一文理解数据库索引
数据库索引虽然有多种,但一般说的就是B-tree索引,B-tree索引可抽象理解为”排好序的快速查找结构”。既然是排好序的,当然就非常利于顺序读,而且有利于范围查询以及排序。本文说的索引就特指B-tree索引。
一.复合索引
索引使用常见的一个误区是,在where条件用到的列上都加上索引。
例: where cat_id=3 and price>100 ; //查询第3个栏目,100元以上的商品
认为在cat_id列和price列上都加上索引性能会更好。可实际上,只能用上cat_id列或price列中的1个索引,因为是独立的索引,同时只能用上1个。cat_id列或price列,是彼此独立的”排好序的快速查找结构”,当使用cat_id列索引快速定位到数据行后,price列的索引顺序与cat_id列毫无关系,已经发挥不了作用了。如果要达到期望的效果,需要为cat_id列和price列建立多列联合索引,或者叫复合索引。复合索引会先按cat_id列值进行排序,cat_id列值相同的行索引再按price列值进行排列。
多列索引上,索引发挥作用,需要满足左前缀要求。即要按索引建立的顺序从左到右使用,中间如果断开,后边的索引列就用不上了。例如,某个表有一个复合索引(c1,c2,c3,c4),条件语句where c1=x and c2=x and c4=x ,只能使用c1和c2,因为在c3断开了。如果这样写where c1=x and c2=x and c4=x and c3=x,索引c1,c2,c3,c4都能用上,虽然c3和c4写反了,但数据库会在不影响语义的情况下进行优化。除了where,order by也可以使用索引,条件语句where c1=x and c2=x and c4=x order by c3,索引c1,c2能用来过滤数据,c3可以用来排序,防止出现filesort,这种情况c4用不上。如果是where c1=x and c2=x and c4=x order by c5,就会出现filesort。此外,group by也会使用索引。因为一般而言,分组统计要先按分组字段有序排列。如果group by 的列没有索引,肯定产生临时表。
当一个表有多条索引可走时, 数据库会根据查询语句的成本来选择走哪条索引, 联合索引的话, 它往往计算的是第一个字段(最左边那个),这样往往会走错索引。如:索引Index_1(Create_Time, Category_ID)、Index_2(Category_ID) ,如果每天(相同Create_Time)的数据都特别多, 而且有很多category,但具体每个category的记录不会很多。当查询SQL条件为select …where create_time= ….and category_id=..时,很可能不走索引Index_1,而走索引Index_2,导致查询比较慢。解决办法是将索引字段的顺序调换一下。
二.聚簇索引
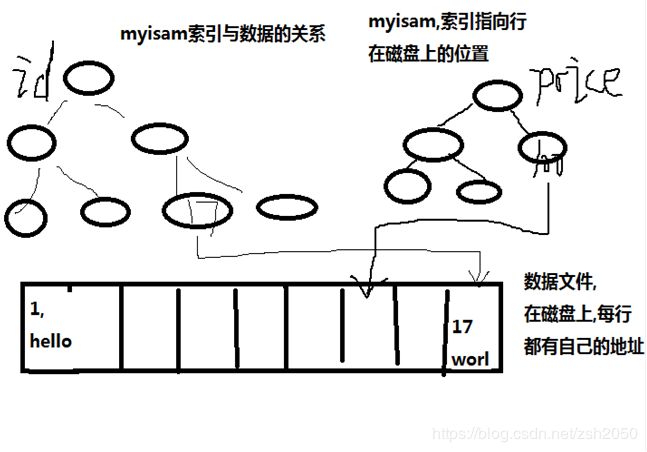
这里先以mysql的两种主要存储引擎InnoDB和MyISAM为例。
InnoDB使用的是聚簇索引,主索引文件上 直接存放该行数据,称为聚簇索引。次索引指向对主键的引用。也就是说数据的存放是按主索引树进行组织。

MyISAM使用的是非聚簇索引,主索引和次索引,都指向物理行(磁盘位置)。
InnoDB存储引擎的特点:
1.主键索引,既存储索引值,又在叶子中存储行的数据。
2.如果没有主键,则会Unique key做主键
3.如果没有unique,则系统生成一个内部的rowid做主键.
