主题模型-LDA
参考:http://blog.csdn.net/v_july_v/article/details/41209515
关于LDA有两种含义,一种是线性判别分析(Linear Discriminant Analysis),一种是概率主题模型:隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA),本文讲后者。
是一种无监督的贝叶斯模型
是一种主题模型,它可以将文档集中每篇文档的主题按照概率分布的形式给出。同时它是一种无监督学习算法,在训练时不需要手工标注的训练集,需要的仅仅是文档集以及制定主题的数量k即可。此外LDA的另一个优点则是,对于每一个主题均可找出一些词语来描述它。
是一种典型的词袋模型,即它认为一篇文档是由一组词构成的一个集合,词与词之间没有顺序以及先后的关系。一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。
人类是怎么生成文档的呢?比如假设事先给定了这几个主题:Arts、Budgets、Children、Education,然后通过学习训练,获取每个主题Topic对应的词语。如下图所示:
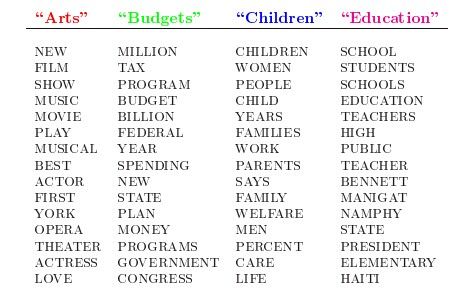
然后以一定的概率选取上述某个主题,再以一定的概率选取那个主题下的某个单词,不断的重复这两步,最终生成如下图所示的一篇文章(其中不同颜色的词语分别对应上图中不同主题下的词):

而当我们看到一篇文章后,往往喜欢推测这篇文章是如何生成的,我们可能会认为作者先确定这篇文章的几个主题,然后围绕这几个主题遣词造句,表达成文。现在某小撮人想让计算机利用LDA干一件事:你计算机给我推测分析网络上各篇文章分别都写了些啥主题,且各篇文章中各个主题出现的概率大小(主题分布)是啥。
复习贝叶斯公式:
P(Y|X)=P(X|Y)P(Y)P(X)
它其实是由以下的联合概率公式推导出来:
P(Y,X)=P(Y|X)P(X)=P(X|Y)P(Y)
模型
用概率作为 【可信度】
每次看到新数据,就更新【可信度】
需要一个模型来解释数据的生成
先验,后验与似然

标准版解释
一篇文章的每个词都是以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语组成的
P(单词|文档)=P(单词|主题)*P(主题|文档)
LDA生成过程:
对于语料库中的每篇文档,LDA定义了如下生成过程(generative process):
1、对每一篇文档,从主题分布中抽取一个主题;
2、从上述被抽到的主题所对应的单词分布中抽取一个单词;
3、重复上述过程直至遍历文档中的每一个单词。
具体来讲:
(w代表单词;d代表文档;t代表主题;大写代表总集合,小写代表个体。)
D中每个文档d看作一个单词序列 < w1,w2,…,wn> ,wi 表示第 i 个单词。
D中涉及的所有不同单词组成一个词汇表大集合 V(vocabulary),LDA以文档集合D作为输入,希望训练出的两个结果向量(假设形成k个topic,V中一共m个词):
- 对每个D中的文档d,对应到不同Topic的概率 θd< pt1,…,ptk>,其中,pti 表示d对应T中第i个topic的概率。计算方法是直观的,pti=nti/n,其中nti表示d中对应第 i 个topic 的词的数目,n是d中所有词的总数。
- 对每个T中的topict,生成不同单词的概率 φt< pw1,…,pwm>,其中,pwi 表示 t 生成 V 中第 i 个单词的概率。计算方法同样很直观,pwi=Nwi/N,其中Nwi表示对应到topict的V 中第 i 个单词的数目,N表示所有对用到topict的单词总数。
所以LDA的核心公式如下:
P(w | d)=P(w | t)*P(t | d)
直观的看这个公式,就是以Topic作为中间层,可以通过当前的 θd 和 φt 给出了文档 d 中出现单词 w 的概率。其中 p(t | d)利用 θd 计算得到,P(w | t)利用φt计算得到。
实际上,利用当前的 θd 和 φt,我们可以为一个文档中的一个单词计算它对应任意一个Topic时的 p(w | d),然后根据这些结果来更新这个词应该对应的topic。然后,如果这个更新改变了这个单词所对应的Topic,就会反过来影响 θd 和 φt。
LDA学习过程:
LDA算法开始时,先随机地给 θd 和 φt 赋值(对所有的d和t)。然后:
- 针对一个特定的文档ds中的第i单词wi,如果令该单词对应的topic为tj,可以把上述公式改写为: Pj(wi|ds)=P(wi|tj)∗P(tj|ds)
- 现在我们可以枚举T中topic,得到所有的 Pj(wi|ds) 。然后可以根据这些概率值结果为ds中的第i个单词wi选择一个topic。最简单的想法是取令 Pj(wi|ds) 最大的 tj (注意,这个式子里只有j是变量)
- 然后,如果ds中的第i个单词wi在这里选择了一个与原先不同的topic(也就是说,这个时候i在遍历ds中所有的单词,而tj理当不变),就会对 θd 和 φt 有影响了。它们的影响又会反过来影响对下面提到的 P(w | d)的计算。对D中所有的d中的所有w进行一次P(w | d)的计算并重新选择topic看作一次迭代。这样进行n次循环迭代之后,就会收敛到LDA所需要的结果了。
在LDA模型中,一篇文档生成的方式如下:
- 从狄利克雷分布 α 中取样生成文档 i 的主题分布 θi
- 从主题的多项式分布 θi 中取样生成文档 i 第 j 个词的主题 zi,j
- 从狄利克雷分布 β 中取样生成主题 zi,j 对应的词语分布 φzi,j
- 从词语的多项式分布 φzi,j 中采样最终生成词语 wi,j
其中,类似Beta分布是二项式分布的共轭先验概率分布,而狄利克雷分布(Dirichlet分布)是多项式分布的共轭先验概率分布。此外,LDA的图模型结构如下图所示(类似贝叶斯网络结构):

