scrapy-redis分布式爬虫如何在start_urls中添加参数
scrapy-redis分布式爬虫如何在start_urls中添加参数
1.背景介绍
- 有这样一个需求,需要爬取A,B,C,D四个链接下的数据,但是每个链接下要爬取的数据量不同:
url链接: 指定爬取的商品数
A: 10
B: 20
C: 5
D: 32- 首先通过下面的文章了解一下scrapy-redis分布式爬虫的基本框架。
- scrapy-redis分布式爬虫的搭建过程(理论篇):https://blog.csdn.net/zwq912318834/article/details/78854571
- 在非分布式的scrapy爬虫中,这个参数非常好带入进去,只需要重写spider中的start_requests方法即可。
- 但是在scrapy-redis分布式爬虫中,爬虫是依赖spider中设置的redis_key启动的,比如我们在spider中指定:
redis_key = 'amazonCategory:start_urls'- 然后,只要往 amazonCategory:start_urls 中填入一些url,爬虫就会启动,并取出这些链接进行爬取。
- 但是,scrapy-redis分布式爬虫,在start_urls的部分,只接受url,所以没有办法和 指定爬取的商品数 这个参数对应起来。
- 当然,可以在默认处理start_urls的方法parse中,用url找到对应的 指定爬取的商品数 参数。但是,这里又存在一个很大的问题:那就是scrapy-redis框架,在start_urls的处理,全都是默认参数,也是默认支持重定向的,这里面的A,B,C,D四个链接,在爬取过程中,随时都可能发生网页重定向,跳转到其他页面,这时候parse函数中取出来的response.url就不是原来的A,B,C,D这几个链接了,而是跳转后的链接,也就无法和原来的 指定爬取的商品数 这个参数对应起来了。
2. 环境
- 系统:win7
- scrapy 1.4.0
- scrapy-redis 0.6.8
- redis 3.0.5
- python 3.6.1
3. 分析scrapy-redis分布式爬虫的起步过程
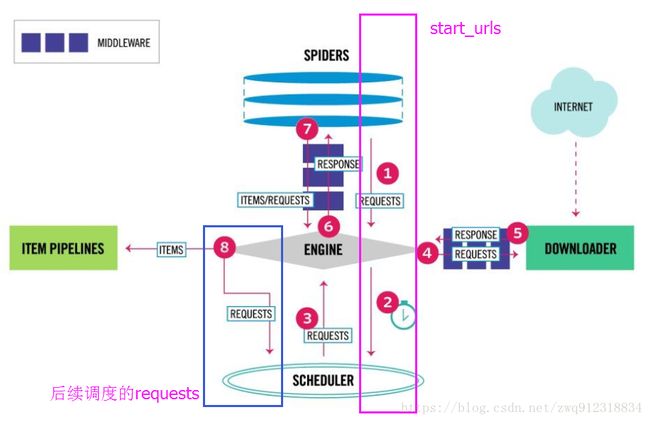
- 上面是scrapy最新的架构图。而scrapy-redis分布式爬虫是将scrapy和redis简单的粘在一起。所以只需要分析这个框架。
整个其实过程可以总结为:
- 第一:爬虫指定好redis_key,启动,等待起始url。
- 第二:运行脚本,往redis_key中填充start_urls
- 第三:爬虫发现redis_key中有了start_urls,开始取出这些url
- 第四:爬虫按照默认参数,将这些url打包生成requests
- 第五:将这些requests送往scheduler调度模块,进入等待队列,等待调度。
- 第六:scheduler模块开始调度这些requests,出队,发往爬虫引擎。
- 第七:爬虫引擎将这些requests送到下载中间件(多个,例如加header,代理,自定义等等)进行处理。
- 第八:处理完之后,送往Downloader模块进行下载。
- …………后面和本次主题无关,暂时就不考虑了。
从上面整个过程来看,只能从一个地方入手,就是 “ 第四:爬虫按照默认参数,将这些url打包生成requests ”,我们需要在将url生成requests这个过程中,增加一些参数。
4. 爬虫起步过程的源码分析
- 第一步:我们的爬虫是继承自类RedisSpider:
# 文件mySpider.py
class MySpider(RedisSpider):
# 文件 E:\Miniconda\Lib\site-packages\scrapy_redis\spiders.py
# RedisSpider 继承自 RedisMixin 和 Spider
class RedisSpider(RedisMixin, Spider):- 第二步 :分析类 RedisMixin
# 文件 E:\Miniconda\Lib\site-packages\scrapy_redis\spiders.py
class RedisMixin(object):
"""Mixin class to implement reading urls from a redis queue."""
redis_key = None
redis_batch_size = None
redis_encoding = None
# Redis client placeholder.
server = None
# 注解: scrapy-redis爬虫启动的第一步
def start_requests(self):
"""Returns a batch of start requests from redis."""
print(f"######1 spiders.py RedisMixin: start_requests")
return self.next_requests()
def setup_redis(self, crawler=None):
"""Setup redis connection and idle signal.
This should be called after the spider has set its crawler object.
"""
if self.server is not None:
return
if crawler is None:
# We allow optional crawler argument to keep backwards
# compatibility.
# XXX: Raise a deprecation warning.
crawler = getattr(self, 'crawler', None)
if crawler is None:
raise ValueError("crawler is required")
settings = crawler.settings
if self.redis_key is None:
self.redis_key = settings.get(
'REDIS_START_URLS_KEY', defaults.START_URLS_KEY,
)
self.redis_key = self.redis_key % {'name': self.name}
if not self.redis_key.strip():
raise ValueError("redis_key must not be empty")
if self.redis_batch_size is None:
# TODO: Deprecate this setting (REDIS_START_URLS_BATCH_SIZE).
self.redis_batch_size = settings.getint(
'REDIS_START_URLS_BATCH_SIZE',
settings.getint('CONCURRENT_REQUESTS'),
)
try:
self.redis_batch_size = int(self.redis_batch_size)
except (TypeError, ValueError):
raise ValueError("redis_batch_size must be an integer")
if self.redis_encoding is None:
self.redis_encoding = settings.get('REDIS_ENCODING', defaults.REDIS_ENCODING)
self.logger.info("Reading start URLs from redis key '%(redis_key)s' "
"(batch size: %(redis_batch_size)s, encoding: %(redis_encoding)s",
self.__dict__)
self.server = connection.from_settings(crawler.settings)
# The idle signal is called when the spider has no requests left,
# that's when we will schedule new requests from redis queue
crawler.signals.connect(self.spider_idle, signal=signals.spider_idle)
# 注解: 从 redis-key中,取出数据,这些数据默认是url,然后用这些url去构造requests
def next_requests(self):
"""Returns a request to be scheduled or none."""
print(f"######2 spiders.py RedisMixin: next_requests")
use_set = self.settings.getbool('REDIS_START_URLS_AS_SET', defaults.START_URLS_AS_SET)
fetch_one = self.server.spop if use_set else self.server.lpop
# XXX: Do we need to use a timeout here?
found = 0
# TODO: Use redis pipeline execution.
# 注解: redis_batch_size 是指我们在setting里面设置的CONCURRENT_REQUESTS, 一次性请求的量
# 这个地方的作用,也是,当数量达到这个值之前,url会进行累计,达到这个数量时,会一次性送去处理
while found < self.redis_batch_size:
# 注解: 从redis_key中读出数据,也就是start_urls
data = fetch_one(self.redis_key)
if not data:
# 注解: redis_key中数据已经全部取完
# Queue empty.
break
# 注解: 将从redis_key中取出的数据(url),制作成request。关键点就在这里了
req = self.make_request_from_data(data)
if req:
# 注解: 将制作好的request,送往调度器
yield req
found += 1
else:
self.logger.debug("Request not made from data: %r", data)
if found:
self.logger.debug("Read %s requests from '%s'", found, self.redis_key)
# 注解: 将从redis_key中取出的数据(url),制作成request。关键点就在这里了
def make_request_from_data(self, data):
"""Returns a Request instance from data coming from Redis.
By default, ``data`` is an encoded URL. You can override this method to
provide your own message decoding.
Parameters
----------
data : bytes
Message from redis.
