第三篇:手动部署Ceph集群(luminous)
第二篇介绍了部署Ceph的环境准备工作,本篇主要内容是介绍手动部署Ceph的全过程。
环境
集群环境
第二篇,我们创建了3台虚拟机,虚拟机配置如下:
[root@ceph-1 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 100G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 99G 0 part
├─centos-root 253:0 0 50G 0 lvm /
├─centos-swap 253:1 0 2G 0 lvm [SWAP]
└─centos-home 253:2 0 47G 0 lvm /home
sdb 8:16 0 2T 0 disk
sdc 8:32 0 2T 0 disk
sdd 8:48 0 2T 0 disk
sde 8:64 0 600G 0 disk
sr0 11:0 1 1024M 0 rom
- 3块大小为2T的磁盘,sdb,sdc,sdd,用于启动osd进程
- 一块大小为600G的磁盘,作为osd的journal分区
集群配置如下:
| 主机 | IP | 功能 |
|---|---|---|
| ceph-1 | 192.168.56.101 | mon1、osd0、osd1、osd2 |
| ceph-2 | 192.168.56.102 | mon2、osd3、osd4、osd5 |
| ceph-3 | 192.168.56.103 | mon3、osd6、osd7、osd8 |
配置NTP服务
将NTP server放在ceph-1节点上,ceph-2/3节点是NTP client,这样可以从根本上解决时间同步问题。
修改配置文件
从本机登录到ceph-1:
ssh [email protected]
在ceph-1节点上进行如下操作:
修改/etc/ntp.conf,注释掉默认的四个server,添加三行配置如下:
vim /etc/ntp.conf
###comment following lines:
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
###add following lines:
server 127.127.1.0 minpoll 4
fudge 127.127.1.0 stratum 0
restrict 192.168.56.0 mask 255.255.0.0 nomodify notrap
修改/etc/ntp/step-tickers文件如下:
# List of NTP servers used by the ntpdate service.
# 0.centos.pool.ntp.org
127.127.1.0
在重启ntp服务之前需要将防火墙关闭,否则客户端不能访问ntp服务:
关闭防火墙
关闭selinux&firewalld
sed -i 's/SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
setenforce 0
systemctl stop firewalld
systemctl disable firewalld
启动ntp服务
重启ntp服务,并查看server端是否运行正常,正常的标准就是ntpq -p指令的最下面一行是*:
[root@ceph-1 ~]# systemctl enable ntpd
Created symlink from /etc/systemd/system/multi-user.target.wants/ntpd.service to /usr/lib/systemd/system/ntpd.service.
[root@ceph-1 ~]# systemctl restart ntpd
[root@ceph-1 ~]# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
*LOCAL(0) .LOCL. 0 l 15 16 1 0.000 0.000 0.000
NTP server端已经配置完毕,下面开始配置client端。
配置客户端ntp同步
同样的方式登录到ceph-2/ceph-3机器上:
修改/etc/ntp.conf,注释掉四行server,添加一行server指向ceph-1:
vim /etc/ntp.conf
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
server 192.168.56.101
重启ntp服务并观察client是否正确连接到server端,同样正确连接的标准是ntpq -p的最下面一行以*号开头:
[root@ceph-2 ~]# systemctl stop firewalld
[root@ceph-2 ~]# systemctl disable firewalld
[root@ceph-2 ~]# systemctl restart ntpd
[root@ceph-2 ~]# systemctl enable ntpd
Created symlink from /etc/systemd/system/multi-user.target.wants/ntpd.service to /usr/lib/systemd/system/ntpd.service.