二项分布(Binomial distribution)
二项分布是从伯努利分布推进的。伯努利分布,又称两点分布或0-1分布,是一个离散型的随机分布,其中的随机变量只是两类取值,非正即负。而二项分布即重复n次的伯努利实验,记为 X ~b(n,p)。简言之,只做一次实验,是伯努利分布,重复做了n次,是二项分布。
二项分布的概率密度函数为:
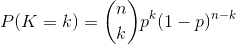
对于k=0,1,2,…,n,其中 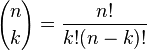 是二项式系数,又记为
是二项式系数,又记为 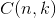 。
。
多项分布,是二项分布扩展到多维的情况
多项分布是指单次实验中的随机变量的取值不再是0-1的,而是有多种离散值可能(1,2,3,…,k)。比如投掷6个面的骰子实验,N次实验结果服从k=6的多项分布。其中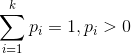
多项分布的概率密度函数为:

Beta分布,二项分布的共轭先验分布
给定参数 α>0 和 β>0,取值范围为 [0,1] 的随机变量 x 的概率密度函数:

其中: ,
,
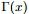 就是gamma函数。
就是gamma函数。
Dirichlet分布,是beta分布在高维度上的推广
Dirichlet分布的的密度函数形式跟beta分布的密度函数如出一辙:

其中 
至此,我们可以看到二项分布和多项分布很相似,Beta分布和Dirichlet 分布很相似,而至于“Beta分布是二项式分布的共轭先验概率分布,而狄利克雷分布(Dirichlet分布)是多项式分布的共轭先验概率分布”
贝叶斯派思考问题的固定模式:
先验分布 + 样本信息
+ 样本信息 
 后验分布
后验分布
上述思考模式意味着,新观察到的样本信息将修正人们以前对事物的认知。换言之,在得到新的样本信息之前,人们对θ的认知是先验分布π(θ),在得到新的样本信息后,人们对θ的认知为 π(θ|x)。
顺便提下频率派与贝叶斯派各自不同的思考方式:
- 频率派把需要推断的参数θ看做是固定的未知常数,即概率θ虽然是未知的,但起码是确定的一个值,同时,样本X是随机的,所以频率派重点研究样本空间,大部分的概率计算都是针对样本X的分布;
- 贝叶斯派的观点截然相反,他们认为待估计的参数θ 是随机变量,服从一定的分布,而样本X是固定的,由于样本是固定的,所以他们重点研究的是参数θ的分布。
几个主题模型(循序渐进)
Unigram model
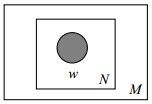
对于文档 w =(w1,w2,...,wN) ,对 p(wn) 表示词 wn 的先验概率,生成文档w的概率为:

其图模型为(图中被涂色的w表示可观测变量,N表示一篇文档中总共N个单词,M表示M篇文档):
Mixture of unigrams model
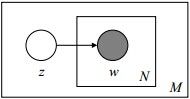
该模型的生成过程是:给某个文档先选择一个主题z,再根据该主题生成文档,该文档中的所有词都来自一个主题。假设主题有 z1,...,zk ,生成文档w的概率为:

其图模型为(图中被涂色的w表示可观测变量,未被涂色的z表示未知的隐变量,N表示一篇文档中总共N个单词,M表示M篇文档):
PLSA 模型
刚才的mix unigram模型里面,一篇文章只给了一个主题。但现实生活中,一篇文章可能有多个主题,只不过是 出现的几率 不一样。
比如介绍一个国家的文档中,往往会分别从教育、经济、交通等多个主题进行介绍。那么在pLSA中,文档是怎样被生成的呢?

