基于知识图谱+机器学习,搭建风控模型的项目落地
本项目主要实现逻辑如下:
1.将测试数据分表格存入mysql数据库。
2.设计知识图谱关系图,按照设计思路将node与对应的relationship存入neo4j数据库。
3.设计一套有效的特征,提取特征用于机器学习模型进行训练,用以风控判断。
4.将提取特征的cypher语句存入mysql,使用SpringBoot搭建微服务,用以读取api获取每个进件的特征矩阵。
5.使用逻辑回归、GBDT,神经网络等模型在训练数据上搭建风控模型,通过AUC指标判断模型的准确率。
6.使用测试数据,通过最优模型获取预测结果。
下面讲解具体实现过程:
1.测试数据准备
我们准备了如下几个测试数据集
person:标注用户姓名、性别、手机号、用户黑名单

phone:手机号、手机号黑名单

phone2phone:通话记录拨打方、接听方、通话的起止时间
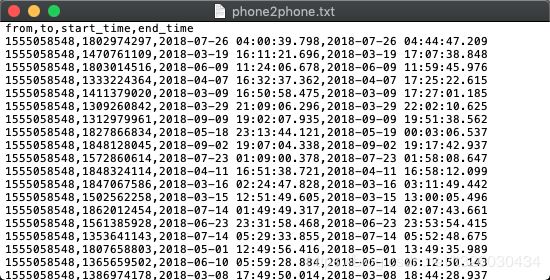
apply_train与apply_test:进件贷款金额、实现、申请人工作、地点、父母手机号、同事手机号、公司电话、申请人id、进件状态(其中apply_test内status值为空)

将以上所有数据导入mysql

2.设计知识图谱
由测试数据可直接得到以下关系:
1.people节点与apply节点之间有fill关系
2.apply节点与phone节点之间有parent_phone、colleague_phone、company_phone等关系
3.people与phone之间有has_phone的关系
然后通过上述关系可推得以下关系:
4.parent_phone的持有人与进件的申请人为parent_of关系,同理可推得colleague_of关系
5.通过通话记录可推得两个people节点之间的known关系

通过以上关系图谱,使用APOC将数据以对应的关系存入neo4j中,得到类似于以下结构的数据

3.设计特征提取规则
因为最终传入机器学习模型的训练应该是一个二维数组,所以我们需要从neo4j中提取每个进件的特征。实际项目中,可能需要设计几十个或上百个规则才可以达到需要的准确率,在这里以7个特征为例做讲解。
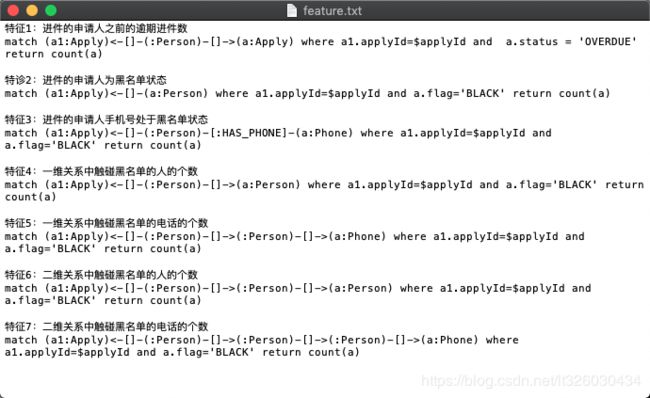
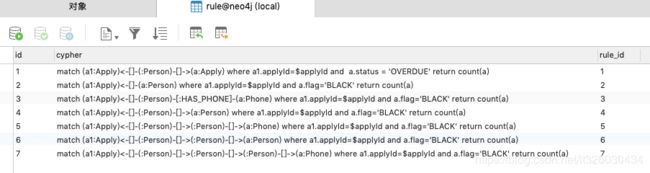
我们需要将以上规则存入mysql,用以后续调用
4.搭建SpringBoot微服务
代码结构如下:业务代码放在RuleController类中
@RestController
@Api(value = "/" , description = "规则引擎服务")
@RequestMapping("v1")
public class RuleController {
@Autowired
private SqlSessionTemplate template;
@Autowired
private Driver driver;
@ApiOperation(value = "获取规则引擎中规则执行的结果",httpMethod = "POST")
@RequestMapping(value = "/getRuleResult", method = RequestMethod.POST)
public int getRuleResult(@RequestParam String ruleID, @RequestParam Integer applyId){
/**
* 从mysql中拿到规则
*/
String ruleCypher = template.selectOne("getRule",ruleID);
/**
* 获取到neo4j的session 对象,用来执行cypher语句
*/
Session session = driver.session();
Map ruleMap = new HashMap();
ruleMap.put("applyId",applyId);
//用来存储Cypher最终执行的结果
int resultCount = 0;
// 执行cypher语句
StatementResult result = session.run(ruleCypher,ruleMap);
Map resultMap = new HashMap();
while (result.hasNext()){
Record record = result.next();
resultMap = record.asMap();
Long resultLong = (Long) resultMap.get("count(a)");
resultCount = Math.toIntExact(resultLong);
}
return resultCount;
}
}
我们在传入对应的rule_id和进件id时,可以通过微服务拿到我们需要的特征值,然后将所有特征组合为二维向量,形成机器学习模型所需的测试数据集。
此时所有OVERDUE状态的进价,我们将label标记为1,其他状态的进件标记为0,导入data.txt文件
import re
import requests
f2 = open('data.txt', 'a+', encoding='utf8')
with open('train.txt', 'r', encoding='utf8') as f:
for i in f.readlines():
l = []
num = re.findall('(\d{6})', i)[0]
l.append(int(num))
for rule in range(1, 8):
r = requests.post(
'http://localhost:9527/v1/getRuleResult?ruleID=' + str(rule) + '&applyId=' + str(num)).text
l.append(int(r))
status = re.findall('IN_PROGREESS|REPAID|OVERDUE|RETURNING', i)[0]
if status == 'OVERDUE':
label = 1
else:
label = 0
l.append(label)
f2.write(str(l)+',')
当然,犹豫样本不均衡的原因,直接使用测试数据会导致模型AUC值较低,所以需要对测试数据集进行一定处理,样本不均衡问题的解决方案不在此做过多阐述。
5.机器学习模型训练
使用逻辑回归、GBDT、神经网络等常用二分类问题模型,对测试数据进行训练,再次仅以神经网络模型进行代码演示。
导入数据集
import pandas as pd
dataArray = eval(open('data.txt', 'r', encoding='utf8').read())
df = pd.DataFrame(dataArray)
X = df.iloc[:, 1:8].values
y = df.iloc[:,8].values
建立神经网络模型进行训练:通过K-FORD交叉验证对模型进行调参
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import KFold
from sklearn.metrics import roc_auc_score
import numpy as np
param_hidden_layer_sizes = np.linspace(10, 200, 20) # 针对参数 “hidden_layer_sizes”, 尝试几个不同的值
param_alphas = np.logspace(-4,1,6) # 对于参数 "alpha", 尝试几个不同的值
best_hidden_layer_size = param_hidden_layer_sizes[0]
best_alpha = param_alphas[0]
for size in param_hidden_layer_sizes:
for val in param_alphas:
sc = []
for train_index, test_index in kf.split(X):
mlp = MLPClassifier(alpha=int(val),hidden_layer_sizes=int(size)).fit(X[train_index],y[train_index])
y_predict = mlp.predict(X[test_index])
sc.append(roc_auc_score(y[test_index],y_predict))
auc_list = np.array(sc)
auc_avg = auc_list.mean()
print(auc_avg)
if auc_avg > best_auc_avg:
best_auc_avg = auc_avg
best_hidden_layer_size = size
best_alpha = val
auc_std = auc_list.std()
print ("auc均值最高时,参数hidden_layer_size值为: %f" % (best_hidden_layer_size))
print ("auc均值最高时,参数alpha值为: %f" % (best_alpha))
print ("此时auc平均值为: %f" % (best_auc_avg))
print ("此时auc标准差为: %f" % (auc_std))
mlp = MLPClassifier(alpha=best_alpha,hidden_layer_sizes=best_hidden_layer_size).fit(X,y)
y_pred = clf.predict(X)
print("模型准确率为: %f" % (clf.score(X,y)))
当获得最优参数的模型后,对模型进行保存
from sklearn.externals import joblib
joblib.dump(mlp, 'mlp.pkl')
6.对测试数据进行标记
载入模型,调取test.txt文件的测试数据,通过SpringBoot获取特征数组,将数组传入神经网络获取label值,然后存入applt_test_pred文件中,到此整个风控模型项目的搭建就结束了。
import re
import requests
lr = joblib.load('mlp.pkl')
f2 = open('applt_test_pred.txt', 'a+', encoding='utf8')
with open('test.txt', 'r', encoding='utf8') as f:
for i in f.readlines():
l = []
num = re.findall('(\d{6})', i)[0]
for rule in range(1, 8):
r = requests.post(
'http://localhost:9527/v1/getRuleResult?ruleID=' + str(rule) + '&applyId=' + str(num)).text
l.append(int(r))
label = lr.predict(l)[0]
if label == 1:
f2.write('OVERDUE'+'\n')
else:
f2.write('NORMAL'+'\n')
f2.flush()
整个项目搭建到这里就完成了,有疑问的同学请在博客下方留言,谢谢!