开始的时候会显示INIT状态,然后等了几分钟之后就出现了*。
异常状态:
[root@ceph-2 ~]# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
ceph-1 .INIT. 16 u - 64 0 0.000 0.000 0.000
正常状态:
[root@ceph-2 ~]# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
*ceph-1 LOCAL(0) 3 u 45 64 77 0.323 0.060 0.034
在搭建ceph集群之前,一定要保证ntp服务能够正常运行。
手动搭建ceph集群
手动部署mon集群
主mon节点部署 (192.168.56.101,ceph-1)
登录到ceph-1机器:
ssh [email protected]
- 创建ceph用户与目录
新建一个脚本文件prepare_env.sh,然后写入以下内容:
[root@ceph-1 ~]# vim prepare_env.sh
/usr/sbin/groupadd ceph -g 167 -o -r
/usr/sbin/useradd ceph -u 167 -o -r -g ceph -s /sbin/nologin -c "Ceph daemons"
mkdir -p /etc/ceph/
chown -R ceph:ceph /etc/ceph/
mkdir -p /var/run/ceph
chown -R ceph:ceph /var/run/ceph
mkdir -p /var/log/ceph
chown -R ceph:ceph /var/log/ceph
mkdir -p /var/lib/ceph/mon
chown -R ceph:ceph /var/lib/ceph
- 创建ceph.conf文件
新建一个conf文件ceph.conf,然后写入以下内容:
[root@ceph-1 ~]# vim /etc/ceph/ceph.conf
[global]
fsid = c165f9d0-88df-48a7-8cc5-11da82f99c93
mon initial members = ceph-1
mon host = 192.168.56.101,192.168.56.102,192.168.56.103
rbd default features = 1
auth_cluster_required = none
auth_service_required = none
auth_client_required = none
public network = 192.168.56.0/24
cluster network = 192.168.56.0/24
osd journal size = 1024
osd pool default size = 3
osd pool default min size = 1
osd pool default pg num = 300
osd pool default pgp num = 300
osd crush chooseleaf type = 1
[mon]
mon allow pool delete = true
这里不对各个参数的含义进行解释,对于初学者而言,先把集群搭建起来,后面再去花时间了解整个ceph的原理及配置文件各个参数对集群的影响。
其中 fsid 是为集群分配的一个 uuid, 可使用uuidgen命令生成。初始化 mon 节点其实只需要这一个配置就够了。
mon host 配置 ceph 命令行工具访问操作 ceph 集群时查找 mon 节点入口。
ceph 集群可包含多个 mon 节点实现高可用容灾, 避免单点故障。
rbd default features = 1 配置 rbd 客户端创建磁盘时禁用一些需要高版本内核才能支持的特性。
- 拷贝这两个文件到ceph-2,ceph-3机器上
scp prepare_env.sh 192.168.56.102:/home
scp prepare_env.sh 192.168.56.103:/home
scp /etc/ceph/ceph.conf 192.168.56.102:/etc/ceph/
scp /etc/ceph/ceph.conf 192.168.56.103:/etc/ceph/
- 启动mon节点
首先执行脚本,创建ceph用户及相关目录。
sh prepare_env.sh
1、为此集群创建密钥环、并生成Monitor密钥
[root@ceph-1 ~]# ceph-authtool --create-keyring /tmp/ceph.mon.keyring --gen-key -n mon. --cap mon 'allow *'
creating /tmp/ceph.mon.keyring
2、生成管理员密钥环,生成 client.admin 用户并加入密钥环
[root@ceph-1 ~]# ceph-authtool --create-keyring /etc/ceph/ceph.client.admin.keyring --gen-key -n client.admin --set-uid=0 --cap mon 'allow *' --cap osd 'allow *' --cap mds 'allow *' --cap mgr 'allow *'
creating /etc/ceph/ceph.client.admin.keyring
3、把 client.admin 密钥加入 ceph.mon.keyring (3台机器一样)
[root@ceph-1 ~]# ceph-authtool /tmp/ceph.mon.keyring --import-keyring /etc/ceph/ceph.client.admin.keyring
importing contents of /etc/ceph/ceph.client.admin.keyring into /tmp/ceph.mon.keyring
4、用规划好的主机名、对应 IP 地址、和 FSID 生成一个Monitor Map,并保存为 /tmp/monmap
这里的--fsid需要跟ceph.conf里面的fsid保持一致
[root@ceph-1 ~]# monmaptool --create --add `hostname` `hostname -i` --fsid c165f9d0-88df-48a7-8cc5-11da82f99c93 /tmp/monmap --clobber
monmaptool: monmap file /tmp/monmap
monmaptool: set fsid to c165f9d0-88df-48a7-8cc5-11da82f99c93
monmaptool: writing epoch 0 to /tmp/monmap (1 monitors)
5、在Monitor主机上分别创建数据目录
[root@ceph-1 ~]# rm -rf /var/lib/ceph/mon/ceph-`hostname`/
[root@ceph-1 ~]# mkdir /var/lib/ceph/mon/ceph-`hostname`/
[root@ceph-1 ~]# chown ceph:ceph -R /var/lib/ceph/mon/ceph-`hostname`/
[root@ceph-1 ~]# chown -R ceph:ceph /var/lib/ceph/
[root@ceph-1 ~]# chown ceph:ceph /tmp/monmap
[root@ceph-1 ~]# chown ceph:ceph /tmp/ceph.mon.keyring
6、用Monitor Map和密钥环组装守护进程所需的初始数据
[root@ceph-1 ~]# sudo -u ceph ceph-mon --mkfs -i `hostname` --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring
7、建一个空文件 done ,表示监视器已创建、可以启动了
[root@ceph-1 ~]# touch /var/lib/ceph/mon/ceph-`hostname`/done
8、启动Monitor
[root@ceph-1 ~]# cp /usr/lib/systemd/system/[email protected] /usr/lib/systemd/system/ceph-mon@`hostname`.service
[root@ceph-1 ~]# sudo systemctl start ceph-mon@`hostname`
[root@ceph-1 ~]# sudo systemctl enable ceph-mon@`hostname`
Created symlink from /etc/systemd/system/ceph-mon.target.wants/[email protected] to /usr/lib/systemd/system/[email protected].
