爬虫——Python 爬取51job 职位信息
既然要爬取职位信息,那么首先要弄清楚目标页面的分布规律。
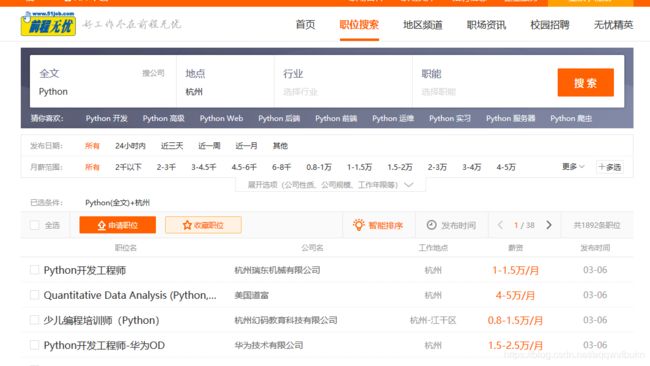
输入职位关键词和相应的地点等条件,然后搜索就可以看到岗位信息。
首先通过翻页来查看url的变化,以此来找到翻页时url的规律
把前面几页的url 复制下来放到文本文档里对比

不难发现除了页码外其他都没有改变
下面开始代码
# 导入相应的包
#-*-coding:utf-8-*-
from bs4 import BeautifulSoup
import requests
import chardet
from lxml import etree
编写一个函数来获取每页的 html 信息
def get_content(page): # 获取每页全部 html信息
# 爬取的页面 url
url='https://search.51job.com/list/080200,000000,0000,00,9,99,Python,2,'+str(page)+'.html?lang=c&stype=1&postchannel\
=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='
# 设置代理信息
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'}
# requests 获取页面信息
rqg=requests.get(url,headers=headers)
# 字符转码
rqg.encoding=chardet.detect(rqg.content)['encoding']
rqg.encoding="iso-8859-1"
html=rqg.content.decode('iso-8859-1').encode('iso-8859-1')
soup=BeautifulSoup(html,'lxml')
soup.prettify() #格式化soup对象
return soup # 返回soup对象
接下来设置列表以存储相应的数据
Name=[] # 初步存储职位名称信息(有 \n\n 的)
Name1=[] # 存储最终的职位名称
Company=[] # 公司名称
Location=[] # 工作地点
Salary=[] # 薪资
Published=[] # 发布时间
从每页数据中提取我们需要的部分
for i in range(1,11): # 循环爬取每页数据 (这里爬取1~10页)
soup=get_content(i)
#名称
name=soup.find_all('p',class_="t1") # 用 find_all 方法搜索所有 class为t1 的 p 对象
for n in name:
Name.append(n.get_text()) # 提取文本度追加到 Name 列表中
### 以下代码注释类似 #######
company=soup.find_all('span',class_="t2")
for i in company:
Company.append(i.get_text())
location=soup.find_all('span',class_="t3")
for i in location:
Location.append(i.get_text())
salary=soup.find_all('span',class_="t4")
for i in salary:
Salary.append(i.get_text())
published=soup.find_all('span',class_="t5")
for i in published:
Published.append(i.get_text())
for a in Name:
Name1.append(a.strip()) # 提取 Name 中的职位名称
Name1.insert(0,'职位') # Name1 列表中插入“职位” 以保证数据对应
岗位数据已经存储到相应的列表 中,下面把它存储到csv文件中
(这里用pandas来把数据写入csv文件)
import pandas as pd
# 将获取到的数据保存到 csv 文件
df=pd.DataFrame(list(zip(Name1,Company,Location,Salary,Published)))
outputfile='C:/Users/AQQWVFBUKN/Desktop/51job.csv'
df.to_csv(outputfile,index=False,encoding='utf_8_sig',header=False)
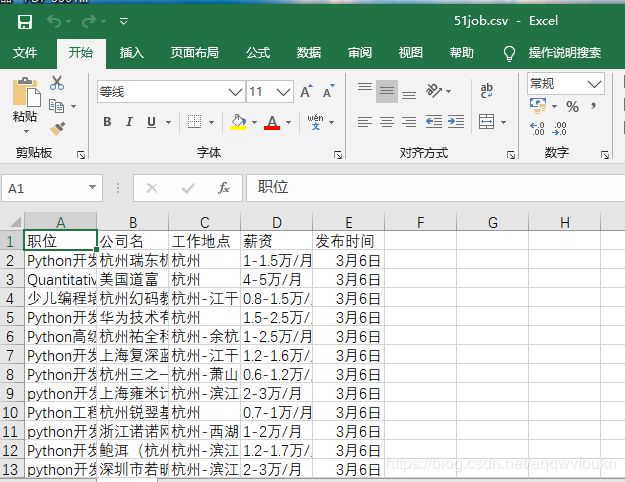
存储到csv后:
######### 以下附上完整代码
#-*-coding:utf-8-*-
from bs4 import BeautifulSoup
import requests
import chardet
from lxml import etree
def get_content(page): # 获取每页全部 html信息
