Hyperledger Fabric 1.3 官方文档翻译(三)关键概念 (Key Concepts) - 3.8 私有数据 (Private data)
私有数据(Private data)
什么是私有数据(What is private data)?
In cases where a group of organizations on a channel need to keep data private from other organizations on that channel, they have the option to create a new channel comprising just the organizations who need access to the data. However, creating separate channels in each of these cases creates additional administrative overhead (maintaining chaincode versions, policies, MSPs, etc), and doesn’t allow for use cases in which you want all channel participants to see a transaction while keeping a portion of the data private.
如果某个通道上的一组组织需要将该数据与该通道上的其他组织保密,他们可以选择创建一个新通道,该通道仅包含需要访问那些数据的组织。 但是,在每种情况下创建单独的通道会产生额外的管理开销(维护链代码版本、策略、MSP等),并且你让所有通道参与者在查看交易的同时保留部分数据私有也是不允许的。
That’s why, starting in v1.2, Fabric offers the ability to create private data collections, which allow a defined subset of organizations on a channel the ability to endorse, commit, or query private data without having to create a separate channel.
这就是为什么,从v1.2开始,Fabric提供了创建私有数据集合的能力,它允许通道上定义的组织子集能够背书、提交或查询私有数据,而无需创建单独的数据通道。
什么是私有数据集合(What is a private data collection)?
A collection is the combination of two elements:
集合是两个元素的组合:
- The actual private data, sent peer-to-peer via gossip protocol to only the organization(s) authorized to see it. This data is stored in a private database on the peer (sometimes called a “side” database, or “SideDB”). The ordering service is not involved here and does not see the private data. Note that setting up gossip requires setting up anchor peers in order to bootstrap cross-organization communication.
实际私有数据,通过流言协议点对点发送给只有授权的组织看到它。 此数据存储在对等节点的私有数据库中(有时称为“旁”数据库或“SideDB”)。 排序服务不涉及这里,也不能看到私有数据。 请注意,设置流言需要设置主播对等节点,以便引导跨组织的通信。 - A hash of that data, which is endorsed, ordered, and written to the ledgers of every peer on the channel. The hash serves as evidence of the transaction and is used for state validation and can be used for audit purposes.
该数据的哈希,它被背书、排序并写入通道上每个对等节点账本。 哈希用作交易的证据,用于状态验证,可用于审计目的。
The following diagram illustrates the ledger contents of a peer authorized to have private data and one which is not.
下图说明了授权拥有私有数据的对等节点的帐本内容,以及未拥有私有数据的对等节点的帐本内容。
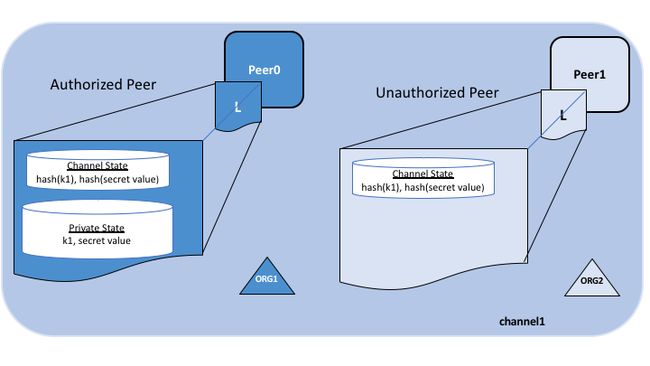
Collection members may decide to share the private data with other parties if they get into a dispute or if they want to transfer the asset to a third party. The third party can then compute the hash of the private data and see if it matches the state on the channel ledger, proving that the state existed between the collection members at a certain point in time.
如果成员集合遇到争议或者想要将资产转移给第三方,他们可以决定与其他方共享私人数据。 然后,第三方可以计算私有数据的hash,并查看它是否与通道帐本上的状态匹配,从而证明在某个时间点成员集合之间存在状态。
何时使用通道内的集合鬼还是单独的通道(When to use a collection within a channel vs. a separate channel)
- Use channels when entire transactions (and ledgers) must be kept confidential within a set of organizations that are members of the channel.
当整个交易(和账本)必须在作为通道成员的一组组织内保密时,使用通道。 - Use collections when transactions (and ledgers) must be shared among a set of organizations, but when only a subset of those organizations should have access to some (or all) of the data within a transaction. Additionally, since private data is disseminated peer-to-peer rather than via blocks, use private data collections when transaction data must be kept confidential from ordering service nodes.
