论文浅尝 | 面向多语言语义解析的神经网络框架
论文笔记整理:杜昕昱,东南大学本科生。

来源:ACL2017
链接:https://aclweb.org/anthology/P17-2007
论文训练了一个多语言模型,将现有的Seq2Tree模型扩展到一个多任务学习框架,该框架共享用于生成语义表示的解码器。该模型能够将来自多种不同语言的自然语言句子解析为它们相应的形式语义表示。论文中报告了多语言查询语料库的评估结果,并介绍了一个新的ATIS语料库的多语言版本。
Introduction
多语言语义解析——将来自多种不同语言的自然语言句子映射到它们相应的形式语义表示的任务。多语言场景有如下两种:
1. 单源类型,输入的一句话由同一种语言组成。
2. 多源类型,输入的一句话由多种语言的并列语句组成。
针对第二种类型的探索,只有过将多种单语言模型组合在一起的工作,单对于每种语言的单独训练会忽视源语言之间的共享信息,而且对每种语言去训练,调整,构建一个新的模型也是不方便的。
本论文提出一个接受输入多语言组成的句子的解析体系,将现有的Sequence-to-Tree模型扩展到一个多任务学习框架(神经网络机器翻译)。论文模型由多个编码器组成,一个用于每种语言,另一个解码器跨源语言共享,用于生成 语义表示。通过这种方式,模型可能受益于拥有一个能够很好地跨语言工作的通用解码器。这样模型可以受益于一个 在跨语言方面有良好表现的解码器。直观来说,该模型鼓励每种源语言编码器为解码器找到一个通用的结构化表示形式,论文还进一步修改了注意力机制,整合多源信息。
论文贡献:
1. 研究了两种多语言场景中的语义解析
2. 在Sequence-to-Tree的结构中加入新颖的拓展使得可以模型在语义解析中可以结合多语言的信息
3. 发布了一个新的ATIS语义数据集,它用两种新语言进行了注释
Model
与传统语义分析模型(为每个语言单独训练语言解析器)不同,论文中提出将N个编码器结合到一个模型中。这个模型将n种语言的句子编码为一个向量,之后用一个共享的解码器把已编码的向量解码到它相应的逻辑形式。输入句子有两种形式(单语言和并列多语言)。编码器被实现为具有长短时记忆(LSTM)单元的单向RNN,以自然语言序列作为输入。
同之前的多任务框架(neural MT),论文中为每个语言都构建了编码器(![]() ),对于第n种语言,他在第时间第t步更新隐藏向量:
),对于第n种语言,他在第时间第t步更新隐藏向量:
![]()
公式(1) ![]() 是LSTM函数
是LSTM函数 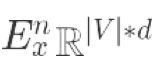 是嵌入矩阵行向量包含令牌在第n个语言的来源。
是嵌入矩阵行向量包含令牌在第n个语言的来源。
如果像传统方式(Seq2Seqmodel)一样,线性生成每一个目标令牌,会忽略逻辑形式上的层次结构,Sqe2Tree模型采用了自顶向下生成逻辑形式的解码器,定义了一个“non-terminal”令牌来表示子树。在树的每个深度,逻辑 形式都是按顺序生成的,直到输出序列结束标记。
与单语情况不同,论文定义了一个共享解码,在计算解码器状态时加入父非终端信息,其中![]() 是LSTM方程):
是LSTM方程):
![]()
注意力机制:
![]()
其中U,V,W是权重矩阵。最终,模型被训练到使下面的条件似然函数最大:
![]()
其中(X,Y)表示训练集D中训练数据中的标注的句子-语义对。在这两种多语言设置(Single-Source Setting&Multi-Source Setting,下面介绍)中,我们对编码器和解码器使用上述相同的公式。每个设置的不同之处在于:(1)编码器状态的初始化,(2)上下文向量的计算,(3)训练过程。
Single-Source Setting
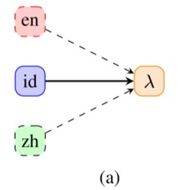
这种设置的输入为来自第n种语言的语句,如(a)所示,其中模型正在解析印度尼西亚输入,而英语和汉语处于非活跃状态。
先要把解码向量投影到一个适合解码的维度,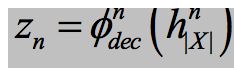 ,其
,其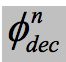 可以是一个仿射变换,类似的,可以在计算注意力分数之前做:
可以是一个仿射变换,类似的,可以在计算注意力分数之前做: ,然后计算上下文向量
,然后计算上下文向量![]() 为第n个编码器中隐藏向量的加权和。
为第n个编码器中隐藏向量的加权和。