你不停的重复扔“文档-主题”骰子和”主题-词项“骰子,重复N次(产生N个词),完成一篇文档,重复这产生一篇文档的方法M次,则完成M篇文档。
定义:
- P(di) 表示海量文档中某篇文档被选中的概率。
- P(wj|di) 表示词 wj 在给定文档 di 中出现的概率。
- 怎样计算得到呢?针对海量文档,对所有文档进行分词后,得到一个词汇列表,这样每篇文档就是一个词语的集合。对于每个词语,用它在文档中出现的次数除以文档中词语总数,便是它在文档中出现的概率 P(wj|di) 。
- P(zk|di) 表示具体某个主题 zk 在给定文档 di 下出现的概率。
- P(wj|zk) 表示具体某个词 wj 在给定主题 zk 下出现的概率,与主题关系越密切的词,其条件概率 P(wj|zk) 越大。
利用上述的第1、3、4个概率,我们便可以按照如下的步骤得到“文档-词项”的生成模型:
- 按照概率 P(di) 选择一篇文档 di
- 选定文档 di 后,从主题分布中按照概率 P(zk|di) 选择一个隐含的主题类别 zk
- 选定 zk 后,从词分布中按照概率 P(wj|zk) 选择一个词 wj
所以pLSA中生成文档的整个过程便是选定文档生成主题,确定主题生成词。
我们通过观测,得到了 知道主题是什么,我就用什么单词 的文本生成模型,那么,根据贝叶斯定律,我们就可以反过来推出 看见用了什么单词,我就知道主题是什么
人类根据文档生成模型写成了各类文章,然后丢给了计算机,相当于计算机看到的是一篇篇已经写好的文章。现在计算机需要根据一篇篇文章中看到的一系列词归纳出当篇文章的主题,进而得出各个主题各自不同的出现概率:主题分布。即文档d和单词w是可被观察到的,但主题z却是隐藏的。
如下图所示(图中被涂色的d、w表示可观测变量,未被涂色的z表示未知的隐变量,N表示一篇文档中总共N个单词,M表示M篇文档):

上图中,文档d和词w是我们得到的样本(样本随机,参数虽未知但固定,所以pLSA属于频率派思想。区别于下文要介绍的LDA中:样本固定,参数未知但不固定,是个随机变量,服从一定的分布,所以LDA属于贝叶斯派思想),可观测得到,所以对于任意一篇文档,其 P(wj|di) 是已知的。
可以根据大量已知的文档-词项信息 P(wj|di) ,训练出文档-主题 P(zk|di) 和主题-词项 P(wj|zk) ,如下公式所示:

故得到文档中每个词的生成概率为:

由于 P(di) 可事先计算求出,而 P(wj|zk) 和 P(zk|di) 未知,所以 θ= ( P(wj|zk) , P(zk|di) )就是我们要估计的参数(值),通俗点说,就是要最大化这个θ。
LDA模型
LDA 就是在pLSA的基础上加层贝叶斯框架,即LDA就是pLSA的贝叶斯版本。
pLSA和LDA对比