"""
url = bytes_to_str(data, self.redis_encoding)
# return self.make_requests_from_url(url)
# 注解: 需要在这一步,将make_requests_from_url改写,加入一些指定参数
# 尤其需要注意到的是,这儿的self.make_requests_from_url(url),
# 指的是E:\Miniconda\Lib\site-packages\scrapy\spiders\__init__.py中的方法。
# 这个部分只会影响到start_urls的构造。 像后续的request构造,都是在mySpider.py中完成,在scheduler模块中调度,不会走入这个逻辑
print(f"######3 spiders.py RedisMixin: make_request_from_data, url={url}")
return self.make_requests_from_url_DontRedirect(url)
def schedule_next_requests(self):
"""Schedules a request if available"""
# TODO: While there is capacity, schedule a batch of redis requests.
for req in self.next_requests():
self.crawler.engine.crawl(req, spider=self)
def spider_idle(self):
"""Schedules a request if available, otherwise waits."""
# XXX: Handle a sentinel to close the spider.
self.schedule_next_requests()
raise DontCloseSpider- 第三步 :分析类 Spider
# 文件 E:\Miniconda\Lib\site-packages\scrapy\spiders\__init__.py
class Spider(object_ref):
"""Base class for scrapy spiders. All spiders must inherit from this
class.
"""
name = None
custom_settings = None
# ……
def make_requests_from_url(self, url):
""" This method is deprecated. """
return Request(url, dont_filter=True)
def make_requests_from_url_DontRedirect(self, url):
""" This method is deprecated. """
print(f"######4 __init__.py Spider: make_requests_from_url_DontRedirect, url={url}")
# 注解: 在这一步进行改写,将原始的originalUrl放到meta信息中进行传递。
# 如果想指定不允许重定向,也是在meta信息中,加入:meta={'dont_redirect':True}
# 不过,在这里,推荐的做法,还是允许跳转,但是记录原始链接originalUrl
return Request(url, meta={'originalUrl': url}, dont_filter=True)- 通过运行的Log跟踪爬虫轨迹:
######1 spiders.py RedisMixin: start_requests
###### there is no BloomFilter, used the default redis set to dupefilter. isUseBloomfilter = False
2018-03-27 17:22:52 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-03-27 17:22:52 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6024
request is None, lostGetRequest = 1, time = 2018-03-27 17:22:52.369602
######2 spiders.py RedisMixin: next_requests
######3 spiders.py RedisMixin: make_request_from_data, url=https://www.amazon.com/s/ref=lp_166220011_nr_n_3/134-0288275-8061547?fst=as%3Aoff&rh=n%3A165793011%2Cn%3A%21165795011%2Cn%3A166220011%2Cn%3A1265807011&bbn=166220011&ie=UTF8&qid=1517900306&rnid=166220011
######4 __init__.py Spider: make_requests_from_url_DontRedirect, url=https://www.amazon.com/s/ref=lp_166220011_nr_n_3/134-0288275-8061547?fst=as%3Aoff&rh=n%3A165793011%2Cn%3A%21165795011%2Cn%3A166220011%2Cn%3A1265807011&bbn=166220011&ie=UTF8&qid=1517900306&rnid=166220011
request is None, lostGetRequest = 1, time = 2018-03-27 17:22:52.386602
######3 spiders.py RedisMixin: make_request_from_data, url=https://www.amazon.com/s/ref=lp_166461011_nr_n_1/133-3783987-2841554?fst=as%3Aoff&rh=n%3A165793011%2Cn%3A%21165795011%2Cn%3A166461011%2Cn%3A11350121011&bbn=166461011&ie=UTF8&qid=1517900305&rnid=166461011
######4 __init__.py Spider: make_requests_from_url_DontRedirect, url=https://www.amazon.com/s/ref=lp_166461011_nr_n_1/133-3783987-2841554?fst=as%3Aoff&rh=n%3A165793011%2Cn%3A%21165795011%2Cn%3A166461011%2Cn%3A11350121011&bbn=166461011&ie=UTF8&qid=1517900305&rnid=166461011
request is None, lostGetRequest = 1, time = 2018-03-27 17:22:52.388602
######3 spiders.py RedisMixin: make_request_from_data, url=https://www.amazon.com/s/ref=lp_495236_nr_n_6/143-2389134-7838338?fst=as%3Aoff&rh=n%3A228013%2Cn%3A%21468240%2Cn%3A495224%2Cn%3A495236%2Cn%3A3742221&bbn=495236&ie=UTF8&qid=1517901748&rnid=495236
######4 __init__.py Spider: make_requests_from_url_DontRedirect, url=https://www.amazon.com/s/ref=lp_495236_nr_n_6/143-2389134-7838338?fst=as%3Aoff&rh=n%3A228013%2Cn%3A%21468240%2Cn%3A495224%2Cn%3A495236%2Cn%3A3742221&bbn=495236&ie=UTF8&qid=1517901748&rnid=495236
request is None, lostGetRequest = 1, time = 2018-03-27 17:22:52.390602
######3 spiders.py RedisMixin: make_request_from_data, url=https://www.amazon.com/s/ref=lp_13980701_nr_n_0/133-0601909-3066127?fst=as%3Aoff&rh=n%3A1055398%2Cn%3A%211063498%2Cn%3A1063278%2Cn%3A3734741%2Cn%3A13980701%2Cn%3A3734771&bbn=13980701&ie=UTF8&qid=1517900284&rnid=13980701
######4 __init__.py Spider: make_requests_from_url_DontRedirect, url=https://www.amazon.com/s/ref=lp_13980701_nr_n_0/133-0601909-3066127?fst=as%3Aoff&rh=n%3A1055398%2Cn%3A%211063498%2Cn%3A1063278%2Cn%3A3734741%2Cn%3A13980701%2Cn%3A3734771&bbn=13980701&ie=UTF8&qid=1517900284&rnid=13980701- 打印看下,originalUrl是否有成功传递过来:
# 文件 mySpider.py
# 分析start_urls页面
# 第一个处理函数必须是parse,名字不能换
def parse(self, response):
print(f"parse url = {response.url}, status = {response.status}, meta = {response.meta}")
theCategoryUrl = response.url # 品类的链接
isRedirect = False # 记录是否发生了跳转,默认是记为 无重定向
redirectUrl = "" # 记录跳转后的页面,默认为空
if "originalUrl" in response.meta:
if response.meta["originalUrl"] == response.url: # 说明没有发生页面跳转
isRedirect = False
else:
# 发生了跳转,打上标记, 并更新categoryUrl为original,方便找到categoryInfo的信息,并记录跳转后的页面
isRedirect = True
theCategoryUrl = response.meta["originalUrl"]
redirectUrl = response.url
else:
# 如果后期没有这个机制的话,那就恢复原来的处理机制,啥也不做
pass
# 先判断这个爬虫是否有这个指定品类的基础信息,如果有,就去爬取;如果没有,就不爬
if theCategoryUrl in self.categoryRecordDict:
categoryInfo = self.categoryRecordDict[theCategoryUrl]
else:
print(f"this url doesnt have mainInfo, no need follow.")
return None
print(f"Follow this url = {theCategoryUrl}")parse url = https://www.amazon.com/s/ref=lp_723452011_nr_n_7/134-5490946-1974065?fst=as%3Aoff&rh=n%3A3760901%2Cn%3A%213760931%2Cn%3A723418011%2Cn%3A723452011%2Cn%3A723457011&bbn=723452011&ie=UTF8&qid=1517900276&rnid=723452011, status = 200, meta = {'originalUrl': 'https://www.amazon.com/s/ref=lp_723452011_nr_n_7/134-5490946-1974065?fst=as%3Aoff&rh=n%3A3760901%2Cn%3A%213760931%2Cn%3A723418011%2Cn%3A723452011%2Cn%3A723457011&bbn=723452011&ie=UTF8&qid=1517900276&rnid=723452011', 'download_timeout': 20.0, 'proxy': 'http://proxy.abuyun.com:9020', 'download_slot': 'www.amazon.com', 'download_latency': 3.305999994277954, 'depth': 0}5. 小结
- 其实通过以上的源码分析,发现在start_urls上能做的文章很少,而且需要很慎重,毕竟这是scrapy-redis的源码,其他爬虫项目也会用到。所以在这个上面的改动一定要特别小心,并做好记录和备份。尽量在满足需求的同时,将影响降到最小。