9、确认下集群在运行
[root@ceph-1 ceph]# ceph -s
cluster:
id: c165f9d0-88df-48a7-8cc5-11da82f99c93
health: HEALTH_OK
services:
mon: 1 daemons, quorum ceph-1
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0B
usage: 0B used, 0B / 0B avail
pgs:
从mon节点部署 (192.168.56.102 & 192.168.56.103)
在另外两台机器ceph-2,ceph-3上,分别ssh登录上去。
创建启动脚本
新建启动脚本文件start_repo_mon.sh
vim start_repo_mon.sh
host_name=`hostname`
sudo ceph mon getmap -o /tmp/monmap
sudo rm -rf /var/lib/ceph/mon/ceph-$host_name
sudo ceph-mon -i $host_name --mkfs --monmap /tmp/monmap
sudo chown -R ceph:ceph /var/lib/ceph/mon/ceph-$host_name/
#nohup ceph-mon -f --cluster ceph --id $host_name --setuser ceph --setgroup ceph &
#ceph-mon -f --cluster ceph --id $host_name &
sudo cp /usr/lib/systemd/system/[email protected] /usr/lib/systemd/system/ceph-mon@$host_name.service
sudo systemctl start ceph-mon@$host_name
sudo systemctl enable ceph-mon@$host_name
启动mon进程
- ceph-2机器192.168.56.102
[root@ceph-2 ceph]# sh prepare_env.sh
groupadd:“ceph”组已存在
useradd:用户“ceph”已存在
[root@ceph-2 ceph]# sh start_repo_mon.sh
got monmap epoch 1
Created symlink from /etc/systemd/system/ceph-mon.target.wants/[email protected] to /usr/lib/systemd/system/[email protected].
[root@ceph-2 ceph]# ps -ef | grep ceph
ceph 11852 1 0 20:47 ? 00:00:00 /usr/bin/ceph-mon -f --cluster ceph --id ceph-2 --setuser ceph --setgroup ceph
root 11908 11645 0 20:47 pts/0 00:00:00 grep --color=auto ceph
[root@ceph-2 ceph]# ceph -s
id: c165f9d0-88df-48a7-8cc5-11da82f99c93
health: HEALTH_OK
services:
mon: 2 daemons, quorum ceph-1,ceph-2
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0B
usage: 0B used, 0B / 0B avail
pgs:
- ceph-3机器192.168.56.103
[root@ceph-3 ceph]# sh prepare_env.sh
groupadd:“ceph”组已存在
useradd:用户“ceph”已存在
[root@ceph-3 ceph]# sh start_repo_mon.sh
got monmap epoch 2
Created symlink from /etc/systemd/system/ceph-mon.target.wants/[email protected] to /usr/lib/systemd/system/[email protected].
[root@ceph-3 ceph]# ps -ef | grep ceph
ceph 11818 1 1 20:51 ? 00:00:00 /usr/bin/ceph-mon -f --cluster ceph --id ceph-3 --setuser ceph --setgroup ceph
root 11874 11081 0 20:51 pts/0 00:00:00 grep --color=auto ceph
[root@ceph-3 ceph]# ceph -s
cluster:
id: c165f9d0-88df-48a7-8cc5-11da82f99c93
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-1,ceph-2,ceph-3
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0B
usage: 0B used, 0B / 0B avail
pgs:
至此可以看到ceph mon集群搭建完毕。
手动搭建ceph-mgr
首先在ceph-1机器上创建并启动ceph-mgr进程。
创建 MGR 监控用户
[root@ceph-1 ceph]# ceph auth get-or-create mgr.`hostname` mon 'allow *' osd 'allow *' mds 'allow *'
[mgr.ceph-1]
key = AQCvovZbpUHTDBAA+/RoCVv+GTBc7lb96rOXRg==
需要将之前创建的用户密码存放至对应位置
[root@ceph-1 ceph]# mkdir /var/lib/ceph/mgr/ceph-`hostname`
[root@ceph-1 ceph]# ceph auth get mgr.`hostname` -o /var/lib/ceph/mgr/ceph-`hostname`/keyring
exported keyring for mgr.ceph-1
启动mgr
[root@ceph-1 ceph]# cp /usr/lib/systemd/system/[email protected] /usr/lib/systemd/system/ceph-mgr@`hostname`.service
[root@ceph-1 ceph]# systemctl start ceph-mgr@`hostname`
[root@ceph-1 ceph]# systemctl enable ceph-mgr@`hostname`
Created symlink from /etc/systemd/system/ceph-mgr.target.wants/[email protected] to /usr/lib/systemd/system/[email protected].
验证是否成功
[root@ceph-1 ceph]# systemctl status ceph-mgr@`hostname`
● [email protected] - Ceph cluster manager daemon
Loaded: loaded (/usr/lib/systemd/system/[email protected]; enabled; vendor preset: disabled)
Active: active (running) since 四 2018-11-22 07:38:49 EST; 14s ago
Main PID: 2050 (ceph-mgr)
CGroup: /system.slice/system-ceph\x2dmgr.slice/[email protected]
└─2050 /usr/bin/ceph-mgr -f --cluster ceph --id ceph-1 --setuser ceph --setgroup ceph
11月 22 07:38:49 ceph-1 systemd[1]: Started Ceph cluster manager daemon.
