一文了解机器学习的二十种度量指标(上)
一文了解机器学习的二十种度量指标
- 一、前言
- 二、分类相关的度量指标
- 2.1 Confusion Matrix 混淆矩阵
- 2.2 Accuracy 准确率
- 2.3 Percision 精确率
- 2.4 Recall 召回率
- 2.5 F1 Score
- 2.6 Sensitivity and Specificity 敏感性和特异性
- 2.7 ROC 曲线
- 2.8 AUC
- 三、回归相关的度量指标
- 3.1 MSE
- 3.2 MAE
- 3.3 Inlier Ratio Metric
- 四、总结
- 五、参考资料
一、前言
对于机器学习来说,模型是重中之重,如何选择合适的模型极大的决定是否能顺利的解决我们面对的任务。目前机器学习模型包罗万象,如何对比不同模型的效果就需要根据任务选择适合的评价标准。本文将系统的介绍机器学习的二十种度量指标,和大家一起完全掌握这些不同的度量指标的具体运用和差别,这样大家在阅读文献的时候遇到不同的度量单位不会感到迷惑。本文由两个部分组成,第一部分将介绍分类和回归模型中常用的十种度量指标,第二部分将介绍排序任务,计算机视觉,自然语言处理和深度学习中的度量指标。
二、分类相关的度量指标
分类任务是工业界中机器学习应用最广泛的领域,从人脸识别到Youtube视频分类,从医学影像分类到文本分类,处处可以看到分类算法的身影。支持向量机,逻辑斯蒂回归,决策树算法,随机森林算法,XGboost,卷积神经网络,循环神经网络都是最常见的分类模型。下面开始介绍相关的指标。
2.1 Confusion Matrix 混淆矩阵
在开始介绍其他的术语之前,首先回顾一下混淆矩阵的概念。混淆矩阵又称误差矩阵,是对模型预测相对于真值表的扁平可视化展示。混淆矩阵的每一行代表预测分类的实例而每一列代表实际分类的实例。下图是一个混淆矩阵的例子:

可以看出,对角线的元素表示模型分类正确的实例,反对角线的实例表示模型分类错误的实例。
2.2 Accuracy 准确率
分类准确率的定义非常简单: a c c u r a c y = T P + T N T P + T N + F P + F N accuracy=\frac{TP+TN}{TP+TN+FP+FN} accuracy=TP+TN+FP+FNTP+TN,所有分类正确的实例的个数除以所有需要分类的实例数量即可得到分类准确率。
2.3 Percision 精确率
当类别实例分布并不均匀的时候,使用准确率作为评判指标往往会产生问题,例如模型可以将所有类别预测成出现最多次数的类别从而获得更高的准确率。因此我们也需要了解模型和类别相关的表现度量标准-精确率。
精确率的定义如下: P e r c i s i o n c l a s s = T P T P + F P Percision_{class}=\frac{TP}{TP+FP} Percisionclass=TP+FPTP
2.4 Recall 召回率
召回率的定义是: R e c a l l = T P T P + F N Recall=\frac{TP}{TP+FN} Recall=TP+FNTP,召回率的定义是模型正确分类的实例数的比例。
2.5 F1 Score
精确率和召回率分别从部分方面反映了模型的性能,但是有时候我们需要平衡两种指标的重要性,从而产生了F1 score,即精确率和召回率的调和均值:
F 1 = 2 × P e r c i s i o n × R e c a l l P e r c i s i o n + R e c a l l F1 = \frac{2\times Percision\times Recall}{Percision+Recall} F1=Percision+Recall2×Percision×Recall
F1值更加广义的定义是:
F β = ( 1 + β 2 ) P e r c i s i o n × R e c a l l β 2 × P e r c i s i o n + R e c a l l F_\beta=(1+{\beta}^2)\frac{Percision\times Recall}{{\beta}^2\times{Percision}+Recall} Fβ=(1+β2)β2×Percision+RecallPercision×Recall
一个模型的精确率和召回率总是存在一个权衡,如果一个指标过高必然带来另一个指标的降低,因此我们需要根据需要平衡两种指标。
2.6 Sensitivity and Specificity 敏感性和特异性
Sensitivity和Specificity是医学和生物学常用的两个术语,定义如下:
S e n s i t i v i t y = R e c a l l = T P T P + F N Sensitivity=Recall=\frac{TP}{TP+FN} Sensitivity=Recall=TP+FNTP
S p e c i f i c i t y = T r u e N e g a t i v e R a t e = T N T N + F P Specificity=True Negative Rate=\frac{TN}{TN+FP} Specificity=TrueNegativeRate=TN+FPTN
2.7 ROC 曲线
ROC 全称是 receiver operating characteristic,是一个展示而分类器的在每一个截至点阈值的性能,它本质上展示了真阳性率和假阳性率对于不同的阈值。如下图是一个ROC曲线的例子:

许多分类模型都是基于概率的,这些模型将输出概率和截至点阈值进行比较,如果大于截至点则输出为真。ROC曲线本质上找出对于不同的阈值点的TPR和FPR值的对比,然后画出TPR和FPR。从图中我们可以看出,随着正类截止阈值的降低,更多的样本被预测成正类。
ROC曲线常用来比较模型的整体性能和选择一个适合的截止阈值点。
2.8 AUC
AUC 全称是 area under the curve,是对二分类器的性能的整体评估,AUC计算ROC曲线下的面积大小,因此取值在0到1之间。一种从概率的角度对于AUC的解释是模型对于一个随机的正样本的排序大于对随机的负样本的排序。
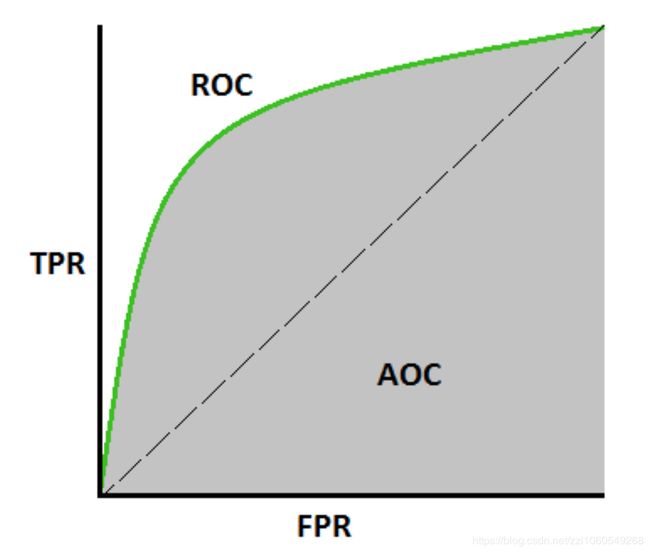
从更高层次来说,AUC越高模型越好。但是对于不同的实际需求来说,AUC有可能不是最需要关心的指标,因此在实际使用中,应当根据自己的实际需求来确定使用什么指标来度量模型。
三、回归相关的度量指标
回归模型是另一大类机器学习和统计模型,用来输出连续的预测值,从房价预测到股票涨跌,从天气预报到图像压缩,回归模型处处可见。常见的回归模型包括线性回归,随机森林,XGboost,卷积神经网络,循环神经网络等。
3.1 MSE
MSE 全称 mean squared error,可能是最常见的用来度量回归模型的指标,它本质是计算预测值和实际值的均方误差。
MSE的公式通常可以看成: M S E = 1 N ∑ i = 1 N ( y i − y i ^ ) 2 MSE=\frac{1}{N}\sum_{i=1}^{N}(y_i-\hat{y_i})^2 MSE=N1i=1∑N(yi−yi^)2
有时候为了度量一个大值,也会使用RMSE,其实就是MSE的平方根。
3.2 MAE
MAE 全称 mean absolute error 是另一种度量预测值和实际值的平均绝对距离的方法,其定义如下:
M A E = 1 N ∑ i = 1 N ∣ y i − y i ^ ∣ MAE=\frac{1}{N}\sum_{i=1}^{N}|y_i-\hat{y_i}| MAE=N1i=1∑N∣yi−yi^∣
相对于MSE,MAE对于离群点更加鲁棒,主要原因是离群点和真实点的距离一般过大,MSE进行平方运算会放大这种距离对于整体评估的影响。
对于MSE和MAE,有一种极大似然估计的解释,如果我们假设特征和目标之间有线性依赖,那么MSE和MAE相当于对于模型参数的极大似然估计,如果对于模型的误差分别是基于高斯或者拉普拉斯先验。
3.3 Inlier Ratio Metric
还有一种对于回归模型的评估标准叫做Inlier Ratio Metric,本质上是数据在给定的误差范围内预测正确的比例。
四、总结
大部分的评估标准都需要结合具体的任务来选择,不同的任务关心的目标不一样,所需要选的评估标准不一样。
五、参考资料
- Ian Goodfellow, Yoshua Bengio, and Aaron Courville. “Deep learning”, MIT press, 2016.
- Christopher M. Bishop, “Pattern recognition and machine learning”, springer, 2006.
- Jerome Friedman, Trevor Hastie, and Robert Tibshirani. “The elements of statistical learning”, Springer series in statistics, 2001.
- Tilo Strutz, “Data fitting and uncertainty: A practical introduction to weighted least squares and beyond”, Vieweg and Teubner, 2010.
- 20 machine learning metrics