Python之代码规范管理工具
参考链接
在之前《使代码整洁的几种规范》文章中,介绍了比较常用的变量、函数等定义方法,本文专门针对python的代码风格进行介绍,主要用到两个超牛的工具pylink和black,可以对代码风格进行规范检测和自动优化。
python界被广泛认同的代码风格是PEP8,这种规则对行长度、缩进、多行表达式、变量命名等内容进行了统一约定,但要注意的是,PEP8中有一些规范是为了方便阅读,而有一些规范实实在在地影响着代码的性能、容错率或重构难度,因此要合理利用,不要盲目使用。具体的规范可参考《python常见的PEP8规范》,这里不做详细介绍,着重讲代码自动化检测和优化工具。
1 自动检测工具Pylint
Pylint 是一个检查违反 PEP8 规范和常见错误的库,它会自动查找不符合代码风格标准和有潜在问题的代码,并在控制台输出代码中违反规范和出现问题的相关信息。
1.安装与使用
与python的其他库一样,直接 pip install pylint 即可完成安装,另外anaconda自带pylint,所以如果安装过anaconda不必再单独安装此库。pylint的使用也非常简单,最基本的用法直接在控制台输入 pylint 路径/模块名 即可对相关模块的代码风格规范 进行检查,检查结果会在控制台输出。建议结合 pylint --help 的提示进行 学习和检索。介绍完pylint的基本情况,我们来结合一个实例进行详细说明。
2).实例演示说明
这里我找了自己刚学python时写的一段代码test.py进行测试:
import pandas as pd
data = []
char_replace_dict = {':':'\t', '(':'(', ')':')', ',':','}
with open('xmq_survey.txt', 'r', encoding = 'utf-8') as file:
for line in file.readlines():
for key, value in char_replace_dict.items():
line = line.replace(key, value)#原来这个是深度引用
#这条代码比自己写的简介的多,也更python
data.append(line)
with open('survey.txt', 'w', encoding = 'utf-8') as file:
for line in data:
file.write(line)
raw_data = pd.read_table('survey.txt', delimiter = '\t', header = None) #查看read_table函数的用法
raw_data.columns = ['Name', 'Raw Info']
raw_data.count()
print('successful')乍一看好像没什么大问题,但是经过pylint检查后(pylint test.py)却给出了一堆问题提示(下图),我们来看检查结果,每行以大写字母+冒号开头的信息都是一处反馈提示。

其中开头的大写字母表示错误类型(主要有C\R\W\E\F几类);以逗号间隔的两个数字表示发现问题的位置(行和 列);其后是对问题的具体描述,括号里的内容称为message id,可以简单理解为错误类型的详细分类,通过pylint --help-msg=
C——违反代码风格标准;
R——代码结构较差;
W——关于细节的警告;
E——代码中存在错误;
F——导致Pylint无法继续运行的错误。根据输出信息进行对应的修改,但还是要强调一下,PEP8不是百分百需要遵守的,当遵循PEP8使自己代码的可读性变差、与自己代码风格不一致的时候,还是要遵循自己的判断。这种情况下,pylint也提供了一种操作,可以手动屏蔽某些问题提示,以刚才的代码为例,剩下的几个问题主要是因为使用了Tab键、变量命名不规范、缺少文档说明造成的,我们可以使用pylint --disable=mixex-indentation,invalid-name,missing-docstring 模块名称 命令对相关规范进行屏蔽重新检 测,发现问题提示全部消除,评分也提升到了10分。
一段20行的代码就检测到如此之多的问题提示,虽然手动修改代码有助于对PEP 8规范的学习,但当项目文件比较 多、脚本代码很长的时候,实在是一个不小的工作量,因此就出现了能够自动优化代码风格的工具。
2 自动优化工具black
在众多代码格式化工具中,Black算是比较新的一个,它最大的特点是可配置项比较少,个人认为这对于新手来说是件好事,因为我们不必过多考虑如何设置Black,让 Black 自己做决定就好。
1).安装与使用
与pylint类似,直接pip install black即可完成该模块的安装,不过black依赖于Python 3.6+,但它仍然可以格式化Python2的代码。在使用方面black默认读取指定python文件并对其进行代码规范格式化,然后输出到原文件。
ubuntu自带的python版本是3.6,因此需要将python版本升级一下
#获取最新的python3.6,将其添加至当前apt库中,并自动导入公钥
$ sudo add-apt-repository ppa:jonathonf/python-3.6
$ sudo apt-get update
$ sudo apt-get install python3.6
# 移除原3.5 link
$ sudo rm /usr/bin/python
# 更换默认python3 的版本为3.6
$ sudo ln -s /usr/bin/python3.6 /usr/bin/python
升级完python后,pip也需要对应的升级
git clone https://github.com/pypa/get-pip.git
cd get-pip
python get-pip.py2).实例演示说明
这里我们仍然使用pylint部分的代码进行演示。通过上面的操作我们知道,对这段代码直接使用pylint进行测试会输出很多问题提示,并给出一个评分0.67。现在我们首先使用black对其进行格式化,得到以下代码:
import pandas as pd
data = []
char_replace_dict = {":": "\t", "(": "(", ")": ")", ",": ","}
with open("xmq_survey.txt", "r", encoding="utf-8") as file:
for line in file.readlines():
for key, value in char_replace_dict.items():
line = line.replace(key, value) # 原来这个是深度引用
# 这条代码比自己写的简介的多,也更python
data.append(line)
with open("survey.txt", "w", encoding="utf-8") as file:
for line in data:
file.write(line)
raw_data = pd.read_table("survey.txt", delimiter="\t", header=None) # 查看read_table函数的用法
raw_data.columns = ["Name", "Raw Info"]
raw_data.count()
print("successful")可能看起来修改前后的代码差异并不十分明显,实质上black已经对代码中参数赋值 = 两端的空格、注释的格式、 制表符等进行了替换和修改,我们使用pylint来进行验证,执行 pylint 模块名称命令,得到如下结果:
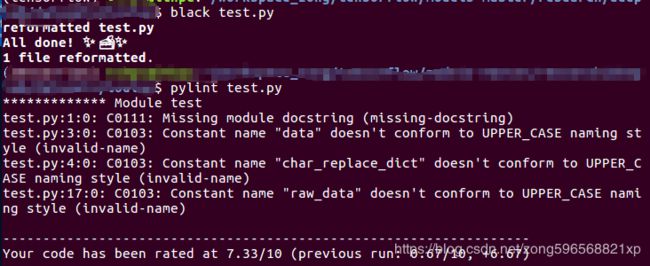
可以看到,相对于最初的文件,评分从0.67分提高到7.3分,输出的问题提示少了很多,剩余的问题主要是缺少说明文档、变量命名不规范,black对于提高我们代码规范性价比也是非常高的。
如果不想black直接对原文件进行修改,而是想看看它对代码中的哪些地方进行了改动的话,可以使用--diff参数,执行black --diff 文件名称,black会将相关信息输出到控制台(下图,其中-表示源代码,+表示建议修改后的代码),而不会对原文件进行修改。

总之,black真的是一个非常好用的库,尤其对于新手来说,可以很方便地规范自己的代码风格。