11月 22 07:38:49 ceph-1 systemd[1]: Starting Ceph cluster manager daemon...
或者:
[root@ceph-1 ceph]# ps -ef | grep ceph-mgr
ceph 2050 1 1 07:38 ? 00:00:00 /usr/bin/ceph-mgr -f --cluster ceph --id ceph-1 --setuser ceph --setgroup ceph
root 2102 1249 0 07:39 pts/0 00:00:00 grep --color=auto ceph-mgr
说明mgr进程正常启动。
监控状态
[root@ceph-1 ceph]# ceph -s
cluster:
id: c165f9d0-88df-48a7-8cc5-11da82f99c93
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-1,ceph-2,ceph-3
mgr: ceph-1(active), standbys: admin
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0B
usage: 0B used, 0B / 0B avail
pgs:
当 mgr 服务被激活之后, service 中 mgr 会显示 mgr-$name(active)
data 部分信息将变得可用
脚本操作
在ceph-2,ceph-3机器上,创建脚本start_mgr.sh,写入以下内容:
[root@ceph-2 ceph]# vim start_mgr.sh
host_name=`hostname`
sudo ceph auth get-or-create mgr.$host_name mon 'allow *' osd 'allow *' mds 'allow *'
sudo rm -rf /var/lib/ceph/mgr/ceph-$host_name
sudo mkdir /var/lib/ceph/mgr/ceph-$host_name
sudo ceph auth get mgr.$host_name -o /var/lib/ceph/mgr/ceph-$host_name/keyring
sudo cp /usr/lib/systemd/system/[email protected] /usr/lib/systemd/system/ceph-mgr@$host_name.service
sudo systemctl start ceph-mgr@$host_name
sudo systemctl enable ceph-mgr@$host_name
执行脚本:
[root@ceph-2 ceph]# sh start_mgr.sh
[mgr.ceph-2]
key = AQCTpfZbNLmpFxAACe1gMNUM4vqKMfNdUGbY/A==
exported keyring for mgr.ceph-2
Created symlink from /etc/systemd/system/ceph-mgr.target.wants/[email protected] to /usr/lib/systemd/system/[email protected].
查看进程状态:
[root@ceph-2 ceph]# ps -ef | grep ceph-mgr
ceph 12101 1 0 07:48 ? 00:00:00 /usr/bin/ceph-mgr -f --cluster ceph --id ceph-2 --setuser ceph --setgroup ceph
root 12173 11645 0 07:50 pts/0 00:00:00 grep --color=auto ceph-mgr
[root@ceph-2 ceph]# systemctl status ceph-mgr*
● [email protected] - Ceph cluster manager daemon
Loaded: loaded (/usr/lib/systemd/system/[email protected]; enabled; vendor preset: disabled)
Active: active (running) since 四 2018-11-22 07:48:19 EST; 2min 33s ago
Main PID: 12101 (ceph-mgr)
CGroup: /system.slice/system-ceph\x2dmgr.slice/[email protected]
└─12101 /usr/bin/ceph-mgr -f --cluster ceph --id ceph-2 --setuser ceph --setgroup ceph
11月 22 07:48:19 ceph-2 systemd[1]: Started Ceph cluster manager daemon.
11月 22 07:48:19 ceph-2 systemd[1]: Starting Ceph cluster manager daemon...
[root@ceph-2 ceph]# ceph -s
cluster:
id: c165f9d0-88df-48a7-8cc5-11da82f99c93
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-1,ceph-2,ceph-3
mgr: ceph-1(active), standbys: admin, ceph-2
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0B
usage: 0B used, 0B / 0B avail
pgs:
可以看到在ceph-2机器上,ceph-mgr进程正常启动。
最后再ceph-3上进行同样的操作。
所有mgr进程创建完成之后,集群的状态如下:
[root@ceph-3 ceph]# ceph -s
cluster:
id: c165f9d0-88df-48a7-8cc5-11da82f99c93
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-1,ceph-2,ceph-3
mgr: ceph-1(active), standbys: admin, ceph-2, ceph-3
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0B
usage: 0B used, 0B / 0B avail
pgs:
- health是处于OK状态
- 3个mon daemons
- mgr进程:ceph-1是active状态,剩下的ceph-2,ceph-3处于standby
手动搭建osd集群
磁盘分区
每个osd对应一块磁盘,是ceph集群存储数据的物理单位,在搭建osd集群之前,先要对三台机器的磁盘进行处理,这里每台机器都是相同的操作,这里只演示ceph-1上的操作:
- 查看磁盘分布情况
[root@ceph-1 ceph]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 100G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 99G 0 part
├─centos-root 253:0 0 50G 0 lvm /
├─centos-swap 253:1 0 2G 0 lvm [SWAP]
└─centos-home 253:2 0 47G 0 lvm /home
sdb 8:16 0 2T 0 disk
sdc 8:32 0 2T 0 disk
sdd 8:48 0 2T 0 disk
sde 8:64 0 600G 0 disk
sr0 11:0 1 1024M 0 rom
这里我们可以看到有三块2T的磁盘:sdb,sdc,sdd,用来部署osd;一块600G的磁盘用作每个osd的journal分区。
- sde进行分区:
[root@ceph-1 ceph]# fdisk /dev/sde
欢迎使用 fdisk (util-linux 2.23.2)。
更改将停留在内存中,直到您决定将更改写入磁盘。
使用写入命令前请三思。
Device does not contain a recognized partition table
使用磁盘标识符 0x986f9840 创建新的 DOS 磁盘标签。
命令(输入 m 获取帮助):g
Building a new GPT disklabel (GUID: E7350C3E-586A-424E-ABAB-73860654C2C8)
命令(输入 m 获取帮助):n
分区号 (1-128,默认 1):
第一个扇区 (2048-1258279965,默认 2048):
Last sector, +sectors or +size{K,M,G,T,P} (2048-1258279965,默认 1258279965):+200G
已创建分区 1
命令(输入 m 获取帮助):n
分区号 (2-128,默认 2):
第一个扇区 (419432448-1258279965,默认 419432448):
Last sector, +sectors or +size{K,M,G,T,P} (419432448-1258279965,默认 1258279965):+200G
已创建分区 2
命令(输入 m 获取帮助):n
分区号 (3-128,默认 3):
第一个扇区 (838862848-1258279965,默认 838862848):
Last sector, +sectors or +size{K,M,G,T,P} (838862848-1258279965,默认 1258279965):
已创建分区 3
命令(输入 m 获取帮助):w
The partition table has been altered!