把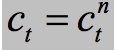 作为等式3中的计算,在这个设置中论文提出了两种变体
作为等式3中的计算,在这个设置中论文提出了两种变体
为每种语言定义独立的权值矩阵
三个权重矩阵为跨语言共享的,本质上减少了N倍的参数数量
训练数据是由N种语言的句子-语义对的组合组成的,其中源语句不一定是平行的。论文中实现一种调度机制,在训练 期间循环所有语言,但每次都只选择一种语言。模型参数在从一种语言进行批处理后更新,然后再转移到下一种语言。这种机制可以防止特定语言的过度更新。
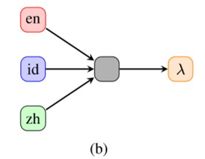
Multi-Source Setting
在这个情况下,输入是N种语言中语义等价的句子。图(b)描述了模型同时解析英语、印度尼西亚语和汉语的场景。灰 色模块是一个组合模块。
解码器初始状态由N个编码器的最终状态来确定,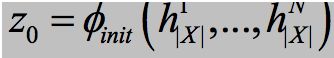 ,这里通过最大池来实现 \phi。论文中给出两种计算 c_t 的方式,集成多个编码器源端信息,首先考虑单词级组合,可以在每个一步时间步长对N进行编码,如下所示:
,这里通过最大池来实现 \phi。论文中给出两种计算 c_t 的方式,集成多个编码器源端信息,首先考虑单词级组合,可以在每个一步时间步长对N进行编码,如下所示:
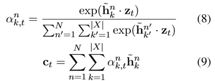
或者在句级组合中,首先用与等式(6)和(7)相同的方法计算每种语言的上下文向量。然后,我们对N个上下文向量进行简单的串联: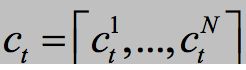
与单源情况不同,训练模型由路并行句子-语义组成。即每个训练实例由N个语义等价的句子及其对应的逻辑形式组成。
Experiment&Result
论文中在两个多语言基准数据集上进行了实验,数据集GEO是语义分析的标准基准评估,该多语言版本包含880个自 然语言查询实例,涉及四种语言(英语、德语、希腊语和泰国语)的美国地理事实( Jonesetal.,2012)。文中使用的标准分割包括600个训练示例和280个测试示例。ATIS数据集包含对飞行数据库的自然语言查询。
Result:
Table1比较了单语言Seq2Tree模型(SINGLE)和论文中的多语言模型(MULTI)在single-source setting下独立与共享参数(single-setting中的两种模型变体)的表现:
平均而言,多语言模型(论文中)的两种变体在GEO上的准确率比单语模型平均准确率高出1.34%,其中共享参数(第二种变体)表现得对GEO有帮助。结果发现在ATIS上的平均表现主要提升在中文和印尼语。还发现虽然包含进英语通常会对其他语言有帮助,但可能会影响他自身的表现。
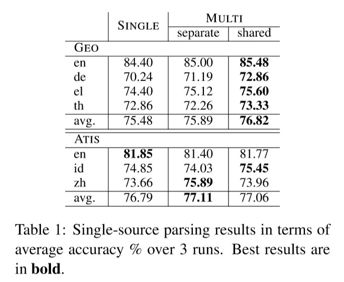
Table2展示了通过对GEO结合3到4种语言,针对ATIS结合2到3种语言的多源解析器的平均表现。对于排名(Ranking)实现,通过选择最高概率的值的方法来联合每个语言的预测结果。观察到模型级的系统组合能够比输出 级的平均性能更好(GEO上的平均性能高达4.29%)。在单词级和句子级组合在两个数据集上显示了相当的性能。可以 看出,当在系统组合中加入英语时,这种优势更加明显。

Analysis
对多语言模型的定性分析。Table3显示了使用ATIS中的三种语言训练单语模型(SINGLE)和使用句子级组合的多语模型(MULTI)的例子。例子展示了多语言模型成功解析3个输入句子到正确的逻辑形式,然而单个的模型无法做到。

Figure2显示了在解析多源设置(MULTI)的ATIS时生成的对齐。对齐矩阵中的每一个单元对应 ![]() (由等式6计算得到)。语义相关的词被对齐如: ground (en), darat (id), 地面 (zh) 和 ground transport。这说明该模型可以共同学习这些对应关系。
(由等式6计算得到)。语义相关的词被对齐如: ground (en), darat (id), 地面 (zh) 和 ground transport。这说明该模型可以共同学习这些对应关系。
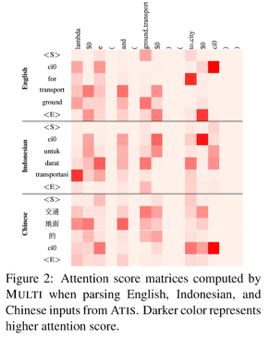
Table4总结了基线和多语言模型中的参数数量,单语(SINGLE)和排序(RANKING)中的参数个数等于单语成分中参数个数的和。可以看出,多语言模型的参数比基线小50-60%左右。

Conclusion
论文提出了一种多语言语义分析器,将Seq2Tree模型拓展到一个多任务学习框架。通过实验发现多语言模型在平均 表现上优于1.单语模型在单源设置(single-source setting)下的表现2. 综合排名(Ranking)在多源设置(multi- source)下的表现。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。