# 爬取的页面 url
url='https://search.51job.com/list/080200,000000,0000,00,9,99,Python,2,'+str(page)+'.html?lang=c&stype=1&postchannel\
=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='
# 设置代理信息
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'}
rqg=requests.get(url,headers=headers)
# 字符转码
rqg.encoding=chardet.detect(rqg.content)['encoding']
rqg.encoding="iso-8859-1"
html=rqg.content.decode('iso-8859-1').encode('iso-8859-1')
soup=BeautifulSoup(html,'lxml')
soup.prettify() #格式化soup对象
return soup
Name=[] # 初步存储职位名称信息(有 \n\n 的)
Name1=[] # 存储最终的职位名称
Company=[] # 公司名称
Location=[] # 工作地点
Salary=[] # 薪资
Published=[] # 发布时间
for i in range(1,11): # 循环爬取每页数据
soup=get_content(i)
#名称
name=soup.find_all('p',class_="t1") # 用 find_all 方法搜索所有 class为t1 的 p 对象
for n in name:
Name.append(n.get_text()) # 提取文本度追加到 Name 列表中
### 以下代码注释类似 #######
company=soup.find_all('span',class_="t2")
for i in company:
Company.append(i.get_text())
location=soup.find_all('span',class_="t3")
for i in location:
Location.append(i.get_text())
salary=soup.find_all('span',class_="t4")
for i in salary:
Salary.append(i.get_text())
published=soup.find_all('span',class_="t5")
for i in published:
Published.append(i.get_text())
for a in Name:
Name1.append(a.strip()) # 提取 Name 中的职位名称
Name1.insert(0,'职位') # Name1 列表中插入“职位” 以保证数据对应
Name=[] # 初步存储职位名称信息(有 \n\n 的)
Name1=[] # 存储最终的职位名称
Company=[] # 公司名称
Location=[] # 工作地点
Salary=[] # 薪资
Published=[] # 发布时间
for i in range(1,11): # 循环爬取每页数据
soup=get_content(i)
#名称
name=soup.find_all('p',class_="t1") # 用 find_all 方法搜索所有 class为t1 的 p 对象
for n in name:
Name.append(n.get_text()) # 提取文本度追加到 Name 列表中
### 以下代码注释类似 #######
company=soup.find_all('span',class_="t2")
for i in company:
Company.append(i.get_text())
location=soup.find_all('span',class_="t3")
for i in location:
Location.append(i.get_text())
salary=soup.find_all('span',class_="t4")
for i in salary:
Salary.append(i.get_text())
published=soup.find_all('span',class_="t5")
for i in published:
Published.append(i.get_text())
for a in Name:
Name1.append(a.strip()) # 提取 Name 中的职位名称
Name1.insert(0,'职位') # Name1 列表中插入“职位” 以保证数据对应
import pandas as pd
# 将获取到的数据保存到 csv 文件
df=pd.DataFrame(list(zip(Name1,Company,Location,Salary,Published)))
outputfile='C:/Users/AQQWVFBUKN/Desktop/51job.csv'
df.to_csv(outputfile,index=False,encoding='utf_8_sig',header=False)