Calling ioctl() to re-read partition table.
正在同步磁盘。
sde磁盘分区好之后,如下图所示:
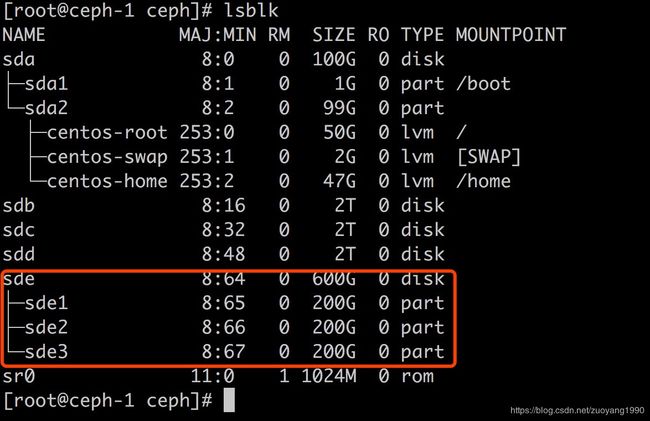
- 创建xfs文件系统
分别对磁盘sdb,sdc,sdd,sde1,sde2,sde3进行如下操作:
[root@ceph-1 ceph]# mkfs.xfs /dev/sdb # 之后将sdb替换为sdc,sdd,sde1,sde2,sde3
meta-data=/dev/sdb isize=512 agcount=4, agsize=134211328 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=536845310, imaxpct=5
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=262131, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
对这几个磁盘操作完之后,查看每个磁盘的uuid
[root@ceph-1 ceph]# blkid
/dev/sda1: UUID="b66ddda6-8a4c-48d8-bb8a-9a3183094c5d" TYPE="xfs"
/dev/sda2: UUID="Iylyc4-LvIV-TnAg-FZK6-xz2D-3gaY-hx17eb" TYPE="LVM2_member"
/dev/sdb: UUID="104c6fd4-58e7-468f-a003-266d9a7fb9ba" TYPE="xfs"
/dev/sdc: UUID="1a06d53d-0f76-4931-9add-fe3494510edc" TYPE="xfs"
/dev/sdd: UUID="30a5527d-e7b6-4c13-b735-c9e086775d51" TYPE="xfs"
/dev/sde1: UUID="58793fce-298c-417c-85dc-b0d913f8cd63" TYPE="xfs" PARTUUID="ca1a9c40-e020-4bf8-a17b-5716b3e1d453"
/dev/sde2: UUID="1c7ef6a8-58a6-47c0-9d2d-ff086a3d81f7" TYPE="xfs" PARTUUID="c458e242-716d-42f7-9a2e-5f21c291987a"
/dev/sde3: UUID="0581b33a-321d-42af-9b5f-272a775fccc1" TYPE="xfs" PARTUUID="651f90d2-9697-4474-b3d8-a0e980b125a4"
/dev/mapper/centos-root: UUID="0fc63cb7-c2e6-46e8-8db9-2c31fdd20310" TYPE="xfs"
/dev/mapper/centos-swap: UUID="a8605f7e-5049-4cd4-bd6d-805c98543f38" TYPE="swap"
/dev/mapper/centos-home: UUID="7fc267af-b141-4140-afb9-388453097422" TYPE="xfs"
可以看到这些磁盘都有独立的UUID,且TYPE都为“xfs”。说明创建成功。
启动osd进程
-
创建osd id
添加一个新osd,
id可以省略,ceph会自动使用最小可用整数,第一个osd从0开始[root@ceph-1 ceph]# ceph osd create 0 -
初始化osd目录
创建osd.0目录,目录名格式
{cluster-name}-{id}#mkdir /var/lib/ceph/osd/{cluster-name}-{id} [root@ceph-1 ceph]# mkdir /var/lib/ceph/osd/ceph-0挂载osd.0的数据盘/dev/sdb
[root@ceph-1 ceph]# mount /dev/sdb /var/lib/ceph/osd/ceph-0查看挂载结果:
[root@ceph-1 ceph]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 100G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 99G 0 part ├─centos-root 253:0 0 50G 0 lvm / ├─centos-swap 253:1 0 2G 0 lvm [SWAP] └─centos-home 253:2 0 47G 0 lvm /home sdb 8:16 0 2T 0 disk /var/lib/ceph/osd/ceph-0 sdc 8:32 0 2T 0 disk sdd 8:48 0 2T 0 disk sde 8:64 0 600G 0 disk ├─sde1 8:65 0 200G 0 part ├─sde2 8:66 0 200G 0 part └─sde3 8:67 0 200G 0 part sr0 11:0 1 1024M 0 rom初始化osd数据目录
# sudo ceph-osd -i {id} --mkfs --mkkey [root@ceph-1 ceph]# ceph-osd -i 0 --mkfs --mkkey 2018-11-22 08:26:54.255294 7fb2734e6d80 -1 auth: error reading file: /var/lib/ceph/osd/ceph-0/keyring: can't open /var/lib/ceph/osd/ceph-0/keyring: (2) No such file or directory 2018-11-22 08:26:54.257686 7fb2734e6d80 -1 created new key in keyring /var/lib/ceph/osd/ceph-0/keyring 2018-11-22 08:26:54.306488 7fb2734e6d80 -1 journal FileJournal::_open: disabling aio for non-block journal. Use journal_force_aio to force use of aio anyway 2018-11-22 08:26:54.341905 7fb2734e6d80 -1 journal FileJournal::_open: disabling aio for non-block journal. Use journal_force_aio to force use of aio anyway 2018-11-22 08:26:54.342312 7fb2734e6d80 -1 journal do_read_entry(4096): bad header magic 2018-11-22 08:26:54.342327 7fb2734e6d80 -1 journal do_read_entry(4096): bad header magic 2018-11-22 08:26:54.342704 7fb2734e6d80 -1 read_settings error reading settings: (2) No such file or directory 2018-11-22 08:26:54.395459 7fb2734e6d80 -1 created object store /var/lib/ceph/osd/ceph-0 for osd.0 fsid c165f9d0-88df-48a7-8cc5-11da82f99c93 -
创建journal
生成journal分区,一般选ssd盘作为journal分区,这里使用/dev/sde1分区作为osd.0的journal。
#查看分区对应的partuuid, 找出/dev/sde1对应的partuuid [root@ceph-1 ceph]# rm -f /var/lib/ceph/osd/ceph-0/journal [root@ceph-1 ceph]# blkid /dev/sda1: UUID="b66ddda6-8a4c-48d8-bb8a-9a3183094c5d" TYPE="xfs" /dev/sda2: UUID="Iylyc4-LvIV-TnAg-FZK6-xz2D-3gaY-hx17eb" TYPE="LVM2_member" /dev/sdb: UUID="104c6fd4-58e7-468f-a003-266d9a7fb9ba" TYPE="xfs" /dev/sdc: UUID="1a06d53d-0f76-4931-9add-fe3494510edc" TYPE="xfs" /dev/sdd: UUID="30a5527d-e7b6-4c13-b735-c9e086775d51" TYPE="xfs" /dev/sde1: UUID="58793fce-298c-417c-85dc-b0d913f8cd63" TYPE="xfs" PARTUUID="ca1a9c40-e020-4bf8-a17b-5716b3e1d453" /dev/sde2: UUID="1c7ef6a8-58a6-47c0-9d2d-ff086a3d81f7" TYPE="xfs" PARTUUID="c458e242-716d-42f7-9a2e-5f21c291987a" /dev/sde3: UUID="0581b33a-321d-42af-9b5f-272a775fccc1" TYPE="xfs" PARTUUID="651f90d2-9697-4474-b3d8-a0e980b125a4" /dev/mapper/centos-root: UUID="0fc63cb7-c2e6-46e8-8db9-2c31fdd20310" TYPE="xfs" /dev/mapper/centos-swap: UUID="a8605f7e-5049-4cd4-bd6d-805c98543f38" TYPE="swap" /dev/mapper/centos-home: UUID="7fc267af-b141-4140-afb9-388453097422" TYPE="xfs" [root@ceph-1 ceph]# ln -s /dev/disk/by-partuuid/ca1a9c40-e020-4bf8-a17b-5716b3e1d453 /var/lib/ceph/osd/ceph-0/journal [root@ceph-1 ceph]# chown ceph:ceph -R /var/lib/ceph/osd/ceph-0 [root@ceph-1 ceph]# chown ceph:ceph /var/lib/ceph/osd/ceph-0/journal [root@ceph-1 ceph]# ceph-osd --mkjournal -i 0 2018-11-22 08:31:06.832760 7f97505afd80 -1 journal read_header error decoding journal header [root@ceph-1 ceph]# ceph-osd --mkjournal -i 0 [root@ceph-1 ceph]# chown ceph:ceph /var/lib/ceph/osd/ceph-0/journal -
注册osd.{id},id为osd编号,默认从0开始
# sudo ceph auth add osd.{id} osd 'allow *' mon 'allow profile osd' -i /var/lib/ceph/osd/ceph-{id}/keyring [root@ceph-1 ceph]# ceph auth add osd.0 osd 'allow *' mon 'allow profile osd' -i /var/lib/ceph/osd/ceph-0/keyring added key for osd.0 -
加入crush map
这是ceph-1上新创建的第一个osd,CRUSH map中还没有ceph-1节点,因此首先要把ceph-1节点加入CRUSH map,同理,ceph-2/ceph-3节点也需要加入CRUSH map
[root@ceph-1 ceph]# ceph osd crush add-bucket `hostname` host added bucket ceph-1 type host to crush map然后把三个节点移动到默认的root
default下面[root@ceph-1 ceph]# ceph osd crush move `hostname` root=default moved item id -2 name 'ceph-1' to location {root=default} in crush map添加osd.0到CRUSH map中的ceph-1节点下面,加入后,osd.0就能够接收数据