当必须在一组组织之间共享交易(和帐本)时,但是当这些组织中只有一部分可以访问交易中的某些(或所有)数据时,使用集合。 此外,由于私有数据是通过点对点而不是通过区块传播的,因此当交易数据必须对排序服务节点保密时,请使用私有数据集合。
私有数据交易流程(Transaction flow with private data)
When private data collections are referenced in chaincode, the transaction flow is slightly different in order to protect the confidentiality of the private data as transactions are proposed, endorsed, and committed to the ledger.
当在链代码中引用私有数据集合时,交易流程略有不同,以便在交易提议、背书和提交到帐本时保护私有数据的机密性。
For details on transaction flows that don’t use private data refer to our documentation on transaction flow.
有关不使用私有数据的交易流程的详细信息,请参阅有关交易流程的文档。
-
The client application submits a proposal request to invoke a chaincode function (reading or writing private data) to endorsing peers which are part of authorized organizations of the collection. The private data, or data used to generate private data in chaincode, is sent in a
transientfield of the proposal.
客户端应用程序向作为集合的这部分组织的背书节点提交提议请求调用链代码功能(读取或写入私有数据)。私有数据或用于在链代码中生成私有数据的数据在提议的transient(临时)字段中发送。 -
The endorsing peers simulate the transaction and store the private data in a
transient data store(a temporary storage local to the peer). They distribute the private data, based on the collection policy, to authorized peers via gossip.
背书节点模拟交易并将私有数据存储在transient data store(对等体本地的临时存储)中。他们通过gossip将基于集合策略的私有数据分发给授权的对等节点。 -
The endorsing peer sends the proposal response back to the client with public data, including a hash of the private data key and value. No private data is sent back to the client. For more information on how endorsement works with private data, click here.
背书节点使用公共数据将提议响应发送回客户端,包括私有数据密钥和值的哈希值。没有私有数据被发送回客户端。有关如何背书私人数据的更多信息,请单击此处。 -
The client application submits the transaction to the ordering service (with hashes of the private data) which gets distributed into blocks as normal. The block with the hashed values is distributed to all the peers. In this way, all peers on the channel can validate transactions with the hashes of the private data in a consistent way, without knowing the actual private data.
客户端应用程序将交易提交给排序服务(具有私有数据的哈希值),该服务正常地将交易分配到区块中。具有哈希值的区块被分发给所有对等节点。通过这种方式,通道上的所有对等节点都可以以一致的方式验证具有私有数据哈希值的交易,而无需知道实际的私有数据。 -
At block-committal time, authorized peers use the collection policy to determine if they are authorized to have access to the private data. If they do, they will first check their local
transient data storeto determine if they have already received the private data at chaincode endorsement time. If not, they will attempt to pull the private data from another peer. Then they will validate the private data against the hashes in the public block and commit the transaction and the block. Upon validation/commit, the private data is moved to their copy of the private state database and private writeset storage. The private data is then deleted from thetransient data store.
在区块提交时,授权的对等节点使用集合策略来确定它们是否有权访问私有数据。如果他们这样做,他们将首先检查他们的本地transient data store,以确定他们是否已经在链代码背书时收到私有数据。如果没有,他们将尝试从另一个对等节点提取私有数据。然后,他们将针对公开区块中的哈希值验证私有数据,并提交交易和区块。验证/提交后,私有数据将移动到其私有状态数据库和私有写入存储的副本。然后从transient data store中删除私有数据。
解释集合的用例(A use case to explain collections)
Consider a group of five organizations on a channel who trade produce:
考虑交易产品的通道中的五个组织:
- A Farmer selling his goods abroad
农民在国外销售他的商品 - A Distributor moving goods abroad
分销商将货物运往国外 - A Shipper moving goods between parties
托运人在各方之间移动货物 - A Wholesaler purchasing goods from distributors
批发商从经销商处购买商品 - A Retailer purchasing goods from shippers and wholesalers
零售商从托运人和批发商处购买商品
The Distributor might want to make private transactions with the Farmer and Shipper to keep the terms of the trades confidential from the Wholesaler and the Retailer (so as not to expose the markup they’re charging).
分销商可能希望与农民和托运人进行私人交易,以保证交易条款对批发商和零售商保密(所以不要暴露他们收费的标记。
The Distributor may also want to have a separate private data relationship with the Wholesaler because it charges them a lower price than it does the Retailer.
