电信用户分析
变量说明
Customer_ID:用户编号
Gender:性别
Age:年龄
L_O_S:在网时长
Tariff:话费类型/话费方案
Handset:手机品牌
Peak_calls:高峰时期电话数
Peak_mins:高峰时期电话时长
OffPeak_calls:低谷时期电话数
OffPeak_mins:低谷时期电话时长
Weekend_calls:周末电话数
Weekend_mins:周末电话时长
International_mins:国际电话时长
Nat_call_cost:国内电话费用
month:月份
背景与目标
运营商能够将客户很好地进行分层是为客户推出差异化的服务的基础,好的用户分析也是提升用户体验的前提。本文通过分析电信客户的相关数据(客户信息与客户通话数据),以期(1)了解客户特征,(2)并通过Kmeans聚类分析对客户进行聚类。
导入数据
import pandas as pd
# 导入数据
# 用户电话情况
custcall = pd.read_csv('C:\\Users\\lin\\Desktop\\custcall.csv',sep = ',')
# 用户信息
custinfo = pd.read_csv('C:\\Users\\lin\\Desktop\\custinfo.csv',sep = ',')
查看数据
print(custcall.shape)
custcall.head()
返回结果:
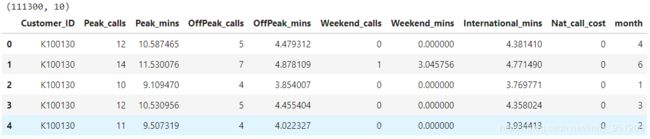
print(custinfo.shape)
custinfo.head()
返回结果:
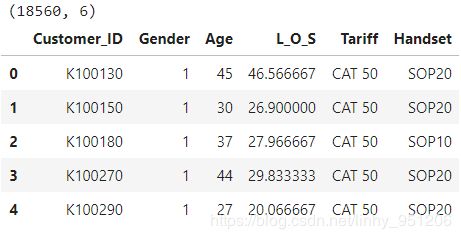
1 数据清洗与整理
# 求每个用户各指标的平均值
custcall_avg = custcall.groupby(by = ['Customer_ID']).mean()
# month 的均值为同一值,故剔除 ‘month’
del custcall_avg['month']
# 合并数据集
cust = pd.merge(custinfo,custcall_avg,left_on = 'Customer_ID',right_index = True,how = 'inner')