像innodb这样,主键的索引结构中,既存储了主键值,又存储了行数据,这种结构称为”聚簇索引”。
优势: 根据主键查询条目比较少时,不用回行(数据就在主键节点下)。
劣势: 如果碰到不规则数据插入,造成频繁的页分裂时,因为节点下有数据文件,因此节点的分裂将会比较慢。
这里引出了一个页分裂的概念。创建聚簇索引时,表格内的数据会按照索引的顺序存储在数据库的数据页中,当新的主键不规则的数据行插入到数据表中,必须刷新数据在数据库中的存储位置。这样就导致索引页中的数据存储方式改变,当某页中数据已满的情况下,就将会创建一个新页,并根据规则将原有页中的部分数据放入新页中,以挪出空间给新的记录行使用。当页分裂的次数较多时,会影响效率。
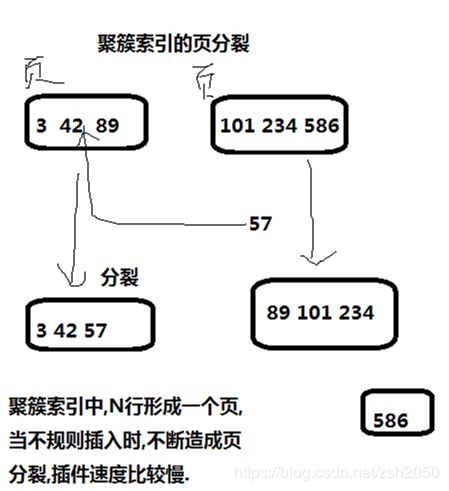
因此,对于使用聚簇索引的数据库主键,高性能索引的策略是,尽量用整型,而且是递增的整型。如果是无规律的数据,将会产生的页的分裂,影响速度。
根据是否使用聚簇索引,可以将数据表分为堆表和索引组织表。
堆表(heap table)数据插入时时存储位置是随机的,主要视数据库内部块的空闲情况决定,全表扫表时不见得先插入的数据先查到。
索引组织表(iot)数据存储是把表按照索引的方式存储的,数据是有序的,数据的位置是预先定好的,与插入的顺序没有关系。
主流数据库中,Oracle支持堆表,也支持索引组织表;PostgreSQL只支持堆表;mysql的InnoDB引擎使用索引组织表,MyISAM引擎则使用堆表。
三.索引覆盖
回行的是指由索引到磁盘取数据的过程。因为索引是非常利于查找的数据结构,而且索引一般还会进行内存缓存,所以访问索引是非常快的,相对来说回行是非常慢的。
索引覆盖是指,如果要查询的列恰好是索引的一部分,那么查询只需要在索引文件上进行,不需要回行到磁盘再找数据。这种查询速度非常快,称为”索引覆盖”。
比如用户表name列已经建立了索引,如果只查询这一列,select name from user where name='tom' ,只需要在索引文件上就能查到数据,不需要回行到磁盘再找数据。而如果select name, age, gender from user where name='tom' ,因为还要查其它数据,就需要回行,无法做到索引覆盖。
索引组织表数据直接按主键索引存储,所以主键索引不存在回行,但次索引需要到主索引去查找数据,所以也需要回行。
聚簇索引,由于主键的索引结构中,既存储了主键值,又存储了行数据,如果行数据中存在长字符串字段或大文件字段,又因为聚簇索引页存储结构,造成每个页中存储数据行变少,页数量变多,当查询跨页较多会影响效率。所以,有的时候如果能够使用索引覆盖而不用回行的查询,因为没有跨页问题,用次索引反而比用主索引更快。
四.索引长度和区分度
理想的索引应该有以下特点:
1.查询频繁
2.区分度高
3.长度小
4.尽量能覆盖常用查询字段
其中长度和区分度是一对矛盾。长度越小越好,而区分度越高越好,而两者是矛盾的,所以两者要达到一个平衡。索引长度直接影响索引文件的大小,影响增删改的速度,并间接影响查询速度(占用内存多)。
如果要对有些长字符串列加索引,可以设定索引长度,从左往右截取部分,来建索引。
1: 截的越短, 重复度越高,区分度越小, 索引效果越不好
2: 截的越长, 重复度越低,区分度越高, 索引效果越好,但带来的影响也越大--增删改变慢,并间影响查询速度。
对于多列复合索引,哪个列应该排在前,哪个列排在后,应首先从业务需求角度出发,看哪个列的查询频率高,哪个列在前。其次则应该看区分度,区分度高的列在前。
五.索引与排序
对于排序,有两种情况:
1.当能够使用索引覆盖,直接在索引上查询时,一边查询,一边查询的结果就是有序的。
2.查出的结果是无序的,根据查出的结果,再次排序,形成临时表,做filesort(文件排序,可能在磁盘上,也可能在内存中)。
我们的争取目标当然是第一种,也就是取出来的数据本身就是有序的。后一种要在临时表做filesort,当然速度就会慢。所以索引不仅能帮助我们查询,也能帮助我们排序,要尽量利用索引来排序。
六.重复索引与冗余索引
重复索引是指在同1个列或者顺序相同的几个列,建立了多个索引。重复索引没有任何帮助,只会增大索引文件,拖慢更新速度,应该禁止。
冗余索引是指2个索引所覆盖的列有重叠, 称为冗余索引。比如 x,y列, 有索引index x(x)和index xy(x,y)。两者的x列重叠了,这种情况,称为冗余索引。即使两个列完全相同,但顺序不同,也是冗余索引,而不是冗余索引,比如index yx(y,x)和index xy(x,y)。
今天是2019年除夕,春节快乐!!!