深入浅出系列Hbase之架构及读写流程
Hbase架构设计
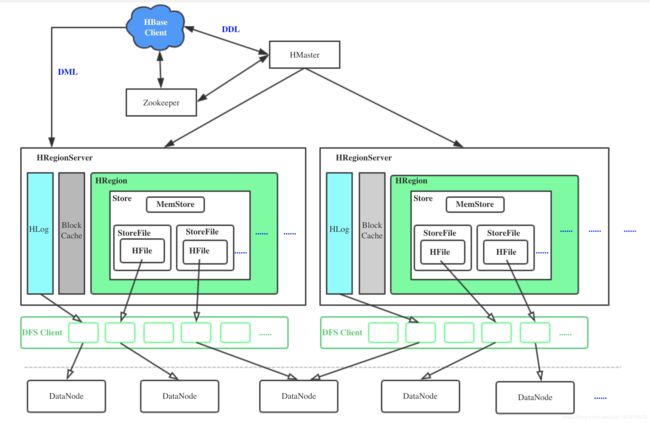
HMaster
- 负责HBASE table和Region的元数据管理,包含表的创建、修改等
- 维护整个集群的负载均衡
- 为RegionServer分配Region
- 发现失效的region,并将失效的region分配到正常的RegionServer
- 当RegionServer失效时,协调对应Hlog的拆分
HRegionServer
- 负责数据的路由,数据的读写和持久化
- 是HBase的数据处理及计算的单元
- 管理master为其分配的region
- 和底层HDFS进行数据存储的交互
- Region变大以后的拆分以及StoreFile的合并
- regionserver要和DN一起部署
hregionserver内部管理了一系列的hregion对象,每个hregion对应table的一个region。hregion是多个store组成,是通过CF划分的,则是一个store管理一个region上的一个CF。每个store是包含 1个memstore 0个或多个storefile组成。
Zookeeper
- 存储meta表的地址,而不是内容!
- RegionServer主动向ZK注册,使得master可随时感知各个rs的健康状态
- 避免master的单点故障(SPOF)
HbaseClient
- RPC机制
- client和master进行ddl管理类通信 和rs进行数据的dml操作类通信
Hlog
预写日志
MemStore
写缓存
StoreFile
storefiles 合并后逐步形成越来越大的storefile文件,
当region内所有的storefile(hfile)的总大小超过 hbase.hregion.max.filesize触发split,一个region变为2个。 父region下线,新的split的2个region被hmaster分配到合适的rs机器上。
使得原先1个region的压力分流到2个region上。
BlockCache
读缓存,是rs级别 ,一个rs只有一个blockcache ,在rs启动时 完成blockcache的初始化工作。
Meta表
首先说明存储位置是记录在zookeeper上的。
hbase(main):026:0> scan 'hbase:meta'
ROW COLUMN+CELL
hbase:namespace,,159 column=info:regioninfo, timestamp=1590821040270, value={ENC
0821039635.0be1ccc4d ODED => 0be1ccc4de45f61db028e2081d5d673b, NAME => 'hbase:na
e45f61db028e2081d5d6 mespace,,1590821039635.0be1ccc4de45f61db028e2081d5d673b.',
73b. STARTKEY => '', ENDKEY => ''}
hbase:namespace,,159 column=info:seqnumDuringOpen, timestamp=1590821040270, valu
0821039635.0be1ccc4d e=\x00\x00\x00\x00\x00\x00\x00\x02
e45f61db028e2081d5d6
73b.
hbase:namespace,,159 column=info:server, timestamp=1590821040270, value=xxx:60020
0821039635.0be1ccc4d
e45f61db028e2081d5d6
73b.
hbase:namespace,,159 column=info:serverstartcode, timestamp=1590821040270, value
0821039635.0be1ccc4d =1590821031895
e45f61db028e2081d5d6
73b.
xxx:orderinfo, column=info:regioninfo, timestamp=1590827295617, value={ENC
,1590826706747.2ce50 ODED => 2ce500c927ace1d96d365f4bdb3930c3, NAME =>
0c927ace1d96d365f4bd 'xxx:orderinfo,,1590826706747.2ce500c927ace1d96d365f4bdb3930c3
xxx:orderinfo,,15908 b3930c3. ', STARTKEY => '', ENDKEY => ''}
26706747.2ce500c927a column=info:seqnumDuringOpen, timestamp=1590827295617,
ce1d96d365f4bdb3930c value=\x00\x00\x00\x00\x00\x00\x00\x11
3.
xxx:orderinfo,,15908 column=info:server, timestamp=1590827295617, value=xxx:60020
26706747.2ce500c927a
ce1d96d365f4bdb3930c
3.
xxx:orderinfo,,15908 column=info:serverstartcode, timestamp=1590827295617, value
26706747.2ce500c927a =1590821031895
ce1d96d365f4bdb3930c3.