# 查看Customer_ID是否有重复值
print(cust['Customer_ID'].duplicated().sum())
# 将Customer_ID设为索引
cust = cust.set_index(keys = ['Customer_ID'])
cust.head()
返回结果:

# 查看cust的形状并将其导出
print(cust.shape)
print(cust.columns.to_list())
cust.to_excel('C:\\Users\\林\\Desktop\\cust.xlsx')

2 可视化分析
2.1 单变量——分类变量分布
将cust导入到Tableau中,分别绘制手机品牌、性别以及套餐的分布情况
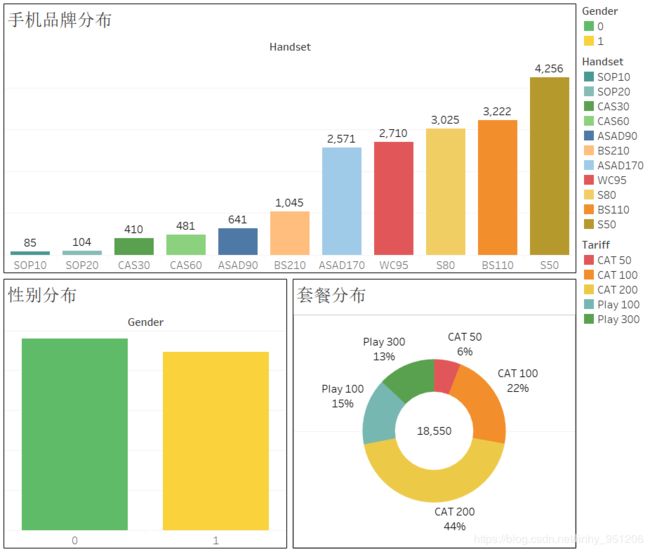
从上图可知:
- 最受欢迎的5种手机品牌分别为:S50、BS110、S80、WC95和ASAD170;
- 电信的用户群体中,男女比例较均衡,没有显著差异;
- 从套餐角度看,CAT 200 套餐用户使用量最多,占全部样本的44%,其次为 CAT 100,占比为22%。
2.2 单变量——连续变量分布
# 查看连续变量的分布
import matplotlib.pyplot as plt
import seaborn as sns
for i in cust.columns:
if i not in ['Gender','Tariff','Handset','Peak_mins_bin','Peak_calls_bin']:
plt.figure()
sns.distplot(cust[i],bins=10,hist_kws=dict(edgecolor='k'),kde=True)
plt.show()
返回结果:
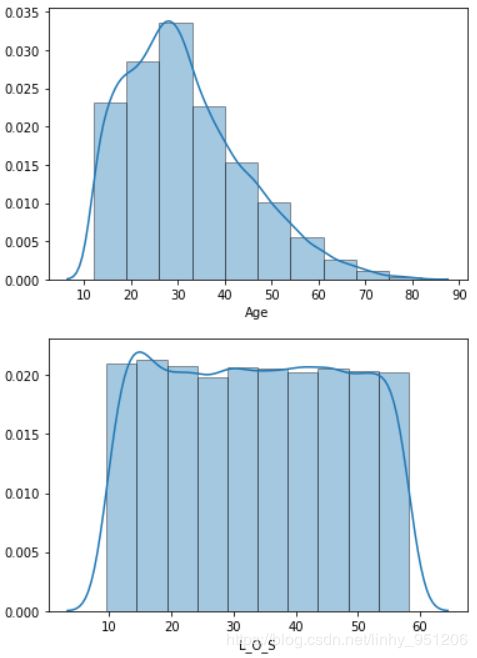
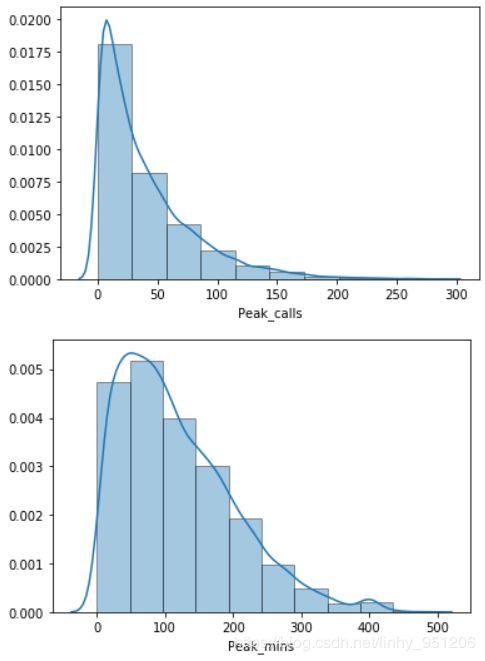
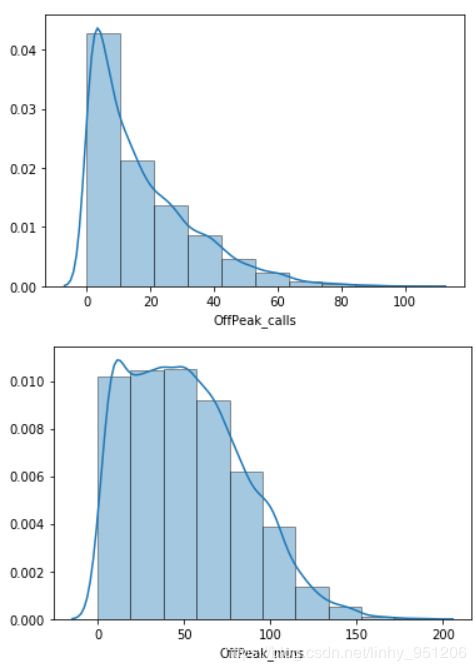
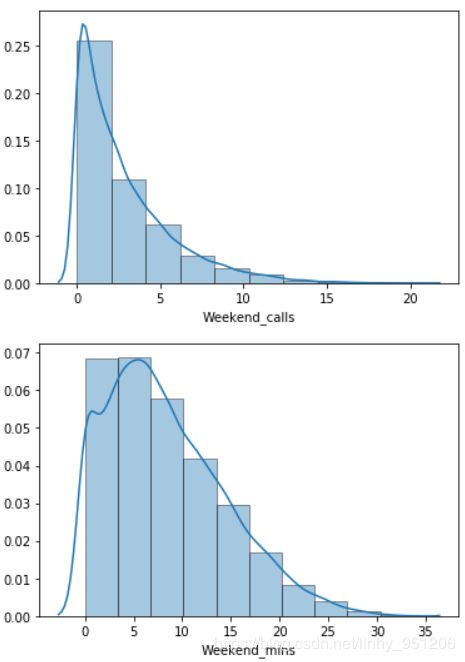
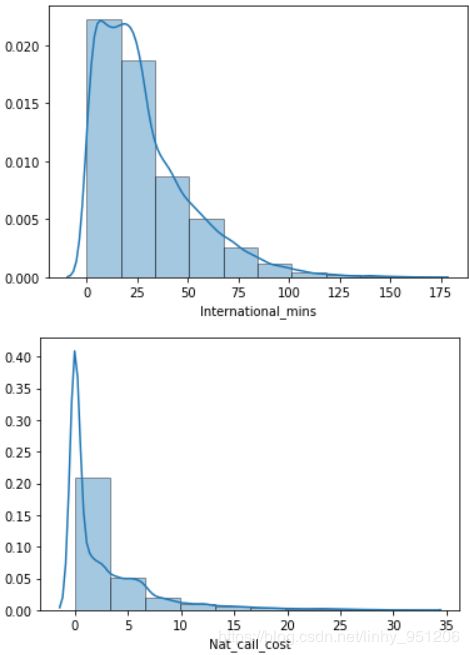
从各连续变量的分布中可以看出:
- 电信用户中,老年人占比少且用户趋向于少龄化。这与现实情况相符,随着互联网与经济、科技的发展,个体接触电子产品的年龄越来越小;
- 用户在网时长分布均匀,没有明显的趋势;
- 其余连续变量如:高峰时期电话数、电话时长,低谷时期电话数、电话时长等都呈现偏态分布,且全部右偏,即存在少量的头部用户消费较高。
2.3 双变量——套餐选择
这一部分分别绘制了:
(1)使用各套餐用户的平均年龄、平均高峰电话数通话时间长、平均低谷电话数及通话时长、平均国际通话时长以及平均国内话费数;
(2)使用某套餐、某品牌手机的用户数;
(3)使用某套餐的性别分布。
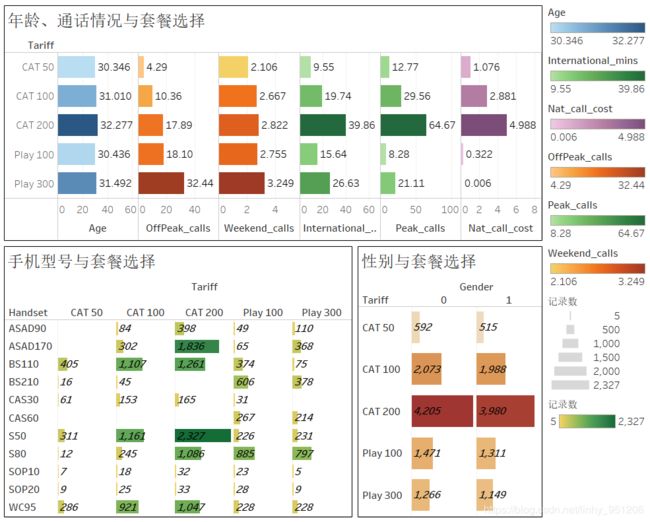
由上图可以得出这样的一些结论:
- 使用各套餐的用户平均年龄相差无几,则很可能在每个套餐中,用户年龄的分布是类似的。换句话说:各年龄段用户对套餐的偏好是类似的。为验证这一点,在Tableau中对年龄进行分桶,计算各年龄段使用各套餐的用户数,并对其进行可视化,如下图所示:
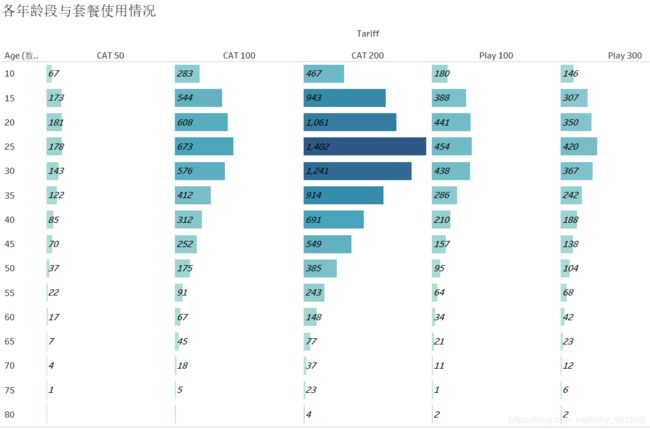
从图中可以看到,无论是哪个年龄段,用户都更偏好套餐CAT 200,且在各套餐情况下,用户的年龄分布是类似的(与总样本中的年龄分布类似),这表明年龄不是套餐选择的影响因素。 - 平均国际通话时间、平均高峰期电话数和平均国内电话费用在套餐CAT 200组别中最大,且平均国际通话时间、平均高峰期电话数和平均国内电话费用在套餐维度上的分布是相似的,即这三者之间很有可能正相关;
- 性别对套餐选择的影响不显著;
- 手机型号对套餐选择的影响不是特别清晰。
2.4 双变量——影响国内电话费用的因素
在2.3节的分析中,猜想国际通话时长、高峰期电话数以及国内电话费用之间可能正相关,为验证这一猜想,这一部分将高峰时期电话次数与国际电话时长分桶,计算这两个维度上的每一个区间的平均国内电话费用,并利用Tableau进行可视化,得到如下图结果(下图上半部分);在这一部分还绘制了手机品牌、套餐与电话费用之间的气泡图。
#数据分桶的代码
# 计算高峰时期电话数与平均国内电话费用,并将数据导出
cust['Peak_calls_bin'] = pd.cut(cust['Peak_calls'],bins = 50)
test = cust.groupby('Peak_calls_bin')['Nat_call_cost'].mean().reset_index()
test.to_excel('C:\\Users\\lin\\Desktop\\Peak_calls_bin.xlsx')
# 计算国际电话时长与平均国内电话费用,并将数据导出
cust['International_mins_bin'] = pd.cut(cust['International_mins'],bins = 50)
test1 = cust.groupby('International_mins_bin')['Nat_call_cost'].mean().reset_index()
test1.to_excel('C:\\Users\\lin\\Desktop\\International_mins_bin.xlsx')
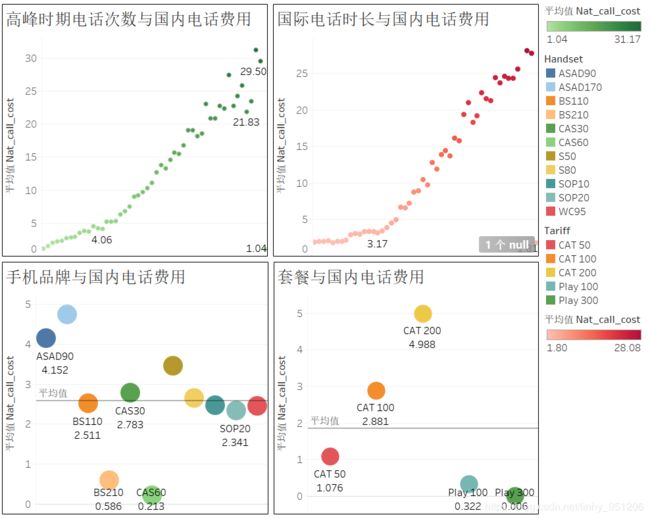
上图对数据的可视化可以得出以下结论:
- 高峰时期电话数、国际通话时长与国内电话费用之间都存在很明显的正相关关系:随着高峰期电话数与国际电话时长的增加,国内电话费用也在增加;
- 使用手机品牌为ASAD90 与ASAD170以及S50的用户国内电话费用超过了国内电话费用的均值,即手机品牌为ASAD90 与ASAD170以及S50的用户相较于其他品牌手机的用户为电信带来更多的收入;
- 套餐为CAT 200 和CAT 100的用户国内电话费用超过了国内电话费用均值,即采用套餐CAT 200 和CAT 100的用户为电信带来了更多的收入;
2.5 矩阵分析
2.4节中关于手机品牌、套餐与国内电话费用之间的分析得到这样的结论:(1)手机品牌为ASAD90 与ASAD170以及S50的用户相较于其他品牌手机的用户为电信带来更多的收入;(2)采用套餐CAT200 和CAT100的用户为电信带来了更多的收入。为了判断这两个结论是否稳健,这一部分对手机品牌与套餐进行了矩阵分析。
2.5.1 手机品牌矩阵分析
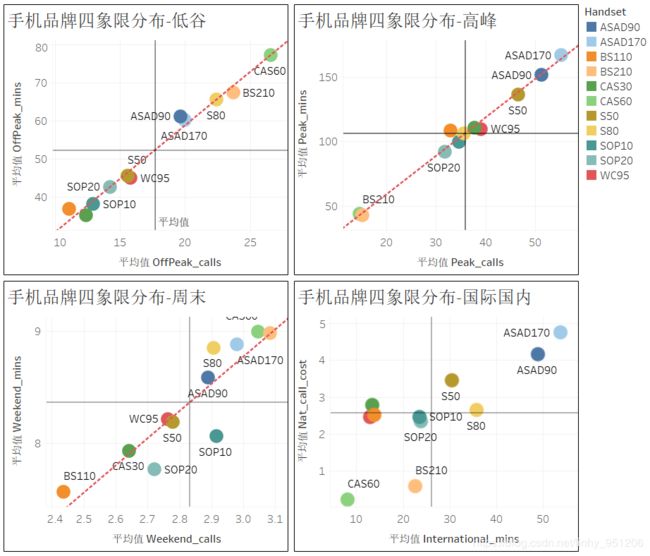
关于手机品牌的矩阵分析可知:
- 手机品牌为ASAD90 与ASAD170的用户,始终处于第一象限。这表明无论是在低谷期还是高峰期,亦或是周末,手机品牌为ASAD90 与ASAD170的用户的电话数与通话时长都超过了平均值;且手机品牌为ASAD90 与ASAD 170的用户的国际通话时长与国内电话费用也都高于平均值;
- 手机品牌为S50的用户在低谷时期、周末通话数与通话时长都低于均值,而在高峰期是通话数与通话时长高于均值,且手机品牌为S50 的用户的国内电话费用与国际通话时长都高于均值。这表明手机品牌为S50的用户属于相对活跃的用户(在低谷期与周末不活跃);
- 从手机品牌矩阵分析中还发现:手机品牌为CAS60和BS210的用户在低谷时期和周末较为活跃,但是这部分用户的国内电话费用却低于平均值;
- 结合手机品牌为S50在高峰时期较为活跃,且其国内电话费用高于均值,而CAS60和BS210在低谷期与周末较为活跃,且其国内电话费用低于均值这一事实,可以剔除这样的猜想:对于电信而言,在高峰期活跃的用户为高价值用户,而在低谷期与周末活跃的用户为低价值用户。换句话讲:高峰期电话数与电话时长与电话费用正相关(2.4中已用可视化证明),低谷期与周末的电话数与电话时长不会给电话费用带来很大影响。为证明这一点,用与2.4类似方法处理数据,并对数据进行可视化,得到下图:
# 计算低谷时期电话数与平均国内电话费用,并将数据导出
cust['OffPeak_calls_bin'] = pd.cut(cust['OffPeak_calls'],bins = 50)
test3 = cust.groupby('OffPeak_calls_bin')['Nat_call_cost'].mean().reset_index()
test3.to_excel('C:\\Users\\lin\\Desktop\\OffPeak_calls_bin.xlsx')
# 计算周末电话数与平均国内电话费用,并将数据导出
cust['Weekend_calls_bin'] = pd.cut(cust['Weekend_calls'],bins = 50)
test4 = cust.groupby('Weekend_calls_bin')['Nat_call_cost'].mean().reset_index()
test4.to_excel('C:\\Users\\lin\\Desktop\\Weekend_calls_bin.xlsx')
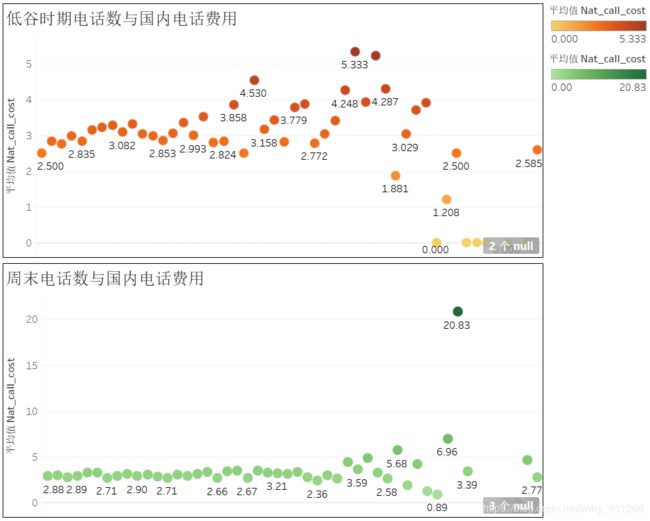
由上图可知,用户低谷期与周末的通话数、通话时长与电话费用之间没有明确的正相关关系;
- 手机品牌矩阵分析还可得到这样的结论:用户高峰时期电话数与高峰时期电话时长、低谷时期电话数与低谷时期电话时长以及周末电话数与周末电话时长正相关(趋势线过原点且与X轴夹角约45°)
2.5.2 套餐矩阵分析
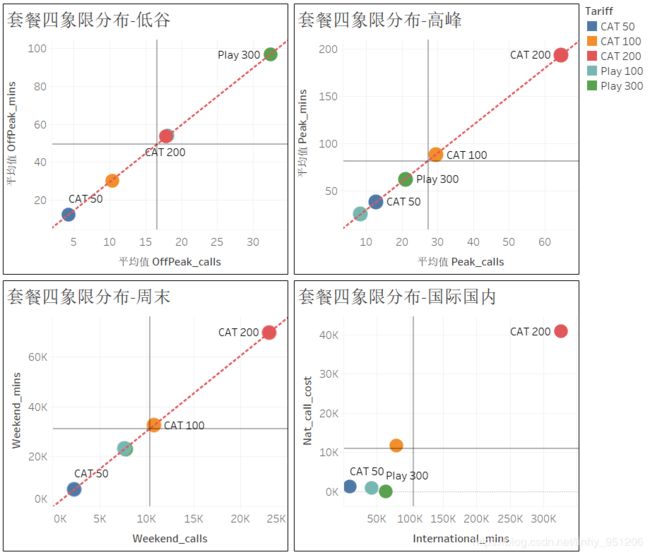
通过套餐矩阵分析可知:
- 在先择CAT 200套餐的用户低谷期、周末、以及高峰期都很活跃,且其电话费用与国际通话时长都超过了平均值,则表明选择套餐CAT 200的用户可能为电信的高价值用户;
- 而选择Play 100与Play 300的用户在低谷期与周末较为活跃,在高峰期不活跃,且这一部分用户的国内电话费用都低于均值,表明这部分用户为低价值用户。
2.5.3 按低谷(周末)和高峰两个维度对用户分层
下图左半部分按高峰时期与低谷时期两个维度分类:高峰时期与低谷时期都活跃的用户(称为A类)、高峰时期活跃而低谷时期不活跃的用户(称为B类)、低谷时期活跃高峰时期不活跃的用户(称为C类)和两个时期都不活跃的用户(称为D类)。
右半部分选择高峰时期与周末两个维度,与左半部分类似。
计算每一种用户的平均电话费用,并用颜色的深浅表示平均电话费用的大小。
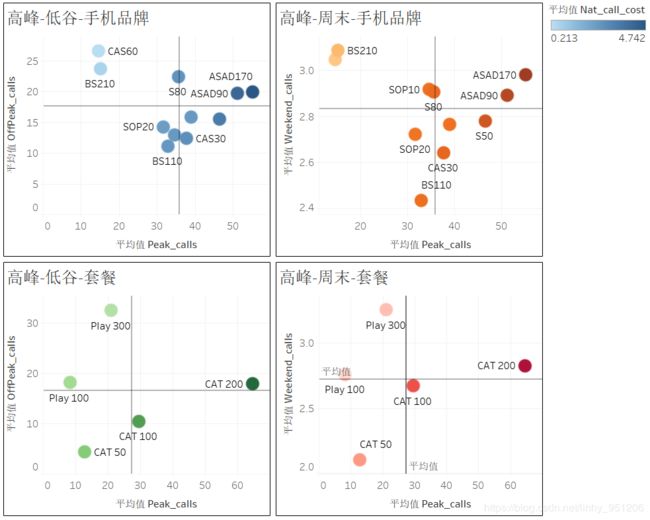
由上图可知:
- 无论是从手机品牌维度还是套餐维度观察,第一象限的点颜色最深,即在高峰期和低谷期或者周末都活跃的用户电话费用最高;
- 从手机品牌维度看,ASAD170和ASAD90是典型的A类用户,从套餐维度分析,CAT 200的用户为典型的A类用户;
- B类用户(手机品牌、套餐)的电话费用排在第二;出乎意料的是D类用户(两个时期都不活跃)的平均电话费用高于C类用户的电话费用(造成这一结果的原因很有可能是因为在低谷活跃的用户会损害电信的收入(即电话费用),如果这种情况成立,那么A类用户的高电话费用就很可能是由于用户在高峰时期的活跃而产生的);
- 从手机品牌维度看,BS210和CAS60是典型的C类用户,从套餐维度分析,Play 100和Play 300的用户为典型的C类用户;
2.6 数据可视化分析结论
- 运营状态:
1、电信用户使用的手机品牌的top5为:S50、BS110、S80、WC95和ASAD170; 从套餐角度看,CAT 200和CAT 100 套餐用户使用量;
2、用户中男女比例较平衡,且趋向于少龄化;
3、用户在网时长分布均匀,没有明显的趋势;
4、高峰时期电话数、电话时长,低谷时期电话数、电话时长等都呈现偏态分布,且全部右偏,即存在少量的头部用户消费较高。 - 用户细分:
在高峰期与低谷期都活跃的用户平均电话费用最高(也有可能只是由于用户在高峰时期活跃导致的),其次为在高峰期活跃而在低谷期不活跃的用户,第三为两个时期都不活跃的用户,最后为在低谷期活跃、高峰期不活跃的用户。
3 聚类分析
3.1 处理数据集
#将类别变量转为虚拟变量,gender为二值型,get_dummies处理后还是一列
dummies=pd.get_dummies(cust[["Gender",'Tariff','Handset']])
# 合并数据集,将虚拟变量加入到数据集中
train = pd.merge(cust,dummies,left_index = True,right_index = True,indicator = True)
# 删除不需要的变量
for i in ['Gender_x','Tariff','Handset']:
del train[i]
train.head()
返回结果:

# 查看数据集的列
# 查看数据集的列
del train['_merge']
train.columns.to_list()
返回结果:

3.2 聚类
# 导入所需库
from sklearn.cluster import KMeans
from sklearn.preprocessing import Normalizer
# 数据预处理
norm = Normalizer()
norm.fit(train)
norm_train = norm.transform(train)
# 聚类
norm_cluser = KMeans(n_clusters = 4)
norm_cluser.fit(norm_train)
# 为用户数据集cust加一列用户标签,标签为聚类模型的分类结果
cust['class'] = norm_cluser.predict(norm_train)
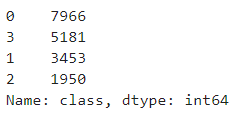
# 查看用户分类分布
cust['class'].value_counts()
返回结果:
3.3 绘图——判断聚类效果
# 降低纬度
from sklearn import manifold
tsne = manifold.TSNE()
tsne_data = tsne.fit_transform(norm_train)
# 将降维后的数据与用户标签合并为一个数据集
tsne_df = pd.DataFrame(tsne_data,columns=['col1','col2'])
tsne_df.loc[:,"class"] = norm_cluser.predict(norm_train)
# 对降维后的数据集绘图,观察类与类之间是否分明
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize = (10,8),dpi = 80)
sns.scatterplot(x = 'col1',y = 'col2',hue = 'class',data = tsne_df)
plt.show()
返回结果:
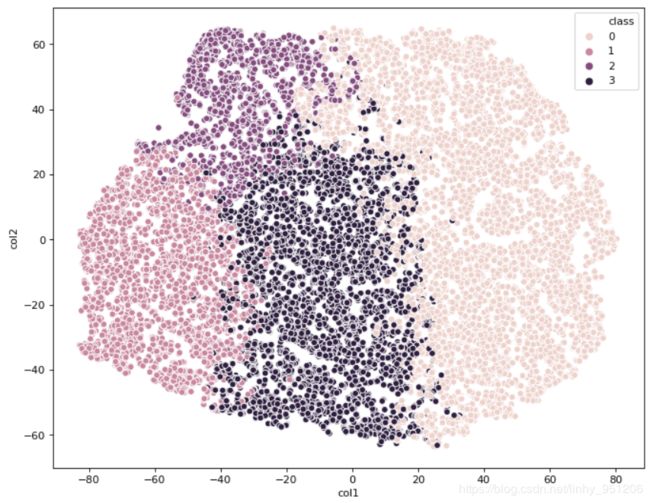
上图显示聚类结果比较好,类与类之间界限比较明晰。
3.4 聚类效果的可视化判断
将聚类后的用户数据导入到Tableau中进行可视化:
cust.to_excel('C:\\Users\\lin\\Desktop\\cust_new.xlsx')
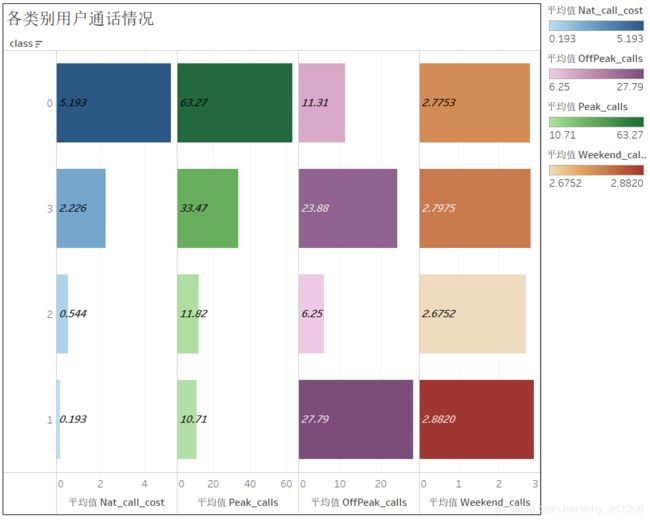
由上图可发现:
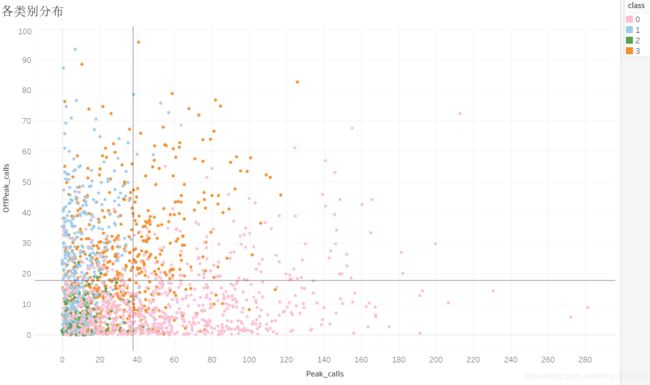
- 通过各类别用户通话情况分析可知:高峰电话数与电话费用正相关,且观察图示可知类别2与2.5.3章节中描述的类别D特征相似,类别1与2.5.3章节中描述的类别C特征相似。观察下图发现类别2的用户基本全部分布在第三象限,类别1基本分布在第四象,这说明聚类模型返回的类别1跟类别2能够较好地地回溯2.5.3章节中对类别C、D的描述;
- 观察聚类模型返回的类别0和类别3,发现与前文描述的类别A、B之间有些许差距,这是由于可视化分析中不能将全部的特征纳入到考虑范围内而造成的;
- 总体而言,聚类模型能够较好地将用户进行聚类。
故此时成功地将电信的用户分为4类,在此基础上能够为每一类用户提供差异化的服务,提升用户体验进而提升企业ARPU值。