分销商也可能希望与批发商有单独的私有数据关系,因为它收取的价格低于零售商。
The Wholesaler may also want to have a private data relationship with the Retailer and the Shipper.
批发商也可能希望与零售商和托运人建立私人数据关系。
Rather than defining many small channels for each of these relationships, multiple private data collections (PDC) can be defined to share private data between:
不是为这些关系中的每一个定义许多小通道,而是可以定义多个私有数据集合(** PDC **)以在以下各项之间共享私有数据:
- PDC1: Distributor, Farmer and Shipper
PDC1:分销商,农民和托运人 - PDC2: Distributor and Wholesaler
PDC2:分销商和批发商 - PDC3: Wholesaler, Retailer and Shipper
PDC3:批发商,零售商和托运人
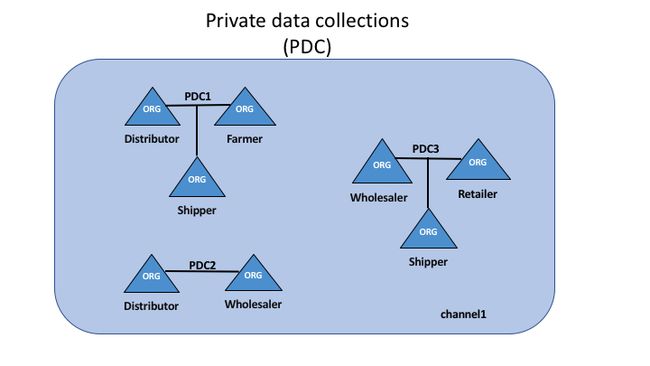
Using this example, peers owned by the Distributor will have multiple private databases inside their ledger which includes the private data from the Distributor, Farmer and Shipper relationship and the Distributor and Wholesaler relationship. Because these databases are kept separate from the database that holds the channel ledger, private data is sometimes referred to as “SideDB”.
使用此示例,分销商拥有的对等节点将在其分类帐内部拥有多个私有数据库,其中包括来自分销商,农民和托运人关系的私有数据以及分销商和批发商的关系。 由于这些数据库与保存通道帐本的数据库保持独立,因此私有数据有时称为“SideDB”(旁数据)。
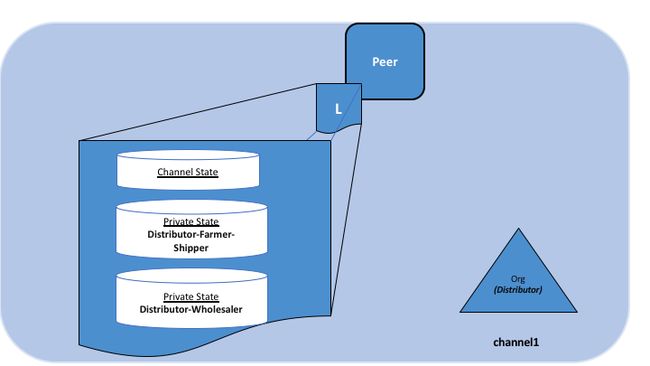
如何定义私有数据集合(How a private data collection is defined)
For more details on collection definitions, and other low level information about private data and collections, refer to the private data reference topic.
有关集合定义以及有关私有数据和集合的其他详细信息的更多细节,请参阅私有数据参考主题。
清除数据(Purging data)
For very sensitive data, even the parties sharing the private data might want — or might be required by government regulations — to “purge” the data stored on their peers after a set amount of time, leaving behind only a hash of the data to serve as immutable evidence of the transaction.
对于非常敏感的数据,甚至共享私有数据的各方可能希望 - 或者可能是政府法规要求 - 在一段时间后“清除”存储在其对等节点上的数据,只留下数据的哈希值作为交易的不可改变的证据。
In some of these cases, the private data only needs to exist on the peer’s private database until it can be replicated into a database external to the blockchain network. The data might also only need to exist on the peers until a chaincode business process is done with it (trade settled, contract fulfilled, etc). To support the later use case, it is possible to purge private data if it has not been modified once a set number of subsequent blocks have been added to the private database.在这些情况下,私有数据只需要存在于对等节点的私有数据库中,直到它可以复制到区块链网络外部的数据库中。 数据可能也只需要存在于对等节点上,直到用它完成链代码业务流程(交易结算,合同履行等)。 为了支持后面的用例,一旦将一定数量的后续区块添加到私有数据库中,就可以清除私有数据。