《流浪地球》影评数据爬取分析
《流浪地球》影评数据爬取分析
人生苦短,我用Python。
阿巴阿巴阿巴,爬虫初学者,志在记录爬虫笔记,交流爬虫思路。
话不多说,开始进行操作。
对于电影数据影评的爬取,这里选取的网站是豆瓣网(豆瓣网自从全面反爬之后,很多东西都只会用户看一部分,而且一天中访问量不得超过60次(maybe?))。
1、首先看一看网页结构:

用红框标出来的就是要爬取的部分。

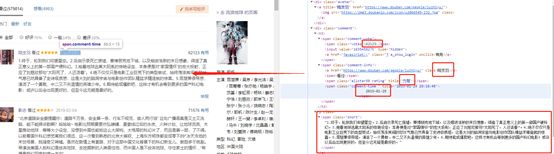
这个就是在网页源码中的呈现形式。
当然,不满足于表面的爬取,还要深入到详情页中去爬取一些东西:

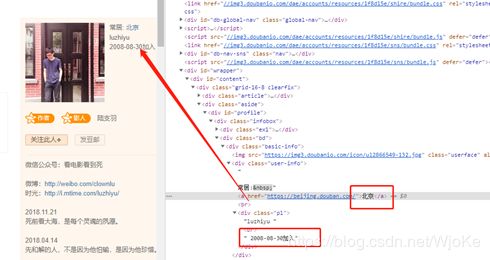
2、进行代码编写前的设置
在编写前需要对得到网页的请求头:

在这里只需要得到图上的这两个部分
3、在Python中进行编写操作
(1)引入需要的库
import requests
from lxml import etree
import time
import re
from bs4 import BeautifulSoup
import pandas as pd
(2)访问得到网页相应体

