframework.boot
spring-boot-starter-parent
2.1.3.RELEASE
org.redisson
redisson-spring-boot-starter
3.11.3
org.springframework.boot
spring-boot-starter-test
test
com.alibaba
fastjson
1.2.61
com.fasterxml.jackson.core
jackson-databind
commons-io
commons-io
2.6
和 「2.1 引入依赖」 的差异点是,我们需要引入 redisson-spring-boot-starter 依赖,实现 Redisson 的自动化配置。
6.1.2 配置文件
在 application.yml 中,添加 Redis 配置,如下:
spring:
# 对应 RedisProperties 类
redis:
host: 127.0.0.1
port: 6379
# password: # Redis 服务器密码,默认为空。生产中,一定要设置 Redis 密码!
database: 0 # Redis 数据库号,默认为 0 。
timeout: 0 # Redis 连接超时时间,单位:毫秒。
# 对应 RedissonProperties 类
redisson:
config: classpath:redisson.yml # 具体的每个配置项,见 org.redisson.config.Config 类。和 「2.2 配置文件」 的差异点是:
1)去掉 Jedis 相关的配置项
2)增加 redisson.config 配置
在我们使用 Spring Boot 整合 Redisson 时候,通过该配置项,引入一个外部的 Redisson 相关的配置文件。例如说,示例中,我们引入了 classpath:redisson.yaml 配置文件。它可以使用 JSON 或 YAML 格式,进行配置。
FROM 《Spring Boot 2.x 整合 lettuce redis 和 redisson》 文章。
clusterServersConfig:
# 连接空闲超时 如果当前连接池里的连接数量超过了最小空闲连接数,而同时有连接空闲时间超过了该数值,那么这些连接将会自动被关闭,并从连接池里去掉。时间单位是毫秒。
idleConnectionTimeout: 10000
pingTimeout: 1000
# 连接超时
connectTimeout: 10000
# 命令等待超时
timeout: 3000
# 命令失败重试次数
retryAttempts: 3
# 命令重试发送时间间隔
retryInterval: 1500
# 重新连接时间间隔
reconnectionTimeout: 3000
# failedAttempts
failedAttempts: 3
# 密码
password: null
# 单个连接最大订阅数量
subscriptionsPerConnection: 5
# 客户端名称
clientName: null
#负载均衡算法类的选择 默认轮询调度算法RoundRobinLoadBalancer
loadBalancer: ! {}
slaveSubscriptionConnectionMinimumIdleSize: 1
slaveSubscriptionConnectionPoolSize: 50
# 从节点最小空闲连接数
slaveConnectionMinimumIdleSize: 32
# 从节点连接池大小
slaveConnectionPoolSize: 64
# 主节点最小空闲连接数
masterConnectionMinimumIdleSize: 32
# 主节点连接池大小
masterConnectionPoolSize: 64
# 只在从服务节点里读取
readMode: "SLAVE"
# 主节点信息
nodeAddresses:
- "redis://192.168.56.128:7000"
- "redis://192.168.56.128:7001"
- "redis://192.168.56.128:7002"
#集群扫描间隔时间 单位毫秒
scanInterval: 1000
threads: 0
nettyThreads: 0
codec: ! {} 注意
注意
注意
如果 redisson.config 对应的配置文件,没有配置任何内容,需要在 application.yml 里注释掉 redisson.config 。像这样:
spring:
# 对应 RedisProperties 类
redis:
host: 127.0.0.1
port: 6379
# password: # Redis 服务器密码,默认为空。生产中,一定要设置 Redis 密码!
database: 0 # Redis 数据库号,默认为 0 。
timeout: 0 # Redis 连接超时时间,单位:毫秒。
# 对应 RedissonProperties 类
# redisson:
# config: classpath:redisson.yml # 具体的每个配置项,见 org.redisson.config.Config 类。6.1.3 简单测试
创建 Test01 测试类,我们来测试一下简单的 SET 指令。代码如下:
@RunWith(SpringRunner.class)
@SpringBootTest
public class Test01 {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
public void testStringSetKey() {
stringRedisTemplate.opsForValue().set("yunai", "shuai");
}
}我们先来执行下 #testStringSetKey() 方法这个测试方法。执行完成后,我们在控制台查询,看看是否真的执行成功了。
$ redis-cli get yunai
"shuai"- 请大声的告诉我,Redis 是怎么夸奖
"yunai"的,哈哈哈哈。
6.1.4 闲聊两句
因为有 Spring Data Redis 的存在,我们其实已经能感受到,即使我们将 Jedis 替换成了 Redisson ,依然调用的是相同的 Spring Data Redis 提供的 API ,而无需感知到 Redisson 或是 Jedis 的存在。如果哪一天,Spring Boot 2.X 版本默认推荐的 Lettuce 真的成熟了,那么我们也可以无感知的进行替换。
6.2 Redis 分布式锁
示例代码对应测试类:LockTest 。
一说到分布式锁,大家一般会想到的就是基于 Zookeeper 或是 Redis 实现分布式锁。相对来说,在考虑性能为优先因素,不需要特别绝对可靠性的场景下,我们会优先考虑使用 Redis 实现的分布式锁。
在 Redisson 中,提供了 8 种分布式锁的实现,具体胖友可以看看 《Redisson 文档 —— 分布式锁和同步器》 。真特码的强大!大多数开发者可能连 Redis 怎么实现分布式锁都没完全搞清楚,Redisson 直接给了 8 种锁,气人,简直了。
本小节,我们来编写一个简单使用 Redisson 提供的可重入锁 RLock 的示例。
创建 LockTest 测试类,编写代码如下:
@RunWith(SpringRunner.class)
@SpringBootTest
public class LockTest {
private static final String LOCK_KEY = "anylock";
@Autowired // <1>
private RedissonClient redissonClient;
@Test
public void test() throws InterruptedException {
// <2.1> 启动一个线程 A ,去占有锁
new Thread(new Runnable() {
@Override
public void run() {
// 加锁以后 10 秒钟自动解锁
// 无需调用 unlock 方法手动解锁
final RLock lock = redissonClient.getLock(LOCK_KEY);
lock.lock(10, TimeUnit.SECONDS);
}
}).start();
// <2.2> 简单 sleep 1 秒,保证线程 A 成功持有锁
Thread.sleep(1000L);
// <3> 尝试加锁,最多等待 100 秒,上锁以后 10 秒自动解锁
System.out.println(String.format("准备开始获得锁时间:%s", new SimpleDateFormat("yyyy-MM-DD HH:mm:ss").format(new Date())));
final RLock lock = redissonClient.getLock(LOCK_KEY);
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
System.out.println(String.format("实际获得锁时间:%s", new SimpleDateFormat("yyyy-MM-DD HH:mm:ss").format(new Date())));
} else {
System.out.println("加锁失败");
}
}
}- 整个测试用例,意图是:1)启动一个线程 A ,先去持有锁 10 秒然后释放;2)主线程,也去尝试去持有锁,因为线程 A 目前正在占用着该锁,所以需要等待线程 A 释放到该锁,才能持有成功。
<1>处,注入 RedissonClient 对象。因为我们需要使用 Redisson 独有的功能,所以需要使用到它。<2.1>处,启动线程 A ,然后调用RLock#lock(long leaseTime, TimeUnit unit)方法,加锁以后 10 秒钟自动解锁,无需调用 unlock 方法手动解锁。<2.2>处,简单 sleep 1 秒,保证线程 A 成功持有锁。<3>处,主线程,调用RLock#tryLock(long waitTime, long leaseTime, TimeUnit unit)方法,尝试加锁,最多等待 100 秒,上锁以后 10 秒自动解锁。
执行 #test() 测试用例,结果如下:
准备开始获得锁时间:2019-10-274 00:44:08
实际获得锁时间:2019-10-274 00:44:17- 9 秒后(因为我们 sleep 了 1 秒),主线程成功获得到 Redis 分布式锁,符合预期。
666. 彩蛋
写了老长一篇,都不晓得有木有会看。断断续续写了小一周,不晓得有木有胖友会看完,甚至看到彩蛋环节,哈哈哈哈。
在高并发场景下,系统会大量依赖缓存和消息队列,实现所需要的高性能。而缓存,绝大部分的选择,基本都是 Redis ,这点毋庸置疑。所以,我们是非常有必要深入去学习下 Redis ,友情推荐下付磊大佬的 《Redis 开发与运维》 。
因为写的还是略有些聪明,所以有错误或者表达不清晰的地方,欢迎胖友指出。国庆快乐,继续学习!