#ceph osd crush add osd.{id} 0.4 root=sata rack=sata-rack01 host=sata-node5 #0.4为此osd在CRUSH map中的权重值,它表示数据落在此osd上的比重,是一个相对值,一般按照1T磁盘比重值为1来计算,这里的osd数据盘1.7,所以值为1.7 [root@ceph-1 ceph]# ceph osd crush add osd.0 2.0 root=default host=`hostname` add item id 0 name 'osd.0' weight 2 at location {host=ceph-1,root=default} to crush map此时osd.0状态是
down且in,in表示此osd位于CRUSH map,已经准备好接受数据,down表示osd进程运行异常,因为我们还没有启动osd.0进程 -
启动ceph-osd进程
需要向systemctl传递osd的
id以启动指定的osd进程,如下,我们准备启动osd.0进程[root@ceph-1 ceph]# cp /usr/lib/systemd/system/[email protected] /usr/lib/systemd/system/[email protected] [root@ceph-1 ceph]# systemctl start ceph-osd@0 [root@ceph-1 ceph]# systemctl enable ceph-osd@0 Created symlink from /etc/systemd/system/ceph-osd.target.wants/[email protected] to /usr/lib/systemd/system/[email protected].上面就是添加osd.0的步骤,然后可以接着在其他
hostname节点上添加osd.{1,2},添加了这3个osd后,可以查看集群状态 ceph -s。 -
验证osd进程是否成功启动
[root@ceph-1 ceph]# ps -ef | grep ceph-osd ceph 2593 1 0 08:55 ? 00:00:00 /usr/bin/ceph-osd -f --cluster ceph --id 0 --setuser ceph --setgroup ceph root 2697 1249 0 08:55 pts/0 00:00:00 grep --color=auto ceph-osd说明osd.0已经启动成功
查看集群状态
[root@ceph-1 ceph]# ceph -s
cluster:
id: c165f9d0-88df-48a7-8cc5-11da82f99c93
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-1,ceph-2,ceph-3
mgr: ceph-1(active), standbys: admin, ceph-2, ceph-3
osd: 1 osds: 1 up, 1 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0B
usage: 107MiB used, 2.00TiB / 2.00TiB avail
pgs:
osd已经有一个处于up跟in状态了。
按照上面的步骤重复操作,添加剩下的osd。
也可以执行如下脚本进行启动osd
[root@ceph-1 ceph]# vim start_osd.sh
#执行脚本时需要输入三个参数,顺序依次为:osd.num, osd数据存储分区,osd journal存储分区
#例如:sudo sh start_osd.sh 0 /dev/sdc2 /dev/sdc1
#获取参数
host_name=`hostname`
id=$1
data_disk=$2
journal_disk=$3
#创建osd data
ceph osd create $id
sudo rm -rf /var/lib/ceph/osd/ceph-$id
sudo mkdir /var/lib/ceph/osd/ceph-$id
#sudo mkfs.xfs $data_disk -f
sudo mount $data_disk /var/lib/ceph/osd/ceph-$id
sudo ceph-osd -i $id --mkfs --mkkey
#创建 journal
#sudo mkfs.xfs $journal_disk -f
uuid=`sudo blkid | grep $journal_disk | awk -F\" '{print $6}'`
sudo rm -f /var/lib/ceph/osd/ceph-$id/journal
sudo ln -s /dev/disk/by-partuuid/$uuid /var/lib/ceph/osd/ceph-$id/journal
sudo chown ceph:ceph -R /var/lib/ceph/osd/ceph-$id
sudo chown ceph:ceph /var/lib/ceph/osd/ceph-$id/journal
#初始化新的journal
sudo ceph-osd --mkjournal -i $id
sudo chown ceph:ceph /var/lib/ceph/osd/ceph-$id/journal
# 添加osd到crushmap
sudo ceph auth add osd.$id osd 'allow *' mon 'allow profile osd' -i /var/lib/ceph/osd/ceph-$id/keyring
sudo ceph osd crush add-bucket $host_name host
sudo ceph osd crush move $host_name root=default
sudo ceph osd crush add osd.$id 1.7 root=default host=$host_name
# 启动osd
sudo cp /usr/lib/systemd/system/[email protected] /usr/lib/systemd/system/ceph-osd@$id.service
sudo systemctl start ceph-osd@$id
sudo systemctl enable ceph-osd@$id
执行实例:
# 第一个参数:osd的id, 第二个参数: osd数据分区 第三个参数: osd的journal
[root@ceph-1 ceph]# sh start_osd.sh 1 /dev/sdc /dev/sde2
1
2018-11-22 09:31:18.144721 7fc56f8b5d80 -1 auth: error reading file: /var/lib/ceph/osd/ceph-1/keyring: can't open /var/lib/ceph/osd/ceph-1/keyring: (2) No such file or directory