在这里决定采用BeautifulSoup和Xpath进行解析的操作(Xpath是因为有谷歌插件,好用)
user=[]###用户名
recommend=[]###推荐
time=[]###评论时间
useful=[]###赞
comment=[]###评论正文
localurl=[]###用户详细页url
times=[]###评论具体时刻
for i in range(25):###只会给用户看25页数据,然后网页的变化规律是每一页*20
res=requests.get('https://movie.douban.com/subject/26266893/comments?start='+str(i*20)+'&limit=20&sort=new_score&status=P',
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36',
'Cookie': 'bid="7sAyY56pZbA"; _vwo_uuid_v2=DCD965FA612B9AA380F3FA1A2339BB564|b67597b839c7d6bc73e9b665eed2bc00; __gads=ID=c51078e4178c48eb:T=1587128591:S=ALNI_MZDDDN1GCQhOG2lGtWmhDyztyYnZw; ll="118331"; __yadk_uid=8afSWVhZUZdGvfM5Si9RIU8CXGBzBERi; ct=y; push_doumail_num=0; push_noty_num=0; __utmv=30149280.21342; douban-fav-remind=1; _ga=GA1.2.744215232.1587128554; _gid=GA1.2.526658113.1587270968; UM_distinctid=17190b8f9179b-09d49616f834c5-6373664-1fa400-17190b8f918bdb; Hm_lvt_19fc7b106453f97b6a84d64302f21a04=1587270974; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1587349547%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3D87F10nBWauMdSF-PaKHoG8T9ZEv2mnP_6OpeQWaLQx4n7WfQTD7-myRg8wfRPA_I%26wd%3D%26eqid%3Dd465097600331851000000065e9d0827%22%5D; _pk_ses.100001.4cf6=*; ap_v=0,6.0; __utma=30149280.744215232.1587128554.1587310231.1587349547.5; __utmc=30149280; __utmz=30149280.1587349547.5.4.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utma=223695111.1317237486.1587265874.1587310231.1587349547.4; __utmb=223695111.0.10.1587349547; __utmc=223695111; __utmz=223695111.1587349547.4.3.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmt=1; __utmb=30149280.2.10.1587349547; dbcl2="213426135:OE+aP6Hb5Lk"; ck=zS1Z; _pk_id.100001.4cf6=0559898e47160491.1587265874.4.1587349586.1587310278.'})
ht=etree.HTML(res.text)###xpath解析
htt=BeautifulSoup(res.text,'lxml')###BeautifulSoup解析
user=user+ht.xpath('//*[@id="comments"]/div/div/h3/span[2]/a/text()')
recommend=recommend+ht.xpath('//*[@id="comments"]/div/div/h3/span[2]/span[2]/@title')
time=time+[j.text for j in htt.find_all(name='span',class_='comment-time')]
times=times+[t['title'] for t in htt.find_all(name='span',class_='comment-time')]
useful=useful+ht.xpath('//*[@id="comments"]/div/div[2]/h3/span[1]/span/text()')
comment=comment+ht.xpath('//*[@id="comments"]/div/div[2]/p/span/text()')
localurl=localurl+ht.xpath('//*[@id="comments"]/div/div/h3/span[2]/a/@href')
在得到表面数据后,因为在之前有了详情页的url,所以继续循环访问,得到详情页数据。
local=[]###用户地址
addtime=[]###用户注册时间
for m in localurl:
ress=requests.get(m,headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36',
'Cookie': 'bid="7sAyY56pZbA"; _vwo_uuid_v2=DCD965FA612B9AA380F3FA1A2339BB564|b67597b839c7d6bc73e9b665eed2bc00; __gads=ID=c51078e4178c48eb:T=1587128591:S=ALNI_MZDDDN1GCQhOG2lGtWmhDyztyYnZw; ll="118331"; __yadk_uid=8afSWVhZUZdGvfM5Si9RIU8CXGBzBERi; ct=y; push_doumail_num=0; push_noty_num=0; __utmv=30149280.21342; douban-fav-remind=1; _ga=GA1.2.744215232.1587128554; _gid=GA1.2.526658113.1587270968; UM_distinctid=17190b8f9179b-09d49616f834c5-6373664-1fa400-17190b8f918bdb; Hm_lvt_19fc7b106453f97b6a84d64302f21a04=1587270974; __utmc=30149280; __utmc=223695111; dbcl2="213426135:5KTItlUeQ5Y"; ck=WaLj; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1587310231%2C%22https%3A%2F%2Fwww.douban.com%2F%22%5D; _pk_ses.100001.4cf6=*; __utma=30149280.744215232.1587128554.1587300080.1587310231.4; __utmz=30149280.1587310231.4.3.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utma=223695111.1317237486.1587265874.1587300080.1587310231.3; __utmb=223695111.0.10.1587310231; __utmz=223695111.1587310231.3.2.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmt=1; __utmb=30149280.4.10.1587310231; _pk_id.100001.4cf6=0559898e47160491.1587265874.3.1587310253.1587306901.'})
httt=etree.HTML(ress.text)
local=local+httt.xpath('//*[@id="profile"]/div/div[2]/div[1]/div/a/text()')
addtime=addtime+httt.xpath('//*[@id="profile"]/div/div[2]/div[1]/div/div/text()[2]')
4、数据处理
因为得到的数据很不好看,逼死处女座!!!!所以在这里想方设法的进行数据的处理。
对评分进行处理:
time=[re.sub('\n|\s+','',z) for z in time]###对评论时间进行清洗
da={'用户':user,'评分':recommend,'日期':time,'赞':useful,'评论':comment}
data=pd.DataFrame(da)
data['评分'][data['评分'].str.contains(' ')]='无'###对评分进行设定
data['分数']=0
for i in range(len(data['评分'])):###划分依据为网站给出
if data['评分'][i]=='力荐':
data['分数'][i]=50
if data['评分'][i]=='推荐':
data['分数'][i]=40
if data['评分'][i]=='还行':
data['分数'][i]=30
if data['评分'][i]=='较差':
data['分数'][i]=20
if data['评分'][i]=='很差':
data['分数'][i]=10
if data['评分'][i]=='无':
data['分数'][i]=0
data.to_excel('C:\\Users\\dell\\Desktop\\表面数据.xlsx')
对地区进行处理:
local1=[re.sub('[A-Z]','国外',m) for m in local]###对用户地址进行清洗
for k in range(len(local1)):
if local1[k]=='中国香港':
local1[k]='香港'
for k in range(len(local1)):
if local1[k]=='中国台湾':
local1[k]='台湾'
for k in range(len(local1)):
if local1[k]=='中国澳门':
local1[k]='澳门'
da1={'地址':local1}
dat=pd.DataFrame(da1)
dat['地址'][dat['地址'].str.contains('国外')]='国外'
for s in range(len(dat['地址'])):
if len(dat['地址'][s])>2:
dat['地址'][s]=dat['地址'][s][0:2]
for k in range(len(dat['地址'])):
if dat['地址'][k]=='讷河':
dat['地址'][k]='黑龙江'
dat.to_excel('C:\\Users\\dell\\Desktop\\地区数据.xlsx')
对时间进行处理:
att={'时刻':times}
datt=pd.DataFrame(att)
datt.to_excel('C:\\Users\\dell\\Desktop\\时刻数据.xlsx')
addtimes=[re.sub('\n','无',g) for g in addtime]###对注册时间进行清洗
addtimes=[re.sub('加入','',g) for g in addtimes]
ad={'注册时间':addtimes}
datad=pd.DataFrame(ad)
datad.drop(index=list(datad['注册时间'][datad['注册时间']=='无'].index),inplace=True)
datad.to_excel('C:\\Users\\dell\\Desktop\\注册时间数据.xlsx')
得到的数据如下:


5、数据可视化部分
(1)词云图
停用词部分
import pandas as pd
import jieba###导入jieba分词库
import pandas as pd
from tkinter import _flatten###导入展开列表的方法
data=pd.read_excel('C:\\Users\\dell\\Desktop\\表面数据.xlsx')###导入数据
da=data['评论']###提出评论一列
dacut=da.apply(jieba.lcut)###对每一项进行分词
with open('C:\\Users\\dell\\Desktop\\stoplist.txt','r',encoding='utf8') as f:###读入停词表
stw=f.read()
stw=['\n','',' ','委','真的','里','中']+stw.split()###设定停词表
datacut=dacut.apply(lambda x:[i for i in x if i not in stw])###进行停词处理
datacut
得到的结果如下:

词频统计
cutname=pd.Series(_flatten(list(datacut)))###展平每一项停词后结果
number=cutname.value_counts()###统计词频
词云图的绘制
import matplotlib.pyplot as plt###画图的库
from wordcloud import WordCloud###导入画词云的库
mask=plt.imread('C:\\Users\\dell\\Desktop\\tipmg.jpg')###读入词云底图
wc=WordCloud(font_path='C:\\Windows\\Fonts\\STHUPO.TTF',mask=mask,background_color='white')###设定词云的字体,底图,背景颜色
plt.figure(figsize=(10,10))###设定画布大小
plt.imshow(wc.fit_words(number))###画出词云
plt.axis('off')###去掉坐标轴
plt.savefig('C:\\Users\\dell\\Desktop\\整体词云.jpg')

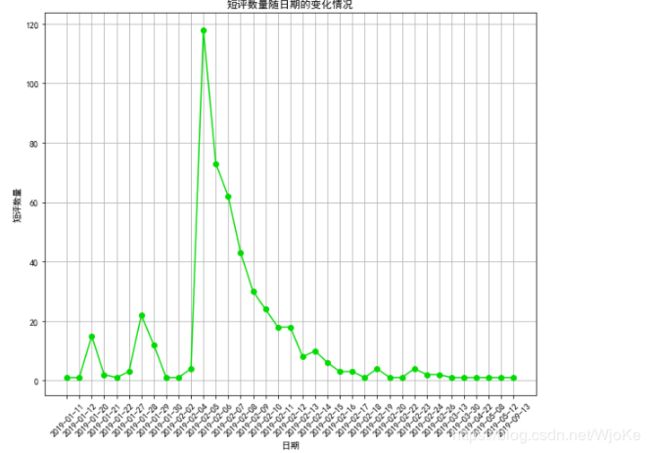
评论与时刻的关系:
date=data['日期'].value_counts()###统计频次
date=date.sort_index()
plt.rcParams['font.sans-serif']=['SimHei']###显示中文
plt.rcParams['axes.unicode_minus'] = False
fig = plt.figure(figsize=(10,8))
plt.plot(range(len(date)), date,marker='o',c='#00DB00')
plt.xticks(range(len(date)), date.index, rotation=45)
plt.grid()
plt.title('短评数量随日期的变化情况')
plt.xlabel("日期")
plt.ylabel('短评数量')
plt.savefig('C:\\Users\\dell\\Desktop\\短评量随时间变化图.jpg')
评论等级和时间关系:
tmp=pd.DataFrame(0,index=data['日期'].drop_duplicates().sort_values(),
columns=data['分数'].drop_duplicates().sort_values())###创建新的数据框
data['分数'].drop_duplicates().sort_values()###统计频次
data.loc[:,['日期','分数']]
for i,j in zip(data['日期'],data['分数']):###统计分数段出现次数
tmp.loc[i,j] += 1
n,m = tmp.shape
plt.figure(figsize=(10,5))
plt.rcParams['axes.unicode_minus'] = False
for i in range(m):
plt.plot(range(n),(-1 if i<3 else 1)*tmp.iloc[:, i],)
plt.fill_between(range(n), (-1 if i<3 else 1)*tmp.iloc[:, i], alpha=0.8) ###循环画图
plt.grid()
plt.legend(tmp.columns)
plt.xticks(range(n), tmp.index,rotation=45)
plt.savefig('C:\\Users\\dell\\Desktop\\评分随时间变化.jpg')
plt.show()

地理图:
引入库
import matplotlib.pyplot as plt
import pandas as pd
from pyecharts.charts import Geo###导入画地图的库
import pyecharts.options as opts###设定风格
from pyecharts.globals import ChartType###设定风格
画图:
data=pd.read_excel('C:\\Users\\dell\\Desktop\\地区数据.xlsx')###导入数据
da1=data['地址'][data['地址'][data['地址']!='国外'].index]###筛选出国内数据
da1=da1.value_counts()###统计个数
###画图
(Geo()
.add_schema(maptype='china',itemstyle_opts=opts.ItemStyleOpts(color="#005757", border_color="#fff"))
.add(series_name='',data_pair=[(i,j) for i,j in zip(da1.index,da1.values)],type_=ChartType.HEATMAP)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(visualmap_opts=opts.VisualMapOpts())
).render_notebook()

5、总结
大体的步骤就是以上啦,今后还会有小爬虫的发布的,谢谢大家!!!奥里给!