2 row(s) in 0.0260 seconds
hbase(main):027:0> 通过上面两行的元数据信息,我们可以知道:
rowkey组成: ns:table,region start key,region id
region start key: 是region的第一个rowkey,这里需要注意
a.这个地方为空,就表明table是第一个region,并且这个region的start key end key 都是空,说明这个表只有一个region
b.在meta表,start key 靠前的region 会排在start key靠后的region的前面。
hbase的key是按照字段的顺序来存放的 字典排序region id: 是region创建的时候的timestamp+.+region id
value组成:regioninfo 包含 start key end key
server 是分配在哪个rs节点上
写流程
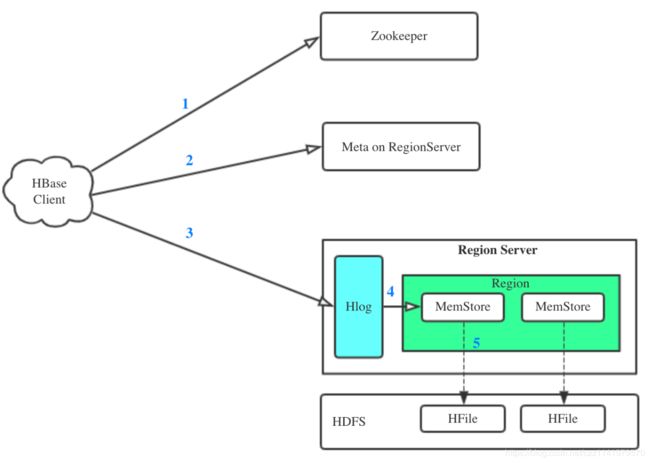
1、client先去zk获取hbase:meta表所在的rs节点,在hbase:meta表根据rk确定所在的目标rs节点和region
2、hbase client将写的请求进行预处理,并根据元数据写入所在的rs节点;将请求发送给对应的rs,rs接收到写的请求将数据进行解析:
先写wal-->再写对应的region的store的memstore,当memstore达到阈值,会异步的flush,将内存的数据写入HFile文件注意: memstore是一个内存结构 是一个CF只有1个memstore,其中memstore里面的数据也是对rk进行字典排序的
hbase是采取LSM树架构,【天生的适合重写轻读的场景】
注意:
对hbase来说 put(更新)、delete操作,在服务端看来 都是写操作。
put更新 是写一条 最新版本数据
delete 是写一条标记为deleted的kv的数据
读流程
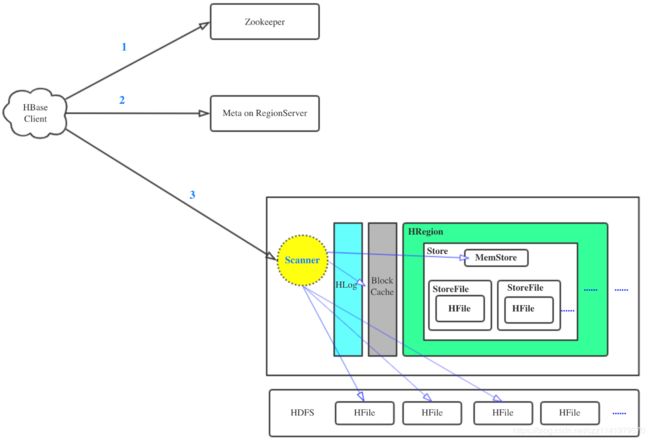
a.先去zk获取hbase:meta表所在的rs节点,在hbase:meta表根据读rk确定所在的目标rs节点和region
b.将读请求封装,发送给目标的rs节点,进行处理。
先到memstore查数据,查不到再去blockcache查,再查不到就访问磁盘的HFile读数据。