2018-11-22 09:31:18.147361 7fc56f8b5d80 -1 created new key in keyring /var/lib/ceph/osd/ceph-1/keyring
2018-11-22 09:31:18.184083 7fc56f8b5d80 -1 journal FileJournal::_open: disabling aio for non-block journal. Use journal_force_aio to force use of aio anyway
2018-11-22 09:31:18.208952 7fc56f8b5d80 -1 journal FileJournal::_open: disabling aio for non-block journal. Use journal_force_aio to force use of aio anyway
2018-11-22 09:31:18.209302 7fc56f8b5d80 -1 journal do_read_entry(4096): bad header magic
2018-11-22 09:31:18.209321 7fc56f8b5d80 -1 journal do_read_entry(4096): bad header magic
2018-11-22 09:31:18.209700 7fc56f8b5d80 -1 read_settings error reading settings: (2) No such file or directory
2018-11-22 09:31:18.246674 7fc56f8b5d80 -1 created object store /var/lib/ceph/osd/ceph-1 for osd.1 fsid c165f9d0-88df-48a7-8cc5-11da82f99c93
2018-11-22 09:31:18.480406 7fce4eeb4d80 -1 journal read_header error decoding journal header
added key for osd.1
bucket 'ceph-1' already exists
no need to move item id -2 name 'ceph-1' to location {root=default} in crush map
add item id 1 name 'osd.1' weight 2 at location {host=ceph-1,root=default} to crush map
Created symlink from /etc/systemd/system/ceph-osd.target.wants/[email protected] to /usr/lib/systemd/system/[email protected].
按照上面的方法添加所有的osd之后,可以得到如下的集群:
[root@ceph-3 ceph]# ceph -s
cluster:
id: c165f9d0-88df-48a7-8cc5-11da82f99c93
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-1,ceph-2,ceph-3
mgr: ceph-1(active), standbys: admin, ceph-2, ceph-3
osd: 9 osds: 9 up, 9 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0B
usage: 858MiB used, 16.0TiB / 16.0TiB avail
pgs:
手动搭建MDS (仅cephfs使用)
- 创建目录:
[root@ceph-1 ceph]# mkdir /var/lib/ceph/mds/ceph-`hostname`
[root@ceph-1 ceph]# chown ceph:ceph -R /var/lib/ceph/mds/ceph-`hostname`
- 在ceph.conf中添加如下信息:
[mds.ceph-1]
host = ceph-1
[mds.ceph-2]
host = ceph-2
[mds.ceph-3]
host = ceph-3
-
重启ceph-mon
[root@ceph-1 ceph]# systemctl restart ceph-mon@`hostname` -
启动mds
[root@ceph-1 ceph]# cp /usr/lib/systemd/system/[email protected] /usr/lib/systemd/system/ceph-mds@`hostname`.service
[root@ceph-1 ceph]# systemctl start ceph-mds@`hostname`
[root@ceph-1 ceph]# systemctl enable ceph-mds@`hostname`
Created symlink from /etc/systemd/system/ceph-mds.target.wants/[email protected] to /usr/lib/systemd/system/[email protected].
- 查看mds状态
[root@ceph-1 ceph]# ceph mds stat
, 1 up:standby
在ceph-2,ceph-3上执行以上相同操作即可。
最终mds的状态为:
[root@ceph-3 ceph]# ceph mds stat
, 3 up:standby
Ceph集群搭建完成
最终的ceph集群状态如下:
[root@ceph-3 ceph]# ceph -s
cluster:
id: c165f9d0-88df-48a7-8cc5-11da82f99c93
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-1,ceph-2,ceph-3
mgr: ceph-1(active), standbys: admin, ceph-2, ceph-3
osd: 9 osds: 9 up, 9 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0B
usage: 965MiB used, 18.0TiB / 18.0TiB avail
pgs:
至此ceph集群搭建完成。