pLSA跟LDA的本质区别就在于它们去估计未知参数所采用的思想不同,前者用的是频度派思想,后者用的是贝叶斯派思想。
LDA模型应用:一眼看穿希拉里的邮件
LDA是无监督学习,只能根据主题分成几类,指明代表这个类主题的几个单词,不能得到这个类主题具体是什么。
import numpy as np # NumPy系统是一个数值计算扩展
import pandas as pd # pandas是一个数据分析库
import re # 正则库
df = pd.read_csv("HillaryEmails.csv") # 也可用Python标准库csv
df = df[['Id', 'ExtractedBodyText']].dropna() # 原始邮件数据中有很多Nan值,直接扔掉 #df是pandas中的一个数据结构,取出Id和ExtractedBodyText这两列
# 文本预处理
def clean_email_text(text):
text = text.replace('\n', " ") # 换行符,换成空格
text = re.sub(r"-", " ", text) # 把 "-" 的两个单词,分开(比如:july-edu ==> july edu)
text = re.sub(r"\d+/\d+/\d+", "", text) # 日期,对主题模型没有意义
text = re.sub(r"[0-2]?[0-9]:[0-6][0-9]", "", text) # 时间,没意义
text = re.sub(r"[\w]+@[\.\w]+", "", text) # 邮件地址,没意义
text = re.sub(r"/[a-zA-Z]*[:\//\]*[A-Za-z0-9\-_]+\.+[A-Za-z0-9\.\/%&=\?\-_]+/i", "", text) # 网址,没意义
pure_text = ''
# 以防还有其他特殊字符(数字)等等,我们直接把他们loop一遍,过滤掉
for letter in text:
# 只留下字母和空格
if letter.isalpha() or letter == ' ':
pure_text += letter
# 再把那些去除特殊字符后落单的单词,直接排除。
# 我们就只剩下有意义的单词了。
text = ' '.join(word for word in pure_text.split() if len(word) > 1)
return text
docs = df['ExtractedBodyText'] # 只要一列
docs = docs.apply(lambda s: clean_email_text(s))
# 输出一行看看
print(docs.head(1).values)
doclist = docs.values # 拿到所有文件内容
# 我们用Gensim来做一次模型构建
# 首先,我们得把我们刚刚整出来的一大波文本数据
# [[一条邮件字符串],[另一条邮件字符串], ...]
# 转化成Gensim认可的语料库形式:
# [[一,条,邮件,在,这里],[第,二,条,邮件,在,这里],[今天,天气,肿么,样],...]
# LDA模型构建
import warnings
warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim')
from gensim import corpora, models, similarities
import gensim
# 为了免去讲解安装NLTK等等的麻烦,我这里直接手写一下停止词列表:
# 这些词在不同语境中指代意义完全不同,但是在不同主题中的出现概率是几乎一致的。所以要去除,否则对模型的准确性有影响
stoplist = ['very', 'ourselves', 'am', 'doesn', 'through', 'me', 'against', 'up', 'just', 'her', 'ours',
'couldn', 'because', 'is', 'isn', 'it', 'only', 'in', 'such', 'too', 'mustn', 'under', 'their',
'if', 'to', 'my', 'himself', 'after', 'why', 'while', 'can', 'each', 'itself', 'his', 'all', 'once',
'herself', 'more', 'our', 'they', 'hasn', 'on', 'ma', 'them', 'its', 'where', 'did', 'll', 'you',
'didn', 'nor', 'as', 'now', 'before', 'those', 'yours', 'from', 'who', 'was', 'm', 'been', 'will',
'into', 'same', 'how', 'some', 'of', 'out', 'with', 's', 'being', 't', 'mightn', 'she', 'again', 'be',
'by', 'shan', 'have', 'yourselves', 'needn', 'and', 'are', 'o', 'these', 'further', 'most', 'yourself',
'having', 'aren', 'here', 'he', 'were', 'but', 'this', 'myself', 'own', 'we', 'so', 'i', 'does', 'both',
'when', 'between', 'd', 'had', 'the', 'y', 'has', 'down', 'off', 'than', 'haven', 'whom', 'wouldn',
'should', 've', 'over', 'themselves', 'few', 'then', 'hadn', 'what', 'until', 'won', 'no', 'about',
'any', 'that', 'for', 'shouldn', 'don', 'do', 'there', 'doing', 'an', 'or', 'ain', 'hers', 'wasn',
'weren', 'above', 'a', 'at', 'your', 'theirs', 'below', 'other', 'not', 're', 'him', 'during', 'which']
# 人工分词:英文的分词,直接就是对着空白处分割就可以了
texts = [[word for word in doc.lower().split() if word not in stoplist] for doc in doclist]
# 建立语料库
# 用标记化 的方法,把每个单词用一个数字index指代,并把我们的原文本变成一条长长的数组
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
# corpus[13]
# [(36, 1), (505, 1), (506, 1), (507, 1), (508, 1)]
# 这个列表告诉我们,第14(从0开始是第一)个邮件中,一共5个有意义的单词(经过我们的文本预处理,并去除了停止词后)
# 其中,36号单词出现1次,505号单词出现1次,以此类推。。。
# 接着,我们终于可以建立模型了:
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=20)
# 我们可以看到,第10号分类,其中最常出现的单词是:
print(lda.print_topic(10, topn=5))
# 0.045*"fyi" + 0.007*"part" + 0.005*"germany" + 0.005*"release" + 0.005*"one"
# 我们把所有的主题打印出来看看
print(lda.print_topics(num_topics=20, num_words=5))
print("------------------------------------------------------------")
# 通过
# lda.get_document_topics(bow)
# 或者
# lda.get_term_topics(word_id)
# 两个方法,把新鲜的文本/单词,分类成20个主题中的一个
text = "To all the little girls watching...never doubt that you are valuable and powerful & deserving of every chance & opportunity in the world."
text = clean_email_text(text) # 经过相同的预处理
text = [word for word in text.lower().split() if word not in stoplist] # 经过相同的分词去除停用词
corpus = dictionary.doc2bow(text) # 经过相同的词袋化
print(corpus)
topiclists = lda.get_document_topics(corpus)
print(topiclists)
for topic in topiclists:
print(lda.print_topic(topic[0], topn=5))#查看相应分类的最长出现的前5个单词