Hadoop之WordCount实战详解
WorldCount可以说是MapReduce中的helloworld了,单词计数主要完成的功能是:统计一系列文本文件中每个单词出现的次数,通过完成这个简单程序让读者摸清 MapReduce 程序的基本结构。 特别是对于每一个阶段的函数执行所产生的键值对。这里对MapReduce过程原理不过多说明。
环境说明
- CentOS 7
- Hadoop 2.7.5
- JDK 1.8
- IDE是IDEA+Gradle,直接创建一个Gradle管理的Java项目即可,然后在build.gradle文件中添加如下依赖:
compile 'org.apache.hadoop:hadoop-common:2.7.5'
compile 'ch.cern.hadoop:hadoop-mapreduce-client-core:2.7.5.0'
compile 'commons-cli:commons-cli:1.2'- hadoop安装路径/usr/local/hadoop,在hadoop目录下建一个input目录,用来存放输入文件,一下是我自己创建的两个文件:
word1.txt
hello hadoop welcome
hello spark world
word2.txt
Spark is good!
Scala is similar with kotlin
编程实战
1.编写Map处理逻辑
首先自定义一个类继承MapReduce框架的Mapper类。Map的输入类型是键值对,键是行号,值就是单词,输出也是键值对,键是一个个单词,值就是其出现的次数,这里的次数值都是1,经过Reduce处理才得到最终次数。
public static class WordMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
//key就是行号,value就是一行字符串
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}2.编写Reduce处理逻辑
Map处理完后,数据经过shuffle节点输入给Reuduce任务,Reduce的输入形式是(key, value-list)形式。
public static class WordReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
3.编写main函数
main函数要设置程序运行时参数(Configuration)以及环境参数(Job),Hadoop都是以作业(job)形式运行用户程序,以下是整个程序代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* Created by charming on 2018/4/4.
*/
public class WordCount {
public static class WordMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class WordReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration(); //程序运行时参数
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2)
{
System.err.println("Usage wordcount " );
System.exit(2);
}
// 删除输出目录
Path outputPath = new Path(otherArgs[1]);
if (outputPath.getFileSystem(conf).exists(outputPath));
{
outputPath.getFileSystem(conf).delete(outputPath, true);
}
Job job = Job.getInstance(conf, "word count"); //设置环境参数
job.setJarByClass(WordCount.class); // 设置整个程序类名
job.setMapperClass(WordMapper.class); //map函数
// job.setCombinerClass(WordReduce.class); //combine的实现和reduce一样
job.setReducerClass(WordReduce.class); //reudce函数
job.setOutputKeyClass(Text.class); //设置输出key类型
job.setOutputValueClass(IntWritable.class); //设置输出value类型
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); // 设置输入文件
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); // 设置输出文件
System.exit(job.waitForCompletion(true)?0:1); // 提交作业
}
} 注意,WordCount.java是直接在main目录下创建,没有包名。不然后面运行时会出异常。
4.编译打包代码
有两种方式
- 在IDEA中使用gradle配置jar包
jar {
baseName 'WordCount'
String appMainClass = 'WordCount'
// from {
// //添加依懒到打包文件
// //configurations.compile.collect { it.isDirectory() ? it : zipTree(it) }
// configurations.runtime.collect{zipTree(it)}
// }
manifest {
attributes 'Main-Class': appMainClass
}
}
- 通过命令行形式打包
jar -cvf WordCount.jar ./WordCount*.class在/usr/local/hadoop下面新建一个job目录,将打包好的jar包放置在此目录下。
5.在MapReduce上运行
hadoop的输入输出都是在hdfs文件系统上的。
首先需要在 HDFS 中创建用户目录,在hadoop目录下执行命令:
./bin/hdfs dfs -mkdir -p /user/hadoop在 HDFS 中创建输入目录,这里使用的是 hadoop 用户,并且已创建相应的用户目录 /user/hadoop ,因此在命令中就可以使用相对路径如 input,其对应的绝对路径就是 /user/hadoop/input:
./bin/hdfs dfs -mkdir input接着将 ./input 中的 txt 文件作为输入文件复制到分布式文件系统中,即将 /usr/local/hadoop/input 复制到分布式文件系统中的 /user/hadoop/input 中。
./bin/hdfs dfs -put ./input/*.txt input复制完成后,可以通过如下命令查看文件列表:
./bin/hdfs dfs -ls input运行 MapReduce 作业
./bin/hadoop jar ./job/WordCount.jar WordCount input output
查看位于 HDFS 中的输出结果:
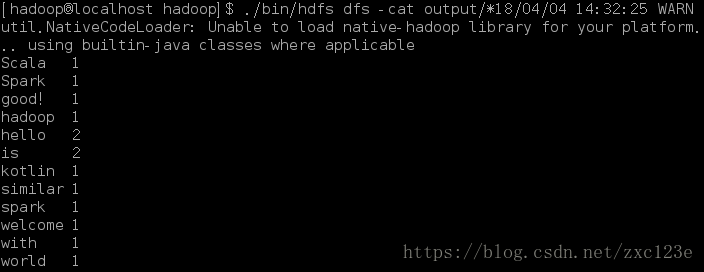
./bin/hdfs dfs -cat output/*我们也可以将运行结果取回到本地:
rm -r ./output # 先删除本地的 output 文件夹(如果存在)
./bin/hdfs dfs -get output ./output # 将 HDFS 上的 output 文件夹拷贝到本机
cat ./output/*Hadoop 运行程序时,输出目录不能存在,否则会提示错误 org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/user/hadoop/output already exists,因此若要再次执行,需要删除 output 文件夹。前面代码中已经给出代码删除output文件的方式。也可以手动使用下面命令进行删除。
./bin/hdfs dfs -rm -r output # 删除 output 文件夹下面是前面两个文件word1.txt、word2.txt运行的结果: